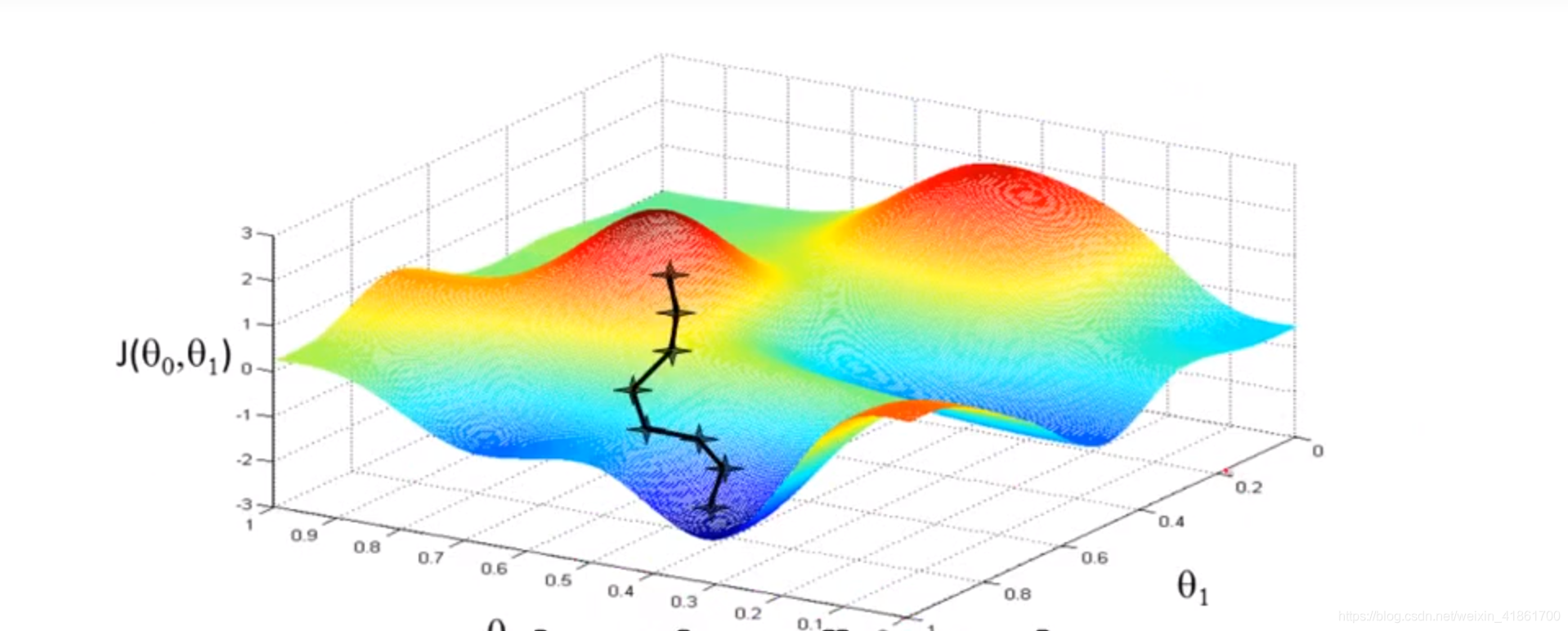
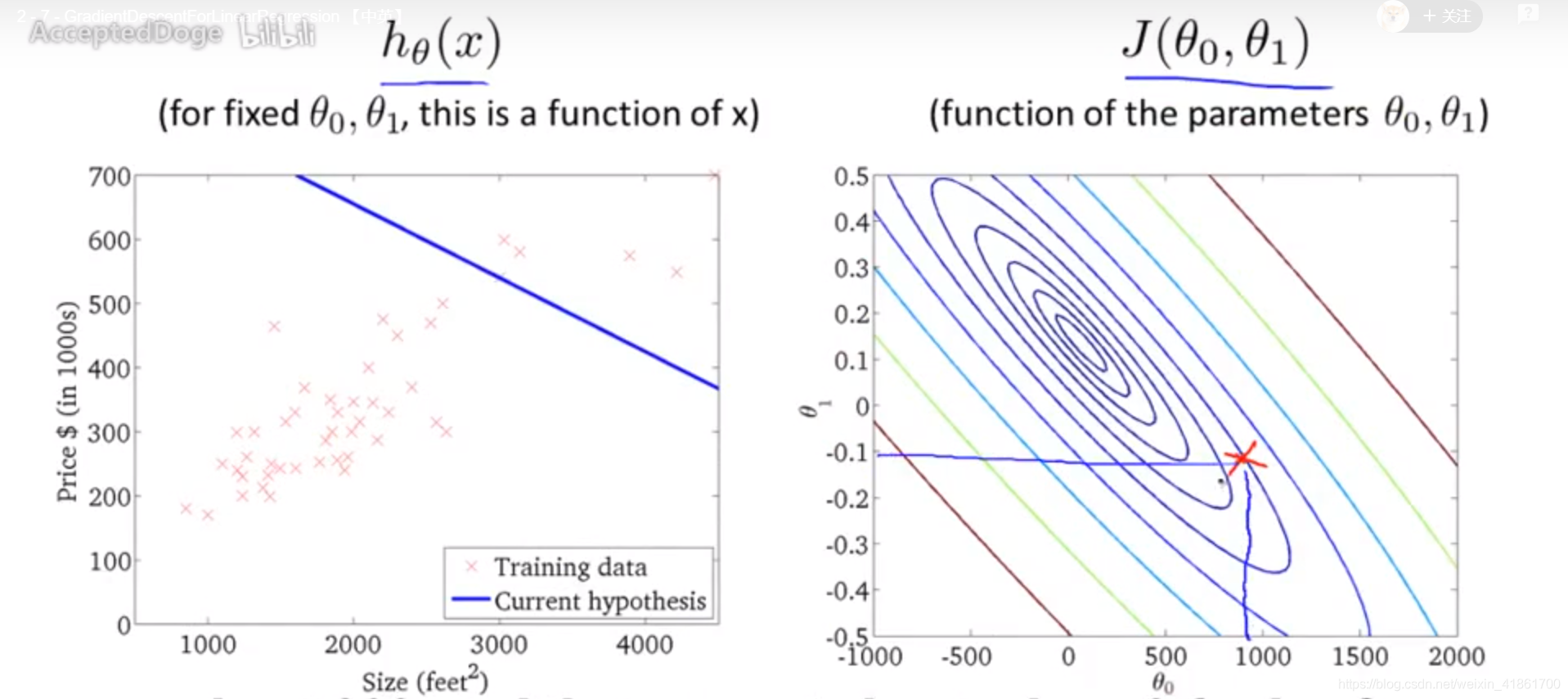
θ0指的是特解a, θ1指的是斜率k, α指的是学习率(machine learning rate)。 θ0通过不停的迭代,找到偏导数的最小值。上次的θ0-学习率再对hθ求偏导数得到新的θ0,θ1同理。 J cost function运行起来的可视化. <









 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






