







视频帧插值的统一金字塔循环网络
Xin Jin1 Longhai Wu1 Jie Chen1 Youxin Chen1 Jayoon Koo2 Cheul-hee Hahm2
1Samsung Electronics (China) R&D Center 2Samsung Electronics, South Korea
paper, code, CVPR2023
文章目录
Abstract
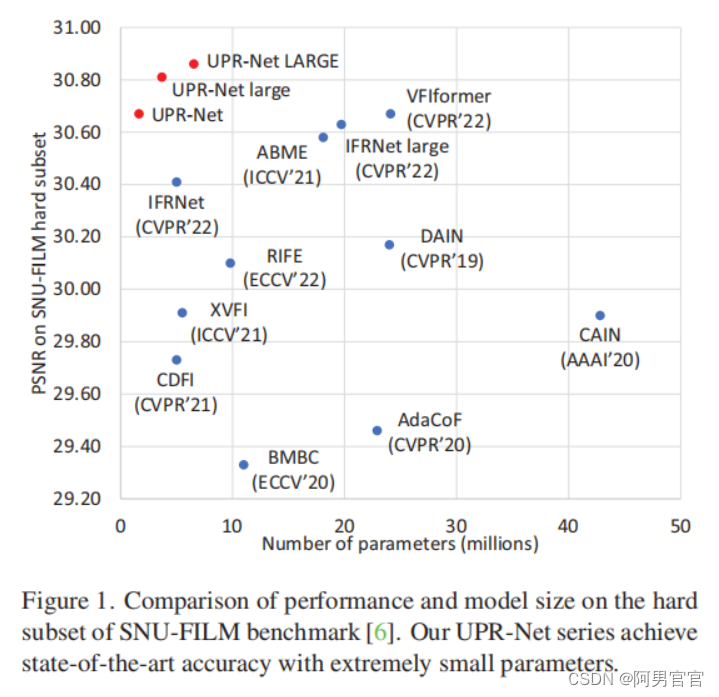
本文提出了一种新的用于帧插值的统一金字塔循环网络。在一个灵活的金字塔框架中,UPR-Net利用轻量级递归模块进行双向流估计和中间帧合成。在每个金字塔级别,它利用估计的双向流来生成帧合成的前扭曲表示;在金字塔层上,它支持光流和中间帧的迭代细化。
1. Introduction
Motivation
- 在普通的flow引导合成pipeline中,光流通常由金字塔网络从粗到细估计,而中间帧仅由合成网络合成一次。尽管在低分辨率视频上有很好的性能,但这种做法错过了迭代细化高分辨率输入插值的机会。
- 其次,对于大范围运动案例,一个重要的问题被以前的作品忽略了,尽管当估计的运动在视觉上是可信的时,在许多情况下,翘曲帧中明显的伪影(例如,前翘曲帧中的大孔)也会降低插值性能。
- 最后,现有的方法通常依赖于较大的模型架构来实现良好的性能,不利于部署在资源有限的平台上,例如移动设备。
Contribution
- UPR-Net允许在测试中定制金字塔级别的数量来估计非常大的运动。但是,它利用金字塔递归网络进行粗到细的帧合成,并在一个金字塔递归网络中统一运动估计和帧合成。
- 证实了从粗到细的迭代合成可以显著提高帧插值在大运动情况下的鲁棒性。在高分辨率金字塔水平,前翘帧可能由于大的运动插值结果差。通过向帧合成模块提供从以前的低分辨率金字塔水平上采样的中间帧估计,这个问题可以被解决。
- 光流和帧合成模块都是非常轻量级的。在每个金字塔层上,UPR-Net首先提取CNN特征,然后构造一个volume,同时进行双向流估计。它从正向扭曲的输入帧及其CNN特征中预测改进的中间帧,以及上采样的中间帧估计。
2. Related Work
Pyramid recurrent optical flow estimator
Coarse-to-fine image synthesis
Artifacts in warped frames
3. Our Approach
3.1. Unified Pyramid Recurrent Network
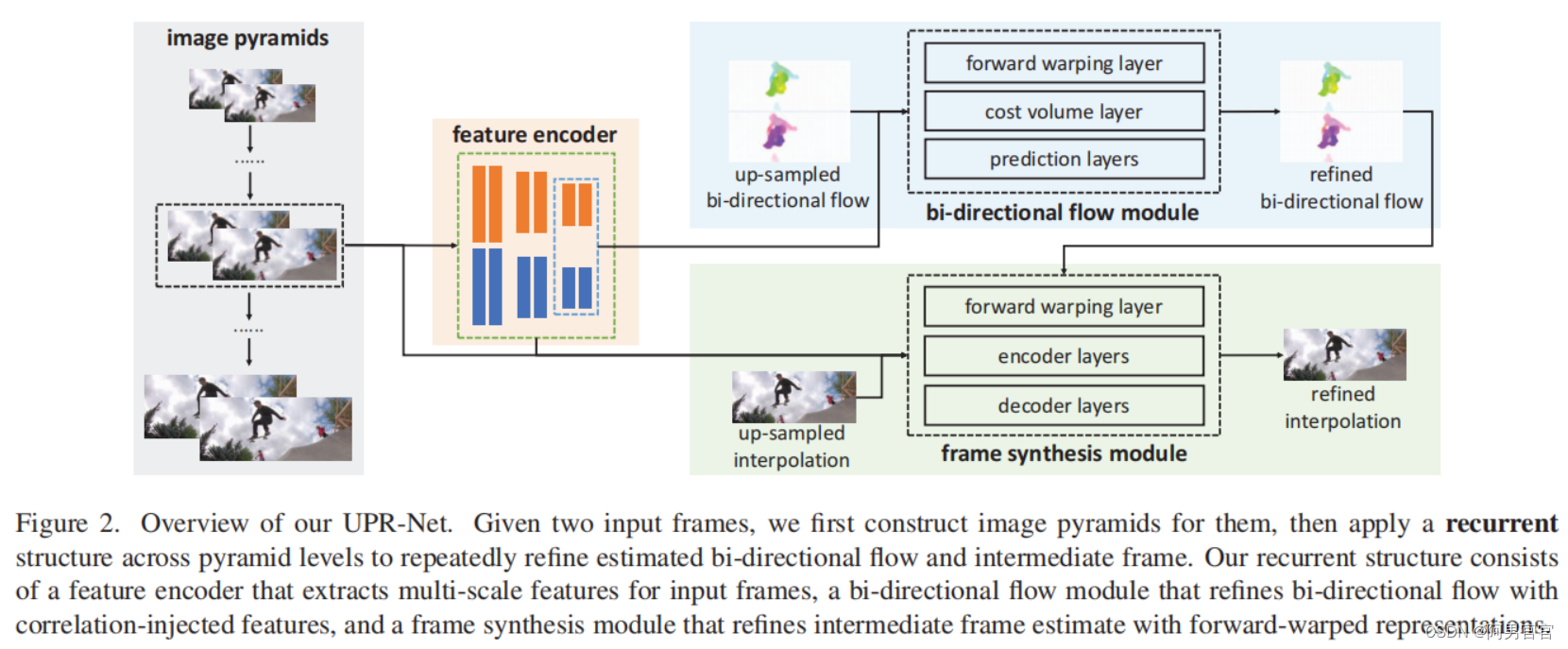
Fig. 2所示整体的UPR-Net。给定一对连续的帧 I 0 , I 1 I_{0}, I_{1} I0,I1和期望的时间步长 t t t(0≤t≤1),目标是合成不存在的中间帧 I t I_{t} It。UPR-Net通过跨 L L L图像金字塔层的迭代细化过程完成任务,从顶层的下采样帧 I 0 L − 1 I_{0}^{L−1} I0L−1和 I 1 L − 1 I_{1}^{L−1} I1L−1,到原始输入帧 I 0 0 I^{0}_{0} I00和 I 1 0 I^{0}_{1} I10的底部(零)金字塔层。
在每个金字塔级别,UPR-Net使用一个特征编码器来提取两个输入帧的多尺度CNN特征。然后,利用双向flow模块对特征编码器最后一层的特征和上采样的光流进行处理,得到精细化的双向流。改进的光流用于前扭曲输入帧和多尺度CNN特征。将扭曲表示与上采样相结合,采用帧合成模块生成精细的中间帧。重复这个估计过程,直到在底部金字塔水平产生最终的插值。
3.2. Recurrent Frame Interpolation Modules
循环结构由三个轻量级模块组成: feature encoder, bi-directional flow module, 和frame synthesis module。
Feature encoder.
在每个金字塔层次上,首先使用一个特征编码器来提取输入帧的多尺度特征。特性编码器有三个卷积阶段:阶段0、阶段1和阶段2。每个阶段由四个卷积层组成,第1阶段和第2阶段的第一层进行降采样。使用来自每个阶段的最后一个卷积层的特性。
Bi-directional flow module.
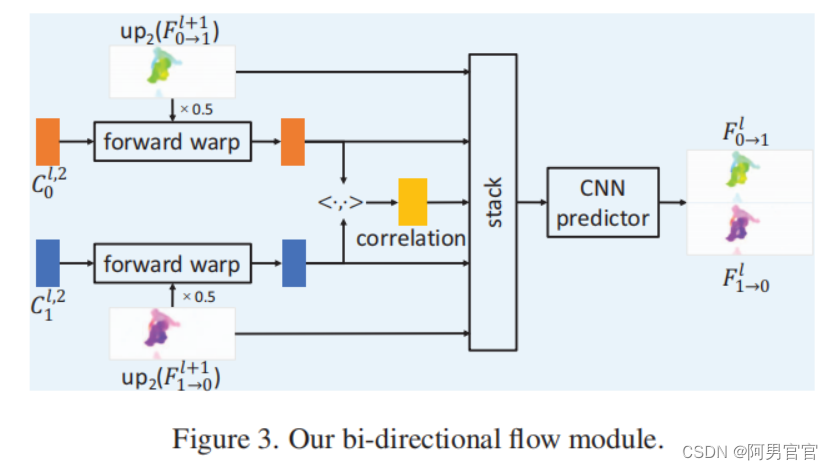
设 F 0 → 1 l + 1 F^{l+1}_{0\to1} F0→1l+1和 F 1 → 0 l + 1 F^{l+1}_{1\to0} F1→0l+1表示 l + 1 l+1 l+1级的细化双向光流。在第1个图像金字塔层,首先通过×2上采样 F 0 → 1 l + 1 F^{l+1}_{0\to1} F0→1l+1和 F 1 → 0 l + 1 F^{l+1}_{1\to0} F1→0l+1: F ^ 0 → 1 l = u p 2 ( F 0 → 1 l + 1 ) \hat{F}^{l}_{0\to1}=up_{2}(F^{l+1}_{0\to1}) F^0→1l=up2(F0→1l+1), F ^ 1 → 0 l = u p 2 ( F 1 → 0 l + 1 ) \hat{F}^{l}_{1\to0}=up_{2}(F^{l+1}_{1\to0}) F^1→0l=up2(F1→0l+1)来初始化双向流。特别是,在顶层的初始流量被设置为零。基于初始流,通过线性缩放获得从输入帧 I 0 l I^{l}_{0} I0l和 I 1 l I^{l}_{1} I1l到隐藏的中间帧 I 0.5 l I^{l}_{0.5} I0.5l的光流: F 0 → 0.5 l = 0.5 ⋅ F ^ 0 → 1 l F^{l}_{0\to0.5}=0.5\cdot\hat{F}^{l}_{0\to1} F0→0.5l=0.5⋅F^0→1l, F 1 → 0.5 l = 0.5 ⋅ F ^ 1 → 0 l F^{l}_{1\to0.5}=0.5\cdot\hat{F}^{l}_{1\to0} F1→0.5l=0.5⋅F^1→0l。
使用 F ^ 0 → 0.5 l \hat{F}^{l}_{0\to0.5} F^0→0.5l和 F ^ 1 → 0.5 l \hat{F}^{l}_{1\to0.5} F^1→0.5l,将CNN的特征 C 0 l , 2 C^{l,2}_{0} C0l,2和 C 1 l , 2 C^{l,2}_{1} C1l,2向前扭曲到中间帧,以对齐它们的像素。然后,利用翘曲特征构造了一个偏相关体积,并使用一个6层CNN来预测重新定义的双向流 F 0 → 1 l F^{l}_{0\to1} F0→1l和 F 1 → 0 l F^{l}_{1\to0} F1→0l。特别是,CNN预测器的输入是相关体积、扭曲特征、初始流 F ^ 0 → 1 l \hat{F}^{l}_{0\to1} F^0→1l和 F ^ 1 → 0 l \hat{F}^{l}_{1\to0} F^1→0l的连接,以及来自之前金字塔级CNN预测器第5层的上采样特征。由于扭曲特征的输入帧分辨率为1/4,因此预测的光流分辨率也为1/4。使用双线性插值法将光流上采样到原始尺度。
Frame synthesis module.
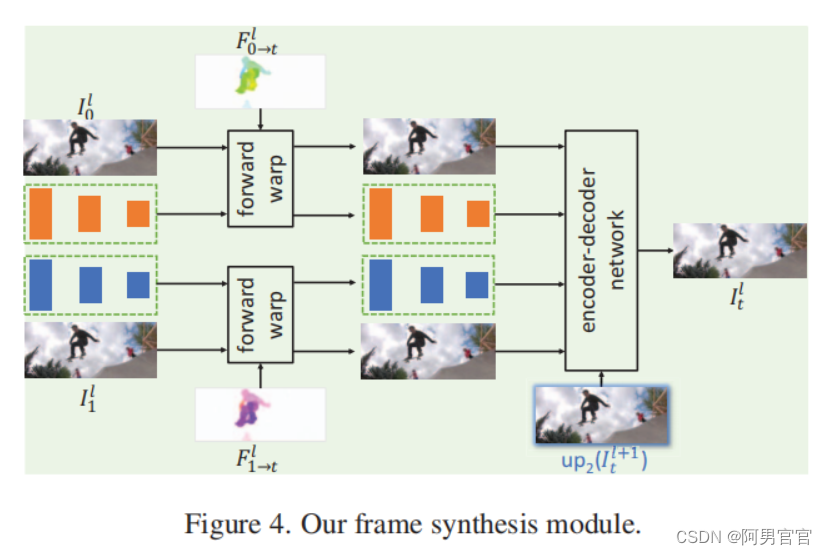
视频帧合成模块是基于一个U-Net结构的。编码器部分有三个卷积阶段,每个阶段由三个卷积层组成,第二阶段和第三阶段的第一层进行降采样。解码器部分也有三个卷积阶段,其中有两个转置卷积层用于上采样。
在金字塔 l l l级,给定细化的双向流 F 0 → 1 l F^{l}_{0\to1} F0→1l和 F 1 → 0 l F^{l}_{1\to0} F1→0l,通过线性缩放获得从输入帧 I 0 l I^{l}_{0} I0l和 I 1 l I^{l}_{1} I1l到目标帧 I t l I^{l}_{t} Itl的光流: F 0 → t l = t ⋅ F 0 → 1 l , F 1 → t l = ( 1 − t ) ⋅ F 1 → 0 l F^{l}_{0\to t}=t\cdot F^{l}_{0\to1}, F^{l}_{1\to t}=(1-t)\cdot F^{l}_{1\to0} F0→tl=t⋅F0→1l,F1→tl=(1−t)⋅F1→0l。使用 F 0 → t l F^{l}_{0\to t} F0→tl和 F 1 → t l F^{l}_{1\to t} F1→tl,向前扭曲输入帧 I 0 l I^{l}_{0} I0l、 I 1 l I^{l}_{1} I1l,以及它们的多尺度上下文特性 { C 0 l , 0 , C 1 l , 0 } \{C^{l,0}_{0}, C^{l,0}_{1}\} {C0l,0,C1l,0}、 { C 0 l , 1 , C 1 l , 1 } \{C^{l,1}_{0}, C^{l,1}_{1}\} {C0l,1,C1l,1}、 { C 0 l , 2 , C 1 l , 2 } \{C^{l,2}_{0}, C^{l,2}_{1}\} {C0l,2,C1l,2}。此外,通过对之前的 l + 1 l+1 l+1水平的插值进行上采样,生成中间帧的初始估计 I ^ t l \hat{I}^{l}_{t} I^tl: I ^ t l = u p 2 ( I t l + 1 ) \hat{I}^{l}_{t}=up_{2}(I^{l+1}_{t}) I^tl=up2(Itl+1)。在顶层,初始估计被设置为两个扭曲帧的平均值。在此基础上,向合成模块的第一个编码器阶段提供了扭曲帧、中间帧 I ^ t l \hat{I}^{l}_{t} I^tl的初始估计、原始输入帧和缩放双向流 F 0 → t l F^{l}_{0\to t} F0→tl和 F 1 → t l F^{l}_{1\to t} F1→tl。将扭曲的上下文特征提供给第二个和第三个编码器阶段,以及第一个解码器阶段,以提供多尺度的上下文线索。
帧合成模块的输出包括两个映射
M
0
l
M^{l}_{0}
M0l和
M
1
l
M^{l}_{1}
M1l,用于融合两个正向弯曲的帧
I
0
→
t
l
I^{l}_{0\to t}
I0→tl和
I
1
→
t
l
I^{l}_{1\to t}
I1→tl,以及一个剩余图像
Δ
I
t
l
\Delta I^{l}_{t}
ΔItl,用于进一步细化。得到细化的中间帧
I
t
l
I^{l}_{t}
Itl通过:
I
t
l
=
(
1
−
t
)
⋅
M
0
l
⊙
I
0
→
t
l
+
t
⋅
M
1
l
⊙
I
1
→
t
l
(
1
−
t
)
⋅
M
0
l
+
t
⋅
M
1
l
+
Δ
I
t
I^{l}_{t}=\frac{(1-t)\cdot M^{l}_{0}\odot I^{l}_{0\to t}+t\cdot M^{l}_{1}\odot I^{l}_{1\to t}}{(1-t)\cdot M^{l}_{0}+t\cdot M^{l}_{1}}+\Delta I_{t}
Itl=(1−t)⋅M0l+t⋅M1l(1−t)⋅M0l⊙I0→tl+t⋅M1l⊙I1→tl+ΔIt
⊙
\odot
⊙表示元素级相乘。
大范围运动的迭代综合分析。

对于普通合成,实际的合成只在底层执行,因为在以前的水平上的插值没有路径来影响底层的框架合成。通过综合比较插值帧,在大运动情况下的一般综合和迭代综合,得出以下经验结论。
- 当使用平面合成进行插值时,由于前向翘曲帧中的大运动而产生的明显伪影可能会导致插值帧中明显的伪影。图5显示了一个典型的示例。
- 粗到精细的迭代合成支持稳健的插值,即使扭曲的帧也有明显的伪影(见图5)。假设在较低分辨率的金字塔水平上合成的上采样插值,由于较小的运动幅度,可能有较少或没有伪影。因此,它可以指导合成模块在更高分辨率水平上产生鲁棒插值。
- 假设得到了图6中所示的证据的支持,其中对降低的分辨率插值了相同的例子。我们发现,在1/8的分辨率下,普通合成也提供了良好的插值,因为运动幅度要小得多。迭代合成在所有尺度上都提供了良好的插值,因为它利用了来自低分辨率级别的插值。

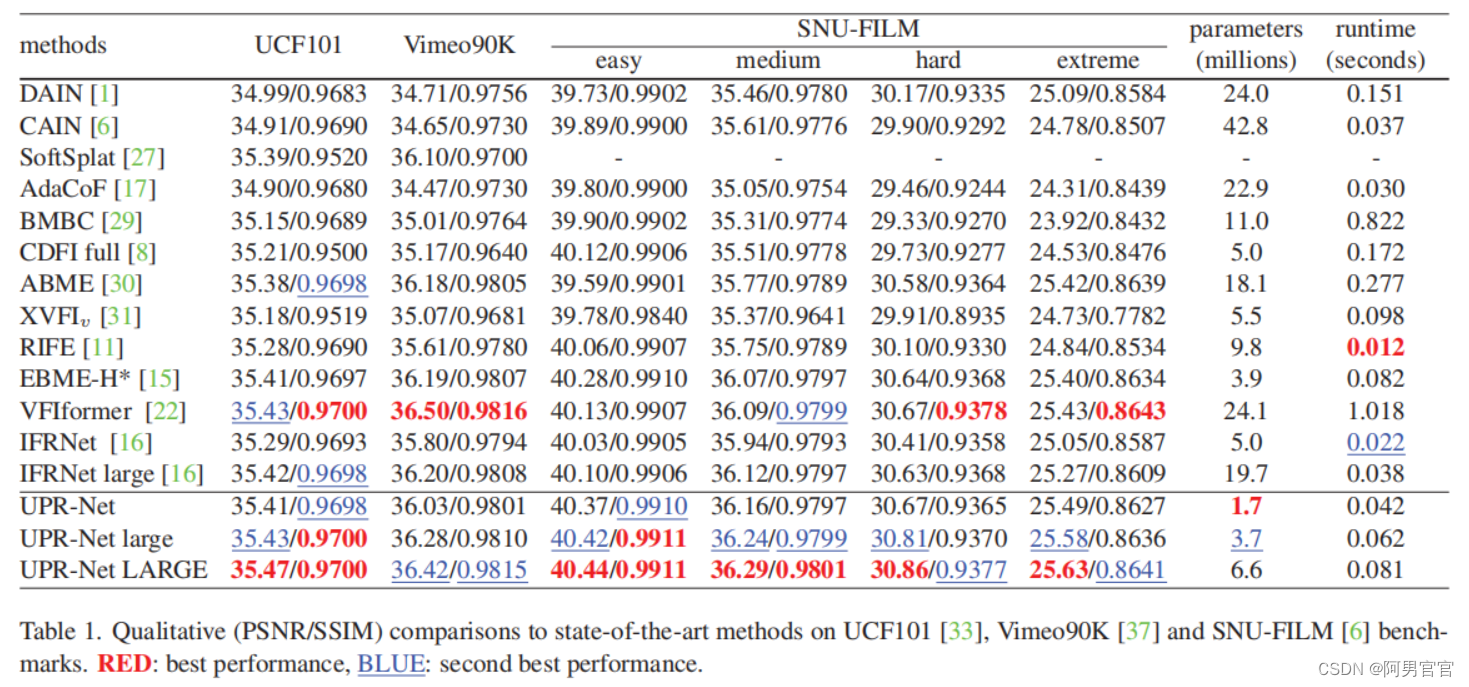
5. Experiment

















 4334
4334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









