




目录
重要性
- 最新的OpenAI GPT和BERT模型,都是以Transformer为基础的。
- 在“放弃幻想,全面拥抱Transformer:NLP三大特征抽取器(CNN/RNN/TF)比较”这篇文章中,作者认为TF(Transformer)提取器会代替CNN和RNN成为接下来的主流提取器。
简介
Transformer模型来自谷歌的论文Attention Is All You Need,最大的亮点是采用了Self-Attention机制和Position Encoding来替代RNN的Sequence-to-sequence,最初用于提升机器翻译的效率。
模型概览
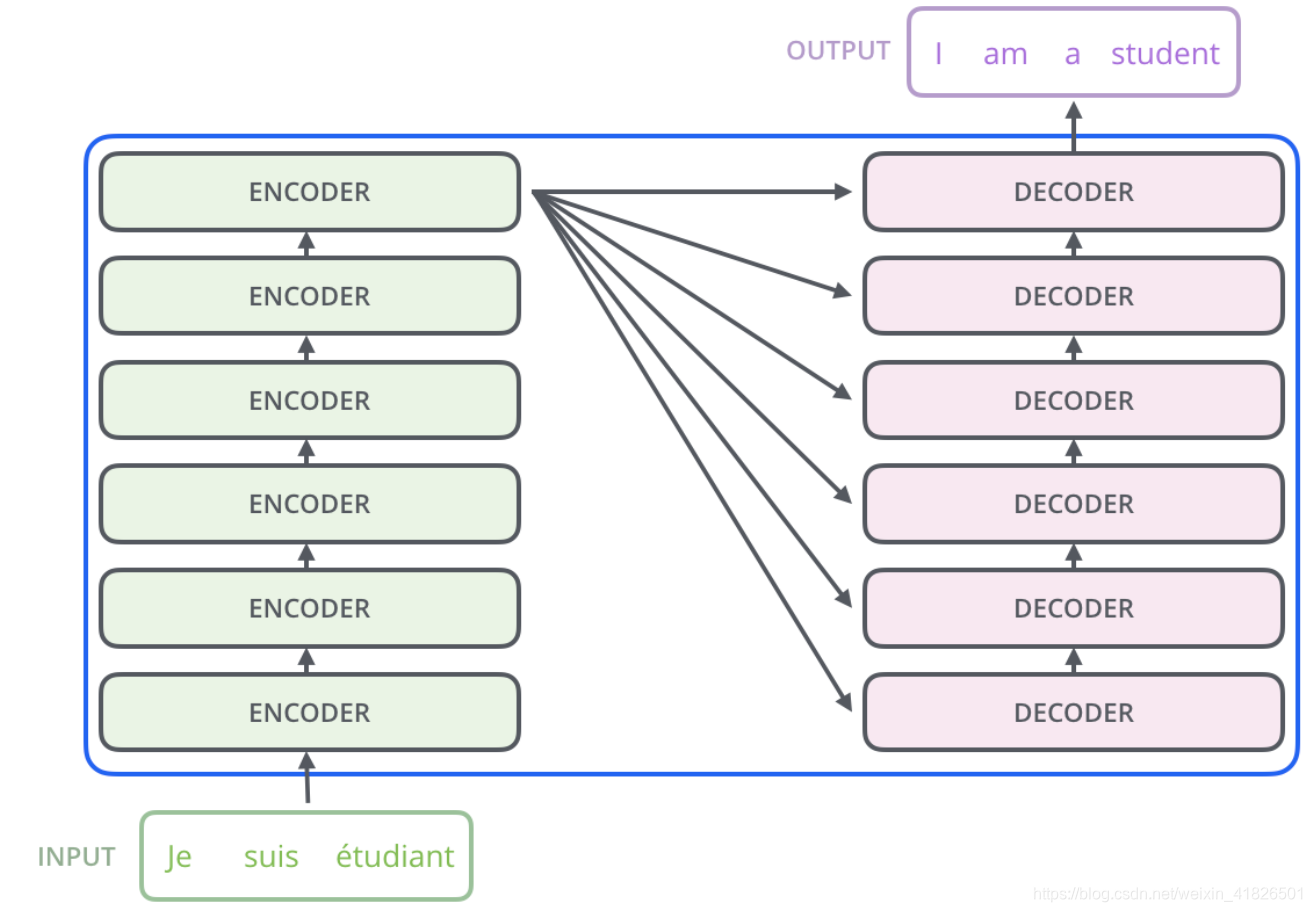
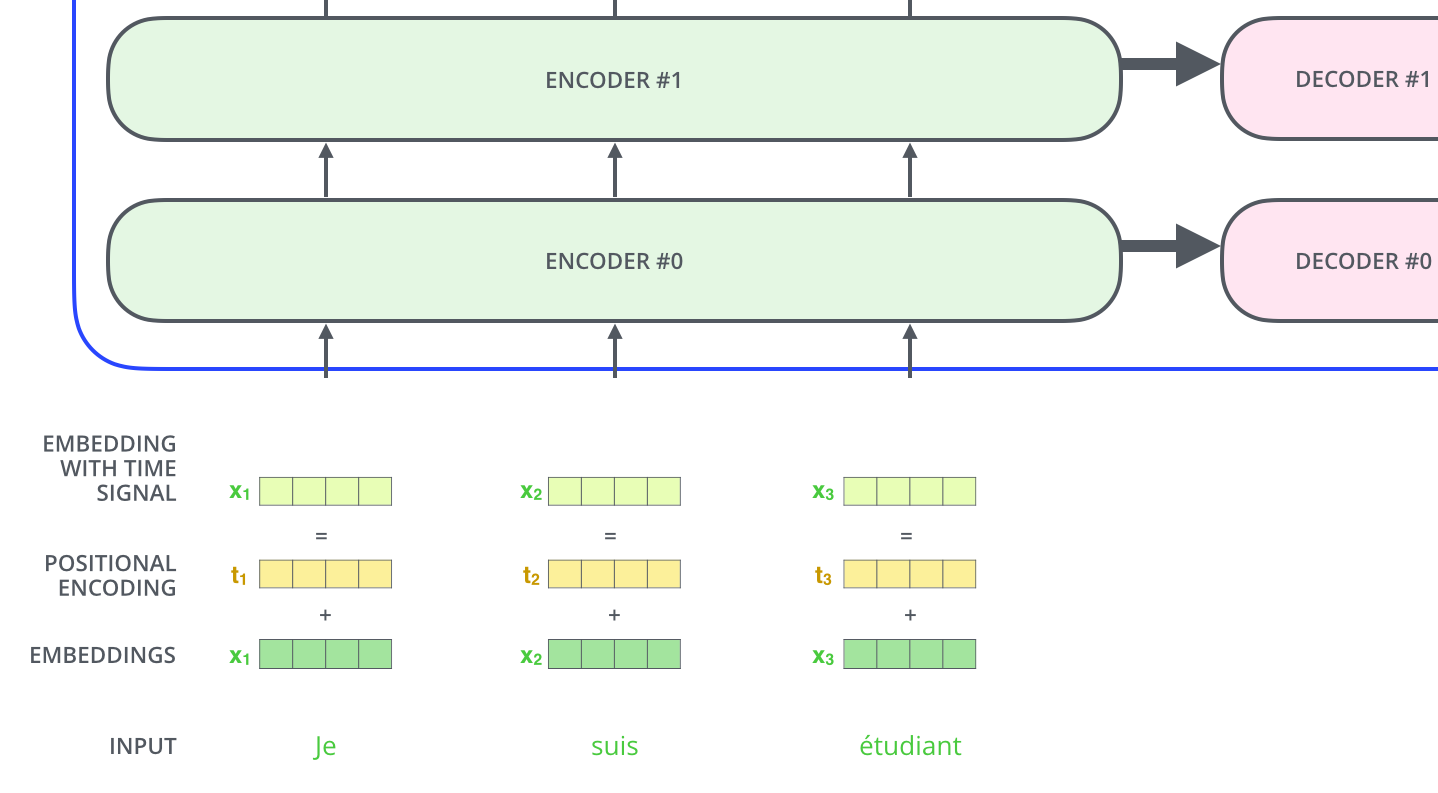
Transformer有Encoder和Decoder两个部分,Encoder有6个结构一样的Encoder层,Decoder有6个结构一样的Decoder层,如下图所示。
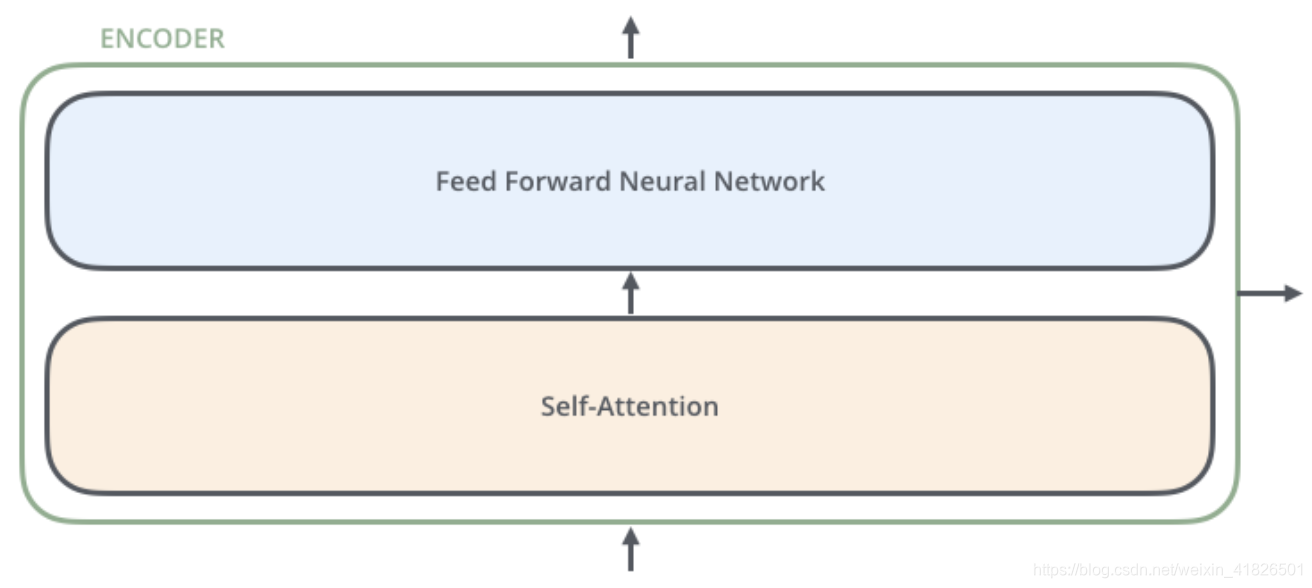
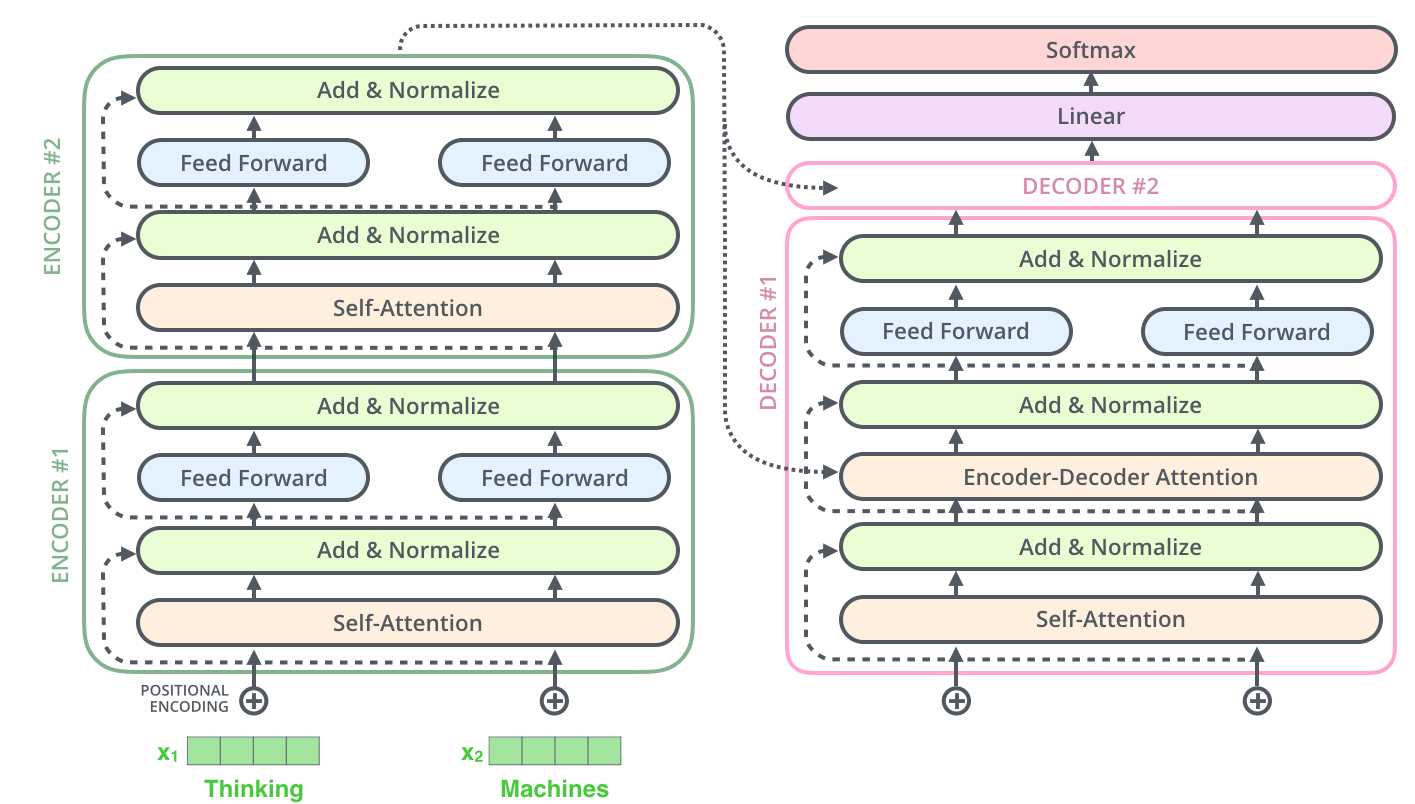
每层Encdoer有一个Self-Attention层和一个全连接网络层,如下图所示:
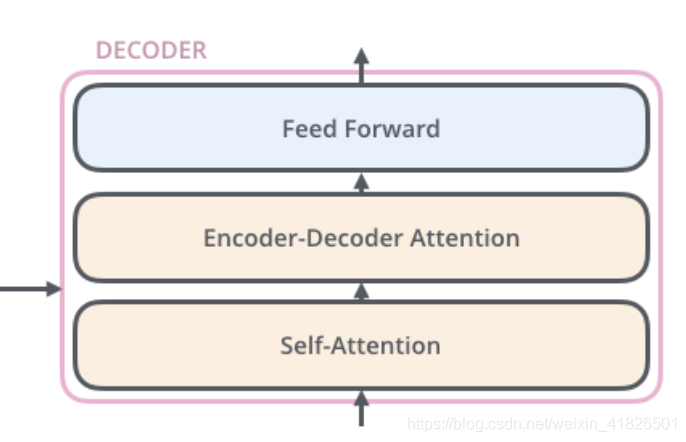
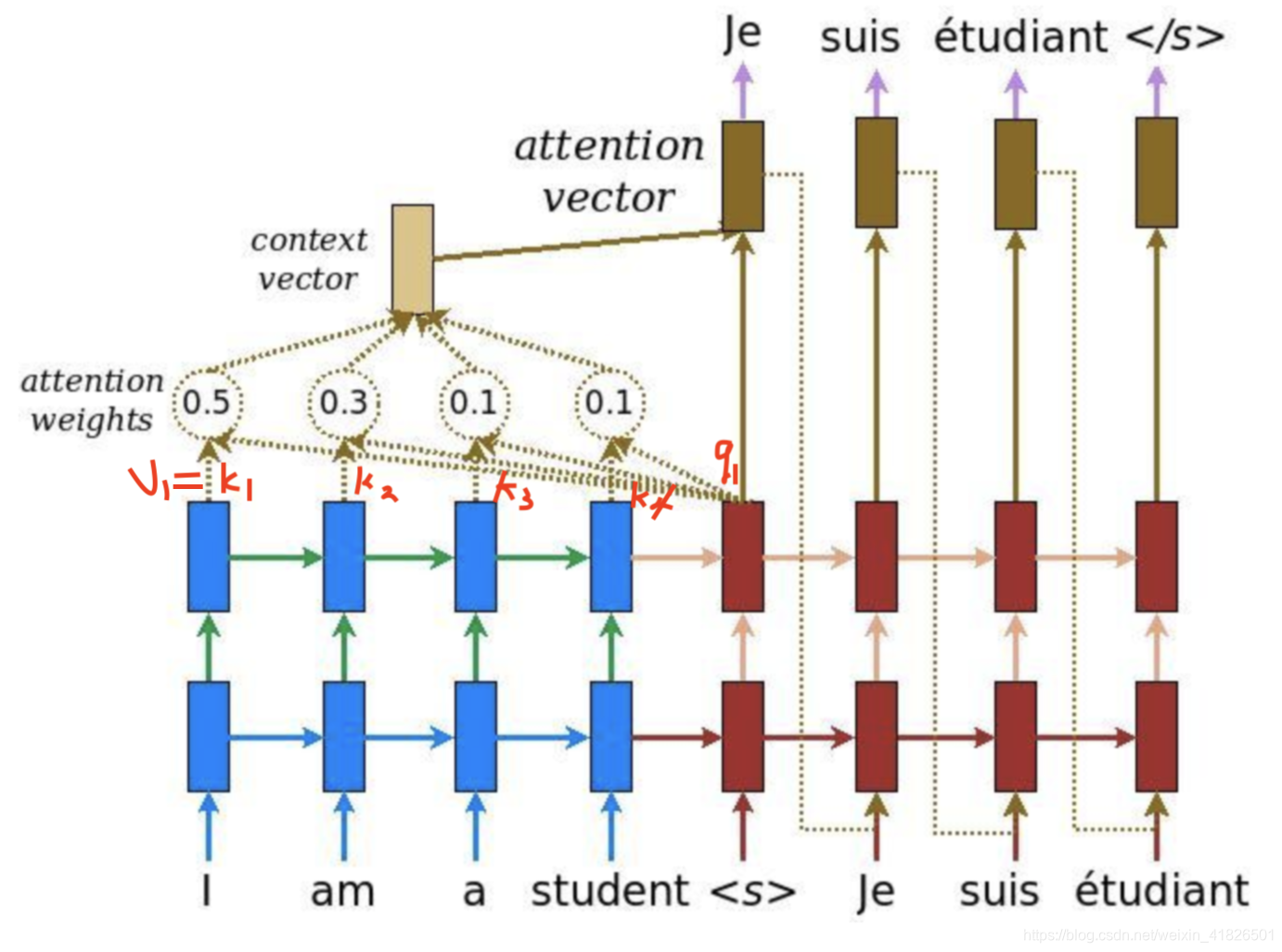
每层Decoder有一个Self-Attention层、一个普通的Attention层(指encoder和decoder之间的attention)和一个全连接层,如下图所示。普通的Attention层使得Decoder在解码时会考虑最后一层Encoder所有时刻的输出,所以Encoder最后一层的输出要喂给所有的Decoder来做这个普通的attention。
加入输入embedding
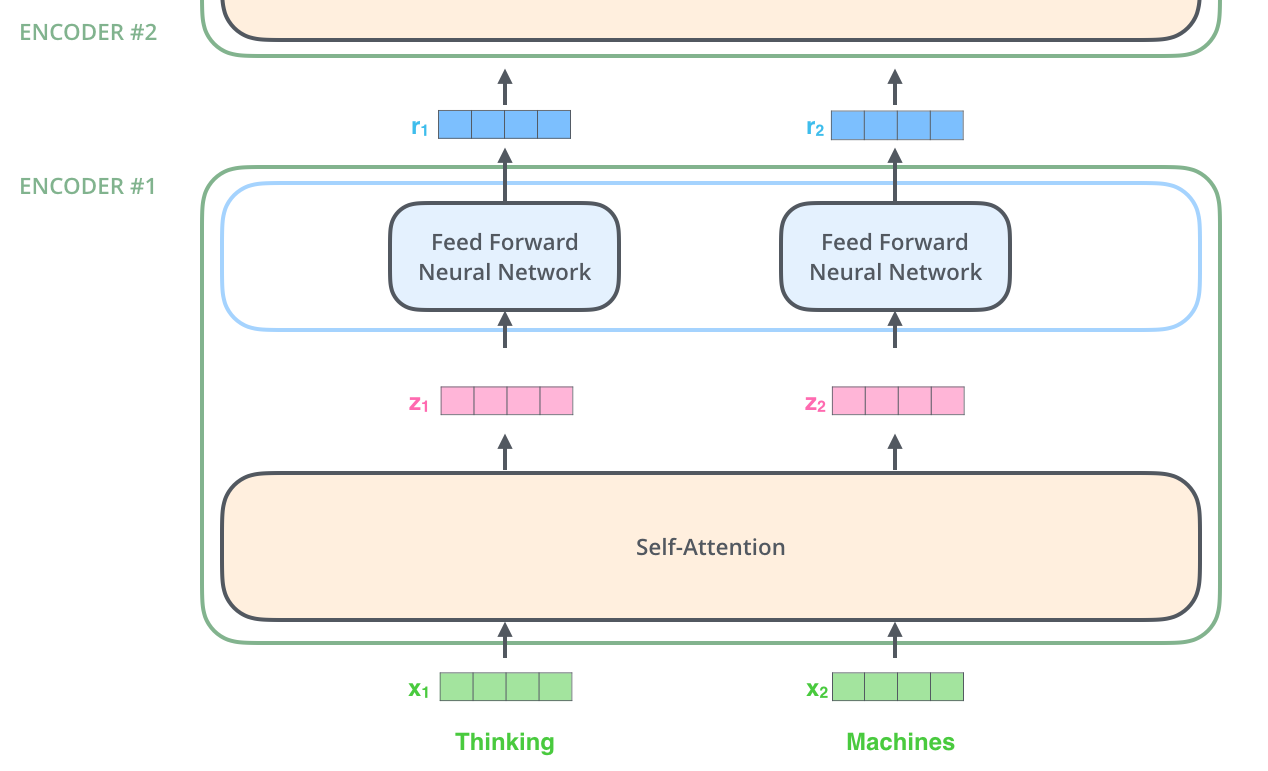
Self-Attention对所有对输入向量做self-attention,得到输入个输出,每个输出各自送到各自的全连接网络,得到各自的输入向量,送入下一层Encoder。
Self-Attention
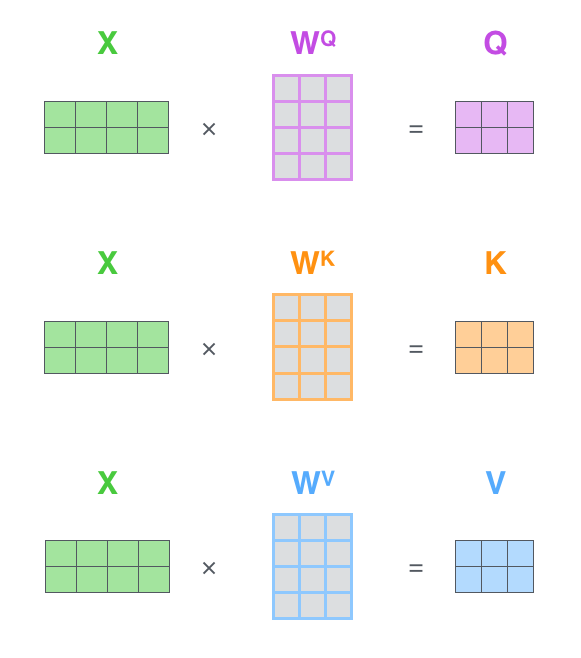
当前句子对自己对attention,体现在对每个单词的embedding进行编码时去考虑它需要对本句的其他单词给予多少关注度。各个词先有一个初始化的embedding,然后分别乘Wq、Wk、Wv参数矩阵得到相应的q、k、v向量,然后用q与所有词的k做点积、归一化、softmax(这三步操作跟普通attention里的很像啊)后,作为需要对各个v的加权权值,最后输出z作为单词的表征向量。
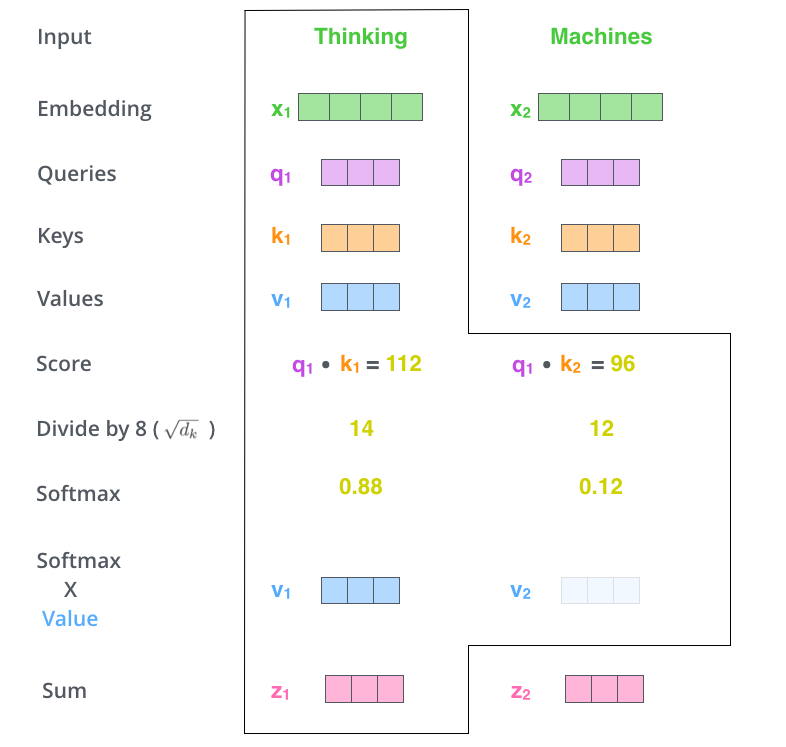
将q、k、v向量跟普通的attention对照一下,就可以看到普通的attention中k=v,是self-attention的一种特例:
可以通过向量化计算提高效率,充分利用硬件资源:
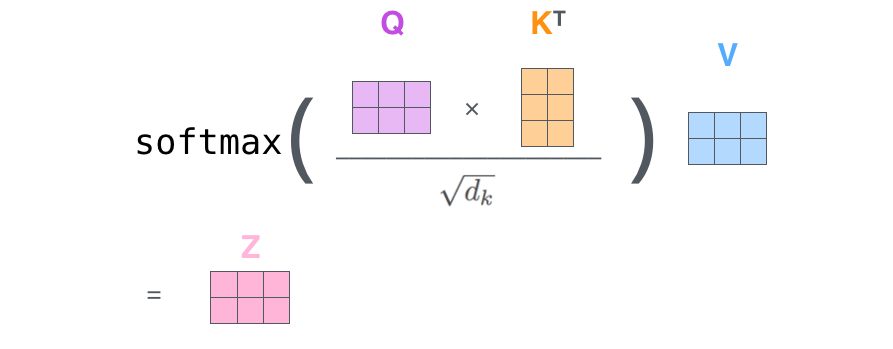
Multi-head Attention
即一个句子用多组Wq、Wk、Wv参数矩阵,来学习多种attention方式。
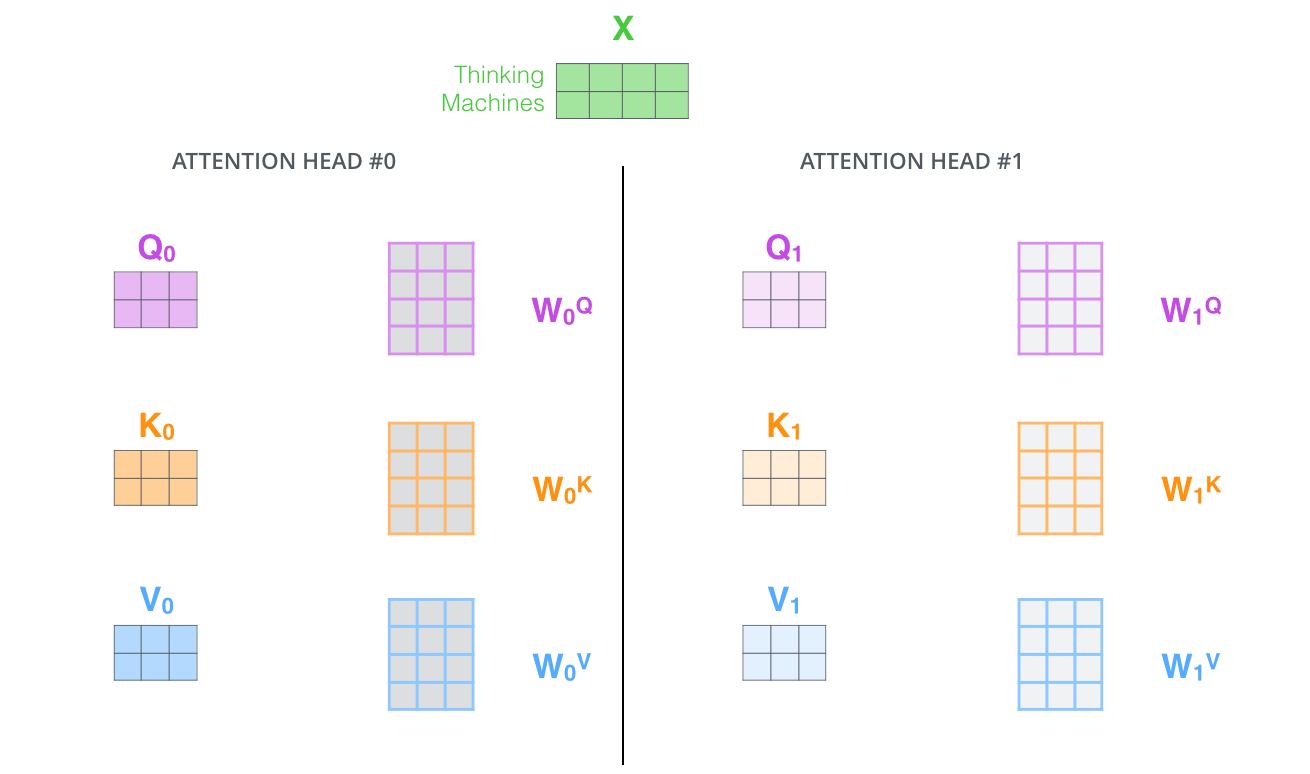
但这样一个词会计算输出多个z,需要压缩成一个z,所以multi-head attention会多出一个压缩矩阵Wo: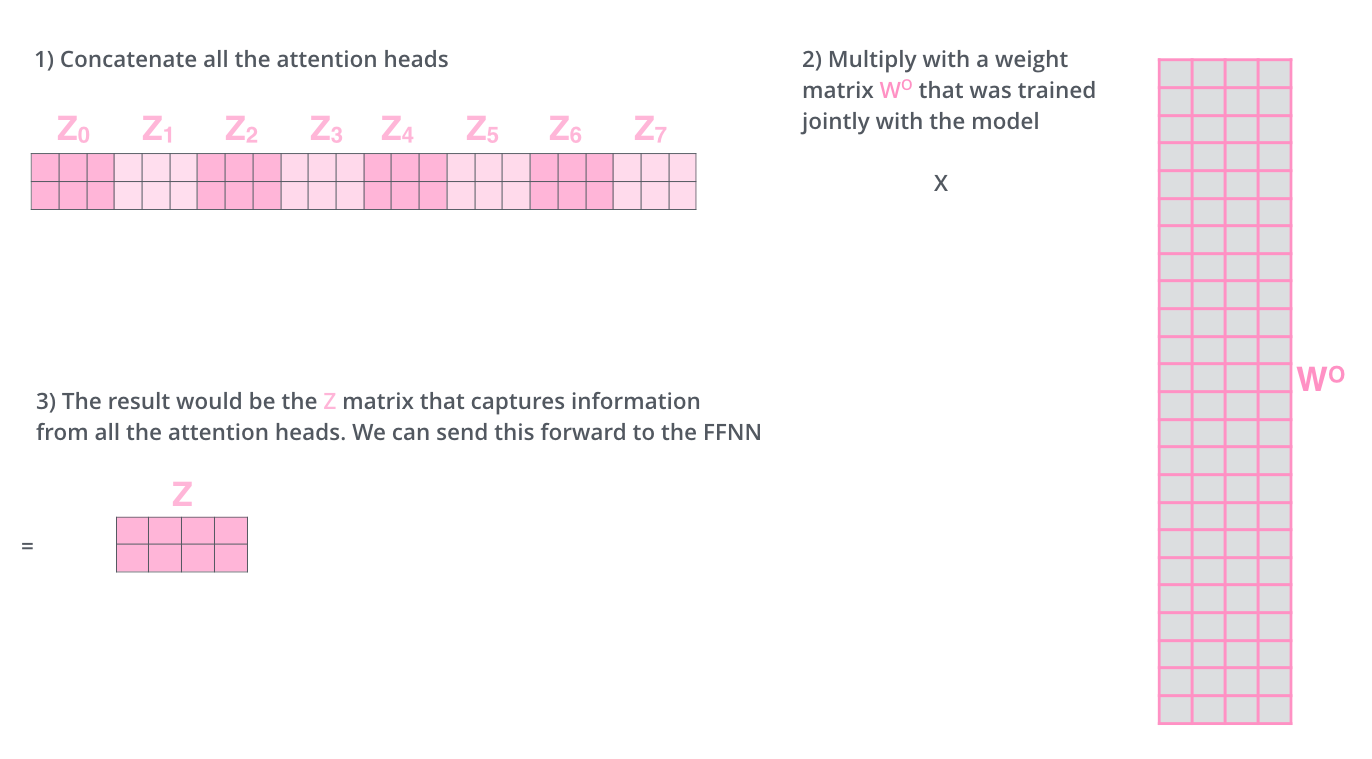
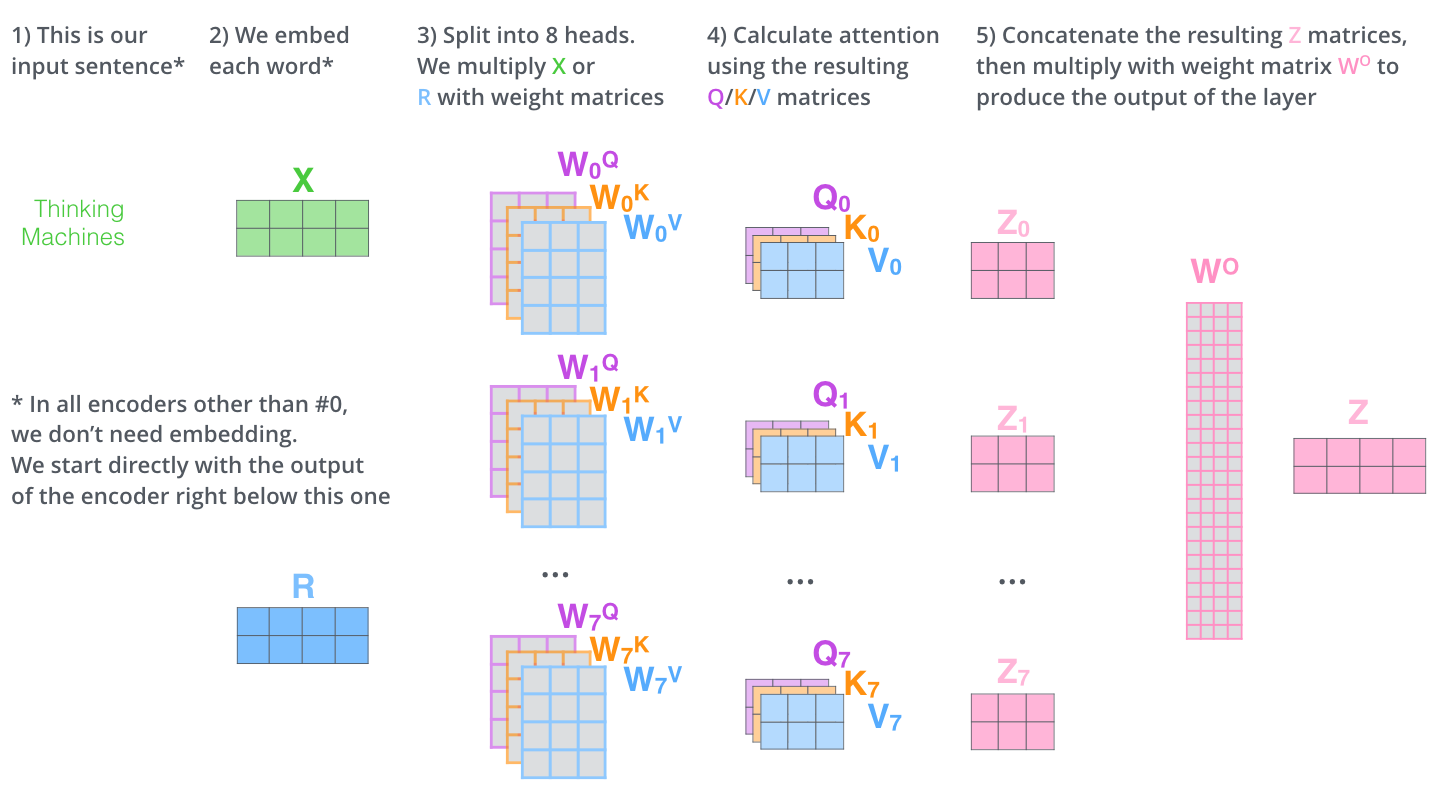
multi-head attention的完整计算过程就是如下的12345步:
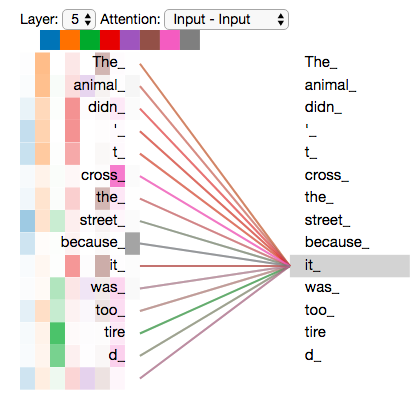
学到的语义就会是如下的tensor-to-tensor里显示出来的(不知道怎么看???):
位置编码(Positional Encoding)
RNN是可以学到各个词的相对位置关系的,同一个词在不同的位置上学出来的word embedding可以不一样。
然而,self-attention把所有的词放在一块去self-attention了,没有融入位置关系,因此考虑对位置进行编码。类比word embedding是对词进行编码,position encoding就是对位置进行编码(跟word embedding通常是同样的维度),将word embedding和position encoding求和作为该位置上该词对embedding,这样同一个词在不同的位置上的embedding就是不同的了,能够融入位置关系。这样的话如果两个词在不同的位置出现了,虽然它们的Embedding是相同的,但是由于位置编码不同,最终得到的向量也是不同的。 在BERT模型里,使用就是这种简单的可以学习的Embedding,和Word Embedding一样,只不过输入是位置而不是词而已。
对于两个句子:”北京到上海的机票”和”你好,我们要一张北京到上海的机票”,Bert里这种编码方式没有办法使得Query(北京1)Key(上海1)等于Query(北京2)Key(上海2)。对此,在transformer原始论文中用的是相对位置编码,能够根据词的相对关系进行编码,具体怎么操作还没去看。
Layer Normalization
Batch Normalization虽然能够让模型收敛的更快,但有两个问题:一是它需要一个minibatch的数据,而且这个minibatch不能太小;二是它不能用于RNN,因为同样一个节点在不同时刻的分布是明显不同的(???)。改进方法Recurrent Batch Normalization可以对RNN进行Batch Normalization。
Transformer里使用了另外一种Normalization技巧,叫做Layer Normalization。假设我们的输入是一个minibatch的数据,我们再假设每一个数据都是一个向量,则输入是一个矩阵,每一行是一个训练数据,每一列都是一个特征。BatchNorm是对每个特征进行Normalization,而LayerNorm是对每个样本的不同特征进行Normalization,因此LayerNorm的输入可以是一行(一个样本)。通过平均”期望”使某样本的各个特征的取值范围大体一致,也可能使得神经网络调整参数更加容易,如果这几个特征实在有很大的差异,模型也可以学习出合适的参数让它来把取值范围缩放到更合适的区间。
残差连接
就是ResNet里的那种残差连接。加入了Layer Normalization和残差连接之后的transformer全景图如下:
好像还有一部分内容是mask:decoder还没译到的信息要遮盖掉???
Transformer的优势
- 可以并行化,而RNN只能顺序执行。
- self-attention可以实现输入参数共享,而RNN只能有单向的信息流,即便是双向RNN的正向和反向也都只能存储单向的信息流,需要第二层RNN才能把双向信息学到。
- 可以实现深层的架构(transformer有6层encoder、6层decoder,OpenAI和Bert里层数更多),而RNN受限于随时间的反向传播,不能设置太多层。

















 2万+
2万+




 到【灌水乐园】发言
到【灌水乐园】发言







