







目录
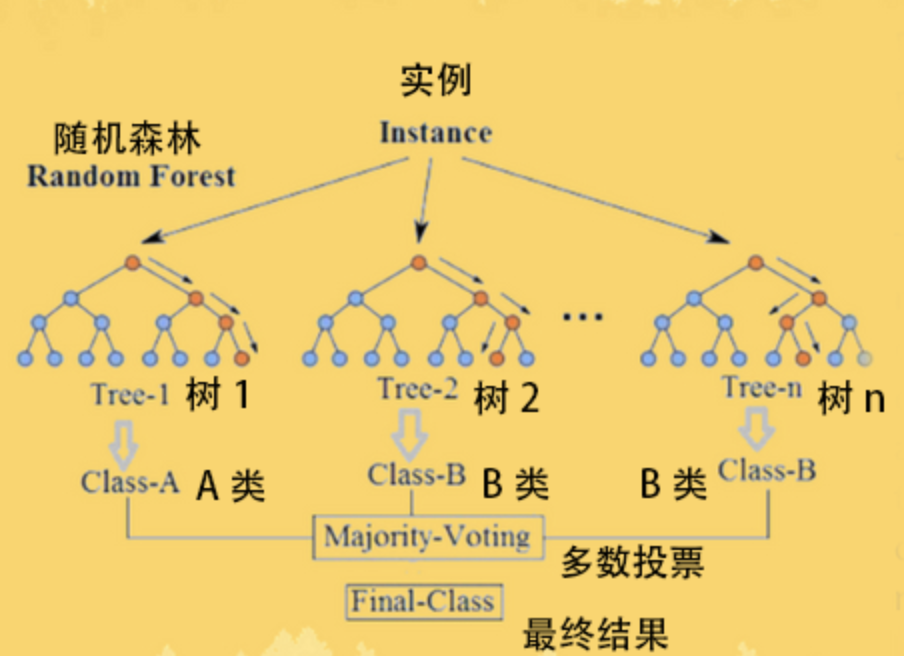
随机森林作为一种强大的集成学习方法,在机器学习领域中占据着重要地位。它由多个决策树组成,通过集成这些决策树的预测结果来进行分类和回归任务。
随机森林能够处理高维数据,这得益于其随机选择特征的方式。在构建每棵决策树时,随机森林会从全部特征中随机选择一个特征子集,然后从中选择最佳特征进行分裂。这种方式使得随机森林能够有效地处理高维数据,并且不需要进行特征选择或降维处理。
随机森林不易过拟合的特性使其在实际应用中表现出色。每棵树的训练样本是随机的,且训练特征集合也是随机抽取的,这增加了模型的多样性,减小了过拟合的风险。例如,在一个包含 1000 个样本、10 个特征的数据集上,随机森林通过有放回抽样从原始数据集中抽取多个子集,每个子集用于训练一棵决策树。同时,从全部特征中随机选择一部分特征进行训练,使得每棵决策树都有所不同。这样,当把这些树组合在一起时,过拟合的部分就会自动被消除掉。
随机森林的应用场景非常广泛。在金融领域,可用于信用评分、风险预测等;在医疗领域,可用于疾病预测、药物研发等;在自然语言处理中,可用于情感分析、文本分类等;在电子商务中,可用于推荐系统、用户分类等。
总之,随机森林以其强大的性能和广泛的应用场景,成为了机器学习领域中不可或缺的一部分。
二、Java 实现随机森林的步骤
(一)收集数据
首先,我们需要收集用于训练和测试的数据集。这里的数据集可以是任何关于分类或回归问题的数据集,例如鸢尾花数据集、泰坦尼克号乘客生存预测数据集等。以鸢尾花数据集为例,它包含了 150 个样本,每个样本有 4 个特征,分别是花萼长度、花萼宽度、花瓣长度和花瓣宽度,以及对应的类别标签,分为三种鸢尾花类别。收集到这样的数据集后,我们就可以进行后续的处理和分析。
(二)准备数据
在准备数据阶段,我们需要对收集到的数据进行一些预处理操作,以便能够正确应用随机森林算法。具体的预处理操作包括:
- 数据清洗:处理缺失值、异常值等。比如对于数值型数据,可以使用均值、中位数等方法填充缺失值;对于异常值,可以通过设定阈值进行剔除或修正。
- 特征选择:选择与目标变量相关性较高的特征。可以使用相关系数、信息增益等方法进行特征选择,以提高模型的性能和效率。
- 数据划分:将数据集划分为训练集和测试集。通常可以按照一定的比例进行划分,如 70% 的数据作为训练集,30% 的数据作为测试集。
(三)构建决策树
随机森林算法是通过构建多个决策树来进行分类或回归的。在构建决策树阶段,我们需要进行以下操作:
- 随机选择数据特征:随机选择一部分特征用于构建决策
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1751
1751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









