







一、熵、信息熵、交叉熵、softMax、sigmoid
-
熵:表示系统的不确定程度,或者说系统的混乱程度 信息熵:熵的另一种叫法,就比如我们叫帅哥,广东叫靓仔,是一个领域和地域的划分
-
信息熵公式:

-
相对熵:就是KL散度
-
KL散度:是两个概率分布间差异的非对称度量
通俗说法:KL散度是用来衡量同一个随机变量的两个不同分布之间的距离。 -
KL散度公式:
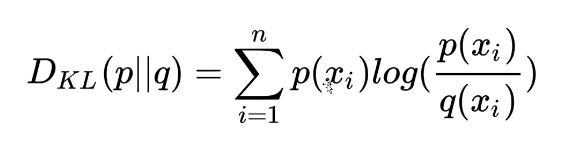
-
KL散度特性:
非对称性,P对Q的,不等于Q对P的
非负性,KL散度大于等于0
公式经过变形,能得到KL散度=交叉熵-信息熵
 7. 交叉熵:
7. 交叉熵:
交叉熵的应用:主要用于同一个随机变量X的预测分布Q和真实分布P之间的差距,差距可理解为(距离、误差、失望值)
8.交叉熵公式:p(x)是真实值,log(q(x))是预测值

预测越准确,交叉熵值越小
交叉熵只跟真实标签的预测概率值有关
9.交叉熵最简公式:
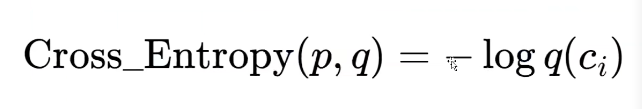
10.交叉熵二分类公式:

注:普通公式、最简公式、二分类公式算出的值都是一样的
问:为什么使用交叉熵做损失函数而不使用信息熵呢?

-
softmax函数
是将数字转换成概率的神器,是进行数据归一化的利器。如果说logistic有两个老婆,则softmax有一堆后宫
softmax公式:
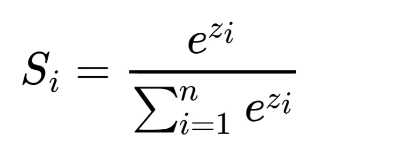
-
sigmoid函数:
sigmoid函数也叫logistic函数,取值范围是0到1,是神经网络的常用激活函数,常被用做二分类
sigmoid公式:
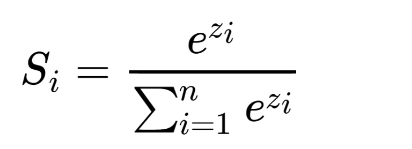
-
常见的交叉熵损失函数类型:
二分类:sigmoid+交叉熵
二分类:softMax+交叉熵
多分类:softMax+交叉熵
问题:sigmoid和softmax都可以做损失函数,那哪一个更好一点呢?
答:哪个都行
以上内容是学习了b站视频做的笔记:
https://www.bilibili.com/video/BV1Wq4y1L7Tu?spm_id_from=333.337.search-card.all.click
二、softtMax函数:
Softmax 将任意实数值转换为概率。
1、将e (数学常数)提高到每个数字的幂。
2、总结所有指数。这个结果就是分母。
3、使用每个数字的指数作为其分子。
4、可能性=分子/分母

Softmax 让我们用概率来回答分类问题,这比简单的答案(例如二进制是/否)更有用
以上内容来自一位博主的博客,讲的非常清楚
https://victorzhou.com/blog/softmax/
.














 1227
1227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









