






 本文介绍了自编码器的基本概念及其工作原理,包括有损压缩、自动学习等特性,并详细探讨了神经网络自编码器的搭建方法及在特征降维方面的应用。
本文介绍了自编码器的基本概念及其工作原理,包括有损压缩、自动学习等特性,并详细探讨了神经网络自编码器的搭建方法及在特征降维方面的应用。
自编码
介绍
仅仅是自编码器的话,其原理其实很简单。自编码器可以理解为一个试图去还原其原始输入的系统。自编码器模型如下图所示。
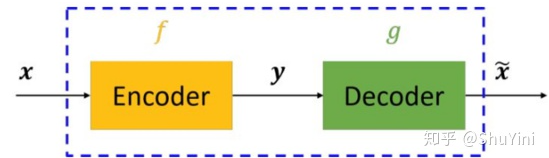
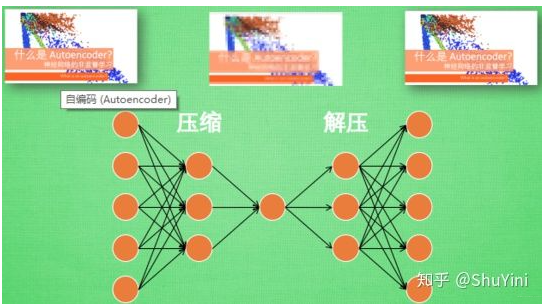
从上图可以看出,自编码器模型主要由编码器(Encoder)和解码器(Decoder)组成,其主要目的是将输入x转换成中间变量y,然后再将y转换成 x‾\overline xx ,然后对比输入x和输出 x‾\overline xx 使得他们两个无限接近。
Auto-encoder本质上就是一个自我压缩和解压的过程,我们想要获取压缩后的code,它代表了对原始数据的某种紧凑精简的有效表达,即降维结果,这个过程中我们需要:
Encoder(编码器),它可以把原先的图像压缩成更低维度的向量
Decoder(解码器),它可以把压缩后的向量还原成图像
注意到,Encoder和Decoder都是Unsupervised Learning,由于code是未知的,对Encoder来说,我们手中的数据只能提供图像作为NN的input,却不能提供code作为output;对Decoder来说,我们只能提供图像作为NN的output,却不能提供code作为input
“自动编码”是一种数据压缩算法,其中压缩和解压缩函数是 1) 特定于数据的,2) 有损的,以及 3) 从示例中自动学习而不是由人工设计的。此外,在几乎所有使用术语“自动编码器”的上下文中,压缩和解压缩功能都是用神经网络实现的。
- 自动编码器是特定于数据的,这意味着它们只能压缩与其训练过的数据类似的数据。这与 MPEG-2 音频层 III (MP3) 压缩算法不同,后者仅对一般的“声音”进行假设,而不对特定类型的声音进行假设。在人脸图片上训练的自动编码器在压缩树木图片方面做得很差,因为它学习的特征是特定于人脸的。
2)自编码器是有损的,这意味着与原始输入(类似于 MP3 或 JPEG 压缩)相比,解压后的输出会降级。这与无损算术压缩不同。
3)自动编码器是从数据示例中自动学习的,这是一个有用的特性:这意味着很容易训练在特定类型的输入上表现良好的算法的专门实例。它不需要任何新的工程,只需要合适的训练数据。
要构建自动编码器,您需要三样东西:编码函数、解码函数以及数据的压缩表示与解压缩表示之间的信息损失量之间的距离函数(即“损失”函数)。编码器和解码器将被选择为参数函数(通常是神经网络),并且相对于距离函数是可微的,因此可以优化编码/解码函数的参数以最小化重建损失,使用随机梯度下降.这很简单!你甚至不需要理解这些词中的任何一个就可以开始在实践中使用自动编码器。
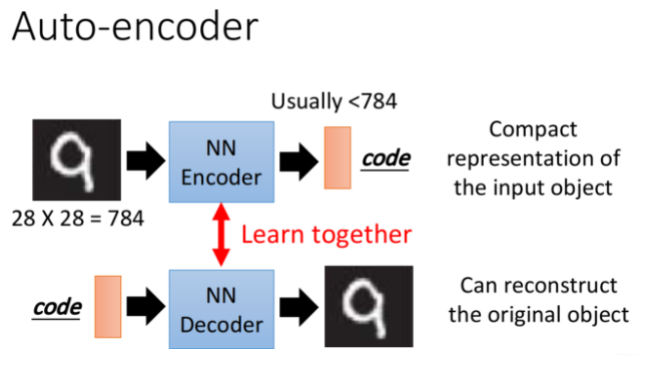
因此Encoder和Decoder单独拿出一个都无法进行训练,我们需要把它们连接起来,这样整个神经网络的输入和输出都是我们已有的图像数据,就可以同时对Encoder和Decoder进行训练,而降维后的编码结果就可以从最中间的那层hidden layer中获取
Compare with PCA
实际上PCA用到的思想与之非常类似,PCA的过程本质上就是按组件拆分,再按组件重构的过程
在PCA中,我们先把均一化后的 x 根据组件W分解到更低维度的c,然后再将组件权重c乘上组件的反置WTW^TWT得到重组后的x^\widehat xx,同样我们期望重构后的x^\widehat xx与原始的xxx越接近越好
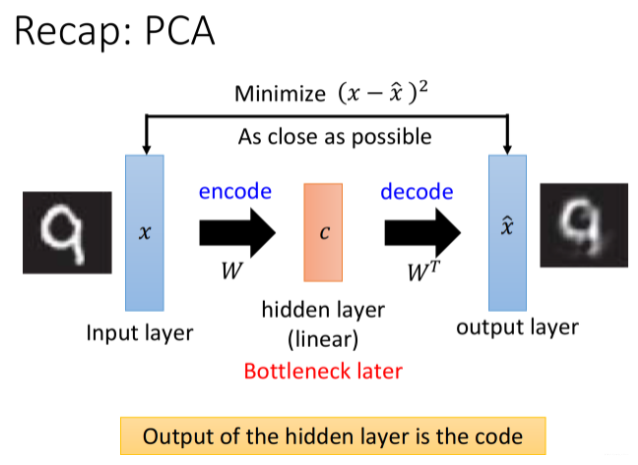
如果把这个过程看作是神经网络,那么原始的xxx就是input layer,重构x^\widehat xx就是output layer,中间组件分解权重ccc就是hidden layer,在PCA中它是linear的,我们通常又叫它瓶颈层(Bottleneck layer)
由于经过组件分解降维后的ccc,维数要远比输入输出层来得低,因此hidden layer实际上非常窄,因而有瓶颈层的称呼
对比于Auto-encoder,从input layer到hidden layer的按组件分解实际上就是编码(encode)过程,从hidden layer到output layer按组件重构实际上就是解码(decode)的过程
这时候你可能会想,可不可以用更多层hidden layer呢?答案是肯定的
Deep Auto-encoder
Multi Layer
对deep的自编码器来说,实际上就是通过多级编码降维,再经过多级解码还原的过程
此时:
- 从input layer到bottleneck layer的部分都属于Encoder
- 从bottleneck layer到output layer的部分都属于Decoder
- bottleneck layer的output就是自编码结果code
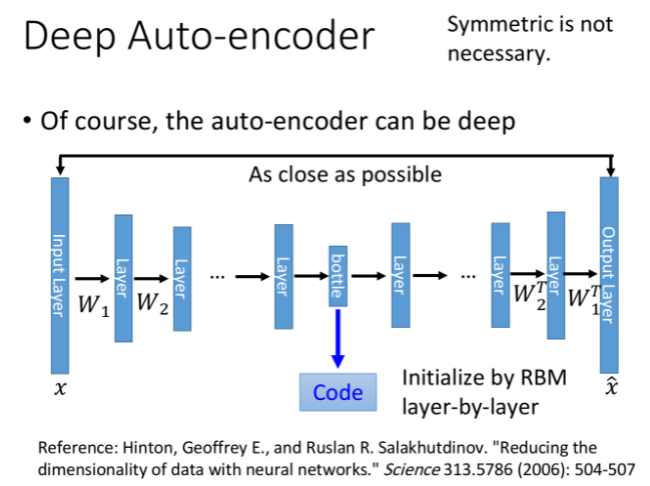
注意到,如果按照PCA的思路,则Encoder的参数WiW_iWi需要和Decoder的参数WiTW_i^TWiT保持一致的对应关系,这可以通过给两者相同的初始值并设置同样的更新过程得到,这样做的好处是,可以节省一半的参数,降低overfitting的概率
但这件事情并不是必要的,实际操作的时候,你完全可以对神经网络进行直接训练而不用保持编码器和解码器的参数一致
神经网络自编码模型
在深度学习中,自动编码器是一种无监督的神经网络模型,它可以学习到输入数据的隐含特征,这称为编码(coding),同时用学习到的新特征可以重构出原始输入数据,称之为解码(decoding)。从直观上来看,自动编码器可以用于特征降维,类似主成分分析PCA,但是其相比PCA其性能更强,这是由于神经网络模型可以提取更有效的新特征。除了进行特征降维,自动编码器学习到的新特征可以送入有监督学习模型中,所以自动编码器可以起到特征提取器的作用。举个例子,我有一张清晰图片,首先我通过编码器压缩这张图片的大小(如果展现出来可能比较模型),然后在需要解码的时候将其还原成清晰的图片。具体过程如下图所示。
那么此时可能会有人问了,好端端的图片为什么要压缩呢?其主要原因是:有时神经网络要接受大量的输入信息, 比如输入信息是高清图片时, 输入信息量可能达到上千万, 让神经网络直接从上千万个信息源中学习是一件很吃力的工作. 所以, 何不压缩一下, 提取出原图片中的最具代表性的信息, 缩减输入信息量, 再把缩减过后的信息放进神经网络学习. 这样学习起来就简单轻松了. 所以, 自编码就能在这时发挥作用. 通过将原数据白色的X 压缩, 解压 成黑色的X, 然后通过对比黑白 X ,求出预测误差, 进行反向传递, 逐步提升自编码的准确性. 训练好的自编码中间这一部分就是能总结原数据的精髓. 可以看出, 从头到尾, 我们只用到了输入数据 X, 并没有用到 X 对应的数据标签, 所以也可以说自编码是一种非监督学习. 到了真正使用自编码的时候. 通常只会用到自编码前半部分。
为何要用输入来重构输出
如果自编码器的唯一目的是让输出值等于输入值,那这个算法将毫无用处。事实上,我们希望通过训练输出值等于输入值的自编码器,让潜在表征h将具有价值属性。
这可通过在重构任务中构建约束来实现。
从自编码器获得有用特征的一种方法是,限制h的维度使其小于输入x,这种情况下称作有损自编码器。通过训练有损表征,使得自编码器能学习到数据中最重要的特征。
如果自编码器的容量过大,它无需提取关于数据分布的任何有用信息,即可较好地执行重构任务。如果潜在表征的维度与输入相同,或是在过完备案例中潜在表征的维度大于输入,上述结果也会出现。
在这些情况下,即使只使用线性编码器和线性解码器,也能很好地利用输入重构输出,且无需了解有关数据分布的任何有用信息。
在理想情况下,根据要分配的数据复杂度,来准确选择编码器和解码器的编码维数和容量,就可以成功地训练出任何所需的自编码器结构。
神经网络自编码器三大特点
1、自动编码器是数据相关的(data-specific 或 data-dependent),这意味着自动编码器只能压缩那些与训练数据类似的数据。比如,使用人脸训练出来的自动编码器在压缩别的图片,比如树木时性能很差,因为它学习到的特征是与人脸相关的。
2、自动编码器是有损的,意思是解压缩的输出与原来的输入相比是退化的,MP3,JPEG等压缩算法也是如此。这与无损压缩算法不同。
3、自动编码器是从数据样本中自动学习的,这意味着很容易对指定类的输入训练出一种特定的编码器,而不需要完成任何新工作。
自编码器(Autoencoder)搭建
搭建一个自动编码器需要完成下面三样工作:搭建编码器,搭建解码器,设定一个损失函数,用以衡量由于压缩而损失掉的信息。编码器和解码器一般都是参数化的方程,并关于损失函数可导,典型情况是使用神经网络。编码器和解码器的参数可以通过最小化损失函数而优化,例如SGD。举个例子:根据上面介绍,自动编码器看作由两个级联网络组成。
第一个网络是一个编码器,负责接收输入 x,并将输入通过函数 h 变换为信号 y:
y=h(x)y=h(x)y=h(x)
第二个网络将编码的信号 y 作为其输入,通过函数f得到重构的信号 r:
r=f(y)=f(h(x))r=f(y)=f(h(x))r=f(y)=f(h(x))
定义误差 e 为原始输入 x 与重构信号 r 之差,e=x–r,网络训练的目标是减少均方误差(MSE),同 MLP 一样,误差被反向传播回隐藏层。
Key Parameters of Convolutional Neural Networks
卷积操作的缺点不言而喻:每一次卷积操作之后,输出矩阵都会缩小一圈,如果是比 [公式] 更大的卷积核,这种收缩会更大;以及对于矩阵中间的像素,我们会用到很多次,而边角上的像素只会用到寥寥几次,所以会导致训练上的偏差。为了解决这个问题,我们可以给输入图像矩阵的外围填充Padding一层或多层0,这样就可以保证卷积操作之后的输出图像的大小和输入一致
填充操作扩展了输出图像的大小,与之相对的跨步Stride则进一步收缩了输出图像的尺寸。这个操作不是一格一格地扫这个输入图像,而是一格隔一格、或者一格隔几格地扫过一个图像矩阵,这就会造成输出图像大小的进一步收缩。
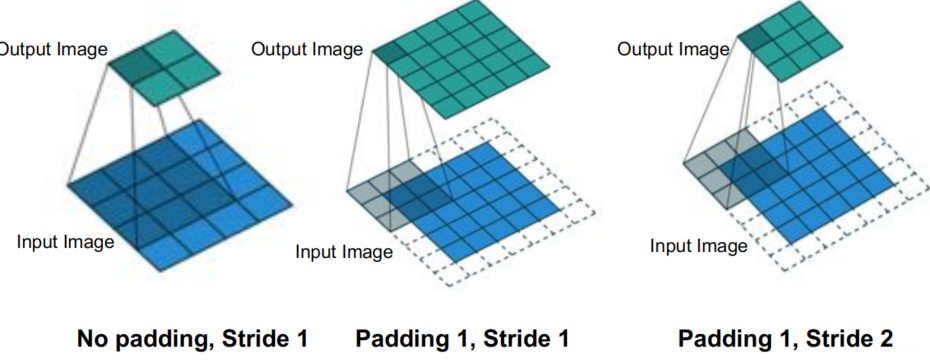
Parameters
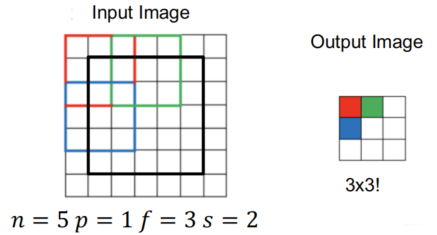
Input Image size n×nn×nn×n
Filter (or Kernel) Size: f×ff×ff×f
Padding ppp
Stride : sss
Output Image Size:
(n+2p−fs+1)×(n+2p−fs+1)\left(\frac{n+2p-f}s+1\right)\times\left(\frac{n+2p-f}s+1\right)(sn+2p−f+1)×(sn+2p−f+1)
2. Pooling Layers
1. Operation of pooling
池化使下一层的输入表示(特征维)更小,因此经常使用“Max Pooling”,因为保留高值以激活下一层可能很有趣,因为它们可能表征某些重要特征。 池化减少了网络中参数和计算的数量,因此控制了过度拟合
max pooling是做subsampling,根据filter 1,我们得到一个4×4的matrix,根据filter 2,你得到另外一个4×4的matrix. 我们把output四个分为一组,每一组里面通过选取平均值或最大值的方式,把原来4个value合成一个 value,这件事情相当于在image每相邻的四块区域内都挑出一块来检测,这种subsampling的方式就可以让你的image缩小!
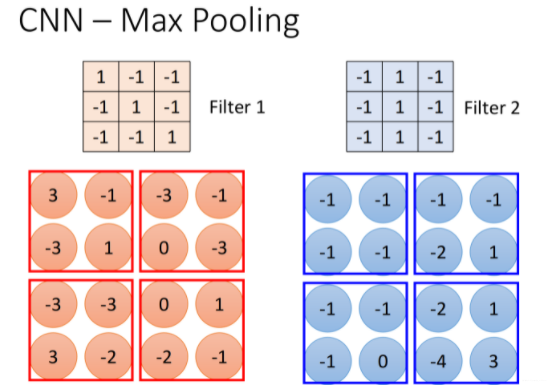
2. Example of Max Pooling Layer
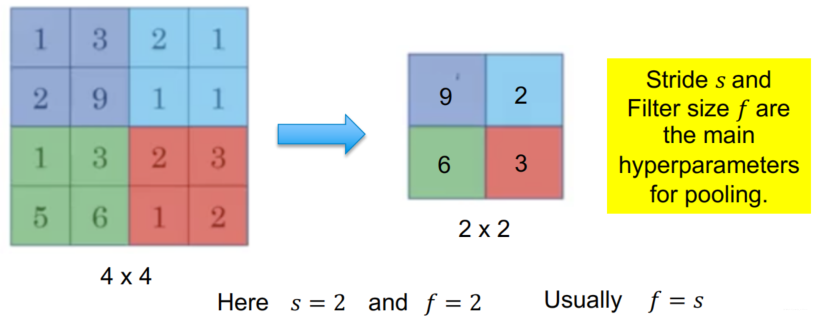
3. Convolution + Pooling
做完一次convolution加一次max pooling,我们就把原来66的image,变成了一个22的image;至于这个2*2的image,它每一个pixel的深度,也就是每一个pixel用几个value来表示,就取决于你有几个filter,如果你有50个filter,就是50维,像下图中是两个filter,对应的深度就是两维
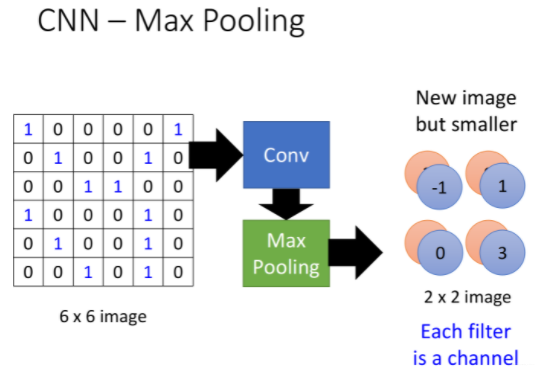
所以,这是一个新的比较小的image,它表示的是不同区域上提取到的特征,实际上不同的filter检测的是该image同一区域上的不同特征属性,所以每一层channel(通道)代表的是一种属性,一块区域有几种不同的属性,就有几层不同的channel,对应的就会有几个不同的filter对其进行convolution操作
这件事情可以repeat很多次,你可以把得到的这个比较小的image,再次进行convolution和max pooling的操作,得到一个更小的image,依次类推
4. Fully Connected Layers (Flatten)
1. 定义
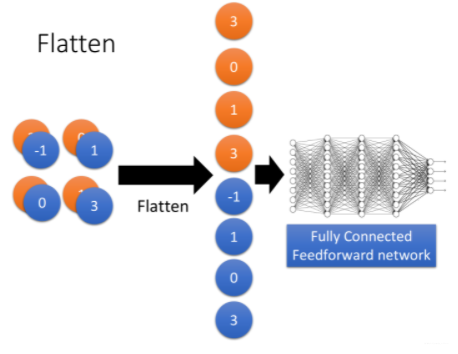
做完convolution和max pooling之后,就是Flatten和Fully connected Feedforward network的部分
Flatten的意思是,把左边的feature map拉直,然后把它丢进一个Fully connected Feedforward network,然后就结束了,也就是说,我们之前通过CNN提取出了image的feature,它相较于原先一整个image的vetor,少了很大一部分内容,因此需要的参数也大幅度地减少了,但最终,也还是要丢到一个Fully connected的network中去做最后的分类工作
Transform for example 32x32x3 image into 10x1 vector.
- Reshape image into 1D vector # of dimension 32x32x3= 3072
- Apply full convolution through matrix WWW
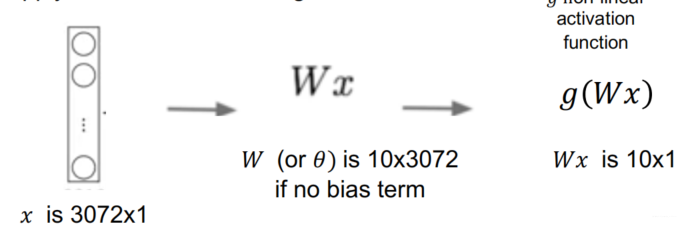
5. Whole structure
1. Number of Weights to Train for a Given Layer of the CNN
If I have 100 filters of size 4 x 4 x 3 (each with bias term) in layer 5, what is the total number of weights (or degrees of freedom) to train for this layer?
***Number of filters ×(size of filter + 1 bias term)***
100×(4×4×3+1)=100×49=4900 weights
请注意,参数的数量与输入图像的大小无关,对于前馈神经网络而言,情况并非如此!
Example
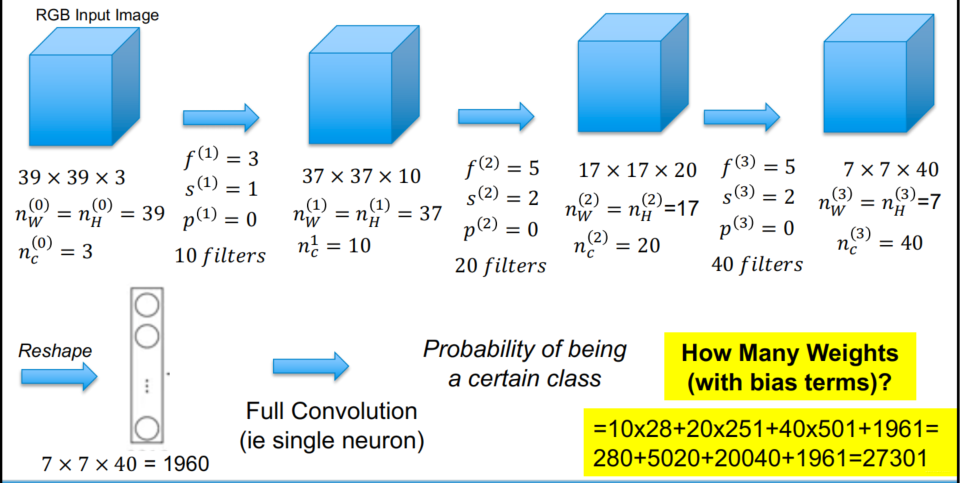
10*(333+1)+20*(5510+1)+40*(5520+1)+1961= 27301
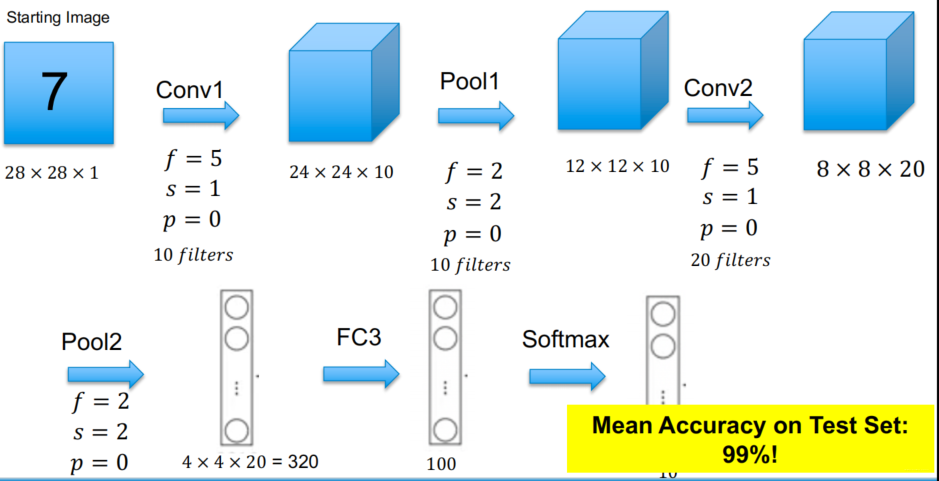
MNIST: CNN Layers (Bias Terms are used)
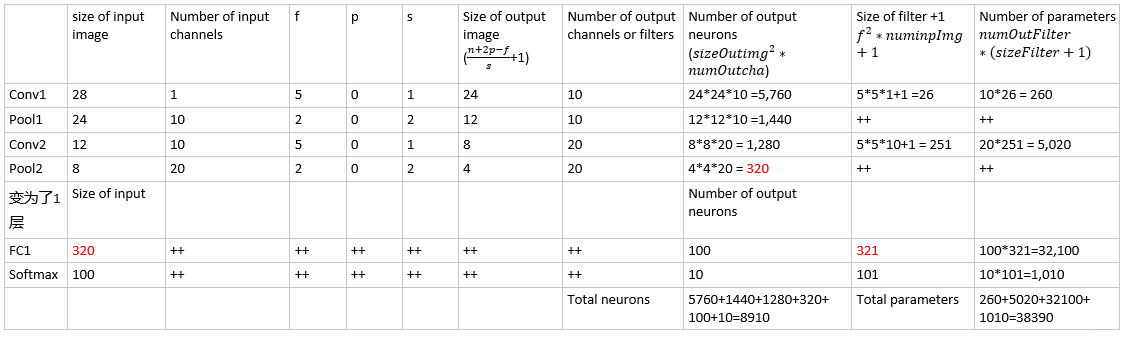
Structure of Harley‘s Network
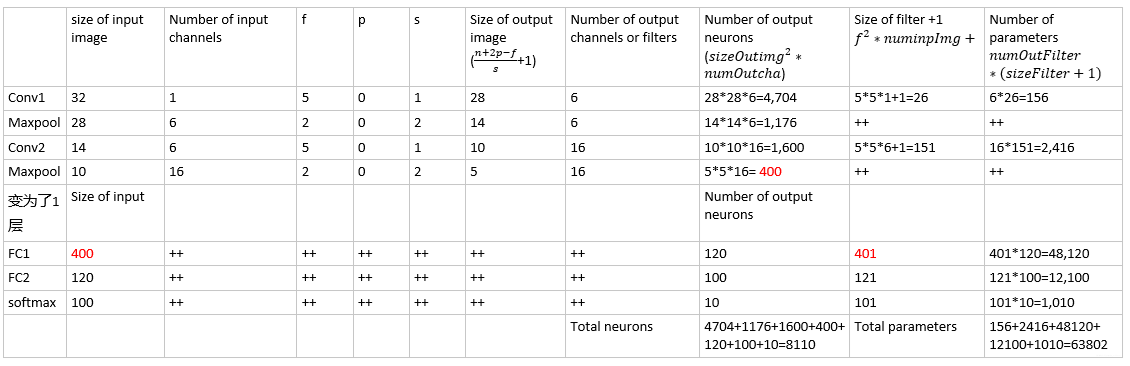
2. Counting the Degrees of Freedom (or Parameters) for a layer l
Assume layer lll has nc(l)n_c^{(l)}nc(l) filters of size f(l)f^{(l)}f(l), a padding p(l)p^{(l)}p(l) and a stride s(l)s^{(l)}s(l)
Assume the input image has size nH(l−1)×nW(l−1)×nc(l−1)n_H^{(l-1)}×n_W^{(l-1)}×n_c^{(l-1)}nH(l−1)×nW(l−1)×nc(l−1)
the output image has size nH(l)×nW(l)×nc(l)n_H^{(l)}×n_W^{(l)}×n_c^{(l)}nH(l)×nW(l)×nc(l)
The size of each filter is f(l)×f(l)×nc(l−1)f^{(l)}×f^{(l)}×n_c^{(l-1)}f(l)×f(l)×nc(l−1) and the depth or number of output features is the number of filters nc(l)n_c^{(l)}nc(l)
The total number of degrees of freedom (or parameters) of layer lll is:
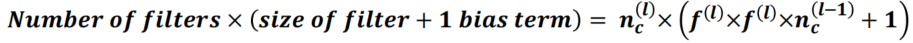
| SVD | ||
|---|---|---|
| reconstruction error |

















 554
554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









