







基于SPARK的淘宝用户购物行为可视化分析(调优版一)
经过上一篇文章的训练,我们已经完成了一定的数据分析,接下来,这篇文章我们将进行SPARK调优。希望在这三台虚拟机跑出好成绩!
服务器配置
单机配置:
- CPU:i5-12600KF
- 内存:32GB
创建3台虚拟机,配置如下:
| hadoop1102 | hadoop1103 | hadoop1104 | |
|---|---|---|---|
| CPU | 2处理器,共8内核 | 2处理器,共8内核 | 2处理器,共8内核 |
| 内存 | 8GB | 4GB | 3GB |
| 磁盘 | 50GB | 50GB | 50GB |
| HDFS | DataNode、NameNode | DataNode | DataNode、SecondaryNameNode |
| YARN | NodeManager | NodeManager、ResourceManager | NodeManager |
此外,还配置了zk、spark-hive等。软件版本设置如下…
- zookpeeper:3.5.7
- sqoop:1.4.6
- jdk:1.8
- scala:2.12
- hadoop:3.1.3
- spark:3.0.0
- hive:3.1.2
配置具体可参考尚硅谷大数据课程。
前置配置
启动hadoop、yarn
start-dfs.sh
start-yarn.sh
启动历史日志服务器,不然啥也看不了
mr-jobhistory-daemon.sh start historyserver
$SPARK_HOME/sbin/start-history-server.sh
随便试试
创建spark应用
object UserScoreAPP {
def main(args: Array[String]): Unit = {
val startTime = System.currentTimeMillis()
//1 初始化环境
val sparkConf: SparkConf = new SparkConf().setAppName("UserScoreAPP") //.setMaster("local[*]")
val sparkSession: SparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
sparkSession.sql("use taobao")
val sql =
s"""
|select user_id,
| case when recent_rank < 671043 * 1 / 4 then 4
| when recent_rank < 671043 * 2 / 4 then 3
| when recent_rank < 671043 * 3 / 4 then 2
| else 1 end +
| case when frequency_rank < 671043 * 1 / 4 then 4
| when frequency_rank < 671043 * 2 / 4 then 3
| when frequency_rank < 671043 * 3 / 4 then 2
| else 1 end
| as score
|from
| (
| select user_id, recent, dense_rank() over (order by recent asc) as recent_rank, frequency, dense_rank() over (order by frequency desc) as frequency_rank
| from (
| select user_id, datediff('2017-12-04', max(create_time)) as recent, count(behavior) frequency
| from dwd_user_behavior
| where behavior='buy'
| group by user_id
| ) t1
| ) rfm
|""".stripMargin
// sparkSession.sql(sql).explain("extended")
// 查看 RDD 的执行计划
// val rdd = sparkSession.sql(sql).rdd
// println(rdd.toDebugString)
// 调用 RDD 的算子进行计算
// rdd.foreach(println)
sparkSession.sql(sql).show()
val endTime = System.currentTimeMillis()
val elapsedTime = (endTime - startTime) / 1000.0
println(s"Execution time: ${elapsedTime}s")
}
}
然后使用maven对这个应用打包,上传至/opt/module/taobao/。
cd /opt/module/taobao/
vim go_spark.sh
文本如下
#!/bin/bash
spark-submit \
--class com.xuhaoran.analyze.UserScoreAPP \
--master yarn \
--deploy-mode cluster \
--driver-memory 1g \
/opt/module/taobao/taobao-1.0-SNAPSHOT-jar-with-dependencies.jar
chmod u+x go_spark.sh
./go_spark.sh
这时候,程序成功跑起来了。
点击url以开始分析
http://hadoop1103:8088/cluster/app/application_1681373698013_0022
成功跑通,显示如下:


运行时间130.774s,时间有点长啊!
为了方便调优学习,我把这一段sql代码转换成rdd代码,代码如下
object UserScoreRDDAPP {
def main(args: Array[String]): Unit = {
val startTime = System.currentTimeMillis()
//1 初始化环境
val sparkConf: SparkConf = new SparkConf().setAppName("UserScoreAPP") //.setMaster("local[*]")
val sparkSession: SparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
// sparkSession.sql("use taobao")
import sparkSession.implicits._
// Load the data and filter by 'buy' behavior
val behaviorRDD = sparkSession.table("taobao.dwd_user_behavior").rdd
.filter(row => row.getAs[String]("behavior") == "buy" && (row.getAs[String]("create_time") != null))
// Calculate recent and frequency for each user_id
val userRF = behaviorRDD
.map(row => (row.getAs[Long]("user_id"), (Timestamp.valueOf(row.getAs[String]("create_time")), 1)))
.reduceByKey((a, b) => (if (a._1.after(b._1)) a._1 else b._1, a._2 + b._2))
.map { case (userId, (maxDate, frequency)) =>
val recent = (Date.valueOf("2017-12-04").getTime - maxDate.getTime) / (24 * 3600 * 1000)
(userId, recent, frequency)
}
// Calculate recent_rank and frequency_rank for each user_id
val sortedRecent = userRF.sortBy(_._2).zipWithIndex.map { case (row, index) => (row._1, index + 1, row._3) }
val sortedFrequency = userRF.sortBy(-_._3).zipWithIndex.map { case (row, index) => (row._1, index + 1) }
val userRFM = sortedRecent
.map { case (userId, recentRank, _) => (userId, recentRank) }
.join(sortedFrequency)
// Calculate the final score for each user_id
val userScoreRDD = userRFM.map { case (userId, (recentRank, frequencyRank)) =>
val recentScore = if (recentRank < 671043 * 1 / 4) 4 else if (recentRank < 671043 * 2 / 4) 3 else if (recentRank < 671043 * 3 / 4) 2 else 1
val frequencyScore = if (frequencyRank < 671043 * 1 / 4) 4 else if (frequencyRank < 671043 * 2 / 4) 3 else if (frequencyRank < 671043 * 3 / 4) 2 else 1
(userId, recentScore + frequencyScore)
}
// Perform operations on RDD
userScoreRDD.foreach(println)
val endTime = System.currentTimeMillis()
val elapsedTime = (endTime - startTime) / 1000.0
println(s"Execution time: ${elapsedTime}s")
}
}
并打包至hadoop1102中,修改go_spark.sh脚本内容
#!/bin/bash
spark-submit \
--class com.xuhaoran.analyze.UserScoreRDDAPP \
--master yarn \
--deploy-mode cluster \
--driver-memory 1g \
/opt/module/taobao/taobao-1.0-SNAPSHOT-jar-with-dependencies.jar
运行时间198.998s,这比sql还长得多啊!!!
正因为有点长,所以也是调优大展身手的时机!让我们马上开冲啦啦啦!!!
常规性能调优
参考文章
- Spark 优化 (一) --------- Spark 性能调优_spark调优_在森林中麋了鹿的博客-CSDN博客
- (2条消息) 第三部分:Spark调优篇_spark 调优_奔跑者-辉的博客-CSDN博客
常规性能调优一: 最优资源配置
首先是为任务分配更多的资源,在一定范围内尽可能用更多的资源,尽情压制机器所有的性能。可以分配的资源如下
| 名称 | 说明 |
|---|---|
| –num-executors | 配置Executor的数量 |
| –driver-memory | 配置Driver内存(影响不大) |
| –executor-memory | 配置每个Executor的内存大小 |
| –executor-cores | 配置每个Executor的CPU core数量 |
由于我的实验环境是yarn-cluster模式,那么这时候观察一下yarn resource资源,再来做决定。
在本机环境中,共有12GB Memory Total、24 VCores Total,每个节点有4GB内存、8个VCores。Capacity Scheduler中Maximum Allocation:<memory:4096, vCores:4>。
在这种条件下
#!/bin/bash
spark-submit \
--class com.xuhaoran.analyze.UserScoreRDDAPP \
--master yarn \
--deploy-mode cluster \
--driver-memory 1g \
/opt/module/taobao/taobao-1.0-SNAPSHOT-jar-with-dependencies.jar
队列仅用33.3%,分配了3个核以及4680的内存。
优化一:添加–num-executors
#!/bin/bash
spark-submit \
--class com.xuhaoran.analyze.UserScoreRDDAPP \
--master yarn \
--deploy-mode cluster \
--driver-memory 1g \
--num-executors 3 \
/opt/module/taobao/taobao-1.0-SNAPSHOT-jar-with-dependencies.jar
队列用了50%,分配了4个核以及6144的内存。
耗时 194.241s,好吧,没啥提升,让我们继续!
优化二:添加executor-cores
增加每个Executor的Cpu core个数,可以提高执行task的并行度,比如3个Executor,每个Executor有8个CPU core,那么可以并行执行24个task。
#!/bin/bash
spark-submit \
--class com.xuhaoran.analyze.UserScoreRDDAPP \
--master yarn \
--deploy-mode cluster \
--driver-memory 1g \
--executor-cores 3 \
--num-executors 3 \
/opt/module/taobao/taobao-1.0-SNAPSHOT-jar-with-dependencies.jar
ok,这时候报错了
Requested resource=<memory:1408, vCores:8>, maximum allowed allocation=<memory:4096, vCores:4>, please note that maximum allowed allocation is calculated by scheduler based on maximum resource of registered NodeManagers, which might be less than configured maximum allocation=<memory:4096, vCores:4>
可以看到scheduler里面最多只可以分配<memory:4096, vCores:4>,而我上面的配置有问题,超过了yarn的配置大小,所以需要调整的。
vim yarn-site.xml进行修改
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>8000</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>12</value>
</property>
<!-- 这里调成了8gb内存和12个vcores,即每个程序最高都能用这么多资源,相比尚硅谷原版的设置4gb和4Vcores,提高了两倍资源,原则上可以提升性能的了啊! -->
然后保存yarn-site.xml并重启YARN服务,以使修改生效。
#!/bin/bash
spark-submit \
--class com.xuhaoran.analyze.UserScoreRDDAPP \
--master yarn \
--deploy-mode cluster \
--driver-memory 1g \
--executor-cores 3 \
--num-executors 3 \
/opt/module/taobao/taobao-1.0-SNAPSHOT-jar-with-dependencies.jar
让我们继续执行,运行时间218.439s,一查yarn的管理网站,发现还是最高分配4个CPU核6144MB,很奇怪,也就是说根本就没提升。
优化三:添加–executor-memory
#!/bin/bash
spark-submit \
--class com.xuhaoran.analyze.UserScoreAPP \
--master yarn \
--deploy-mode cluster \
--driver-memory 1g \
--executor-cores 2 \
--num-executors 3 \
--executor-memory 2g \
/opt/module/taobao/taobao-1.0-SNAPSHOT-jar-with-dependencies.jar
分配4个CPU,分配9216内存,队列使用率75%
提高了这个按理说对性能有3点提升:
- 缓存更多的cache数据,写入磁盘的数据响应减少,减少磁盘IO
- 可以为shuffle操作提供更多内存,即有空间存放reduce端拉去的数据,写入磁盘的数据响应减少
- 为task提供更多的执行内存,避免频繁GC,提升整体性能。
但是!运行时间223.576s,真是难啊,为什么跟博客、课程学的不一样呢…
小结
既然最优资源配置不行,考虑一下是不是单机情况下虚拟机性能不ok产生的情况,但我目前也不清楚,所以只能对这个现象按下不表,先做点其他优化吧。
常规性能调优二: RDD优化

纵观整个spark运行,可以发现sortBy at UserScoreRDDAPP.scala:40运行时间最长
点进去看一下

可以发现map at UserScoreRDDAPP.scala 32的代码运行时间2.0min


调整初始分区数
基本可以确定前8个任务的运行时间都超长,就是在读取的时候运行时间很长,那么我们试试修改一下分区数?因为理想情况下,分区数应当接近 executor 核心总数(executor 数量 * 每个 executor 的核心数),以实现最佳并行度。
因此我们在代码中修改一下
val sparkConf: SparkConf = new SparkConf().setAppName("UserScoreAPP").set("spark.default.parallelism", 3*3+"")
这里就是将分区调成executor 数量 * 每个 executor 的核心数=9
效果还是有点显著的,运行时间Execution time: 172.823s
再次调executor-memory
把每个executor的内存调成3g,这时候再次运行
yarn中显示:队列占用100%,3个vcores,以及8704分配内存和3584保留内存。
运行时间161.153s

job 0的运行时间明显降低,从2.min降到1.8min,效果不错。
疑问点:在这里调成了3g,发现hadoop1102不启动了,但是整体运行速度却加快。
好吧,那继续把 调整executor-cores=8,在程序内分区数设为 .set(“spark.default.parallelism”, 16+“”),希望可以让每台机器充分利用8个核
最后测得运行时间151.916s,job0的运行时间从1.8min降到1.5min,效果显著。
使用缓存
val userRF = behaviorRDD
.map(row => (row.getAs[Long]("user_id"), (Timestamp.valueOf(row.getAs[String]("create_time")), 1)))
.reduceByKey((a, b) => (if (a._1.after(b._1)) a._1 else b._1, a._2 + b._2))
.map { case (userId, (maxDate, frequency)) =>
val recent = (Date.valueOf("2017-12-04").getTime - maxDate.getTime) / (24 * 3600 * 1000)
(userId, recent, frequency)
}
// Calculate recent_rank and frequency_rank for each user_id
val sortedRecent = userRF.sortBy(_._2).zipWithIndex.map { case (row, index) => (row._1, index + 1, row._3) }
val sortedFrequency = userRF.sortBy(-_._3).zipWithIndex.map { case (row, index) => (row._1, index + 1) }
在这里加上 userRF.cache() 方法会对 userRF RDD 进行缓存。这意味着当 RDD 第一次被计算时,其结果将被存储在内存中,以便后续操作可以更快地访问它。这在对同一个 RDD 进行多次操作时非常有用,因为它可以避免重复计算 RDD 的数据。
在这个例子中,userRF 被用作 sortedRecent 和 sortedFrequency 的输入。如果没有缓存,那么每次操作 userRF 时,都需要重新计算整个 userRF。通过使用 .cache() 方法,userRF 只需要计算一次,然后结果将被存储在内存中,这将加速后续的 sortedRecent 和 sortedFrequency 计算。
因此运行速度提高,运行时间达到144.971s
常规性能调优三: JVM优化
上面的测试结果也可以发现一些问题,就是Job0的每个Task,GC时间占了一半,因此这里也需要进行调优。
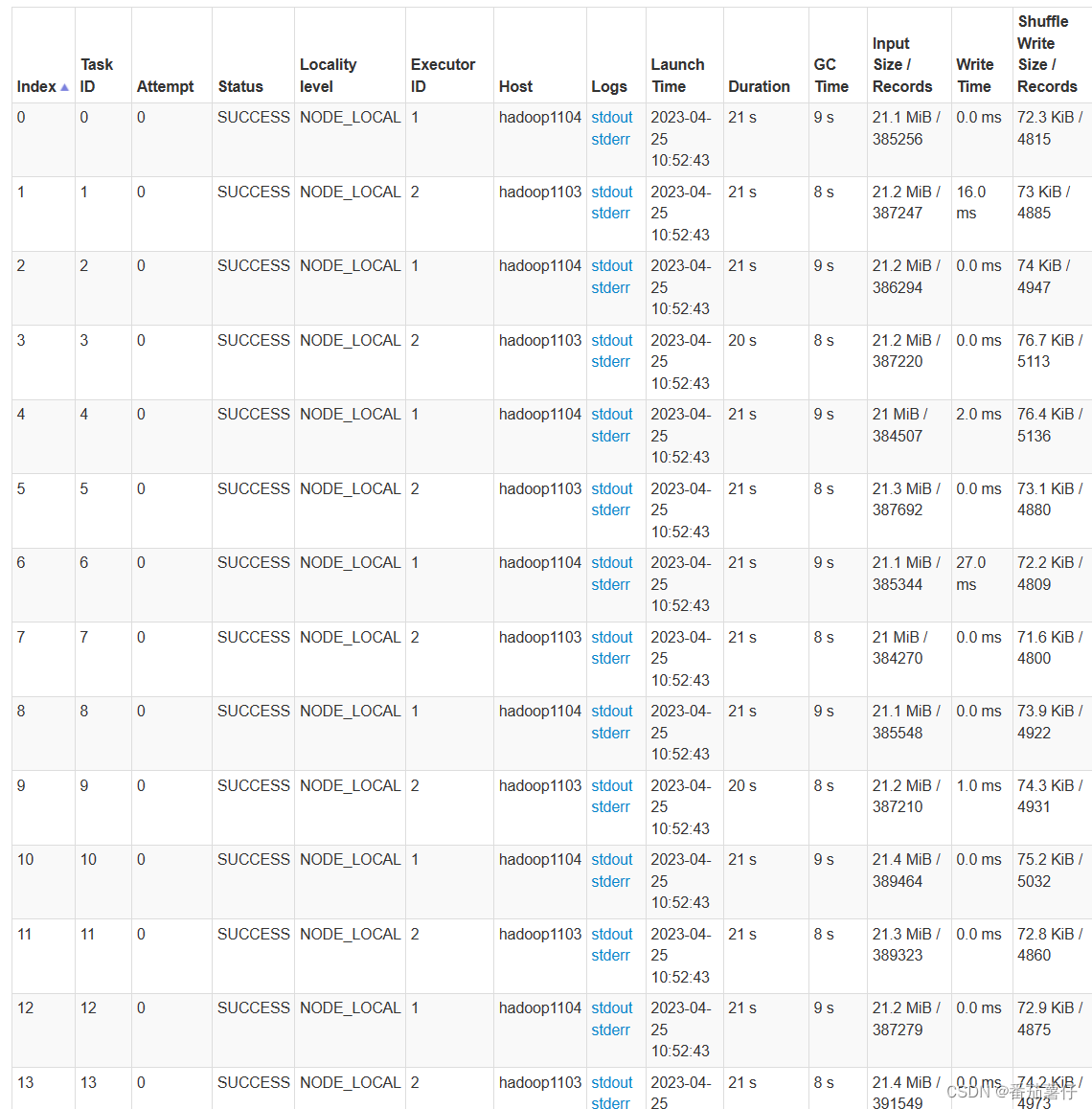
我用的是java8,java8默认的gc收集器是parrel gc,在spark web ui可以看到其实程序跑的慢原因主要是gc占了多数,因此我想尝试调整至g1垃圾收集器
但是惊奇的发现:g1收集器的时候运行时间是496.727s。
我上网搜了两点问题,这可能是g1在spark程序中不能跑得快的原因:
- G1 垃圾收集器的吞吐量并不是最高的,在一些需要高吞吐量的应用场景中,可能需要选择其他垃圾收集器。
- G1 垃圾收集器需要对堆内存进行分区,并对每个分区进行回收。在堆内存较小的情况下,分区的数量可能会增加,导致垃圾收集器的性能下降。
好吧,我再看看java8有什么更速的垃圾收集器吧,我需要的选型是高吞吐量的,低GC时间的。
增加年轻代的比例可以将更多的内存分配给年轻代,从而提高程序的吞吐量和性能。年轻代是垃圾收集频率较高的区域,如果能够将更多的对象分配到年轻代中,就可以减少老年代的垃圾收集频率,从而减少应用程序的暂停时间,提高程序的性能和吞吐量。
这个时候我在想,慢的情况主要发生在读取数据后几个RDD,说明年轻代的问题比较大,那我是不是可以调高年轻代的比例呢?
#!/bin/bash
spark-submit \
--class com.xuhaoran.analyze.UserScoreRDDAPP \
--master yarn \
--deploy-mode cluster \
--driver-memory 1g \
--executor-cores 8 \
--num-executors 3 \
--executor-memory 3g \
--conf "spark.executor.extraJavaOptions=-XX:NewRatio=3" \
/opt/module/taobao/taobao-1.0-SNAPSHOT-jar-with-dependencies.jar
更慢了。。。用时174.273
失败!真的裂开!好吧,那继续下一个。
那动态分配新生代和老年代呢,这种情况如何?
--conf "spark.executor.extraJavaOptions=-XX:+UseAdaptiveSizePolicy" \
但是运行速度也是150多s,感觉跟前面做的最优速度没变化。
其他性能调优
比如说,按照(1条消息) Spark 优化 (一) --------- Spark 性能调优_spark调优_在森林中麋了鹿的博客-CSDN博客的介绍,其他调优方法还有:
- 常规性能调优
- 最优资源配置(已完成)
- RDD优化
- RDD 复用(已完成)
- RDD持久化
- RDD尽可能早的filter操作(已完成)
- 并行度调节(已完成)
- 广播大变量
- Kryo序列化
- 调节本地化等待时长
- 算子调优(已完成)
- forearchPartition优化数据库操作
- filter与coalesce的配合使用
- repartition解决SparkSQL低并行度问题
- reduceByKey预聚合(已完成)
- Shuffle调优
- 调节map端缓冲区大小
- 调节reduce端拉取数据缓冲区大小
- 调节reduce端拉去数据重试次数
- 调节reduce端拉取数据等待间隔
- 调节SortShuffle排序操作阈值
- JVM调优
- 降低cache操作的内存占比
- 调节Executor堆外内存
- 调节连接等待时长
总结
感谢各位大佬能看到这里了啦!
本次实验是我第一次调优,简直是糟糕透了,尝试了这么多配置感觉都是有问题的,目前还搞不通里面的门门道道,但至少运行时间从200s降至144s(比Spark-sql 高14s),也算是有点进步了。
此外,由于这次实验涉及的Shuffle不多,所以也并未做到Shuffle相关的调优,这些优化操作将在下一次实验进行,也期待下一次实验能够给大家展示成功的调优过程!














 1717
1717











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









