







MetaFuse :A Pre-trained Fusion Model for Human Pose Estimation
题目:《MetaFus:一种用于人体姿态估计的预训练融合模型》
作者:Rongchang Xie, Chunyu Wang, Yizhou Wang
Center for Data Science, Peking University
Adv. Inst. of Info. Tech., Peking University
Center on Frontiers of Computing Studies, Peking University
CS Dept., Peking University
Microsoft Research Asia
Deepwise AI Lab
{rongchangxie, yizhou.wang}@pku.edu.cn, chnuwa@microsoft.com
来源:CVPR 2020
研究方向:多目-单人姿态识别-预训练融合模型
已有研究:
1、对多目图像3D HPE方法分为两种:
①基于模型的方法:该方法将身体模型定义为简单的基元,如圆柱体等优化参数,与模型投影后与特征图像进行匹配(主要挑战:非线性非凸优化问题)
②两步框架:从摄像机中估计2D姿态后,将2D姿态提升至3D姿态,而提升至3D姿态往往取决于所估计的2D姿态质量,而在发生遮挡时所估计的2D姿态误差往往较大。
解决办法:多视图融合
↓重点解决方向
不同摄像机中的对应位置
↓提出
每对相机的融合网络NativeFuse
(融合网络NativeFuse:使用监督学习一对相机的空间关系,使用全连接层FCL连接两视图的不同位置特征,因此需要很多参数,将所有像素连接起来,而有些位置连接后影响较大且相机位姿发生变换后,需要对模型再训练且灵活性不好)
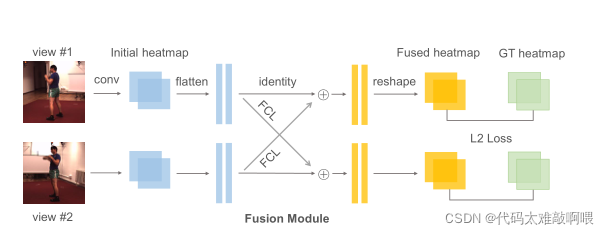
改进: 提出MetaFuse(基于元学习理论)的预训练模型,有效的适应训练或微调一对新的摄像机(仅用少量标签),提升了对相机姿态变换的适应能力
研究方法(思路):
整体结构:重新定制NativeFuse以此解决多视图融合的灵活性问题
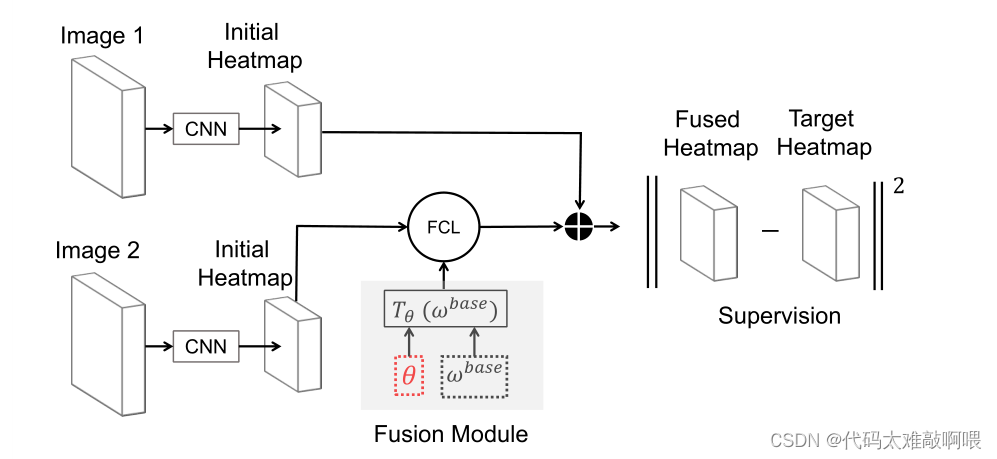
提出:MetaFuse(本文使用CMP Panoptic数据集进行预训练),分为两部分:
①所有摄像机共享通用融合模型(适应未知相机位姿和小数据情况);
②轻量级仿射转换
采用元学习风格:通过一个学习系统对另一个学习系统进行优化,从多任务中学习以快速适应新任务,应用在少镜头分类和强化学习

摄像机C1中的特征X1对相机C2对应的极线I的所有特征融合在一起(在heatmap层),而不找确定的对应关系(通过从数据中学习到的像素进行仿射变换6参数)
整体框架:初始算法Wbase和模型θ进行仿射变换Tθi制定出权重大小,其步骤为:
①对主干网络进行预训练,确定网络模型Wbase和初始化θ(使用训练集数据进行预训练),通过GT和初始热图Wbase,并使用均方误差优化主干网络;
②对MetaFuse进行微调:用少量标注的训练数据,计算梯度θ。
数据集:
1、用Total Capture数据集
在6个相机中选择4个进行多视角融合预训练Wbase,进行多次实验计算平均结果,以此减少随机性;
在测试时,用该数据集对预训练模型Wbase进行测试,但是与训练时所选相机不同。
2、 用H36M数据集
用于对预训练模型进行微调θ(5个相机,每个相机包含4个动作),测试(2个相机)。
3、用CMU Panoptic数据集
和现有多种方法进行比较评估

精度评估
① 2D pose-JDR(成功检测关节百分比)
②3D pose-MPJPE
本文实验:
输入256*256,使用ResNet50网格作为主干网络,输出64*64,所有阶段都是使用Adam优化器,得出结论:MetaFuse模型有较强的泛化能力,且用于训练所需时间短。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









