






本次为各位同学准备的是Spark高频八股-BlockManager管理~
创作不易!多多支持!
面筋
面筋来源:
spark的内存管理机制学习——BlockManager-云社区-华为云 (huaweicloud.com)
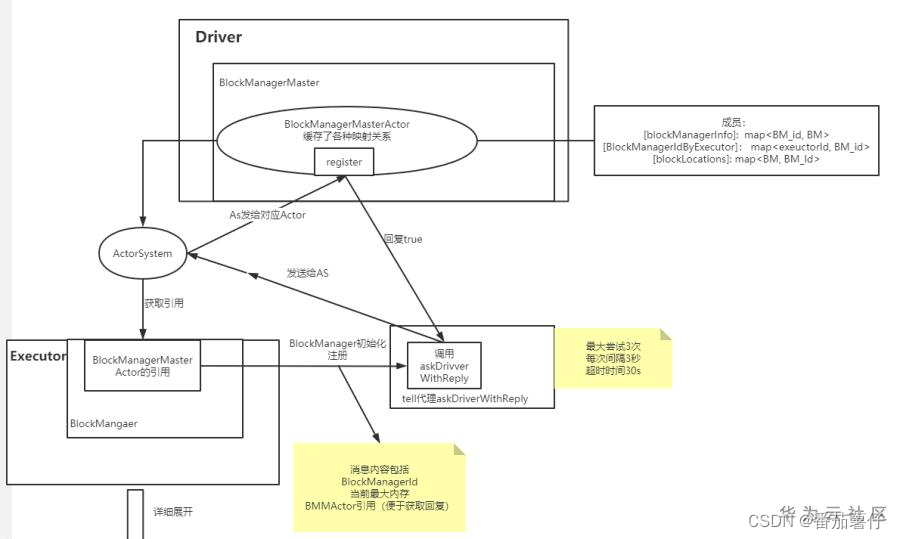
Spark存储(主要由BlockManager来完成)主要完成了:
- 写入数据块,如果需要备份数据块,则将数据块写入其他节点;
- 读取数据块,如果当前节点不含有数据块,则从其他节点获取数据块;
- 向Driver节点注册自身的BlockManager,以及上报其所管理的数据块节点。
Spark使用BlockInfoManager来管理当前节点所管理的数据块的元数据,维护了BlockId(数据块的唯一标识)到BlockInfo(数据块元数据)的映射关系。使用内存(MemoryStore)和磁盘(DiskStore)来存储数据块。
Spark使用BlockManagerMaster使Executor的BlockManager与Driver进行通信,向Driver注册自己,并上报数据块信息。Driver通过Executor BlockManager的BlockManagerStorageEndpoint向Executor发出删除数据块/Rdd/Shuffle/Broadcast等数据。
Spark使用BlockTransferService来实现不同Executor BlockManager之间的通信。用这个BlockTransferService去其他blockManager获取数据块block或者更新数据块block信息
Spark设置了多种存储级别:
| 存储级别 | 说明 |
|---|---|
| DISK_ONLY | 只使用磁盘存储 |
| DISK_ONLY_2 | 只使用磁盘存储,并且有一个备份 |
| MEMORY_ONLY | 只使用内存储存储 |
| MEMORY_ONLY_2 | 只使用内存存储,并有一个备份 |
| MEMORY_ONLY_SER | 只使用内存存储序列化数据 |
| MEMORY_ONLY_SER_2 | 只使用内存存储序列化数据,并有一个备份 |
| MEMORY_AND_DISK | 只使用内存存储序列化数据,并有一个备份 |
| MEMORY_AND_DISK_2 | 优先内存存储,内存不足使用磁盘,并有一个备份 |
| MEMORY_AND_DISK_SER | 优先内存存储序列化数据,内存不足使用磁盘 |
| MEMORY_AND_DISK_SER_2 | 优先内存存储序列化数据,内存不足使用磁盘,并有一个备份 |
| OFF_HEAP | 使用堆外存储(同MEMORY_AND_DISK_SER,只是使用堆外内存) |
put block(写入数据块):在写数据块的时候,根据存储级别的不同,如果存储级别要求存储序列化/非序列化的数据,而输入的数据块是非序列化/序列化的,则要首先序列化/反序列化;如果支持内存存储,则将数据块保存到内存中,如果设置了MEMORY_AND_DISK之类的存储级别,当内存不足时,会将数据块写入磁盘。如果不支持内存存储,只支持磁盘存储,则直接将数据块写入磁盘。如果需要备份数据块,则将数据块同步的写入其他节点。
get block(获取数据块):获取数据块时,如果请求序列化的数据而存储级别是非序列化,则优先从磁盘中获取数据,如果磁盘获取不到,则根据存储级别尝试从内存获取数据并将其序列化;如果存储级别就是序列化数据,则首先尝试从内存获取数据,如果获取不到,则根据存储级别从磁盘获取数据。如果请求的是非序列化的数据,如果存储级别包括内存,则首先尝试从内存获取,如果获取不到,则根据存储级别再尝试从磁盘获取并反序列化数据;如果存储级别只包括磁盘,则直接从磁盘获取并反序列化数据。
register & register block(注册BlockManager&上报数据块信息):Executor的BlockManager在初始化时需要向Driver注册,并定时上报其所管理的数据块信息。
remove(删除数据块):Driver向Executor BlockManager下发删除数据块/Rdd/Shuffle/Broadcast等数据的指令,Executor BlockManager接收指令并在本地执行删除操作。
BlockInfoManager
BlockInfoManager主要维护了BlockManager所管理的所有数据块元数据以及对申请数据块读写的任务提供数据块读写锁。Spark中的数据块除了实际存储数据的Block之外,还有两个数据结构,BlockId和BlockInfo分别用来为数据块提供全局唯一的标记,以及记录数据块的元数据。
BlockId解析
在Spark的存储体系中,数据的读写是以block为单位的,这是用户的操作单位,一个Block对应一块内存
每个block都有唯一的标识,Spark把这个标识抽象成BlockId,blockId有多个实现类,表示为
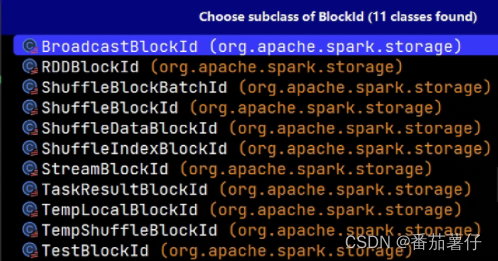
大致可以服务于Shuffle、RDD、Broadcast、TaskReuslt、Stream等
BlockInfo解析
BlockInfo是对一个Block元信息的记录,可以方便跟踪blockid的一些基本数据,该类由三个变量描述:
- level:块的期望存储等级,不代表实际的存储情况。而这个就是
StorageLevel - classTag:块的类标签
- tellMaster:是否要将该块的元信息告知Master
- size:这个块的尺寸
- readerCount:该块已锁定用于read的次数
- writerTask:当前持有该块写锁的TaskID
BlockManager解析
Spark中使用BlockManager块来管理当前节点内存和磁盘的数据块,Driver和Executor节点都会创建BlockManager。 块管理器负责数据的读写请求,删除等操作,并向Driver节点注册,汇报其所管理的数据块元数据信息(如果是Driver节点的块管理器,则整个注册过程无需网络通信,如果是Executor节点的块管理器注册,则需要与Driver节点进行网络通信)。当节点需要的数据块不在本地时,块管理器会首先通过Driver节点获取到持有所需数据块的节点,然后直接与该节点进行通信,完成数据的传输。其中涉及到的通信(不论是网络通信还是本地通信),都是通过Spark的RPC框架实现的
BlockManager的组件
-
MemoryStore 负责内存数据的读写操作。MemoryStore用来将数据块以序列化/非序列化的形式保存到内存中,以及从内存中获取数据块。当内存空间不足时,MemoryStore会将内存中的数据块迁移到磁盘中。
-
DiskStore负责磁盘数据的读写操作。DiskStore用来将数据块存储到磁盘上,以及从磁盘上获取数据块。如果数据块的存储级别配置了磁盘,则当内存不足时,Spark会将数据块从内存移动到磁盘上。
在新建DiskStore时,会传入DiskBlockManager实例,DiskBlockManager主要用来创建和维护逻辑数据块和磁盘实际存储的物理位置的映射关系。
-
BlockTransferService 这里mapOutputTracker与其他的BlockManger连接成功后,负责进行数据的传输,方法如下:
- 从其他Executor获取数据块的方法
fetechBlocks - 响应其他Executor的请求,将数据块返回给请求的Executor。
uploadBlock
- 从其他Executor获取数据块的方法
-
mapOutputTracker。 shuffle输出的时候,要记录shufflemaptask的输出位置,以供下一个Stage使用,因此需要进行记录
-
DiskBlockManager。DiskBlockManager用来创建并维护逻辑数据块和磁盘实际存储的物理位置的映射关系。数据块会被保存到以BlockId为名字的文件中。数据块文件会被hash到spark.local.dir所配置的目录。
BlockManager创建的时机
Driver端
在Driver的创建环境SparkEnv的时候创建
Executor端
val blockManager = new BlockManager(
executorId,
rpcEnv,
blockManagerMaster,
serializerManager,
conf,
memoryManager,
mapOutputTracker,
// shuffleManager是在SparkEnv中创建的,将shuffleManager传入到BlockManager,BlockManager就拥有shuffleManager的成员变量,
// 从而可以调用shuffleManager的相关方法
shuffleManager,
blockTransferService,
securityManager,
externalShuffleClient)
可以看到在创建blockManager的时候,传入了blockManagerMaster的参数,memoryManager,mapOutputTracker,(实现是UnifiedMemoryManager)以及blockTransferService的与块管理相关的参数。接下来的篇幅会讲解这几个部分
然后回到SparkContext,在这里执行了
_env.blockManager.initialize(_applicationId)
表示带着应用ID来注册blockManager.点进去方法里面,
def initialize(appId: String /** 应用id **/): Unit = {
// 调用blockTransferService的init方法,blockTransferService用于在不同节点fetch数据,传送数据
// 初始化BlockTransferService
blockTransferService.init(this)
externalBlockStoreClient.foreach { blockStoreClient =>
// 用于读取其他Executor上的shuffle files
// 初始化ShuffleClient
blockStoreClient.init(appId)
}
blockReplicationPolicy = {
val priorityClass = conf.get(config.STORAGE_REPLICATION_POLICY)
val clazz = Utils.classForName(priorityClass)
val ret = clazz.getConstructor().newInstance().asInstanceOf[BlockReplicationPolicy]
logInfo(s"Using $priorityClass for block replication policy")
ret
}
// 创建BlockManagerId
val id =
BlockManagerId(executorId, blockTransferService.hostName, blockTransferService.port, None)
// 向blockManagerMaster注册BlockManager,在registerBlockManager方法中传入了slaveEndpoint,slaveEndpoint为BlockManager
// 中的RPC对象,用于和blockManagerMasater通信
val idFromMaster = master.registerBlockManager(
id,
diskBlockManager.localDirsString,
maxOnHeapMemory,
maxOffHeapMemory,
storageEndpoint ) // 这个消息循环体来接收Driver中BlockManagerMaster的信息
// 得到shuffleManageId
blockManagerId = if (idFromMaster != null) idFromMaster else id
// 得到shuffleServerId
shuffleServerId = if (externalShuffleServiceEnabled) {
logInfo(s"external shuffle service port = $externalShuffleServicePort")
BlockManagerId(executorId, blockTransferService.hostName, externalShuffleServicePort)
} else {
blockManagerId
}
// Register Executors' configuration with the local shuffle service, if one should exist.
// 注册shuffleserver
// 如果存在,将注册Executors配置与本地shuffle服务
if (externalShuffleServiceEnabled && !blockManagerId.isDriver) {
registerWithExternalShuffleServer()
}
...
logInfo(s"Initialized BlockManager: $blockManagerId")
}
就是执行如下步骤:
- 初始化BlockTransferService
blockTransferService.init(this),这个类是用来进行网络连接获取远程数据的 master.registerBlockManager向BlockManagerMaster注册,这个时候BlockManagerMaster会为该BlockManager创建对应的BlockManagerInfo,BlockManagerInfo管理集群中每个Executor的BlockManager元数据,并存储到BlockStatus中- …
Executor端
当Worker节点中启动ExecutorRunner时,ExecutorRunner中会启动CoarseGrainedExecutorBackend进程, 在CoarseGrainedExecutorBackend的onStart方法中,向Driver发出RegisterExecutor注册请求
然后Driver接受RegisterExecutor并注册Executor, CoarseGrainedExecutorBackend接受到成功注册的回应之后, 向自己发送RegisteredExecutor, 并且启动Executor的类
在这里Executor的类中,最终执行了以下初始化blockManager的方法
env.blockManager.initialize(conf.getAppId)
BlockManagerMaster解析
BlockManagerMaster是BlockManager的组件,BlockManager通过其来与Driver进行通信,完成向Driver注册BlockManager,从Driver获取数据块的位置信息,定时向Driver同步BlockManager所管理的数据块信息,响应Driver发来的删除数据块的请求等。
Driver和Executor节点都会创建自己的BlockManagerMaster,区别是Driver自身BlockManager中的BlockManagerMaster与Driver通信时,不产生网络通信。而Executor节点中的BlockManagerMaster与Driver通信时,会产生网络通信。
Executor任何的BlockManagerMaster所做的动作都是去driver做的,所以Executor的BlockManagerMaster说白了还只是用来跟driver通信而已。关键能做动作的比如(updateBlockInfo、getLocations、removeBlock)还是需要各方exeuctor的block通知给driver端去执行命令!!!
BlockManagerMasterEndpoint
BlockManagerMasterEndpoint是RpcEndpoint的一个具体实现类,就是上文中BlockManagerMaster所持有的RpcEndpointRef的具体指向类,是Driver的BlockManager处理来自Executor请求,以及向Executor发送请求的逻辑。来自Executor的请求/向Executor发送的请求与BlockManagerMaster发送和响应的相同,主要为注册Executor的BlockManager,返回所保存的数据块的位置信息,接收并更新Executor发送过来的数据块信息,向Executor发送删除数据块的请求等。
在BlockManagerMasterEndpoint中维护了注册的BlockManager,BlockManager和Executor的映射关系,数据块所在的位置等信息。这些都可以看做是存储相关的元数据信息。Driver节点通过保存这些元数据来管理整个集群的存储。
BlockManagerMasterEndpoint的方法
receiveAndReply
根据来自Executor不同的请求,调用相关函数并回调请求回调函数,比如
case RegisterBlockManager(id, localDirs, maxOnHeapMemSize, maxOffHeapMemSize, endpoint) =>
context.reply(register(id, localDirs, maxOnHeapMemSize, maxOffHeapMemSize, endpoint))
还有其他的方法比如
updateBlockInfoGetLocationsAndStatus(blockId, requesterHost)根据blockId, requesterHost位置返回存他们BlockManagerId的位置和blockid的状态GetLocations(blockId)首先判断内存缓存结构blockLocations中是否包含blockId,如果已包含,就获取位置信息,否则返回空的信息GetLocationsMultipleBlockIds(blockIds)获取存放一堆blockIds的blockmanagerId的位置GetPeers(blockManagerId)获取给定块管理器的对等方列表GetExecutorEndpointRef(executorId)返回用于发送 RPC 消息的 BlockManagerReplicaEndpoint 的 RpcEndpointRefGetMemoryStatus返回从块管理器 ID 到最大内存和剩余内存的映射GetStorageStatus使用一组初始块创建存储状态,而不修改源GetBlockStatus(blockId, askSlaves)返回所有块管理器的块状态(如果有)。注意:这是一项可能代价高昂的操作,应仅用于测试。如果 askStorageEndpoint 为 true,则主节点将查询每个块管理器以获取最新的块状态。当所有块管理器未通知主节点给定块时,这很有用。GetMatchingBlockIds(filter, askSlaves)RemoveRdd(rddId)首先删除给定 RDD 的元数据,然后从storage endpoint中异步删除块。RemoveShuffle(shuffleId)移除所有属于特定随机shuffle的blockRemoveBroadcast(broadcastId, removeFromDriver)移除所有属于特定随机broadcast的blockRemoveBlock(blockId)从具有该块的storage endpoint中删除该块。这只能用于删除主节点知道的块RemoveExecutor(execId)从driver endpoint中删除失效的executor。这仅在driver endpoint调用StopBlockManagerMasterBlockManagerHeartbeat(blockManagerId)HasCachedBlocks(executorId)
存取block的过程
以ResultTask为例
Executor端存储block的执行流程
在Executor.run的方法中,任务执行完会形成任务结果,这个任务结果是准备发送给TaskSetManager的,任务结果会根据结果的大小来判断是否需要变成indirectTaskResult对象,这里的IndirectTaskResult对象中包含结果所在的BlockId,在SchedulerBackend中可以通过BlockManager获得该BlockId对应的结果数据
在这个过程中执行了如下
val blockId = TaskResultBlockId(taskId)
env.blockManager.putBytes(
blockId,
new ChunkedByteBuffer(serializedDirectResult.duplicate()),
StorageLevel.MEMORY_AND_DISK_SER)
logInfo(s"Finished $taskName. $resultSize bytes result sent via BlockManager)")
// 返回元数据ser.serialize(new IndirectTaskResult[Any](blockId, resultSize))
ser.serialize(new IndirectTaskResult[Any](blockId, resultSize))
过程中清晰的看出了,通过用taskId来创建TaskResultBlockId,然后将串行化之后的信息通过blockManager.putBytes的方法放进blockManager中,而且用到的存储级别是MEMORY_AND_DISK_SER
在方法内部调用了blockStoreUpdater.save(),详细看doPut方法
private def doPut[T](
blockId: BlockId,
level: StorageLevel,
classTag: ClassTag[_],
tellMaster: Boolean,
keepReadLock: Boolean)(putBody: BlockInfo => Option[T]): Option[T] = {
...
val putBlockInfo = {
val newInfo = new BlockInfo(level, classTag, tellMaster)
// lockNewBlockForWriting写入一个新的块前先尝试获得适当的锁,如果我们是第一个写块,获得写入锁后继续后续操作。
// 否则,如果另一个线程已经写入块,须等待写入完成,才能获取读取锁,调用new()函数创建一个BlockInfo赋值给putBlockInfo,
// 然后通过putBody(putBlockInfo)将数据存入。putBody是一个匿名函数,输入BlockInfo,输出的是一个泛型Option[T]。
// putBody函数体内容是doPutIterator方法(doPutBytes方法也类似调用doPut)调用doPut时传入。
if (blockInfoManager.lockNewBlockForWriting(blockId, newInfo)) {
newInfo
} else {
...
}
return None
}
}
...
val result: Option[T] = try {
val res = putBody(putBlockInfo)
...
res
} catch {
...
} finally {
...
}
}
...
result
}
-
val newInfo = new BlockInfo(level, classTag, tellMaster)创建putBlockInfo,在其中需要用用锁 -
通过putBody(putBlockInfo)将数据存入
-
putBody是一个匿名函数,其在
BlockManager.save()中定义,如下info => val startTimeNs = System.nanoTime() // Since we're storing bytes, initiate the replication before storing them locally. // This is faster as data is already serialized and ready to send. val replicationFuture = if (level.replication > 1) { Future { // This is a blocking action and should run in futureExecutionContext which is a cached // thread pool. replicate(blockId, blockData(), level, classTag) }(futureExecutionContext) } else { null } if (level.useMemory) { // Put it in memory first, even if it also has useDisk set to true; // We will drop it to disk later if the memory store can't hold it. val putSucceeded = if (level.deserialized) { saveDeserializedValuesToMemoryStore(blockData().toInputStream()) } else { saveSerializedValuesToMemoryStore(readToByteBuffer()) } if (!putSucceeded && level.useDisk) { logWarning(s"Persisting block $blockId to disk instead.") saveToDiskStore() } } else if (level.useDisk) { saveToDiskStore() } val putBlockStatus = getCurrentBlockStatus(blockId, info) val blockWasSuccessfullyStored = putBlockStatus.storageLevel.isValid if (blockWasSuccessfullyStored) { // Now that the block is in either the memory or disk store, // tell the master about it. info.size = blockSize if (tellMaster && info.tellMaster) { reportBlockStatus(blockId, putBlockStatus) } addUpdatedBlockStatusToTaskMetrics(blockId, putBlockStatus) } logDebug(s"Put block ${blockId} locally took ${Utils.getUsedTimeNs(startTimeNs)}") if (level.replication > 1) { // Wait for asynchronous replication to finish try { ThreadUtils.awaitReady(replicationFuture, Duration.Inf) } catch { case NonFatal(t) => throw new SparkException("Error occurred while waiting for replication to finish", t) } } if (blockWasSuccessfullyStored) { None } else { Some(blockSize) } }.isEmpty
在过程中执行如下:
-
val replicationFuture = if (level.replication > 1) {}如果level中显示复制数>1,那么执行replicate()方法,将这个block复制到其他block。详细如下:
val initialPeers = getPeers(false).filterNot(existingReplicas.contains),去blockManagerMaster那里拉取peer block managers的var peersForReplication = blockReplicationPolicy.prioritize对block的一组peeers进行优先级排序blockTransferService.uploadBlockSync即上传复制的block数据到其他的节点中
-
if (level.useMemory)判断是否使用memory。即使设置了使用Disk,也是首先使用内存,如果内存无法存储,才放到Disk中。val putSucceeded = if (level.deserialized) { saveDeserializedValuesToMemoryStore(blockData().toInputStream()) } else { saveSerializedValuesToMemoryStore(readToByteBuffer()) } if (!putSucceeded && level.useDisk) { logWarning(s"Persisting block $blockId to disk instead.") saveToDiskStore() }方法非常直观,比如说存储串行数据到memoryStore中,则执行
saveSerializedValuesToMemoryStoreprivate def saveSerializedValuesToMemoryStore(bytes: ChunkedByteBuffer): Boolean = { val memoryMode = level.memoryMode memoryStore.putBytes(blockId, blockSize, memoryMode, () => { if (memoryMode == MemoryMode.OFF_HEAP && bytes.chunks.exists(!_.isDirect)) { bytes.copy(Platform.allocateDirectBuffer) } else { bytes } }) }重点在于
memoryStore.putBytes。看到这里,其实就很明白blockManager.puteBytes()最终还是执行了memoryStore或者diskStore的putBytesdef putBytes[T: ClassTag]( blockId: BlockId, size: Long, memoryMode: MemoryMode, _bytes: () => ChunkedByteBuffer): Boolean = { require(!contains(blockId), s"Block $blockId is already present in the MemoryStore") if (memoryManager.acquireStorageMemory(blockId, size, memoryMode)) { // 为这个快获得了足够的内存,所以把它放进去 // We acquired enough memory for the block, so go ahead and put it val bytes = _bytes() assert(bytes.size == size) val entry = new SerializedMemoryEntry[T](bytes, memoryMode, implicitly[ClassTag[T]]) entries.synchronized { entries.put(blockId, entry) } logInfo("Block %s stored as bytes in memory (estimated size %s, free %s)".format( blockId, Utils.bytesToString(size), Utils.bytesToString(maxMemory - blocksMemoryUsed))) true } else { false }putBytes方法重点在于-
memoryManager.acquireStorageMemory(blockId, size, memoryMode)从UnifiedMemoryManager中获取StorageMemory。这里的步骤我在上一篇已经提到了,串起来了!【读懂面经中的源码】SPARK源码解析——内存管理机制_番茄薯仔的博客-CSDN博客。如何通过内存管理来动态获取Storage的过程非常精彩,有兴趣的同学可以去了解一下! -
那分配到内存之后,就要将这个东西存储下来了。
val entry = new SerializedMemoryEntry[T](bytes, memoryMode, implicitly[ClassTag[T]]) entries.synchronized { entries.put(blockId, entry) }这就很有趣了,其实BlockManager存储的块是通过LinkedHashMap来管理的。
-
-
至此,memoryStore已经存放完block内容。如果内存不够,返回到BlockManager中,它执行了如下方法
if (!putSucceeded && level.useDisk) { logWarning(s"Persisting block $blockId to disk instead.") saveToDiskStore() }进入saveToDiskStore()中,发现执行
diskStore.putBytes(blockId, bytes),其实就是利用java.nio来写磁盘了 -
reportBlockStatus(blockId, putBlockStatus)把这个blockStatus发送到driver端的,用blockManagerInfo来包装,Driver的blockmanagerInfo因此做统计信息的更新
返回Executor.run,已经把block存储至blockManager之后,就会执行execBackend.statusUpdate(taskId, TaskState.FINISHED, serializedResult)将执行的结果反馈给CoarseGrainedSchedulerBackend.receive()。
driver端的获取block的执行流程
在这里CoarseGrainedSchedulerBackend.receive()接受executor发来的信息开始看起
调用scheduler.statusUpdate(taskId, state, data.value)更新状态信息。在方法内部执行了taskResultGetter.enqueueSuccessfulTask(taskSet, tid, serializedData)处理task完成的信息,那方法内部主要是这个部分
case IndirectTaskResult(blockId, size) => // 就通过blockManager.getRemoteBytes远程获取,获取以后再进行反序列化
if (!taskSetManager.canFetchMoreResults(size)) {
// dropped by executor if size is larger than maxResultSize
sparkEnv.blockManager.master.removeBlock(blockId)
// kill the task so that it will not become zombie task
scheduler.handleFailedTask(taskSetManager, tid, TaskState.KILLED, TaskKilled(
"Tasks result size has exceeded maxResultSize"))
return
}
logDebug(s"Fetching indirect task result for ${taskSetManager.taskName(tid)}")
scheduler.handleTaskGettingResult(taskSetManager, tid)
val serializedTaskResult = sparkEnv.blockManager.getRemoteBytes(blockId)
if (serializedTaskResult.isEmpty) {
/* We won't be able to get the task result if the machine that ran the task failed
* between when the task ended and when we tried to fetch the result, or if the
* block manager had to flush the result. */
// 如果运行任务的机器在任务结束和我们试图获取任务结果之间发生故障,或者区块管理器必须刷新结果,我们将无法获取任务结果。
scheduler.handleFailedTask(
taskSetManager, tid, TaskState.FINISHED, TaskResultLost)
return
}
val deserializedResult = serializer.get().deserialize[DirectTaskResult[_]](
serializedTaskResult.get.toByteBuffer)
// force deserialization of referenced value
deserializedResult.value(taskResultSerializer.get())
sparkEnv.blockManager.master.removeBlock(blockId)
(deserializedResult, size)
}
很直观,就是接受了之前在Executor发送的IndirectTaskResult(blockId, size)对象
然后val serializedTaskResult = sparkEnv.blockManager.getRemoteBytes(blockId)来根据blockId远程获取序列化的任务执行结果,这些结果先前已经在远处的executor通过blockManager存储成功了。
def getRemoteBytes(blockId: BlockId): Option[ChunkedByteBuffer] = {
getRemoteBlock(blockId, (data: ManagedBuffer) => {
// SPARK-24307 undocumented "escape-hatch" in case there are any issues in converting to
// ChunkedByteBuffer, to go back to old code-path. Can be removed post Spark 2.4 if
// new path is stable.
if (remoteReadNioBufferConversion) {
new ChunkedByteBuffer(data.nioByteBuffer())
} else {
ChunkedByteBuffer.fromManagedBuffer(data)
}
})
}
这是driver端的获取远处block的方法,点击进去查看代码:
private[spark] def getRemoteBlock[T](
blockId: BlockId,
bufferTransformer: ManagedBuffer => T): Option[T] = {
logDebug(s"Getting remote block $blockId")
require(blockId != null, "BlockId is null")
// Because all the remote blocks are registered in driver, it is not necessary to ask
// all the storage endpoints to get block status.
// 因为所有的远程块都注册在driver中,所以不需要要求所有的从执行器获取块状态
// 去driver那里获取地址和状态
val locationsAndStatusOption = master.getLocationsAndStatus(blockId, blockManagerId.host)
if (locationsAndStatusOption.isEmpty) {
logDebug(s"Block $blockId is unknown by block manager master")
None
} else {
val locationsAndStatus = locationsAndStatusOption.get
val blockSize = locationsAndStatus.status.diskSize.max(locationsAndStatus.status.memSize)
locationsAndStatus.localDirs.flatMap { localDirs =>
val blockDataOption =
readDiskBlockFromSameHostExecutor(blockId, localDirs, locationsAndStatus.status.diskSize)
val res = blockDataOption.flatMap { blockData =>
try {
Some(bufferTransformer(blockData))
} catch {
case NonFatal(e) =>
logDebug("Block from the same host executor cannot be opened: ", e)
None
}
}
logInfo(s"Read $blockId from the disk of a same host executor is " +
(if (res.isDefined) "successful." else "failed."))
res
}.orElse {
fetchRemoteManagedBuffer(blockId, blockSize, locationsAndStatus).map(bufferTransformer)
}
}
}
这个方法主要关注以下的内容:
-
val locationsAndStatusOption = master.getLocationsAndStatus(blockId, blockManagerId.host)因为所有的远程块都注册在driver中,所以不需要要求所有的从执行器获取块状态,这个方法就是去driver那里获取地址和状态。然后在Driver的BlockManagerMasterEndpoint执行getLocationsAndStatus获取这个blockId对应的blockManager地址和状态 -
带着这些位置和状态去localDirs来获取本地的blockManager,执行
readDiskBlockFromSameHostExecutor。但在Result的场景中,result存放在了executor中,所以需要远端拿取block。即执行了如下的方法的了fetchRemoteManagedBuffer(blockId, blockSize, locationsAndStatus).map(bufferTransformer),代码如下:private def fetchRemoteManagedBuffer( blockId: BlockId, blockSize: Long, locationsAndStatus: BlockManagerMessages.BlockLocationsAndStatus): Option[ManagedBuffer] = {s // 如果块大小超过阈值,将FileManager传递给BlockTransferService,利用它来溢出块;如果没有,传递空值意味着块将持久存在内存中。 val tempFileManager = if (blockSize > maxRemoteBlockToMem) { remoteBlockTempFileManager } else { null } var runningFailureCount = 0 var totalFailureCount = 0 // sortLocations方法返回给定块的位置列表,本地计算机的优先级从多个块管理器可以共享同一个主机,然后是同一机架上的主机 val locations = sortLocations(locationsAndStatus.locations) val maxFetchFailures = locations.size var locationIterator = locations.iterator while (locationIterator.hasNext) { val loc = locationIterator.next() logDebug(s"Getting remote block $blockId from $loc") val data = try { // 调用blockTransferService.fetchBlockSync方法实现远程获取数据 val buf = blockTransferService.fetchBlockSync(loc.host, loc.port, loc.executorId, blockId.toString, tempFileManager) if (blockSize > 0 && buf.size() == 0) { throw new IllegalStateException("Empty buffer received for non empty block") } buf } catch { case NonFatal(e) => runningFailureCount += 1 totalFailureCount += 1 // 放弃尝试的位置。要么我们已经尝试了所有的原始位置,或者我们已经从master节点刷新了位置列表,并且仍然在刷新列表中尝试位置后命中失败 if (totalFailureCount >= maxFetchFailures) { logWarning(s"Failed to fetch block after $totalFailureCount fetch failures. " + s"Most recent failure cause:", e) return None } // 如果有大量的 Executors,那么位置列表可以包含一个旧的条目造成大量重试,可能花费大量的时间。 // 在一定数量的获取失败之后,为去掉这些旧的条目,我们刷新块位置 if (runningFailureCount >= maxFailuresBeforeLocationRefresh) { // 如果有大量执行者,则位置列表可以包含大量过时的条目导致大量重试,可能花大量的时间。除去这些陈旧的条目,在一定数量的提取失败后刷新块位置 locationIterator = sortLocations(master.getLocations(blockId)).iterator logDebug(s"Refreshed locations from the driver " + s"after ${runningFailureCount} fetch failures.") runningFailureCount = 0 } // This location failed, so we retry fetch from a different one by returning null here // 此位置失败,所以我们尝试从不同的位置获取,这里返回一个 null null } if (data != null) { assert(!data.isInstanceOf[BlockManagerManagedBuffer]) return Some(data) } logDebug(s"The value of block $blockId is null") } logDebug(s"Block $blockId not found") None }主要执行的步骤如下:
val locations = sortLocations(locationsAndStatus.locations)。sortLocations按照主机->同一机架主机的顺序来排序,返回这些节点的列表- 然后调用
blockTransferService.fetchBlockSync方法实现远程获取数据,点进去方法,实际上就是执行了NettyBlockTransferService.fetechBlocks的方法
删除block的过程
举个例子,当ExecutorMemory要扩增的时候,如果executor内存不够,那么就要往storage的位置要空间,使用StorageMemoryPool.acquireMemory进行,memoryStore.evictBlocksToFreeSpace(Some(blockId), numBytesToFree, memoryMode)代码表示storage空间删除block
def dropBlock[T](blockId: BlockId, entry: MemoryEntry[T]): Unit = {
val data = entry match {
case DeserializedMemoryEntry(values, _, _) => Left(values)
case SerializedMemoryEntry(buffer, _, _) => Right(buffer)
}
val newEffectiveStorageLevel =
blockEvictionHandler.dropFromMemory(blockId, () => data)(entry.classTag)
if (newEffectiveStorageLevel.isValid) {
// The block is still present in at least one store, so release the lock
// but don't delete the block info
blockInfoManager.unlock(blockId)
} else {
// The block isn't present in any store, so delete the block info so that the
// block can be stored again
blockInfoManager.removeBlock(blockId)
}
}
看看这里看了什么,blockEvictionHandler.dropFromMemory(blockId, () => data)(entry.classTag)就是在这里根据storagelevel来删除block,如果storagelevel需要磁盘存储的话,就在这里将内存以转移至diskStore,即diskStore.putBytes(blockId, bytes)
然后开始从memoryStore删除这个block,val blockIsRemoved = memoryStore.remove(blockId),在里面实际上就是使用entries.remove(blockId)。
然后获取这个block当前的status,判断状态tellMaster是否为true,如果是的话,就将信息告诉master更新。具体执行的代码如BlockManager.tryToReportBlockStatus->master.updateBlockInfo->driverEndpoint.askSync[Boolean](UpdateBlockInfo..)->在driver端的BlockManagerMasterEndpoint执行更换关于这个blockmanager里面的blockId的信息更新一下下。
返回到MemoryStore.dropBlock的位置,如果所有的block都删除,那么就使用blockInfoManager.removeBlock(blickId),不再记录这个block的
总结
好了,到了这个时候,已经知道Spark中BlockManager是怎么管理的了,里面涉及到几个类,比如BlockInfoManager、BlockManager、BlockManagerMaster、BlockManagerMasterEndpoint等。如何深入理解它们最好还是找一个存取block的过程例子去理解比较好。
在写各个组件流程的时候,可能会遗漏掉一些也很关键的介绍,欢迎各位同学批评指正!!我会改正的!















 341
341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









