







AT-EDM: Attention-Driven Training-Free Efficiency Enhancement of Diffusion Models
paper, project, CVPR2024
Hongjie Wang1*, Difan Liu2, Yan Kang2, Yijun Li2, Zhe Lin2, Niraj K. Jha1, Yuchen Liu2†
1Princeton University, 2Adobe Research
研究的过程和模型搭建过程可以参考
Motivation
DM的优越性是以大量的计算为前提,LDMs推理过程仍然缓慢。为了克服该问题,引入了许多针对高效DM的方法:高效采样策略和高效模型架构。高效的采样方法虽然可以减少去噪步骤的数量,但是不会减少每个步骤的内存占用和计算成本,限制了在计算资源不足设备上的使用。高效的模型架构降低了每个步骤的成本,与采样策略结合可以进一步提高效率。然而,高效的架构需要对DM主干进行再训练,这需要大量算力,并且不同平台对部署要求不同,骨干模型的压缩比不同,需要多次训练。
为什么高效的采样方法能够减少去噪步骤数量?
- 高效地探索高概率区域。采样集中在概率较高或者变化剧烈的区域,从而更快地捕捉模型中重要的特征和动态变化,在关键区域表现准确减少需要去噪的次数
- 降低估计方差。高效的采样方法降低方差估计,将主要的任务集中在有效利用已有的高质量样本上。
- 加速模型收敛。
技术路线
无训练的DM架构压缩是一个未知的领域,以往有ToMe在ViT上表现出良好的性能,但是在DMs上依然有改进空间。
| 问题 | 关键 | 方法 |
|---|---|---|
| 分析Stable Diffusion的FLOPs | Attention Blocks是主要的工作量 | 动态修剪冗余标记 |
| 识别冗余标记 | 设计基于图的快速算法 | 广义加权页面排名部署到DMs的attention map |
| 修剪后的token如何恢复 | 设计基于相似性的标记复制方法 | 再次使用提供的丰富信息 |
| 分析注意映射的方差 | 研究去噪过程中的跨步冗余性 | 设计新的剪枝方法DSAP |

Contributions:
- 提出的AT-EDM使用attention maps的丰富信息加速预训练的DM而不需要再训练。
- 设计了针对单一去噪步骤的标记剪枝算法。具体来说,快速的基于图的算法G-WPR识别冗余标记,基于相似度的复制方法回复缺失的标记。
- 受到不同去噪步骤中注意图的方差趋势的启发,开发了DSAP剪枝策略。
- 该方法的FID得分为28.0,FLOPs减少了40%,达到了SOTA的结果。

Method

Overview
Part 1 在单一去噪步骤中的token剪枝方法
- 从UNet的一个self-attention层中获得attention maps。备选self-attention和cross-attention。(消融)
- 设计评分模块G-WPR,根据attention maps为每个标记分配重要性分数。
- 根据重要性分数的分布生成剪枝mask。这里使用了top-k的方法确定保留的token。
- 使用生成的mask修剪token。备选FFN之前或之后修剪。(消融)
- 重复以上步骤,不对ResNet之前的最后一个attention层修剪。
- 在传给ResNet之前要填充修剪后的token。这里使用的是基于相似性将标记复制到相应的位置。


Part 2 DSAP schedule
Attention maps在去噪的前几步比后几步更混乱,包含信息更少,具体表现为attention maps的方差低,区别不重要符号的能力较弱。基于经验,设计了在早期去噪步骤中修剪较少token的DSAP策略。具体来说,在上采样和下采样选择一些attention block不修剪。
Experiment


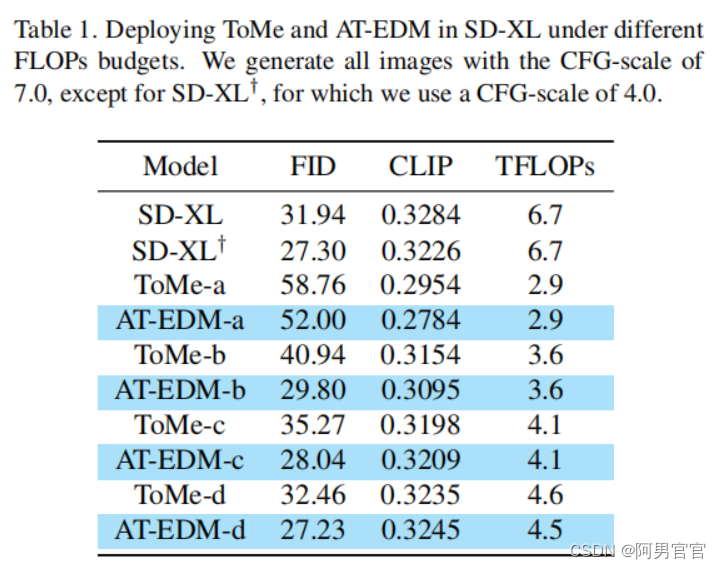
消融实验
Self-Attention (SA) vs. Cross-Attention (CA).

Similarity-based Copy.

Denoising-Steps-Aware Pruning
















 2944
2944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









