







LDMVFI:使用潜在扩散模型的视频帧插值
Duolikun Danier, Fan Zhang, David Bull
University of Bristol
paper, code, AAAI2024
文章目录
Abstract
现有的视频帧插值(VFI)的工作大多采用深度神经网络,这些网络通过最小化输出和地面真实帧之间的L1、L2或深度特征空间距离(例如VGG损失)来训练。然而,最近的研究表明,这些指标是感知VFI质量的较差指标。为了发展面向感知的VFI方法,在这项工作中,我们提出了基于潜在扩散模型的VFI,LDMVFI。这将从生成的角度来处理VFI问题,并将其表述为一个条件生成问题。作为使用潜在扩散模型来解决VFI问题的首要努力,我们严格地在现有的VFI文献中使用的常见测试集上对我们的方法进行了基准测试。我们的定量实验和用户研究表明,即使是在高分辨率的情况下,LDMVFI也能够以良好的感知质量插入视频内容。
1. Introduction
Video frame interpolation (VFI)技术和实际应用。现有的VFI方法主要基于深度神经网络,这些深度模型在建筑设计和运动建模方法上有所不同,但大多是通过训练来最小化L1、L2或VGG,特征在它们的输出和地面真实中间帧之间的距离。然而,这些优化目标并不能表明插值视频的感知质量,因为它们与人类判断的相关性很差。现有的方法虽然达到了较高的PSNR值,但往往在感知上表现不佳,特别是在具有复杂运动的动态纹理的具有挑战性场景中。
提高VFI方法感知性能的一个潜在方法是为训练VFI模型开发更准确的感知指标,这是另一个研究领域的重点,即视频质量评估。在这项工作中,我们不是依赖于特定的度量,而是探索了基于扩散模型的面向感知的VFI的新方向。然而,尽管VFI能够合成高深度的视觉内容,但其扩散模型的应用尚未得到充分的研究。
在上述背景下,我们提出了一个视频帧插值的潜在扩散模型(LDMVFI),其中VFI被表示为一个条件图像生成问题。具体来说,我们采用了最近提出的潜在扩散模型(Rombachetal.2022)(LDM),在一个包含自动编码模型的框架内,将图像投射到一个潜在空间,和一个去噪的U-Net,它在该潜在空间中执行反向扩散过程。为了更好地使LDMs适应VFI,我们设计了VFI专用组件,特别是一种新的基于向量量化的VFI自编码模型VQ-FIGAN,该方法显示出了比普通的LDMs更好的性能。
这项工作是利用潜在扩散模型来解决VFI作为一个条件生成问题,也是展示面向感知的VFI的新范式的潜力。贡献总结如下:
- 提出了LDMVFI,一种基于潜在扩散的方法,利用扩散模型的高模型图像合成能力来执行VFI。
- 在LDMs中引入了新的VFI特殊组件,包括向量量化自编码模型VQ-FIGAN,这进一步提高了VFI的性能。
- 我们通过定量和定性实验证明,所提出的方法优于先进的技术。
2. Related Work
Video Frame Interpolation.
Diffusion Models.
3. LDMVFI
给定一个视频中的两个连续的帧 I 0 I^{0} I0, I 1 I^{1} I1,VFI的目标是生成不存在的中间帧 I n I^{n} In,其中 n = 0.5 n = 0.5 n=0.5用于 × 2 \times2 ×2的上采样。从生成的角度理解VFI,目标是使用数据集 D = { I s 0 , I s n , I s 1 } s = 1 S D=\left\{ I^{0}_{s}, I^{n}_{s}, I^{1}_{s} \right\}^{S}_{s=1} D={Is0,Isn,Is1}s=1S来学习条件分布 p ( I n ∣ I 0 , I 1 ) p(I^{n}|I^{0}, I^{1}) p(In∣I0,I1)的参数近似。采用LDM对VFI进行条件生成。提出的LDMVFI包含两个主要组成部分:(i)VFI专用自编码模型VQ-FIGAN,它将视频帧投影到潜在空间,并从潜在编码重构目标框架;(ii)去噪U-Net,在潜在空间中执行反向扩散过程,用于条件图像生成。图1展示了LDMVFI的框架。

3.1. Latent Diffusion Models
潜在扩散模型(LDMs)建立在去噪扩散概率模型(DDPM,以下称为扩散模型)之上,它是一类生成模型,通过学习长度为
T
T
T的预定义马尔可夫链的反向过程(即正向过程)来学习数据分布
p
(
x
)
p(x)
p(x),该过程逐渐向数据添加高斯噪声。具体地说,一个有时间条件的神经网络
ϵ
θ
=
(
x
t
,
t
)
\epsilon _{\theta }=(x_{t},t)
ϵθ=(xt,t)被训练成在步骤
t
=
1
,
.
.
.
,
T
t = 1, ..., T
t=1,...,T 去噪数据,目标函数
L
D
M
=
E
x
0
,
ϵ
∼
N
(
0
,
I
)
,
t
∼
U
(
1
,
T
)
[
∥
ϵ
−
ϵ
θ
(
x
t
,
t
)
∥
2
]
,
\mathcal{L}_{DM}=\mathbb{E}_{x_{0},\epsilon \sim \mathcal{N}\left ( 0,I \right ),t \sim \mathcal{U} \left ( 1,T \right ) } \left [ \left \| \epsilon - \epsilon_{\theta }\left ( x_{t}, t \right ) \right \| ^{2} \right ] ,
LDM=Ex0,ϵ∼N(0,I),t∼U(1,T)[∥ϵ−ϵθ(xt,t)∥2],
其中,
x
t
x_{t}
xt是从正向扩散过程中采样的,
U
(
1
,
T
)
\mathcal{U}(1,T)
U(1,T)表示在
{
1
,
.
.
.
,
T
}
\left \{ 1, ..., T \right \}
{1,...,T}上的均匀分布。这对应于
log
p
(
x
)
\log p(x)
logp(x)上的变分下界的一个重新加权版本。
为了对新的图像进行采样,我们可以从一个高斯噪声开始,然后使用去噪网络 ϵ θ \epsilon_{\theta} ϵθ对其进行逐步去噪。在条件生成设置下,我们可以对 ϵ θ \epsilon_{\theta} ϵθ附加一个输入 y y y,它可以表示VFI上下文中的两个输入帧。
潜在扩散模型包含一个图像编码器
E
:
x
↦
z
E:x\mapsto z
E:x↦z,它将一个图像
x
x
x编码为一个低维的潜在表示
z
z
z,以及一个解码器
D
:
z
↦
x
D: z \mapsto x
D:z↦x来重建图像
x
x
x。正向扩散和反向扩散过程发生在潜在空间中,学习反向扩散过程的训练目标是
L
L
D
M
=
E
E
(
x
0
)
,
ϵ
∼
N
(
0
,
I
)
,
t
∼
U
(
1
,
T
)
[
∥
ϵ
−
ϵ
θ
(
z
t
,
t
)
∥
2
]
.
\mathcal{L}_{LDM}=\mathbb{E}_{E(x_{0}),\epsilon \sim \mathcal{N}\left ( 0,I \right ),t \sim \mathcal{U} \left ( 1,T \right ) } \left [ \left \| \epsilon - \epsilon_{\theta }\left ( z_{t}, t \right ) \right \| ^{2} \right ] .
LLDM=EE(x0),ϵ∼N(0,I),t∼U(1,T)[∥ϵ−ϵθ(zt,t)∥2].
通过将图像投影到一个紧凑的潜在空间,LDM允许扩散过程集中在数据语义的重要部分,并使高效计算的采样过程。
3.2. Autoencoding with VQ-FIGAN
在LDM的原始形式中,自编码模型 { E , D } \{E,D\} {E,D}被认为是一个感知的图像编解码器。它解码符号的目的是将图像投影到有效的潜在表示中,在编码过程中去除高频细节,并在解码中恢复。然而,在VFI的背景下,这些信息可能会影响被插值视频的感知质量,因此解码器有限的重构能力会对VFI的性能产生负面影响。为了增强高频细节恢复,我们提出了一个VFI专用的自动编码模型: VQFIGAN,如图2所示。虽然主干模型使用的原始VQGAN相似,但有三个主要的区别。

首先,利用VFI任务的一个特性——在推理过程中相邻的帧可用,设计一个帧辅助解码器。特别地说,给定地面-真实的目标帧 I n ∈ R H × W × 3 I^{n}\in\mathbb{R}^{H \times W \times 3} In∈RH×W×3编码器 E E E产生潜在的编码 z n = E ( I n ) z^{n}=E(I^{n}) zn=E(In),这里的 z n ∈ R H f × W f × 3 z^{n}\in\mathbb{R}^{\frac{H}{f}\times\frac{W}{f}\times3} zn∈RfH×fW×3, f f f是一个超参数(图2显示了 f = 4 f=4 f=4的情况)。然后,解码器 D D D输出重构帧 I ^ n \hat{I}^{n} I^n,取输入 z n z^{n} zn,以及 E E E从相邻两帧 I 0 I^{0} I0、 I 1 I^{1} I1中提取的特征金字塔 ϕ 0 \phi^{0} ϕ0、 ϕ 1 \phi^{1} ϕ1 。在解码期间,这些特征金字塔融合解码特性 z n z^{n} zn在多层使用MaxCA块,新设计MaxViT基于交叉注意块,查询嵌入注意机制生成使用解码特性 z n z^{n} zn,和关键和值嵌入从 ϕ 0 \phi^{0} ϕ0、 ϕ 1 \phi^{1} ϕ1 。
其次,原始的VQGAN使用了full self-attention,就像视觉Transformer一样,这可能是大量计算(二次复杂度)和内存密集型的,特别是当图像分辨率很高时。为了对高分辨率(如全高清)视频进行更有效的推理,使用最近提出的MaxViT块来执行self-attention。MaxViT块中的多轴自注意层结合了窗口注意和扩展网格注意,同时执行局部和全局操作,同时实现了相对于输入大小的线性复杂度。
第三,所提出的VQ-FIGAN不是让解码器直接输出重构图像
I
^
n
\hat{I}^{n}
I^n,而是输出基于可变形卷积的插值核,以提高VFI性能。具体地说,假定
H
H
H,
W
W
W是帧的高度和宽度,解码器网络的输出包含了具有大小的局部自适应可变形卷积核的参数
K
×
K
:
{
Ω
τ
,
α
τ
,
β
τ
}
K\times K: \{\Omega^{\tau}, \alpha^{\tau}, \beta^{\tau} \}
K×K:{Ωτ,ατ,βτ},
τ
=
0
,
1
\tau=0, 1
τ=0,1是输入帧的索引。这里的
Ω
∈
[
0
,
1
]
H
×
W
×
K
×
K
\Omega\in[0,1]^{H\times W \times K \times K}
Ω∈[0,1]H×W×K×K是它们的空间偏移(分别为水平和垂直)。考虑到遮挡,解码器还输出一个可见图
v
∈
[
0
,
1
]
H
×
W
v\in[0, 1]^{H \times W}
v∈[0,1]H×W,以及残差图
δ
∈
R
H
×
W
\delta \in \mathbb{R}^{H\times W}
δ∈RH×W,以进一步提高VFI性能。为了生成插值帧,需要有部分局部自适应的可变形卷积对每个输入帧
{
I
τ
}
τ
=
0
,
1
\{I^{\tau}\}_{\tau=0,1}
{Iτ}τ=0,1操作
I
n
τ
(
h
,
w
)
=
∑
i
=
1
K
∑
j
=
1
K
Ω
h
,
w
τ
(
i
,
j
)
⋅
P
h
,
w
τ
(
i
,
j
)
,
I^{n\tau}(h,w)=\sum^{K}_{i=1}\sum^{K}_{j=1}\Omega^{\tau}_{h,w}(i,j)\cdot P^{\tau}_{h,w}(i,j),
Inτ(h,w)=i=1∑Kj=1∑KΩh,wτ(i,j)⋅Ph,wτ(i,j),
P
h
,
w
τ
=
I
τ
(
h
+
α
h
,
w
τ
(
i
,
j
)
,
w
+
β
h
,
w
τ
(
i
,
j
)
)
P^{\tau}_{h,w}=I^{\tau}(h+\alpha^{\tau}_{h,w}(i,j), w+\beta^{\tau}_{h,w}(i,j))
Ph,wτ=Iτ(h+αh,wτ(i,j),w+βh,wτ(i,j))
其中,
I
n
τ
I^{n\tau}
Inτ表示
I
τ
I^{\tau}
Iτ得到的结果,
P
h
,
w
τ
P^{\tau}_{h,w}
Ph,wτ是从
I
τ
I^{\tau}
Iτ采样的输出位置
(
h
,
w
)
(h,w)
(h,w)。然后使用可视图和残差图将这些中间结果结合起来:
I
^
n
=
v
⋅
I
n
0
+
(
1
−
v
)
⋅
I
n
1
+
δ
\hat{I}^{n}=v\cdot I^{n0}+(1-v)\cdot I^{n1}+\delta
I^n=v⋅In0+(1−v)⋅In1+δ
采用可分离可变形卷积实现,该实现利用内核的可分离性特性,在保持VFI性能的同时减少内存。
3.3. Conditional Generation with LDM
经过训练的VQ-FIGAN允许访问一个紧凑的潜在空间,根据预先设定的噪声计划逐步加入目标帧 I n I^{n} In的潜在高斯噪声 z n z^{n} zn来执行前向扩散,并学习反向(去噪)过程来执行条件生成。为此,采用DMs的噪声预测参数化,通过最小化条件对数似然 log p θ ( z n ∣ z 0 , z 1 ) \log p_{\theta}(z^{n}|z^{0},z^{1}) logpθ(zn∣z0,z1)的重加权变分下界来训练去噪U-Net,这里的 z 0 , z 1 z^{0}, z^{1} z0,z1是两个输入帧的潜在编码。
Training.
特别,去噪U-Net
∈
θ
\in\theta
∈θ作为输入目标帧
I
n
I^{n}
In潜在编码
z
t
n
z^{n}_{t}
ztn(采样从
t
t
t步向前扩散过程的长度
T
T
T),扩散
t
t
t步,以及输入帧
I
0
,
I
1
I^{0}, I^{1}
I0,I1的条件延迟
z
0
z^{0}
z0,
z
1
z^{1}
z1。它被训练通过最小化来预测每个时间步
t
t
t添加到
z
n
z^{n}
zn的噪声
L
=
E
z
n
,
z
0
,
z
1
,
ϵ
∼
N
(
0
,
I
)
,
t
[
∥
ϵ
−
ϵ
θ
(
z
t
n
,
t
,
z
0
,
z
1
)
∥
2
]
,
\mathcal{L}=\mathbb{E}_{z^{n},z^{0},z^{1},\epsilon\sim\mathcal{N}(0,I),t } \left [ \left \| \epsilon -\epsilon_{\theta }(z^{n}_{t},t,z^{0},z^{1}) \right \|^{2} \right ] ,
L=Ezn,z0,z1,ϵ∼N(0,I),t[
ϵ−ϵθ(ztn,t,z0,z1)
2],
其中
t
∼
U
(
1
,
T
)
t\sim\mathcal{U}(1,T)
t∼U(1,T)。关于
ϵ
θ
\epsilon_{\theta}
ϵθ的训练程序的推导和全部细节见补充说明。直观地说,训练是通过根据预先设定的噪声计划在
z
n
z^{n}
zn中交替添加随机高斯噪声,并让网络
ϵ
θ
\epsilon_{\theta}
ϵθ预测给定步骤
t
t
t的噪声,条件
z
0
,
z
1
z^{0}, z^{1}
z0,z1。
Inference.
为了从
I
0
I^{0}
I0,
I
1
I^{1}
I1开始插值
I
^
n
\hat{I}^{n}
I^n,首先在潜在空间中采样一个高斯噪声
z
T
n
z^{n}_{T}
zTn,然后执行
T
T
T步去噪,直到得到
z
T
n
z_{T}^{n}
zTn。在每一步中,网络
ϵ
θ
\epsilon_{\theta}
ϵθ部分预测噪声
ϵ
^
\hat{\epsilon}
ϵ^。然后利用
ϵ
^
\hat{\epsilon}
ϵ^和预处理的相关参数
z
t
−
1
n
z^{n}_{t-1}
zt−1n计算前向过程。最后,解码器
D
D
D从
I
0
,
I
1
I^{0}, I^{1}
I0,I1中,利用特征金字塔
ϕ
0
,
ϕ
1
\phi^{0}, \phi^{1}
ϕ0,ϕ1从去噪的潜在
z
0
n
z^{n}_{0}
z0n中提取插值帧。
Network Architecture.
对 ϵ θ \epsilon_{\theta} ϵθ使用时间条件的U-Net,但有一个修改:所有 vanilla自我注意块被上述MaxViT块取代,以获得计算效率。U-Net的调节机制是 z t n z^{n}_{t} ztn和 z 0 z^{0} z0, z 1 z^{1} z1在输入处的连接。
4. Experimental Setup
Implementation Details.
重复编码器中的
R
e
s
N
e
t
B
l
o
c
k
+
C
o
n
v
3
×
3
ResNetBlock+Conv3\times3
ResNetBlock+Conv3×3层三次,将VQ-FIGAN的降采样因子设置为
f
=
32
f=32
f=32(见图2)。解码器输出的内核的大小为
K
=
5
K = 5
K=5。关于扩散过程,采用线性噪声计划和8192的码本大小在VQ-FIGAN中进行矢量量化。使用DDIM采样器从所有扩散模型中进行采样,共进行200步采样。使用ADAM优化器和使用Adam-W优化器训练VQ-FIGAN,初始学习速率分别设置为
1
0
−
5
10^{−5}
10−5和
1
0
−
6
10^{−6}
10−6。所有的模型都被训练到收敛,VQ-FIGAN对应大约70 epochs,U-Net对应大约60 epochs。所有的训练和评估都使用了NVIDIA RTX 3090GPUs。
Training Dataset.
使用VFI中最常用的训练集,Vimeo90k。然而,之前的工作已经讨论了有限的运动幅度范围和Vimeo90k的多样性。为了更好地测试VFI方法在更广泛的场景下的学习能力和性能,额外合并来自BVI-DVC数据集的样本。因此,fnal训练集分别包括来自Vimeo90k-septuplets和BVI-DVC的64612帧和17600帧三联体(仅使用中心的三帧)。为了增强数据,随机crop 256×256 patches,并进行随机固定和时间顺序反转。值得注意的是,大多数现有的工作只使用Vimeo90-septuplets进行训练,因此,我们还提供了仅在该数据集上训练的LDMVFI的评估结果,以供参考。
Test Datasets.
在常用的VFI基准上评估模型,Middlebury (Baker et al. 2011), UCF-101 (Soomro, Zamir, and Shah 2012),
DAVIS (Perazzi et al. 2016), SNU-FILM (Choi et al. 2020), 和 VFITex (Danier, Zhang, and Bull 2022c)。这些测试集涵盖了从225×225到4K的分辨率,以及不同水平的VFI差异。为了进一步评估感知表现,我们使用BVI-HFR (Mackin,Zhang, and Bull 2018)它涵盖了广泛的纹理和运动类型的数据集。
Evaluation Methods.
由于本工作的主要重点是提高插值内容的感知质量,我们采用感知图像质量度量LPIPS(Zhang等人2018)和定制的VFI度量FloLPIPS(Danier,Zhang和Bull 2022b)进行性能评估。与常用的质量测量方法、PSNR和SSIM相比,这些指标与人类的VFI质量判断具有优越的相关性(Wang et al. 2004)。我们还评估了FID(Heusel et al. 2017),它测量了插值帧和地面真实帧分布之间的相似性;这之前被用作视频压缩(Yang、Timofte和Van Gool 2022)、增强(Yang 2021)和着色(Kang et al. 2023)的感知度量。
为了测量VFI方法的真实感知性能,我们还进行了一个心理物理实验,并将所提出的方法与目前的技术水平进行了比较(see Sec. 5.2).为了完整起见,我们还在补充版中提供了基于PSNR和SSIM的基准结果,注意到这些结果在重构插值内容的感知质量(Danier,Zhang,和Bull 2022d)方面是有限的,因此不是本文的重点。
5. Experiments
5.1. Quantitative Evaluation
提出LDMVFI与最近SOTA的10个VFI方法,BMBC (Park et al. 2020), AdaCoF (Lee et al. 2020), CDFI (Ding et al. 2021), XVFI (Sim, Oh, and Kim 2021), ABME (Park, Lee, and Kim 2021), IFRNet (Kong et al. 2022), VFIformer (Lu et al. 2022), ST-MFNet (Danier, Zhang, and Bull 2022c), FLAVR (Kalluri et al. 2023), 和 MCVD (Voleti, JolicoeurMartineau, and Pal 2022)。它指出,MCVD是唯一现有的基于扩散的VFI方法。所有这些模型都在我们的训练数据集上重新训练,以便进行公平的比较。
Performance.
表1显示了评估方法在 Middlebury, UCF-101, DAVIS, 和 VFITex测试集上的性能。需要注意的是,Middebury和UCF-101上的FID分数可能不可靠,因为它们包含的测试帧很少(分别为12和100)。从表中可以看出,LDMVFI在大多数情况下优于所有其他VFI方法,并且与第二优方法相比的性能提高是最显著的。VFITex主要包含动态纹理(如边缘、水、树叶),并呈现出复杂的运动(见补充文件中的进一步讨论)。
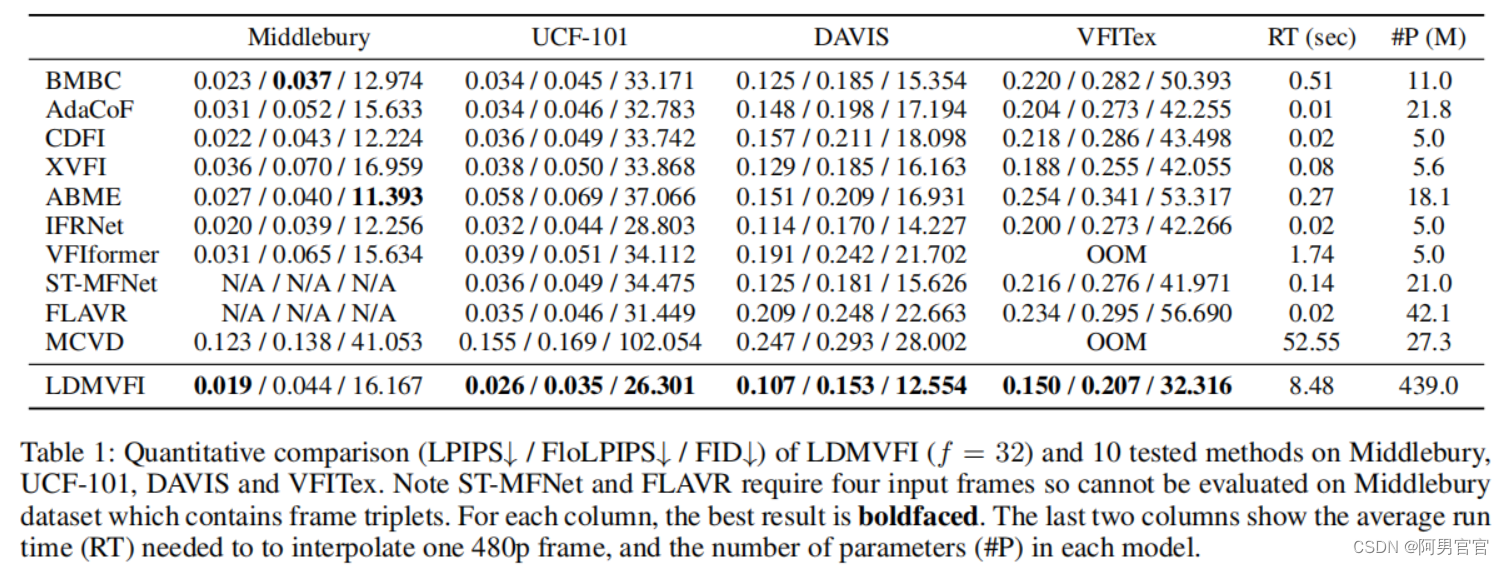
表2总结了SNU-FILM数据集的四个分割模型上的性能,这再次证明了LDMVFI插值的视频的良好感知质量。这也意味着另一种基于扩散的VFI方法MCVD总体上不能令人满意,直接将原始扩散模型公式应用于VFI不足以提高性能。这进一步证明了LDMVFI的有效性。多帧(即×4)的插值结果在补充文件中提供。

Complexity.
在单块RTX 3090 GPU上插值480p帧所需的平均时间和每个模型的参数数如表1(最后两列)所示。据观察,LDMVFI的推理速度比其他方法要低得多,这主要是由于在采样过程中执行的迭代去噪操作。这是现有扩散模型的一个常见缺点。人们提出了各种方法来加快扩散模型的采样过程,这也可以应用于LDMVFI。LDMVFI中的参数数量也很大,因为采用了(通过一些修改,see Sec. 3.2)现有的去噪U-Net设计用于通用图像生成。
5.2. Subjective Experiment
为了进一步提高LDMVFI插值的视频的感知质量,并测量其时间一致性,我们进行了一个主观实验,雇佣人类参与者来对我们和竞争方法插值的视频质量进行评分。
Test Videos.
使用来自BVI-HFR数据集的22个高质量的全高清30fps视频作为源内容。这些视频涵盖了与运动和纹理相关的广泛视频特征,如原始论文的分析所示,允许对VFI方法进行更彻底的基准测试。为了生成测试内容,这22个视频随后被直接截断到5秒(150帧)。然后,使用四种不同的VFI方法将所有视频插值到60fps。除LDMVFI外,测试方法包括ST-MFNet、IFRNet和BMBC,它们在更具挑战性的测试集(如DAVIS、SNU-FILMmexorl)上显示出最具竞争力的定量性能。结果,我们获得了四种VFI方法生成的88个测试视频。
Test Methodology.
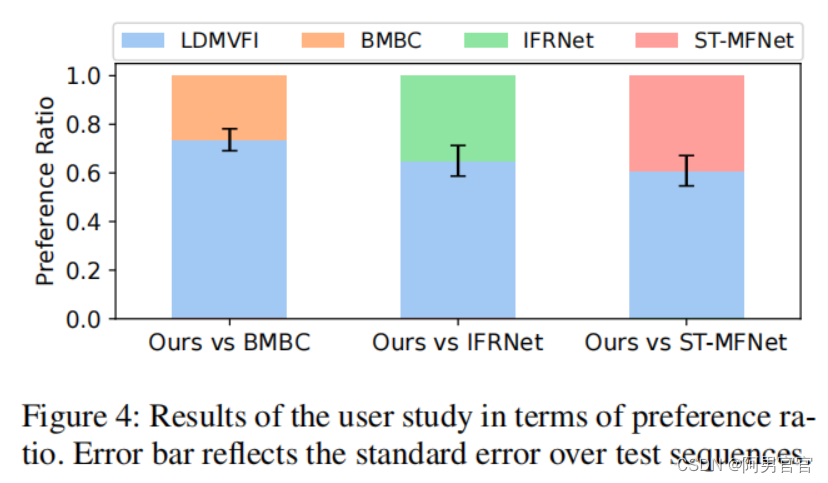
根据之前的工作,主观实验采用2AFC方法,要求参与者从一对视频中选择感知质量较好的视频。具体地说,在每个测试阶段,参与者展示了66对视频,每对视频中的一个视频由LDMVFI插值,另一个视频由ST-MFNet、IFRNet或BMBC插值。66对测试视频的显示顺序和每对测试视频的显示顺序都是随机的。用户不知道用于生成视频的方法。每对视频被呈现两次,然后要求参与者回答“两个视频中哪一个质量更高?”的问题。总共雇佣了20名参与者。详情请参见补充资料。
Results.
在收集了所有的用户数据后,对于22个源序列中的每一个,计算出首选LDMVFI的用户比例。图4报告了对LDMVFI的平均偏好比和对序列的标准误差。可以看出,在所有的比较中,LDMVFI都获得了更高的偏好比。对序列偏好比的T-检验分析(见补充)表明,在95%的可信度水平上,LDMVFI相对于其他三种测试方法的优势在统计学上是显著的。这些结果进一步证实了LDMVFI优越的感知表现。
Visual Examples.
图3显示了由LDMVFI和竞争方法插值的示例帧,表明LDMVFI结果具有最好的视觉质量。

5.3. Ablation Study
本节通过实验验证和研究了LDMVFI中的不同成分和超参数。消融研究结果总结在表3中,其中显示了该模型的6个变体在三个测试集上的评价结果。完整的消融研究结果见补充资料,其中分析了模型的更多方面,包括对LDMVFI结果的可变性的讨论。

Effectiveness of VQ-FIGAN.
Downsampling Factor f f f.
Effectiveness of Diffusion Process.















 1207
1207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









