







最近本来在研究word2vec,想计算两个句子的相似度。
偶然看到synonmys,感觉好强大啊,以后要多多学习!
synonyms:中文近义词工具包
synonyms可以用于自然语言理解的很多任务:文本对齐,推荐算法,相似度计算,语义偏移,关键字提取,概念提取,自动摘要,搜索引擎等。
两个句子的相似度比较:
例子:
sen1 = "发生历史性变革"
sen2 = "发生历史性变革"
r = synonyms.compare(sen1, sen2, seg=True)
其中,参数 seg 表示 synonyms.compare是否对sen1 和 sen2进行分词,默认为 True。返回值:[0-1],并且越接近于1代表两个句子越相似。
计算结果:
旗帜引领方向 vs 道路决定命运: 0.429
旗帜引领方向 vs 旗帜指引道路: 0.93
发生历史性变革 vs 发生历史性变革: 1.0
中文分词:
例子:
import synonyms
synonyms.seg("中文近义词工具包")
结果:
(['中文', '近义词', '工具包'], ['nz', 'n', 'n'])
分词结果由两个list组成的元组,分别是单词和对应的词性。该分词不去停用词和标点。
打印近义词:
例子:
>>> synonyms.display("飞机")
'飞机'近义词:
1. 架飞机:0.837399
2. 客机:0.764609
3. 直升机:0.762116
4. 民航机:0.750519
5. 航机:0.750116
6. 起飞:0.735736
7. 战机:0.734975
8. 飞行中:0.732649
9. 航空器:0.723945
10. 运输机:0.720578
获得一个词语的向量:
例子:
>>> synonyms.v("飞机")
array([-2.412167 , 2.2628384 , -7.0214124 , 3.9381874 , 0.8219283 ,
-3.2809453 , 3.8747153 , -5.217062 , -2.2786229 , -1.2572327 ],
dtype=float32)
该向量为numpy的array,当该词语是未登录词时,抛出 KeyError异常。
什么是未登录词??
获得一个分词后句子的向量:
synonyms.sv(sentence, ignore=False)
sentence: 句子是分词后通过空格联合起来
ignore: 是否忽略OOV,False时,随机生成一个向量
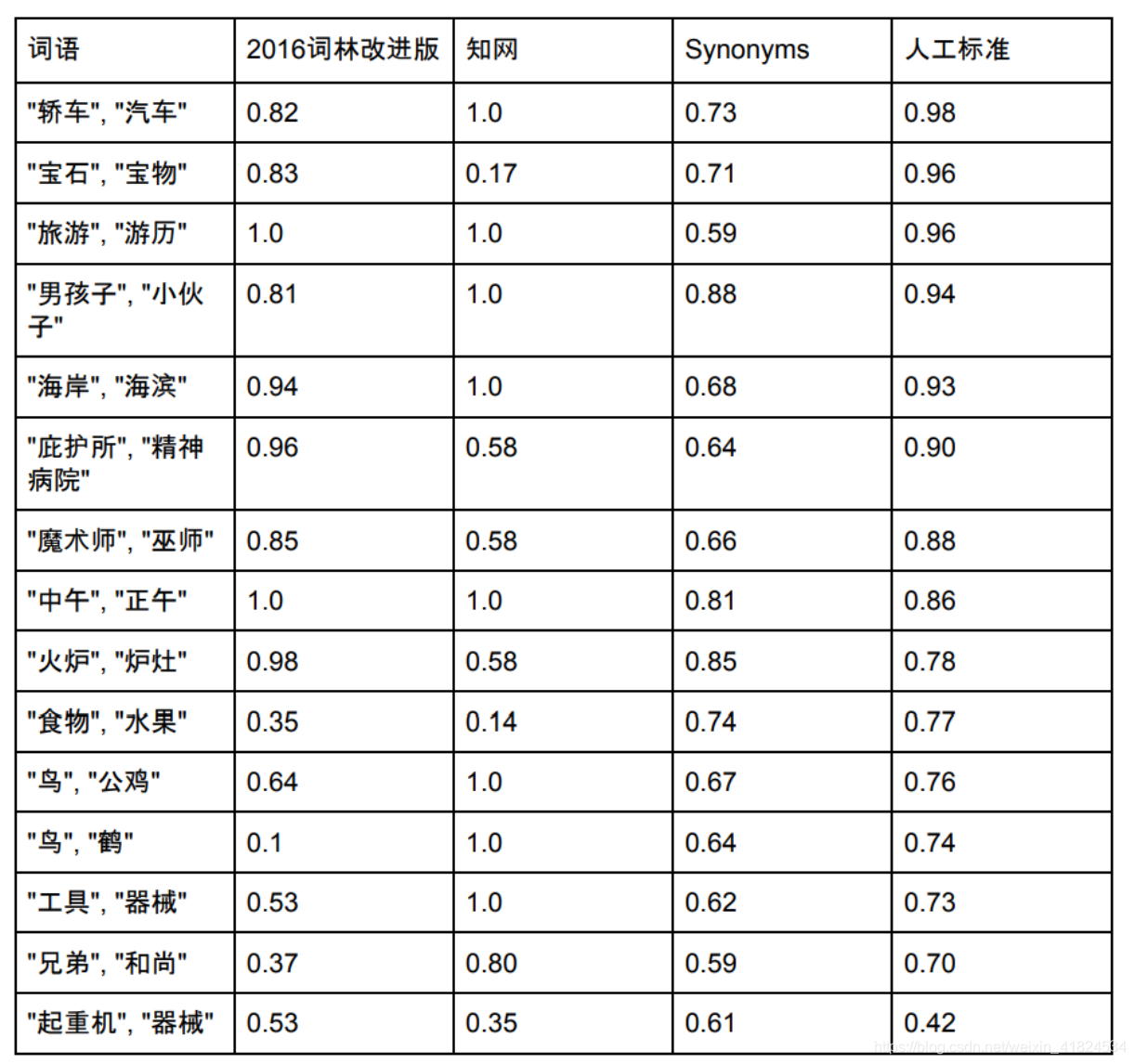
数据来源:
Synonyms的词表容量是125,792,下面选择一些在同义词词林、知网和Synonyms都存在的几个词,给出其近似度的对比:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









