






SVM:support vector machine,支持向量机
支持向量就是分类时的边界向量,主要通过支持向量来对分类算法进行优化。
优化问题主要分类三类:
1.不带约束条件:min fx;求取函数f(x)的导数,然后令其为零,可以求得候选最优值,再在这些候选值中验证;如果是凸函数,可以保证是最优解。这也就是我们高中经常使用的求函数的极值的方法。
2.带等式约束条件:min fx;s.t. hx=0;s.t.是subject to ,常常使用的方法就是拉格朗日乘子法(Lagrange Multiplier) ,即把等式约束h_i(x)用一个系数与f(x)写为一个式子,称为拉格朗日函数,而系数称为拉格朗日乘子。通过拉格朗日函数对各个变量求导,令其为零,可以求得候选值集合,然后验证求得最优值。
3,带不等式约束条件:min fx;s.t. gx<=0;常常使用的方法就是KKT条件。同样地,我们把所有的等式、不等式约束与f(x)写为一个式子,也叫拉格朗日函数,系数也称拉格朗日乘子,通过一些条件,可以求出最优值的必要条件,这个条件称为KKT条件。
SMO算法
(Sequential Minimal Optimizaion)。Platt的SMO算法是将大优化问题分解为多个小优化问题来求解的。这些小优化问题往往很容易求解,并且对它们进行顺序求解的结果与将它们作为整体来求解的结果完全一致的。在结果完全相同的同时,SMO算法的求解时间短很多。
SMO算法的目标是求出一系列alpha和b,一旦求出了这些alpha,就很容易计算出权重向量w并得到分隔超平面。
SMO算法的工作原理是:每次循环中选择两个alpha进行优化处理。一旦找到了一对合适的alpha,那么就增大其中一个同时减小另一个。这里所谓的"合适"就是指两个alpha必须符合以下两个条件,条件之一就是两个alpha必须要在间隔边界之外,而且第二个条件则是这两个alpha还没有进进行过区间化处理或者不在边界上。
SMO算法的步骤:
第一步:选取一个alpha,ai;计算误差值Ei,Ei等于预测值fxi-实际值yi
Ei=fxi-yi;
yi是标签值,1或者-1;
fx=wTx+b,决策函数;fx=0位决策面方程;b是常数项。
fxi=wTxi+b
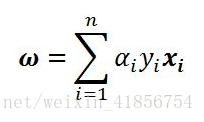
w由KKT条件求得。
则:
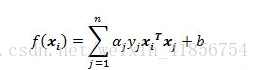
第二步:判断ai是否满足KKT条件,不满足则继续往下进行,满足则退出重新选择a值;
不满足KKT条件说明a值还不是最优值,需要继续进行优化。
不满足KKT的两种情况:
1.yifxi<1 and ai<C
2.yifxi>1 and ai>0
代码中引入了容错率tolerance,toler;
则:
1.yifxi<1-toler and ai<C;
2.yifxi>1+toler and ai>0;
代码中写的是:
1.yiEi<-toler and ai<C
2.yiEi>toler and ai>0
yiEi=yi(fxi-yi)=yifxi-yi*yi=yifxi-1
第三步:随机选取第二个alpha值,aj;计算aj的误差值Ej;
第四步:计算aj的取值范围。上下界H和L;
代码中增加限制条件,如果上下边界一样,即L=H,则放弃本次更新,进行下一次迭代。
如果上下边界一样,则aj没有更新的空间。
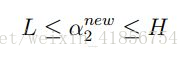
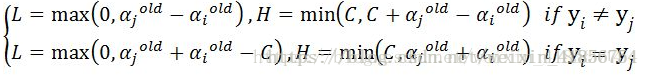
C是常数项,输入的参数之一,是为了衡量松弛变量的权重。就是衡量个别不在线性划分范围的点的影响。
第五步:更新aj值;并根据上下边界修剪aj;
代码中增加了一个限制条件:如果aj更新的幅度达不到要求,则放弃本次更新,进行下一次迭代。
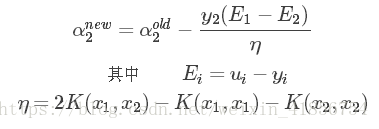
eta,η,称为学习速率。K表示内积;
修剪公式:

第六步:更新ai值;
满足:yi*ai_new+yjaj_new=yi*ai_old+yj*aj_old=k,k表示非变量。KKT条件求得。
推导可得下式:不过应该是除以yi,不过yi不是1就是-1,所以除还是乘结果都一样。
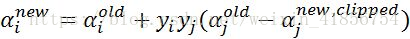
第七步:更新b1和b2,最后更新b值:
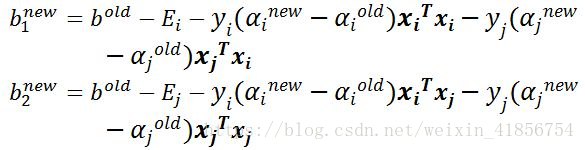
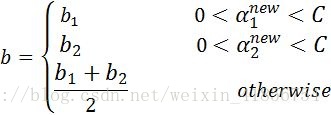
这样,便得到了b和alphas

根据此式,求出w;
这里要注意的是:
三个向量相乘,无法直接用矩阵相乘表示。
应当先用数组相乘,再用矩阵相乘。
于是就可以就得分类函数:
f(xi)=w*xi+b
f(x)=0时为决策面。














 903
903











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









