










当下,最火的人工智能无疑就是生成式大模型,包括纯大语言模型和多模态模型,所以本次也抱着学习的态度,以大模型发展的时间线来对主要节点的一些生成式语言模型的论文进行分享(论文和分享内容会动态更新)。
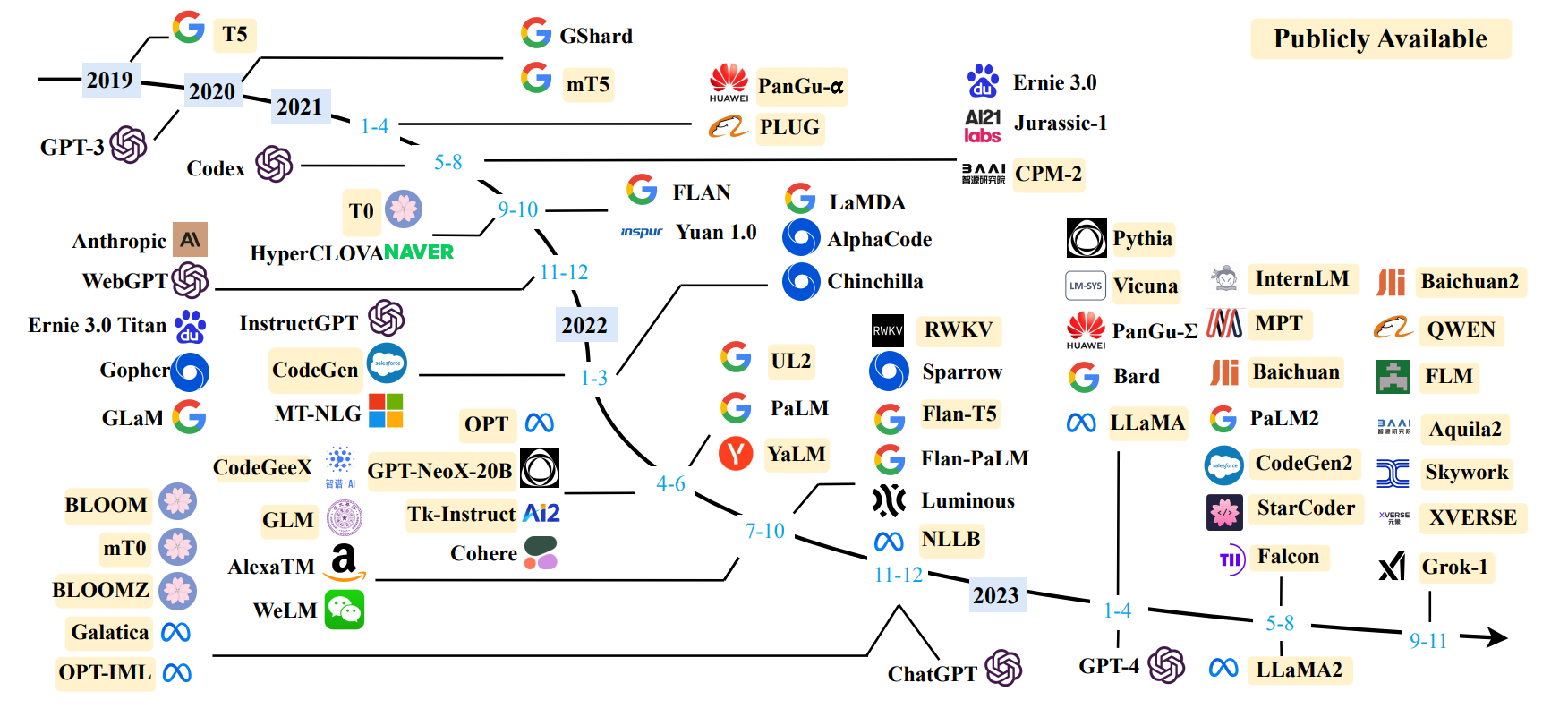
下面再补一张2019前的论文时间线图

分享目录
transformer原理-Attention Is All You Need -2017
GPT-1原理-Improving Language Understanding by Generative Pre-Training -2018
自注意力相对位置编码-Self-Attention with Relative Position Representations(待补充)
BERT原理-Pre-training of Deep Bidirectional Transformers for Language Understanding -2018
GPT-2原理-Language Models are Unsupervised Multitask Learners -2019
T5原理-Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer -2019(待补充)
GPT-3原理-Language Models are Few-Shot Learners -2019(待补充)
【动态更新中】















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









