







对分(Dichotomy)、增长函数(Growth Function)、突破点(Break Point)、VC维(Vapink-Chervonenkis Dimension)是计算学习理论中非常重要的概念,也是机器学习的基石。可以说如果不理解计算学习理论,那就不能从根本上理解机器学习。
机器学习最基本的问题是二分类和回归,在这里我们讨论的是二分类的问题。我们知道有很多二分类的模型,我们把这些模型称为分类器,常见的分类器有下面几种:
- 正射线
- 正间隔
- 一维感知机
- 二维感知机
详情可以参考《快乐机器学习》这本书,或者林轩田老师的机器学习基石课程。
如果一种操作能把正负样点线性分开,我们就把这种操作称为对分。一种对分其实就是线性二分类的一种分类方式。一种模型可以有若干种对分方式。我们把模型能产生对分的种类的数量定义为这种分类器的增长函数。增长函数和样本点的数量有关系,显然,样本点越多,对分的方式越多,增长函数就越大。直观上,我们感觉有 n n n个点,就有 2 n 2^n 2n中对分方式,因为对于二分类,每个点有2中可能的取值,总共有 2 n 2^n 2n中组合总数。但是实际上,很多组合是线性不可分的,因此真实情况下,在n比较小的时候,能满足增长函数等于 2 n 2^n 2n;随着n增大,增长函数将小于 2 n 2^n 2n。
常见的二分类问题增长函数如下表所示:
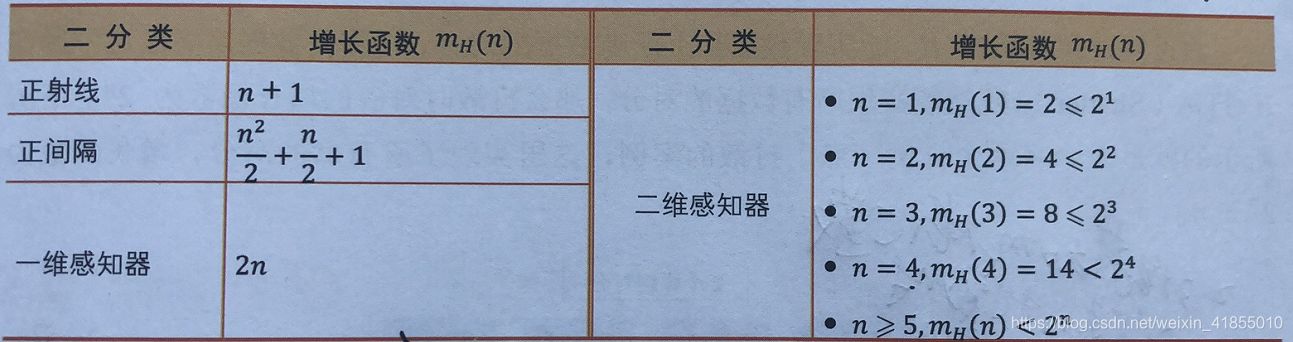
以一维感知机为例我们可以用下图表示增长函数
d
h
(
n
)
d_h(n)
dh(n)和指数函数
f
(
n
)
f(n)
f(n)之间的关系。
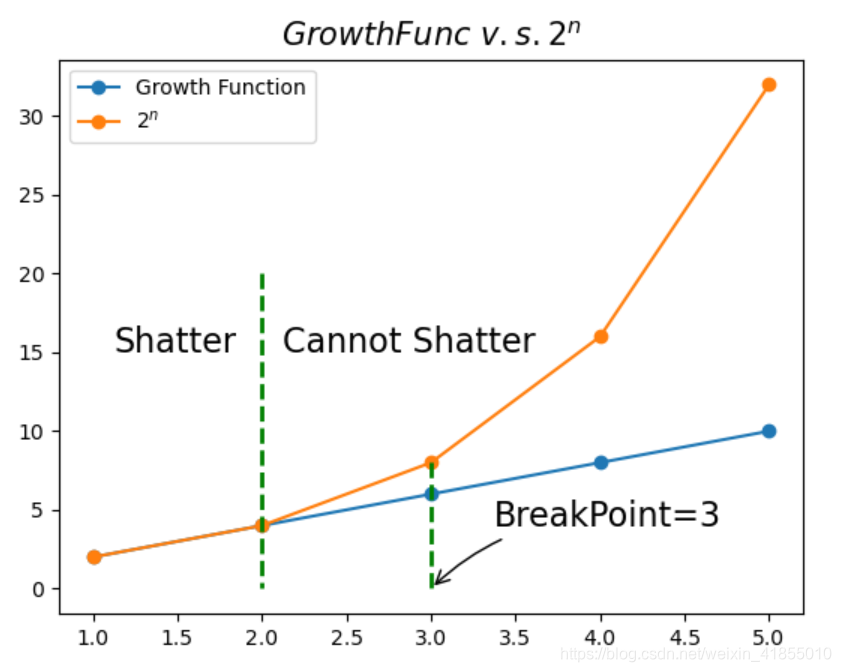
我们可以看到,在
n
<
=
2
n<=2
n<=2时,增长函数和指数函数是重合的,我们把这样的情况称为,在这样的n下,数据集可以被这个分类器打散(Shatter)。当n>2时,增长函数就小于指数函数了,这个时候就是不能打散的情况了,第一个出现不能打散情况时n的取值3,称为突破点(BreakPoint),我们通常记为
k
k
k。k-1又被称为VC维(Vapink-Chervonenkis Dimension)
这样,我们就把这几个计算学习理论中的概念用可视化的方式展示了出来。
该图的代码如下:
import matplotlib.pyplot as plt
from matplotlib.legend_handler import HandlerLine2D
import numpy as np
n = np.arange(1,6)
g = 2*n
f = np.power(2,n)
line1, = plt.plot(n,g, marker='o', label='Line 1')
line2, = plt.plot(n,f, marker='o', label='Line 2')
plt.legend([line1,line2],['Growth Function',r'$2^n$'],loc='upper left')
plt.plot([3,3],[8,0],'g--',lw=2)
plt.annotate('BreakPoint=3',xy=(3,0),xytext=(+30,+30),textcoords='offset points',fontsize=16,
arrowprops=dict(arrowstyle='->',connectionstyle='arc3,rad=.2'))
plt.title(r'$Growth Func\ v.s. 2^n$',fontsize=15)
plt.plot([2,2],[20,0],'g--',lw=2)
plt.annotate(r'Shatter',xy=(1,15),xytext=(+10,0),textcoords='offset points',fontsize=16)
plt.annotate(r'Cannot Shatter',xy=(2,15),xytext=(+10,0),textcoords='offset points',fontsize=16)
plt.show()
20200523看林老师视频后的理解更新:
成长函数:关于数据大小n的函数,这个数表示某种操作能产生全部二分的种数。这个数目其实可以看成是在这种操作下能产生假设的数量。
成长函数的接口定义可以写成是 int growth_func(operation_fun H, int data_len)
简单记忆:成长函数就是二分种数
什么叫做成长,就是假设的数量会随着数据大小增长,假设的数量越多,表达能力就越强。
突破点:对于某种操作,当数据集达到k时,这种操作无法打散该数据集,那么k就是这种操作的突破点。
突破点的接口定义可以写成 int break_point(operation_fun H)
我们就可以用突破点来量化这种操作
打散:对于某种操作,如果能产生对某数据集的全部对分,则成为这种操作能够打散该数据集。
shatter的使用语法:一种操作shatter了一个数据集
打散的接口定义可写成 bool is_shatter(operation_fun H,dataset)
我们的目标是把成长函数从关于数据集大小的函数编程关于突破点的函数,也就是把成长函数的定义变为:
int growth_func(int break_point, int data_len)
即 mH(N) -> mK(N)<=poly(N)
第3页slide讲的是,突破点为k的某种操作,当数据集大小为n的时候,可能的二分种类有多少个,也即集成长函数是多少。为了证明如果尺寸大于k的数据集,都不能被该操作shatter。并且找到成长函数和k之间的关系。因为成长函数受到了k的约束。这个约束会产生一个上界,这个上界就是Bounding Func,边界函数。
这页ppt本质上讲的是突破点为k的操作的成长函数的变化趋势
如果n<k的,数据集是可以被shatter的,如果n>k,那么数据集不能被shatter。对于三个数据点,不能shatter其中任意的两个点。
成长函数本质上是某个操作(假设)对于大小为N的数据集的有效假设的数量函数 M H ( n ) M_H(n) MH(n),我们可以通过推导(林老师课程的第六章)代换为他的上限函数B(n,k),其中k是对应操作的的突破点。也就是不能被打散的最小值。VC维度就是通过breakpoint引出来的,VC维度=k-1,也就是能够这种假设能够shatter的最多点。

















 778
778

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









