






本次为各位同学准备的是Spark高频八股–broadcast机制~
创作不易!多多支持!
面筋
面筋来源:公众号旧时光大数据
Spark广播变量的实现和原理
广播变量可以让用户在每台计算机上保留一个只读变量,而不是为每个任务复制一份副本。例如,可以使用他们以高效的方式为每个计算节点提供大型输入数据集的副本。Spark也尽量使用有效的广播算法来分发广播变量,以减少通信成本。
另外,Spark action操作会被划分成一系列的stage来执行,这些stage根据是否产生shuffle操作来进行划分的。Spark会自动广播每个stage任务需要的通用数据。这些被广播的数据以序列化的形式缓存起来,然后在任务执行前进行反序列化。
也就是说,在以下两种情况下显示的创建广播变量才有用:
- 当任务跨多个stage并且需要同样的数据时
- 当以反序列化的形式来缓存数据时
Spark广播变量的特性:
- 广播变量会在每个worker节点上保留一个副本,而不是为每个Task保留副本。这样会节省网络和本地存储资源
- Spark会通过某种广播算法来进行广播变量的分发,这样可以减少通信成本。Spark使用了类似BitTorrent协议的数据分发蒜贩来进行广播变量的数据分发
- 广播变量有一定的适用场景,当任务跨多个stage,且需要同样的数据时,或以反序列化的形式来缓存数据时
广播变量的创建和适用
scala> val v = Array(1,2,3,4,5,6)
v: Array[Int] = Array(1, 2, 3, 4, 5, 6)
scala> val bv = sc.broadcast(v)
res1: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(1)
scala> bv
res9: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(2)
// 获取广播变量的值
scala> bv.value
res10: Array[Int] = Array(1, 2, 3, 4, 5, 6)
// 销毁广播变量
scala> bv.destory
注意,在创建广播变量时,广播变量的值必须是本地的可序列化的值,不能是RDD
另外,广播变量一旦被创建就不应该再修改,这样可以保证所有的worker的节点的值都是一致的,这是因为,现有worker将看不到更新的值,新的worker才可能会看到新的值
广播变量的实现原理
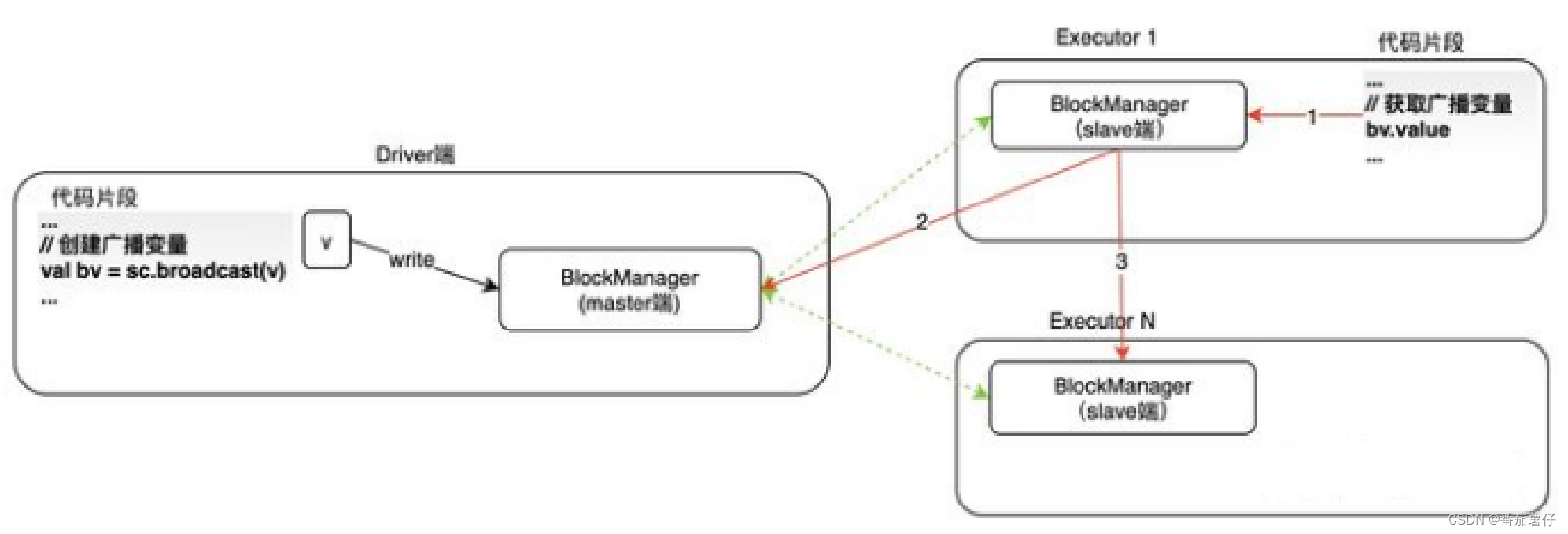
广播变量的创建
广播变量的创建发生在Driver端,如图2所示,当调用SparkContext#broadcast来创建广播变量时,会把
该变量的数据切分成多个数据块,保存到driver端的BlockManger中,使用的存储级别是:
MEMORY_AND_DISK_SER。
所以,广播变量的读取也是懒评价的,只有在Executor端需要获取广播变量时才会去获取。此时广播变量的数据只在Driver端存在。
此时的状态如下图所示:

从上图可以看出,此时广播变量被保存在本地,并会把广播变量的值切分成多个数据块进行保存。广播变量数据块的默认大小是4m
广播变量的读取
当要使用广播变量时,需要先获取广播变量的值,其实现流程如下图所示。获取广播变量调用的是bv.value。
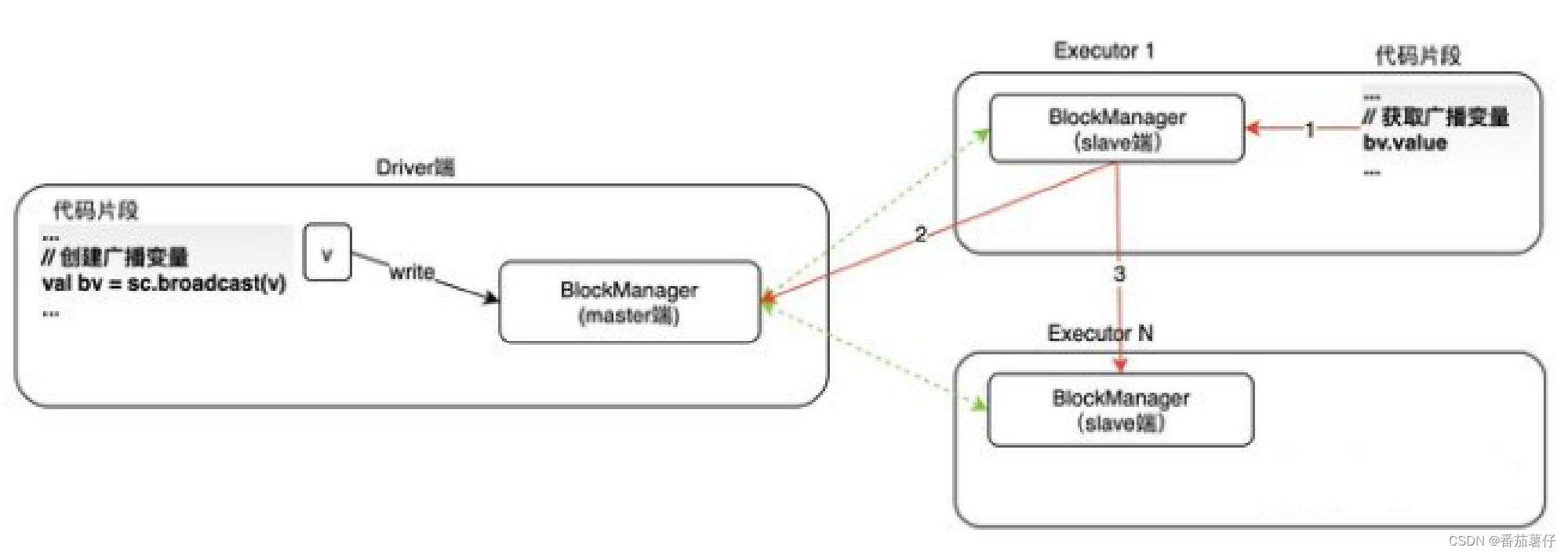
逻辑如下:
- 第一步(红色线1):首先Executor本地的BlockManager中读取广播变量的数据,若存在就直接获取,并返回。不再执行第2步和第3步。若不存在,则执行第2步。
- 第2步(红色线2):从Driver端获取广播变量的状态和位置信息(由于所有的BlockManager slave端)都会向Master端汇报数据块状态
- 第3步:优先从本地目录(数据块就在本地),或者相同主机的其他Executor中读取广播变量数据块。若再本地Exeuctor和同主机其他Executor中都不存在,则只能从远端获取数据。从远端获取数据的原则是:先从同一机架(rack)的主机和Executor端获取。若不能从其他Executor中获取广播变量,则会直接从Driver端获取。
从以上获取流程可以看出,在执行spark应用时,只要有一个worker节点的executor从driver端获取到了广播变量的数据,则其他的executor就不需要从driver端获取了。
当某个executor上的某个数据块被删除,可以从其他executor直接获取该数据块,然后把数据块保存到自己的executor的blockmanager中
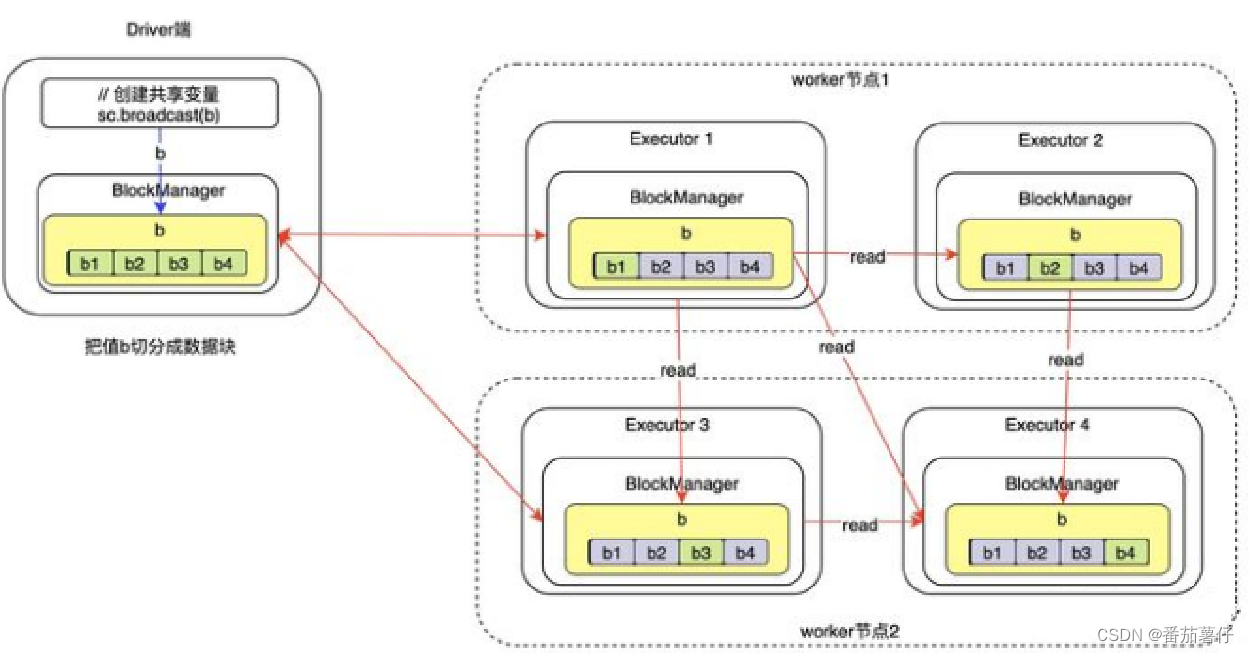
从上图可以看出,executor4中的任务需要使用广播变量,但它只有该变量的b4数据块。此时,它首先从同主机(worker2节点)的中获取数据,获取到数据块b3;然后分别从不同主机的executor1和executor2中读取数据块b1和b2.此时,executor4就获取到变量b的全部数据块了,然后把这些数据块在自己的blockmanager中保存一份。此时,其他executor就可以从executor4中读取数据了。
当完成这些操作后,各个executor端的blockmanager(worker端)会向driver端的blockmanager(masetr端)汇报这些数据块的状态
广播变量的创建和使用
来看看Spark自带的官方样例
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.appName("Multi-Broadcast Test")
.master("local[*]")
.getOrCreate()
val slices = if (args.length > 0) args(0).toInt else 2
val num = if (args.length > 1) args(1).toInt else 1000000
val arr1 = new Array[Int](num)
for (i <- 0 until arr1.length) {
arr1(i) = i
}
val arr2 = new Array[Int](num)
for (i <- 0 until arr2.length) {
arr2(i) = i
}
val barr1 = spark.sparkContext.broadcast(arr1)
val barr2 = spark.sparkContext.broadcast(arr2)
val observedSizes: RDD[(Int, Int)] = spark.sparkContext.parallelize(1 to 10, slices).map { _ =>
(barr1.value.length, barr2.value.length)
}
// Collect the small RDD so we can print the observed sizes locally.
observedSizes.collect().foreach(i => println(i))
spark.stop()
}
在这个程序中,首先定义了arr1和arr2,随后采用了spark.sparkContext.broadcast将这两个数组给广播起来,并通过map遍历两个广播变量的长度,最后collect输出结果。
广播变量创建流程
在val barr1 = spark.sparkContext.broadcast(arr1)点进去bradcast(arr1)的时候
def broadcast[T: ClassTag](value: T): Broadcast[T] = {
assertNotStopped()
require(!classOf[RDD[_]].isAssignableFrom(classTag[T].runtimeClass),
"Can not directly broadcast RDDs; instead, call collect() and broadcast the result.")
// 在这里创建了TorrentBroadcastFactory
// Spark 2.0版本中的TorrentBroadcast方式:数据开始在Driver中,A节点如果使用了数据,A就成为供应源,这时Driver节点、
// A节点两个节点成为供应源,如第三个节点B访问的时候,第三个节点B也成了供应源,同样地,第四个节点、第五个节点……
// 都成了供应源,这些都被BlockManager管理,这样不会导致一个节点压力太大,从理论上讲,数据使用的节点越多,
// 网络速度就越快。
val bc = env.broadcastManager.newBroadcast[T](value, isLocal)
val callSite = getCallSite
logInfo("Created broadcast " + bc.id + " from " + callSite.shortForm)
cleaner.foreach(_.registerBroadcastForCleanup(bc))
bc
}
再进去env.broadcastManager.newBroadcast[T](value, isLocal),最终执行的是broadcastFactory.newBroadcast[T](value_, isLocal, bid),在这里实际上创建的就是**TorrentBroadcast**
TorrentBroadcast按照BLOCK_SIZE(默认是4MB)将Broadcast中的数据划分成为不同的Block,然后将分块信息 (也就是Meta信息)存放到Driver的BlockManager中,同时会告诉BlockManagerMaster,说明Meta信息存放 完毕 。 TorrentBroadcast将元数据信息存放到BlockManager,然后汇报给BlockManagerMaster。数据存放到BlockManagerMaster中就变成了全局数据, BlockManagerMaster具有所有的信息,Driver、Executor就可以访问这些内容。Executor运行具体的TASK的时候, 通过TorrentBroadcast的方式readBlocks,如果本地有数据,就从本地读取,如果本地没有数据,就从远程读取数据。 Executor读取信息以后,通过TorrentBroadcast的机制通知BlockManagerMaster数据多了一份副本,下一个Task读取数据的时候, 就有两个选择,分享的节点越多, 下载的供应源就越多,最终变成点到点的方式。
点进去TorrentBroadcast类中,在里面执行了writeBlocks方法,实际上就是将对象划分为多个块,并将这些块放在块管理器中。方法如下:
private def writeBlocks(value: T): Int = {
import StorageLevel._
// Store a copy of the broadcast variable in the driver so that tasks run on the driver
// do not create a duplicate copy of the broadcast variable's value.
// 将广播变量的副本存储在driver中,以便在驱动程序上运行的任务
// 不会创建广播变量值的重复副本。
val blockManager = SparkEnv.get.blockManager
if (!blockManager.putSingle(broadcastId, value, MEMORY_AND_DISK, tellMaster = false)) {
throw new SparkException(s"Failed to store $broadcastId in BlockManager")
}
try {
val blocks =
TorrentBroadcast.blockifyObject(value, blockSize, SparkEnv.get.serializer, compressionCodec)
if (checksumEnabled) {
checksums = new Array[Int](blocks.length)
}
blocks.zipWithIndex.foreach { case (block, i) =>
if (checksumEnabled) {
checksums(i) = calcChecksum(block)
}
val pieceId = BroadcastBlockId(id, "piece" + i)
val bytes = new ChunkedByteBuffer(block.duplicate())
if (!blockManager.putBytes(pieceId, bytes, MEMORY_AND_DISK_SER, tellMaster = true)) {
throw new SparkException(s"Failed to store $pieceId of $broadcastId " +
s"in local BlockManager")
}
}
blocks.length
} catch {
case t: Throwable =>
logError(s"Store broadcast $broadcastId fail, remove all pieces of the broadcast")
blockManager.removeBroadcast(id, tellMaster = true)
throw t
}
}
总结来说就是执行了以下几步:
-
blockManager.putSingle(broadcastId, value, MEMORY_AND_DISK, tellMaster = false),这里将value的广播变量存放进去blockManager,存储级别是MEMORY_AND_DISK。那么这个方法继续往下点会发现最终会调用BlockManager#putIterator的方法。大概的步骤即先存放至内存空间,如果内存空间不够就用磁盘空间来存储,最后返回是否存储成功。
2.将广播的变量内切片,默认大小为4MB。blockManager.putBytes(pieceId, bytes, MEMORY_AND_DISK_SER, tellMaster = true)然后将这些切片后的内容存储到Driver的BlockManager中,同时BlockManager#reportBlockStatus会告诉BlockManagerMaster,说明Meta信息存放完毕 。 TorrentBroadcast将元数据信息存放到BlockManager,然后汇报给BlockManagerMaster。
广播变量读取流程
Executor运行具体的TASK的时候, 通过TorrentBroadcast的方式readBlocks,如果本地有数据,就从本地读取,如果本地没有数据,就从远程读取数据。 Executor读取信息以后,通过TorrentBroadcast的机制通知BlockManagerMaster数据多了一份副本,下一个Task读取数据的时候, 就有两个选择,分享的节点越多, 下载的供应源就越多,最终变成点到点的方式。
返回MulitiBroadcastTest中的
val observedSizes: RDD[(Int, Int)] = spark.sparkContext.parallelize(1 to 10, slices).map { _ =>
(barr1.value.length, barr2.value.length)
}
点进去barr1.value,里面主要有这些方法
override protected def getValue() = synchronized {
val memoized: T = if (_value == null) null.asInstanceOf[T] else _value.get
if (memoized != null) {
memoized
} else {
val newlyRead = readBroadcastBlock()
_value = new SoftReference[T](newlyRead)
newlyRead
}
}
意味着当Executor执行map算子的过程中,里面需要用到broadcast的内容,其中如果获取不到_value值,执行了TorrentBroadcast#getValue()方法。
在这个方法中主要看到了val newlyRead = readBroadcastBlock(),点进去看一下:
private def readBroadcastBlock(): T = Utils.tryOrIOException {
TorrentBroadcast.torrentBroadcastLock.withLock(broadcastId) {
// As we only lock based on `broadcastId`, whenever using `broadcastCache`, we should only
// touch `broadcastId`.
val broadcastCache = SparkEnv.get.broadcastManager.cachedValues
Option(broadcastCache.get(broadcastId)).map(_.asInstanceOf[T]).getOrElse {
setConf(SparkEnv.get.conf)
val blockManager = SparkEnv.get.blockManager
blockManager.getLocalValues(broadcastId) match {
case Some(blockResult) =>
if (blockResult.data.hasNext) {
val x = blockResult.data.next().asInstanceOf[T]
releaseBlockManagerLock(broadcastId)
if (x != null) {
broadcastCache.put(broadcastId, x)
}
x
} else {
throw new SparkException(s"Failed to get locally stored broadcast data: $broadcastId")
}
case None =>
val estimatedTotalSize = Utils.bytesToString(numBlocks * blockSize)
logInfo(s"Started reading broadcast variable $id with $numBlocks pieces " +
s"(estimated total size $estimatedTotalSize)")
val startTimeNs = System.nanoTime()
val blocks = readBlocks()
logInfo(s"Reading broadcast variable $id took ${Utils.getUsedTimeNs(startTimeNs)}")
try {
val obj = TorrentBroadcast.unBlockifyObject[T](
blocks.map(_.toInputStream()), SparkEnv.get.serializer, compressionCodec)
// Store the merged copy in BlockManager so other tasks on this executor don't
// need to re-fetch it.
val storageLevel = StorageLevel.MEMORY_AND_DISK
if (!blockManager.putSingle(broadcastId, obj, storageLevel, tellMaster = false)) {
throw new SparkException(s"Failed to store $broadcastId in BlockManager")
}
if (obj != null) {
broadcastCache.put(broadcastId, obj)
}
obj
} finally {
blocks.foreach(_.dispose())
}
}
}
}
}
具体实现如下:
-
从broadcastCache获取,如果获取不到,就开始下面的步骤
-
blockManager.getLocalValues(broadcastId)来获取executor本地block。如果获取到block,就返回这个block,并且把这个block放到缓存里面。 -
如果executor本地获取不到block,那么执行如下操作:
-
readBlocks()。从driver 或者其他exeuctor获取block。遍历blocks分片,如果本地有分片就获取分片,否则根据pieceId远程获取序列化block切片。使用
getRemoteBlock来获取远程切片。Spark会自动识别这个切片的远近来获取的,这样尽可能减少网络消耗。具体是locationsAndStatusOption = master.getLocationsAndStatus(blockId, blockManagerId.host)来获取这个blockId的存放的位置。如果在同一主机不同exeuctor上存在block,那么执行readDiskBlockFromSameHostExecutor,通过读取文件的形式来获取block;否则fetchRemoteManagedBuffer按距离优先(同一节点>同一机架->~~~)向远处获取的。 -
校验checksum来判断这个远处获取的block是否损坏。
-
如果获取到了这个分片,那么就将这个分片block存储到本地blockmanager中
bm.putBytes(pieceId, b, StorageLevel.MEMORY_AND_DISK_SER, tellMaster = true),并告诉driver端本地的blockmanager已经存储了这个分片。 -
存放broadcast缓存。
-
-
赋值
_value。这个值是由readBroadcastBlock重建的,在driver,如果需要该值,则会从blockamnager延迟读取该值。这个_value是一个软引用对象,随时会进行垃圾回收。
由此,broadcast的变量就可以被Executor读取成功了,整体流程还算简单。但是这个TorrentBroadcast的延迟获取的思想设计的非常棒,值得去深究!!!!!!
回顾–executor怎么知道broadcastId?
当executor在执行获取xxx.value()的时候,实际上执行的是TorrentBroadcast#getValue。
我们都知道TorrentBroadcast由driver创建,那么这个TorrentBroadcast是怎么传输至executor的呢?
回答:
实际上这个broadcast的信息是由BroadcastManager管理的,其中在broadcastFactory.newBroadcast[T](value_, isLocal, bid)创建完成。而BroadcastManager就是SparkEnv的类变量。
SparkEnv是由启动Executor通过传参传进来的。
那么Exeuctor又怎么启动呢???
具体表示就是:SparkContext启动后,StandaloneSchedulerBackend中会调用new()函数创建一个StandaloneAppClient, StandaloneAppClient中有一个名叫ClientEndPoint的内部类, 在创建ClientEndpoint时会传入Command来指定具体为当前应用程序启动的Executor进行的入口类的名称 为CoarseGrainedExecutorBackend。 ClientEndPoint继承自ThreadSafeRpcEndpoint,其通过RPC机制完成和Master的通信。 在ClientEndPoint的start方法中,会通过registerWithMaster方法向Master发送RegisterApplication请求, Master收到该请求消息后,首先通过registerApplication方法完成信息登记,之后将会调用schedule方法,在Worker上启动Executor。
所以,executor在执行的时候就可以知道broadcast的信息了。
除此之外,exeuctor还可以从SparkEnv中获取到driver的blockmanager、serializer、mapOutputTracker等。
这么一解释,好像又有点明白了是不是~~














 5824
5824











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









