







视频帧插值的运动感知潜在扩散模型
Zhilin Huang1,2* Yijie Yu1,2* Ling Yang3 Chujun Qin4 Bing Zheng1,2 Xiawu Zheng2,5 Zikun Zhou2† Yaowei Wang2 Wenming Yang1,2†
1 Tsinghua University 2 Peng Cheng Laboratory 3 Peking University 4 China Southern Power Grid 5 Xiamen University
paper, code
Abstract
对于VFI任务,相邻帧间的运动估计对避免运动模糊性起着至关重要的作用。然而,现有的VFI方法总是难以准确预测连续帧之间的运动信息,这种不精确的估计会导致帧模糊和视觉上不相干的插值帧。本文提出了一种新的扩散框架,运动感知潜在扩散模型(MADIFF),它是专门为VFI任务设计的。通过在整个扩散采样过程中结合条件相邻帧与目标插值帧之间的运动先验,MADIFF逐步细化中间结果,最终产生视觉上平滑和真实的结果。在基准数据集上进行的大量实验表明,我们的方法取得了显著超过现有方法的最先进的性能,特别是在涉及具有复杂运动的动态纹理的具有挑战性的场景下。
Introduction
然而,这些基于深度学习的VFI方法往往会产生不真实的纹理、伪影和低感知的结果。原因是优化目标的主要贡献者-因此模型的最终性能-仍然是它们的输出和真插值帧之间基于L1/ L2的失真损失。
扩散模型将VFI任务作为有条件图像生成的一种形式,通过将相邻帧进入去噪网络,以进行目标插值帧生成。然而,这些方法并不能明确地模拟插值帧与给定的相邻条件帧之间的帧间运动,这是防止由于运动模糊而产生模糊插值帧的关键因素。这在涉及复杂的运动、遮挡或亮度突变的复杂动态场景中尤为重要。
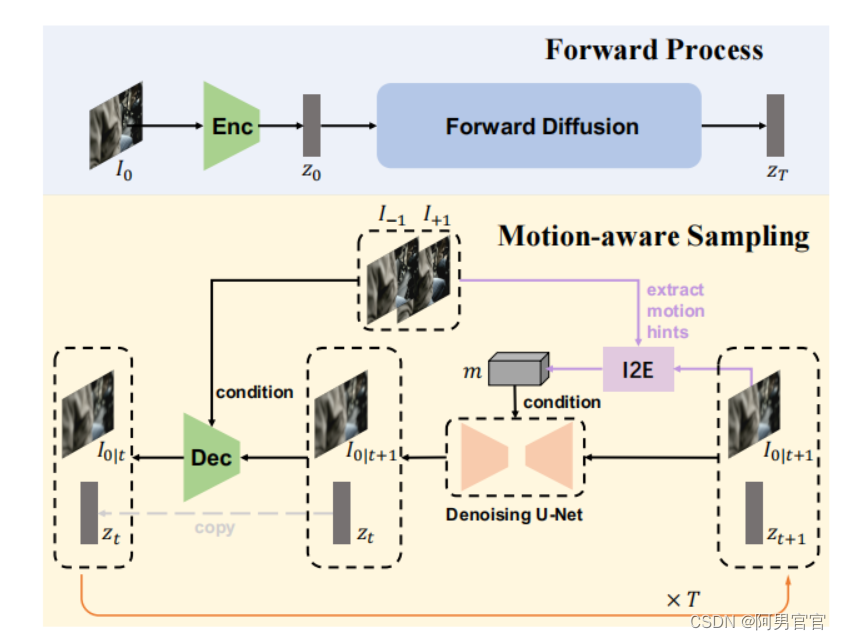
为了解决这些挑战,本文提出了一种新的潜在扩散框架,即运动感知潜在扩散模型(MADIFF),用于视频帧插值任务。具体来说,采用最近提出的潜在扩散模型(LDMs)。LDM包括一个将图像映射到潜在空间的自动编码器和一个去噪的Unet,它在潜在空间内执行反向扩散过程,形成了框架的基础。为了将给定条件相邻帧与插值帧之间的帧间运动先验合并到MADIFF中,提出了一种新的向量量化运动感知生成对抗网络,VQMAGAN。
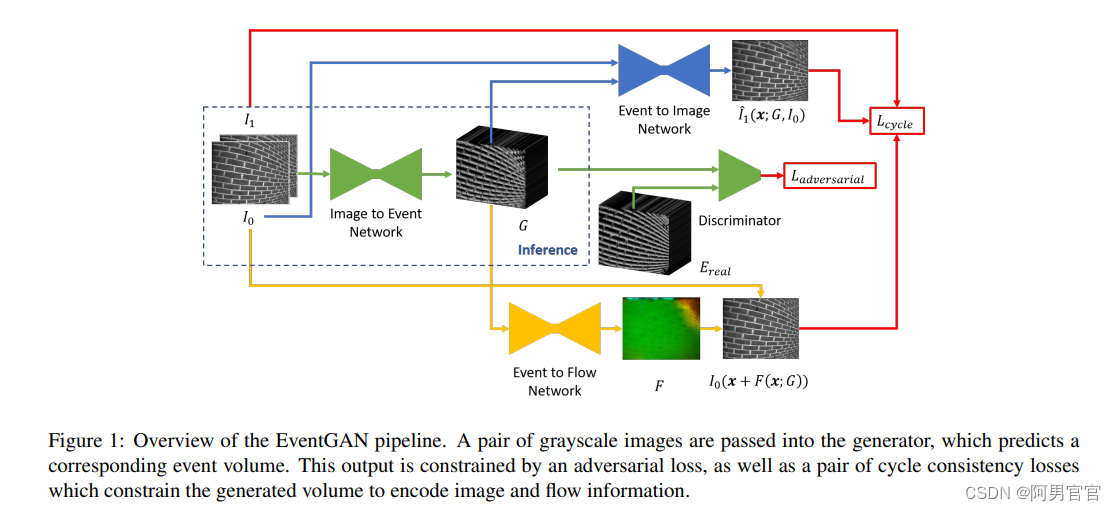
首先使用预训练过的EventGAN来预测反映连续两帧之间像素级强度变化的事件。随后,利用插值帧与相邻两个条件帧之间的事件体量作为运动提示,以增强VQ-MAGAN解码器内的图像重建。VQ-MAGAN具有在帧间运动提示的指导下,通过聚合给定相邻帧的上下文细节来预测目标插值帧的能力。此外,对于LDM中的去噪过程,将插值帧和相邻两个帧之间的运动提示作为附加条件。
在VQ-MAGAN和去噪U-Net的训练过程中,直接利用地面真实插值帧来提取插值帧与相邻条件帧之间的帧间运动提示。由于在LDM采样过程中地面真插值帧是未知的,因此在插值帧与条件相邻帧之间提取运动提示是不可行的。为了消除采样阶段和训练阶段之间运动线索提取的差异,使采样过程中的运动线索可用,提出了一种新的运动感知采样方法(MA-SAMPLING)。
具体来说,在采样过程中,使用前一个时间步长中预测的粗插值帧与条件相邻帧一起提取帧间运动提示。然后将提取的运动提示输入VQ-MAGAN和去噪U-Net,用于预测当前时间步长中的插值帧。通过逐步细化插值帧,MADIFF可以有效地将帧间的运动提示集成到采样过程中,从而产生视觉上的平滑和真实的帧。
在各种VFI基准数据集上进行的大量实验,包括低分辨率和高分辨率内容(高达4K),表明我们的MADIFF实现了最先进的性能,显著优于现有的方法,特别是在涉及具有复杂运动的动态纹理的具有挑战性的场景下。
Contribution:
- 本文提出了一种新的向量量化运动感知生成对抗网络VQ-MAGAN,该网络将目标插值帧与给定相邻条件帧之间的帧间运动提示充分整合到插值帧的预测中。
- 提出一种新的运动感知采样方法,MA-SAMPLING,以消除采样阶段和训练阶段之间运动提示提取的差异,使采样过程中运动提示的提取可行,并逐步细化预测的插值帧。
- 我们通过定量和定性的实验证明,所提出的方法达到了最先进的性能,显著优于现有的方法。
2. Related Work
2.1. Image-to-Event Generation
2.2. Video Frame Interpolation
3. Preliminary
3.1. Representation of Event Volume
每个事件
e
\mathbf{e}
e都可以用一个元组
(
x
,
y
,
t
,
p
)
(x,y,t,p)
(x,y,t,p)来表示,这里的
x
x
x和
y
y
y表示事件的空间位置,
t
t
t代表事件节点,
p
=
±
1
p=\pm1
p=±1表示两极。为了便于处理事件,事件分散到一个固定大小的三维时空volume中,其中每个事件
(
x
,
y
,
t
,
p
)
(x,y,t,p)
(x,y,t,p)插入到volume中,该volume具有
B
=
9
B = 9
B=9时间通道,具有一个线性核:
t
i
∗
=
(
B
−
1
)
⋅
t
i
−
t
1
t
N
−
t
1
,
V
(
x
,
y
,
t
)
=
∑
i
m
a
x
(
0
,
1
−
∣
t
−
t
i
∗
∣
)
.
t^{\ast}_{i}=(B-1)\cdot\frac{t_{i}-t_{1}}{t_{N}-t_{1}},\\ V(x,y,t)=\sum_{i}max(0,1-|t-t^{\ast}_{i}|).
ti∗=(B−1)⋅tN−t1ti−t1,V(x,y,t)=i∑max(0,1−∣t−ti∗∣).
这保留了事件在
x
-
y
-
t
x\text{-}y\text{-}t
x-y-t空间中的分布,并在许多任务中显示出了成功。
由于EventGAN生成的事件volume是不同极性的事件volume沿时间维度的连接,因此最终的事件volume是严格的非负的。在MADIFF中,直接利用EventGAN生成的事件volume作为帧间运动提示。
3.2. Latent Diffusion Models
LDMs是DDPM的变体,它在自动编码器的潜空间中执行去噪过程,即 E ( . ) \mathcal{E}(.) E(.)和 D ( . ) \mathcal{D}(.) D(.),由预训练的VQ-GAN或VQ-VAE实现。与在像素级数据中执行去噪过程相比,LDM可以在保持高视觉质量的同时降低计算成本。
对于LDM的训练,将随机采样训练图像
x
x
x的潜码
z
z
z转换为噪声,采用转移核定义的马尔可夫过程:
q
(
z
t
∣
z
t
−
1
)
=
N
(
z
t
;
α
t
z
t
−
1
,
(
1
−
α
)
I
)
q(z_{t}|z_{t-1})=\mathcal{N} (z_{t}; \sqrt{\alpha_{t} }z_{t-1} , (1-\alpha)\mathbf{I} )
q(zt∣zt−1)=N(zt;αtzt−1,(1−α)I)
这里的
t
=
1
,
2
,
.
.
.
,
T
t=1,2,...,T
t=1,2,...,T,
z
0
=
z
z_{0}=z
z0=z,而
α
t
\alpha_{t}
αt是一个控制噪声注入速率的超参数。当噪声量足够大时,
z
T
z_{T}
zT根据
N
(
0
,
I
)
\mathcal{N}(0,\mathbf{I})
N(0,I)近似分布。为了将噪声转换回数据,用于样本生成,通过学习反向转换核来估计反向扩散过程:
p
θ
(
z
t
−
1
∣
z
t
)
=
N
(
μ
θ
(
z
t
)
,
∑
θ
(
z
t
)
)
p_{\theta}(z_{t-1}|z_{t})=\mathcal{N}(\mu_{\theta}(z_{t}),\sum_{\theta}(z_{t}))
pθ(zt−1∣zt)=N(μθ(zt),θ∑(zt))
然后把它作为
q
(
z
t
−
1
∣
z
t
)
q(z_{t-1}|z_{t})
q(zt−1∣zt)的近似值。
μ
θ
(
z
t
)
\mu_{\theta}(z_{t})
μθ(zt)用神经网络
ϵ
θ
(
z
t
,
t
)
\epsilon_{\theta}(z_{t},t)
ϵθ(zt,t)(称为分数模型[63,64])参数化,
∑
θ
\sum_{\theta}
∑θ被固定为一个常数。评分模型可以通过去噪评分匹配的进行优化。在样本生成过程中,在每个时间步长内,去噪U-Net先预测
z
^
0
\hat{z}_{0}
z^0。最后,VQ-GAN或VQ-VAE的解码器从去噪的潜在表示
z
^
0
\hat{z}_{0}
z^0中生成图像
I
^
0
\hat{I}_{0}
I^0,而不考虑任何上下文信息。
4. Methods
4.1. Motion Hints Extraction
在MADIFF中,我们利用预先训练好的EventGAN来捕获插值帧与条件相邻帧之间的帧间运动提示。具体来说,给定插值帧
I
0
∈
R
H
×
W
×
3
I_{0}\in\mathbb{R}^{H\times W\times3}
I0∈RH×W×3和两个条件相邻帧
I
−
1
,
I
+
1
∈
R
H
×
W
×
3
I_{-1}, I_{+1}\in\mathbb{R}^{H\times W\times3}
I−1,I+1∈RH×W×3,其中
I
−
1
I_{-1}
I−1表示前一帧,
I
+
1
I_{+1}
I+1表示下一帧。运动提示提取过程表述如下:
m
−
1
→
0
=
f
I
2
E
(
I
−
1
,
I
0
)
m
0
→
+
1
=
f
I
2
E
(
I
0
,
I
+
1
)
m_{-1\to0}=f_{I2E}(I_{-1},I_{0})\\ m_{0\to+1}=f_{I2E}(I_{0},I_{+1})
m−1→0=fI2E(I−1,I0)m0→+1=fI2E(I0,I+1)
其
f
I
2
E
(
.
)
f_{I2E}(.)
fI2E(.)为预训练的EventGAN,
m
i
→
j
m_{i\to j}
mi→j表示从帧
i
i
i到帧
j
j
j提取的运动提示。在实践中,我们直接使用预测的事件volume
E
V
i
→
j
∈
R
H
×
W
×
(
2
×
B
)
EV_{i\to j}\in \mathbb{R}^{H\times W\times(2\times B)}
EVi→j∈RH×W×(2×B)作为
m
i
→
j
m_{i\to j}
mi→j。此外,我们提出的MADIFF是一个通用的框架,它可以轻松地融入不同的运动相关模型。
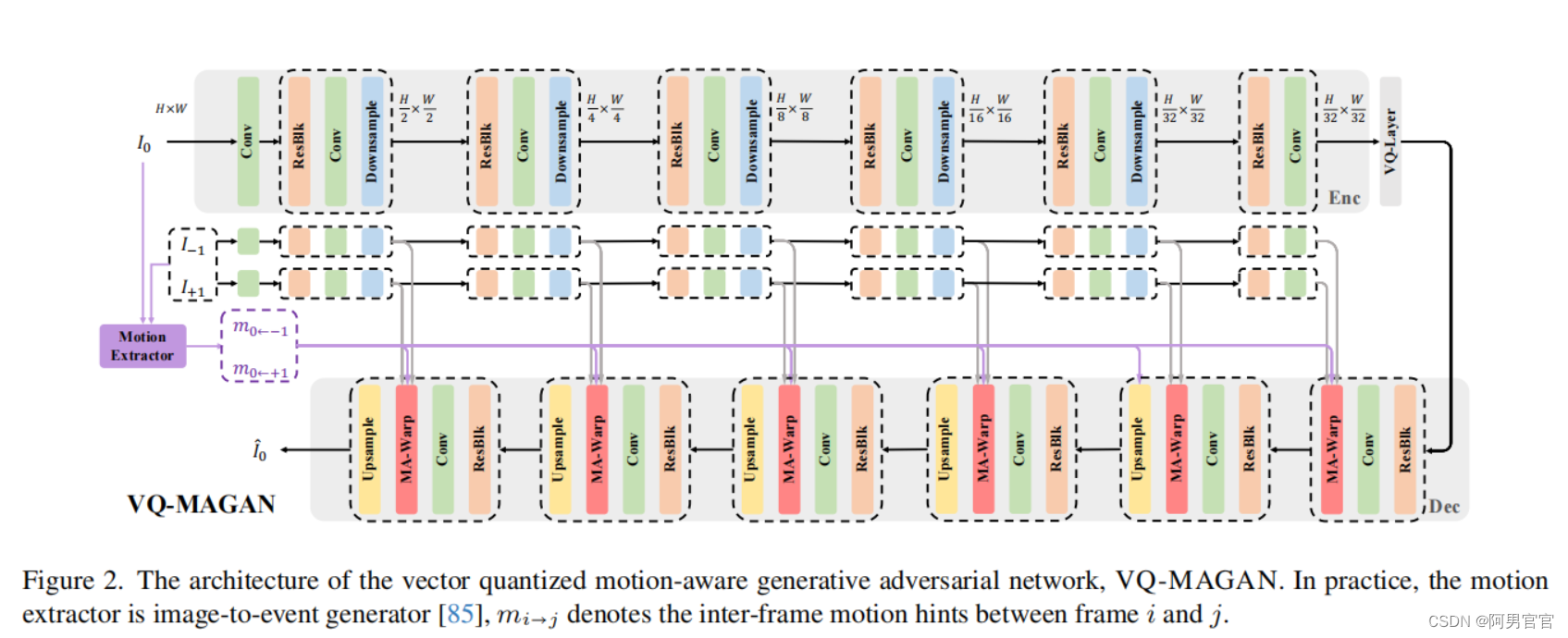
4.2. VQ-MAGAN
Implementation Details
编码器 E \mathcal{E} E通过给定的地面真实目标帧 I 0 ∈ R H × W × 3 I_{0}\in\mathbb{R}^{H\times W\times 3} I0∈RH×W×3作为输入,产生潜在编码 z 0 = E ( I 0 ) z_{0}= \mathcal{E}(I_{0}) z0=E(I0),这里的 z 0 ∈ R H f × W f × 3 z_{0}\in \mathbb{R}^{\frac{H}{f}\times \frac{W}{f}\times 3} z0∈RfH×fW×3, f f f是一个超参数,设置为 f = 32 f=32 f=32。
解码器
D
\mathcal{D}
D通过取
z
0
z_{0}
z0和由
E
\mathcal{E}
E之后的两个相邻帧
I
−
1
,
I
+
1
I_{−1}, I_{+1}
I−1,I+1中提取的特征金字塔
ϕ
−
1
,
ϕ
+
1
\phi_{-1}, \phi_{+1}
ϕ−1,ϕ+1来重构目标帧
I
^
0
\hat{I}_{0}
I^0。此外,利用运动提示提取器来捕获地面真实目标帧
I
0
I_{0}
I0与相邻帧
I
−
1
I_{−1}
I−1和
I
+
1
I_{+1}
I+1之间的帧间运动提示
m
−
1
→
0
m_{-1\to 0}
m−1→0和
m
0
→
+
1
m_{0\to +1}
m0→+1。然后,我们将
m
−
1
→
0
m_{-1\to 0}
m−1→0和
m
0
→
+
1
m_{0\to +1}
m0→+1作为通过运动感知扭曲(MA-WARP)模块在解码器
D
\mathcal{D}
D中进行上下文聚合的额外指导。具体来说,对于插值帧的特征
h
0
l
∈
R
U
×
V
×
C
h^{l}_{0}\in\mathbb{R}^{U\times V \times C}
h0l∈RU×V×C和运动提示
m
−
1
→
0
,
m
0
→
+
1
∈
R
H
×
W
×
(
2
×
B
)
m_{-1\to 0},m_{0\to +1}\in \mathbb{R}^{H\times W\times(2\times B)}
m−1→0,m0→+1∈RH×W×(2×B),第
l
l
l层首先重塑运动提示到
U
×
V
U\times V
U×V的分辨率,获得
m
−
1
→
0
l
,
m
0
→
+
1
l
∈
R
U
×
V
×
(
2
×
B
)
m^{l}_{-1\to 0},m^{l}_{0\to +1}\in \mathbb{R}^{U\times V\times(2\times B)}
m−1→0l,m0→+1l∈RU×V×(2×B)。然后对每个运动提示,通过可学习的神经网络生成2通道偏移图分别为
Ω
−
1
→
0
l
\Omega^{l}_{-1\to 0}
Ω−1→0l和
Ω
0
→
+
1
l
\Omega^{l}_{0\to +1}
Ω0→+1l,它反映了相邻帧到目标插值帧的像素级特征相关性:
Ω
−
1
→
0
l
=
f
Ω
(
h
0
l
,
m
−
1
→
0
l
,
ϕ
−
1
l
)
Ω
+
1
→
0
l
=
f
Ω
(
h
0
l
,
m
0
→
+
1
l
,
ϕ
+
1
l
)
\Omega^{l}_{-1\to 0}=f_{\Omega}(h^{l}_{0}, m^{l}_{-1\to 0},\phi^{l}_{-1})\\ \Omega^{l}_{+1\to 0}=f_{\Omega}(h^{l}_{0}, m^{l}_{0\to +1},\phi^{l}_{+1})
Ω−1→0l=fΩ(h0l,m−1→0l,ϕ−1l)Ω+1→0l=fΩ(h0l,m0→+1l,ϕ+1l)
然后,引入了扭曲函数
f
w
a
r
p
(
.
)
f_{warp}(.)
fwarp(.),作为一种聚合机制:
h
0
←
−
1
l
=
f
w
a
r
p
(
Ω
0
←
−
1
l
,
ϕ
−
1
l
)
h
0
←
+
1
l
=
f
w
a
r
p
(
Ω
0
←
+
1
l
,
ϕ
+
1
l
)
h^{l}_{0 \gets -1}=f_{warp}(\Omega^{l}_{0\gets-1}, \phi^{l}_{-1})\\ h^{l}_{0 \gets +1}=f_{warp}(\Omega^{l}_{0\gets+1}, \phi^{l}_{+1})
h0←−1l=fwarp(Ω0←−1l,ϕ−1l)h0←+1l=fwarp(Ω0←+1l,ϕ+1l)
MA-WARP还生成一个门控图
g
∈
[
0
,
1
]
U
×
V
×
1
g\in[0,1]^{U\times V\times 1}
g∈[0,1]U×V×1来解释遮挡,以及一个残差图
δ
∈
R
U
×
V
×
C
\delta\in\mathbb{R}^{U\times V\times C}
δ∈RU×V×C,以进一步提高性能:
h
~
0
l
=
g
⋅
h
0
←
−
1
l
+
(
1
−
g
)
⋅
h
0
←
+
1
l
+
δ
,
g
=
f
g
(
h
0
←
−
1
l
,
h
0
←
+
1
l
)
,
δ
=
f
δ
(
h
0
l
)
\tilde{h}^{l}_{0} = g\cdot h^{l}_{0\gets-1}+(1-g)\cdot h^{l}_{0\gets +1}+\delta,\\ g=f_{g}(h^{l}_{0\gets-1}, h^{l}_{0\gets+1}),\\ \delta=f_{\delta}(h^{l}_{0})
h~0l=g⋅h0←−1l+(1−g)⋅h0←+1l+δ,g=fg(h0←−1l,h0←+1l),δ=fδ(h0l)
这里的
f
g
(
.
)
f_{g}(.)
fg(.)和
f
δ
(
.
)
f_{\delta}(.)
fδ(.)是可学习的神经网络,
h
~
0
l
\tilde{h}^{l}_{0}
h~0l是MA-WARP第
l
l
l层解码器的输出。通过在解码器层中分层应用MA-WARP,VQ-MAGAN能够充分利用运动提示,准确地从相邻帧中聚合金字塔上下文。与VQ-FIGAN相比,我们的VQ-MAGAN能够合并目标插值帧与条件相邻帧之间的帧间运动。
Training VQ-MAGAN
VQMAGAN的训练,遵循VQGAN的原始训练设置,其中损失函数包括基于LPIPS的感知损失、基于补丁的对抗性损失和基于向量量化(VQ)层的潜在正则化项。特别地,我们使用地面真插值帧来提取给定条件相邻帧的运动提示。
由于在VQMAGAN训练过程中提供了地面真目标帧来提取运动提示,VQ-MAGAN的重建任务可能变得更加容易,可能会降低推理阶段的重建性能。为了解决这个问题,我们在训练阶段只利用概率为0.5的运动提示来协助VQ-MAGAN的重建过程。
4.3. De-noising with Conditional Motion Hints
Implementation Details
经过训练的VQMAGAN的编码器允许我们访问一个紧凑的潜在空间,其中我们通过根据预定义的噪声计划逐步加入目标帧
I
0
I_0
I0的潜在
z
0
z_0
z0来执行前向扩散,并学习反向(去噪)过程来执行条件生成。此外,与以往的方法相比,我们在去噪过程中还加入了动态帧间运动提示。为此,我们采用噪声预测参数化[23]扩散模型和训练去噪通过最小化重加权变分下界条件似然对数
log
p
θ
(
z
0
∣
z
−
1
,
z
+
1
,
m
−
1
→
0
,
m
0
→
+
1
)
\log p_{\theta}(z_{0}|z_{-1}, z_{+1}, m_{-1\to 0},m_{0\to +1})
logpθ(z0∣z−1,z+1,m−1→0,m0→+1),
z
−
1
,
z
+
1
z_{-1}, z_{+1}
z−1,z+1潜在的表示两个条件相邻帧,
m
i
→
j
m_{i\to j}
mi→j表示
i
i
i帧和
j
j
j帧间的运动提示。
具体来说,去噪U-Net
ϵ
θ
\epsilon_{\theta}
ϵθ作为输入噪声潜在表示
z
t
z_{t}
zt目标帧
I
0
I_{0}
I0(采样的
t
t
t步向前扩散过程长度
T
T
T),扩散步骤
t
t
t,以及条件潜在表示
z
−
1
z_{−1}
z−1,
z
+
1
z_{+1}
z+1相邻帧
I
−
1
I_{−1}
I−1,
I
+
1
I_{+1}
I+1。它被训练为通过最小化来预测在每个时间步长
t
t
t中添加到
z
0
z_{0}
z0中的噪声
L
=
E
[
∣
∣
ϵ
=
ϵ
θ
(
z
t
,
t
,
z
−
1
,
z
+
1
,
m
−
1
→
0
,
m
0
→
+
1
)
∣
∣
2
]
\mathcal{L}=\mathbb{E}[||\epsilon=\epsilon_{\theta}(z_{t},t,z_{-1},z_{+1},m_{-1\to0},m_{0\to +1})||^{2}]
L=E[∣∣ϵ=ϵθ(zt,t,z−1,z+1,m−1→0,m0→+1)∣∣2]
其中
t
∼
U
(
1
,
T
)
t\sim \mathcal{U}(1,T)
t∼U(1,T)。
ϵ
θ
\epsilon_{\theta}
ϵθ的推导和训练过程的全部细节提供在附录A。训练是通过预先定义的噪声计划在
z
0
z_{0}
z0中交替添加一个随机高斯噪声,并让网络
ϵ
θ
\epsilon_{\theta}
ϵθ预测在给定的步骤
t
t
t中添加的噪声,根据
z
−
1
z_{−1}
z−1,
z
+
1
z_{+1}
z+1和
m
i
→
j
m_{i\to j}
mi→j。
Training of De-noising U-net与VQ-MAGAN一致
4.4. MA-SAMPLING of MADIFF
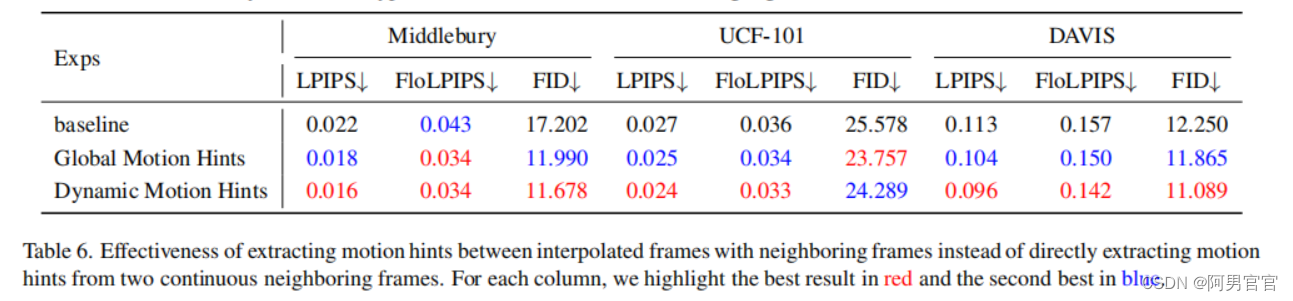
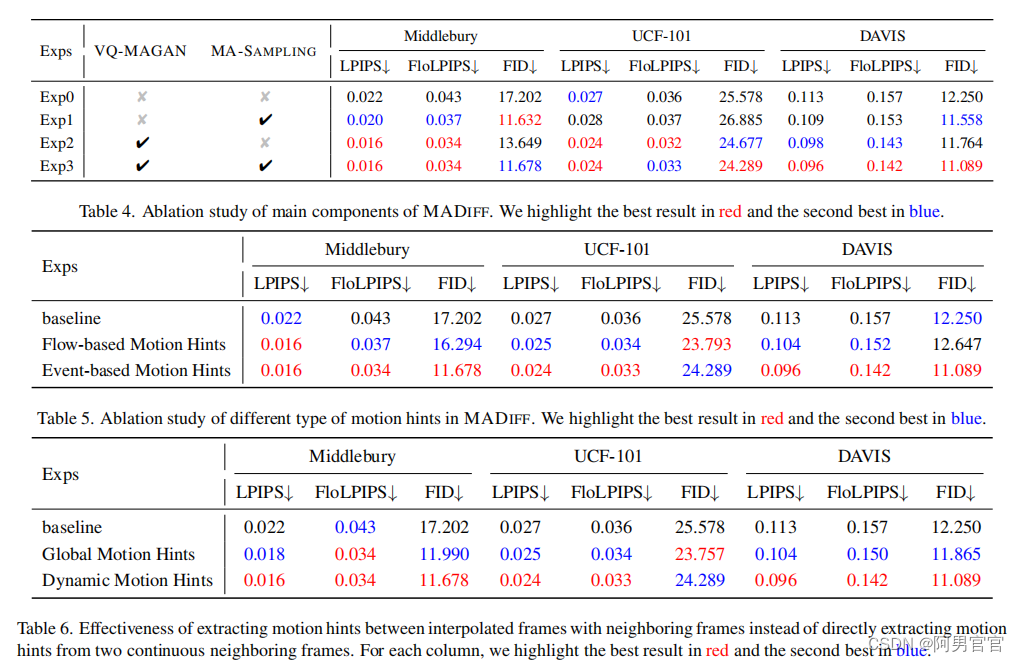
如上所述,VQ-MAGAN和去噪U-net都是基于从插值帧和条件相邻帧中提取的帧间运动提示。在VQ-MAGAN和去噪U-Net的训练阶段,直接使用地面真实插值帧以强制的方式提取运动提示。然而,插值帧在采样阶段是未知的,使得在插值帧和相邻帧之间的帧间运动提示的提取不可行。而直接从给定的相邻帧中提取的运动提示往往是不准确的,不能提供足够的指导,导致如Tab. 6所述的次优性能。为了消除训练阶段和采样阶段之间运动线索提取的差异,使采样过程中的运动线索可用,我们提出了一种新的MA-SAMPLING。
在引入MA-SAMPLING之前,我们提供了一个审查抽样过程在以往LDM VFI任务[16]:在每个时间步长内,首先去噪U-net
ϵ
θ
\epsilon_{\theta}
ϵθ预测基于邻近帧
I
−
1
I_{-1}
I−1,
I
+
1
I_{+1}
I+1的潜在表示
z
−
1
z_{−1}
z−1,
z
+
1
z_{+1}
z+1的噪声
ϵ
~
\tilde{\epsilon}
ϵ~。则得到的
z
^
0
∣
t
\hat{z}_{0|t}
z^0∣t如下:
ϵ
^
=
ϵ
θ
(
z
^
t
,
t
,
z
−
1
,
z
+
1
)
z
^
0
∣
t
=
z
^
t
−
ϵ
^
\hat{\epsilon}=\epsilon_{\theta}(\hat{z}_{t},t,z_{-1},z_{+1})\\ \hat{z}_{0|t}=\hat{z}_{t}-\hat{\epsilon}
ϵ^=ϵθ(z^t,t,z−1,z+1)z^0∣t=z^t−ϵ^
其中 ϵ θ ( . ) \epsilon_{\theta}(.) ϵθ(.)是去噪U-net, z ^ 0 ∣ t \hat{z}_{0|t} z^0∣t表示在时间 t t t步的预测 z 0 z_{0} z0(特别是我们将 z ^ 0 ∣ 1 \hat{z}_{0|1} z^0∣1表示为 z ^ 0 \hat{z}_{0} z^0), z ^ t \hat{z}_{t} z^t是采样过程中前一个时间步 t + 1 t + 1 t+1得到的预测 z ^ 0 ∣ t + 1 \hat{z}_{0|t+1} z^0∣t+1的噪声潜在表示。而 z ^ t \hat{z}_{t} z^t可以通过使用 ϵ ^ \hat{\epsilon} ϵ^和预定义的正向过程的相关参数作为eq (3)来计算。最后,VQ-GAN的解码器利用编码器 E \mathcal{E} E从 I − 1 I_{−1} I−1, I + 1 I_{+1} I+1中提取的特征金字塔 ϕ − 1 \phi_{-1} ϕ−1, ϕ + 1 \phi_{+1} ϕ+1,从 z ^ 0 ∣ 1 \hat{z}_{0|1} z^0∣1中生成图像 I ^ 0 \hat{I}_{0} I^0。
MA-SAMPLING具有在插值帧和相邻帧之间合并精确的运动提示的能力,从而逐步细化预测的目标帧。具体地说,在时间步长
t
t
t,首先去噪U-net
ϵ
θ
\epsilon_{\theta}
ϵθ预测噪声
ϵ
~
\tilde{\epsilon}
ϵ~的潜表示,
z
−
1
z_{−1}
z−1,
z
+
1
z_{+1}
z+1为条件相邻帧
I
−
1
I_{−1}
I−1,
I
+
1
I_{+1}
I+1,额外的运动提示
m
^
0
→
+
1
∣
t
+
1
\hat{m}_{0\to+1|t+1}
m^0→+1∣t+1,
m
^
−
1
→
0
∣
t
+
1
\hat{m}_{-1\to0|t+1}
m^−1→0∣t+1。
z
^
0
∣
t
\hat{z}_{0|t}
z^0∣t是
ϵ
^
=
ϵ
θ
(
z
^
t
,
t
,
z
−
1
,
z
+
1
,
m
^
−
1
→
0
∣
t
+
1
,
m
^
0
→
+
1
∣
t
+
1
)
z
^
0
∣
t
=
1
α
t
(
z
^
t
−
1
−
α
t
1
−
α
ˉ
t
ϵ
^
)
\hat{\epsilon}=\epsilon_{\theta}(\hat{z}_{t},t, z_{−1},z_{+1}, \hat{m}_{-1\to0|t+1}, \hat{m}_{0\to+1|t+1})\\ \hat{z}_{0|t}=\frac{1}{\sqrt{\alpha}_{t}}(\hat{z}_{t}-\frac{1-\alpha_{t}}{\sqrt{1-\bar{\alpha}_{t}}}\hat{\epsilon})
ϵ^=ϵθ(z^t,t,z−1,z+1,m^−1→0∣t+1,m^0→+1∣t+1)z^0∣t=αt1(z^t−1−αˉt1−αtϵ^)
其中,
m
^
−
1
→
0
∣
t
+
1
,
m
^
0
→
+
1
∣
t
+
1
\hat{m}_{-1\to0|t+1}, \hat{m}_{0\to+1|t+1}
m^−1→0∣t+1,m^0→+1∣t+1从预测的插值帧
I
^
0
∣
t
+
1
\hat{I}_{0|t+1}
I^0∣t+1和相邻帧
I
−
1
I_{-1}
I−1和
I
+
1
I_{+1}
I+1得到:
I
^
0
∣
t
+
1
=
D
(
z
^
0
∣
t
+
1
)
m
^
−
1
→
0
∣
t
+
1
=
f
I
2
E
(
I
−
1
,
I
^
0
∣
t
+
1
)
m
^
0
→
+
1
∣
t
+
1
=
f
I
2
E
(
I
^
0
∣
t
+
1
,
I
+
1
)
\hat{I}_{0|t+1}=\mathcal{D}(\hat{z}_{0|t+1})\\ \hat{m}_{-1\to0|t+1}=f_{I2E}(I_{-1},\hat{I}_{0|t+1})\\ \hat{m}_{0\to+1|t+1}=f_{I2E}(\hat{I}_{0|t+1},I_{+1})\\
I^0∣t+1=D(z^0∣t+1)m^−1→0∣t+1=fI2E(I−1,I^0∣t+1)m^0→+1∣t+1=fI2E(I^0∣t+1,I+1)
z
^
t
−
1
\hat{z}_{t-1}
z^t−1可以使用
ϵ
^
\hat{\epsilon}
ϵ^和预定义的正向过程的相关参数作为以往方法采样过程(3)来计算。特别是,在时间步长
T
T
T时,运动提示
m
^
−
1
→
0
∣
T
+
1
\hat{m}_{-1\to0|T+1}
m^−1→0∣T+1和
m
^
0
→
+
1
∣
T
+
1
\hat{m}_{0\to+1|T+1}
m^0→+1∣T+1都被空特征
O
∈
R
H
×
W
×
(
2
×
B
)
\mathbf{O}\in\mathbb{R}^{H\times W \times (2\times B)}
O∈RH×W×(2×B)所取代。
最后,解码器 D \mathcal{D} D产生插值帧 I ^ 0 ∣ 1 \hat{I}_{0|1} I^0∣1(简化表示 I ^ 0 \hat{I}_{0} I^0)从去噪潜在表示 z ^ 0 ∣ t + 1 \hat{z}_{0|t+1} z^0∣t+1即 z ^ 0 \hat{z}_{0} z^0,充分考虑功能金字塔 ϕ − 1 \phi_{-1} ϕ−1, ϕ + 1 \phi_{+1} ϕ+1提取编码器 E \mathcal{E} E从 I ^ − 1 \hat{I}_{-1} I^−1, I ^ + 1 \hat{I}_{+1} I^+1上下文的指导下运动提示 m ^ − 1 → 0 ∣ 1 \hat{m}_{-1\to0|1} m^−1→0∣1, m ^ 0 → + 1 ∣ 1 \hat{m}_{0\to+1|1} m^0→+1∣1。在附录A中提供了完整的细节和伪代码。
5. Experiment
5.1. Detail & Setup as LDMVFI
5.3. Quantitative Comparison

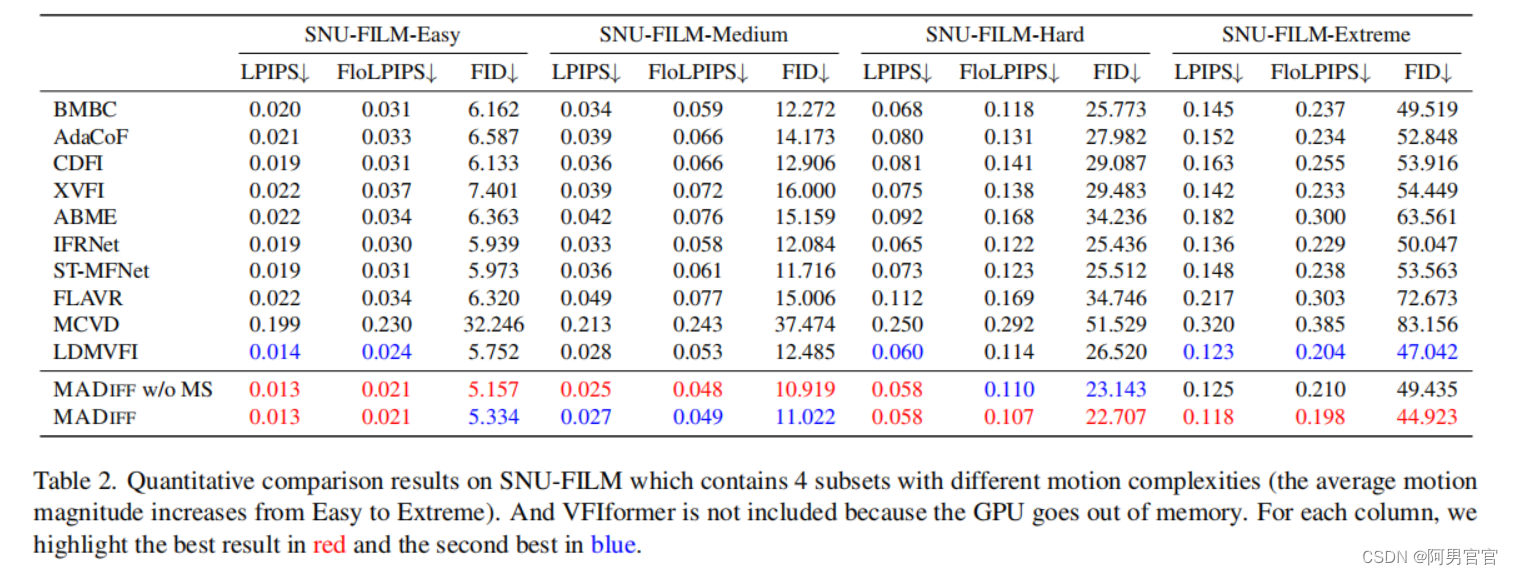
5.4. Qualitative Comparison

5.5. Ablation Study















 781
781











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









