







 本文探讨了在SeleniumUI自动化中遇到的元素失效问题,分析了原因并提出使用XPath作为不受元素属性、层级和网页结构影响的稳定定位方式。XPath通过路径表达式选取XML文档中的节点,介绍了基本类型、节点关系、XPath语法、谓语和通配符的使用,以及XPath在实际项目中的应用和IFrame处理方法。
本文探讨了在SeleniumUI自动化中遇到的元素失效问题,分析了原因并提出使用XPath作为不受元素属性、层级和网页结构影响的稳定定位方式。XPath通过路径表达式选取XML文档中的节点,介绍了基本类型、节点关系、XPath语法、谓语和通配符的使用,以及XPath在实际项目中的应用和IFrame处理方法。
为什么使用xpath
元素失效的场景
做过selenium UI自动化的同学会经常遇到元素失效的问题,主要集中以下三种情况
-
在A机器上可以,在B机器上不行
-
刚刚还能校验成功,网页刷新后就不行了
-
昨天还可以校验成功,今天就不行了
元素为什么会失效
-
元素没有id和class属性,需要依赖其他属性(其他属性稳定性比较差)
-
虽然有id和class属性,但是这些属性值可能改变
-
元素本身属性没有变化,但是网页的机构发生了变化,会导致元素的层级发生变化
-
元素特殊原因无法直接捕获
总的来说,定位条件产生变化和网页结构不稳定是元素失效的主要原因,那么我们是否能找到不受元素属性、层级、和网页结构影响又灵活稳定的定位方式呢,那就是xpath
同一个按钮的多种定位方式

XPath 介绍
XPath (XML Path Language) 是一门在 XML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历。
XPath定位在爬虫和UI自动化测试中都比较常用,通过使用路径表达式来选取 XML 文档中的节点或者节点集,熟练掌握XPath可以极大提高提取数据的效率。。
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<author>JK.Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>基本类型
1、节点
标题:`<h1>、<h2>、<h3>、<h4>、<h5>、<h6>、<title>`
段落:<p>
链接:<a>
图像:<img>
样式:<style>
列表:无序列表<ul>、有序列表<ol>、列表项<li>
块:<div>、<span>
脚本:<script>
注释:<!--注释-->
2、文本数据
处于两个尖括号中的数据,即:>文本数据<
3、属性数据
由一个属借键和属性值组成更多HTML学习可以参考W3School文档:https://www.w3school.com.cn/html/in
节点关系
父(Parent)
每个元素以及属性都有一个父。
在下面的例子中,book 元素是 title、author、year 以及 price 元素的父:
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>子(Children)
元素节点可有零个、一个或多个子。
在下面的例子中,title、author、year 以及 price 元素都是 book 元素的子:
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>同胞(Sibling)
拥有相同的父的节点
在下面的例子中,title、author、year 以及 price 元素都是同胞:
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>先辈(Ancestor)
某节点的父、父的父,等等。
title 元素的先辈是 book 元素和 bookstore 元素:
后代(Descendant)
某个节点的子,子的子,等等。
bookstore 的后代是 book、title、author、year 以及 price 元素:
XPath 语法
XPath 使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
实例
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="eng"Harry Potter</title
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。 下面列出了最有用的路径表达式:
| 表达式 | 描述 |
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取(取子节点)。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置(取子孙节点)。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
| 路径表达式 | 结果 |
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore | 选取根元素 bookstore。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。谓语被嵌在方括号中。
| 路径表达式 | 结果 |
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang='eng'] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]//title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
xpath函数
text(匹配精准)
适用于其内的text在页面唯一的情况, 书写起来也最简单
//div[(text()='更新文案')]
Contains(模糊匹配)
适用于某个属性动态的值变化, 但是其值总是包含什么特定的字符串。
//*[contains(@id,'message')]
Start-With
可以理解为contains的延申, 选择某元素的值总是以XXX开头
//label[starts-with(@id,'message')]
Or和And关键字
用Or的话, 两个条件其中之一为真则为真, 用And的话, 两个条件均为真则真(个人用And多一点, 用来筛选元素)。
//input[@type='submit' and @name='btnLogin']
XPath 验证
1、控制台control + F 元素查找
右键复制元素xpath
优点操作简单,缺点不方便总览定位
2、控制台输入
$x('//*[@id="s-top-left"]/a')

优点返回结构清晰,但是每次都写表达式
3、插件
xpath-helper

Shift 鼠标悬停 方便快速显示定位元素
有浏览器工具复制,为什么手写xpath?
-
元素没有id,name,class等明显或者唯一属性
-
元素id是动态
-
元素定位工具抓取不到
-
复制xpath不稳定
复制1:/html/body/form/p[3]/button复制2:/html/body/form/p[4]/button -
元素本身没有变化,其它元素修改导致该元素定位失效
-
复制缺点:不支持文本,不支持批量 只能参考不能依赖
xpath实战
XPath 格式: //tagname[@attribute='value']
xpath的思想: 通过路径找节点 (元素属性、内容)
绝对路径:
绝对定位用一个杠“/”, 绝对路径一个层级变化所有空间都有变化
/html/body/div[2]/div[2]/div[3]/span
相对路径
相对定位是两个杠表示“//”,相对路径易维护

属性查找@
这里我们以百度为例,如果我们要定位到百度的id元素,那么可以使用 //标签名[@元素名称=‘元素值’]
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">
//input[@id='kw'] //input[@name='wd']

xpath逻辑表达式
一、and
//标签名[@元素名称='元素值' and @元素名称='元素值']
二、or
// 标签名[@元素名称='元素值' or @元素名称='元素值']
//a[@class="mnav c-font-normal c-color-t" or @class="user-menu-item"]
三、not
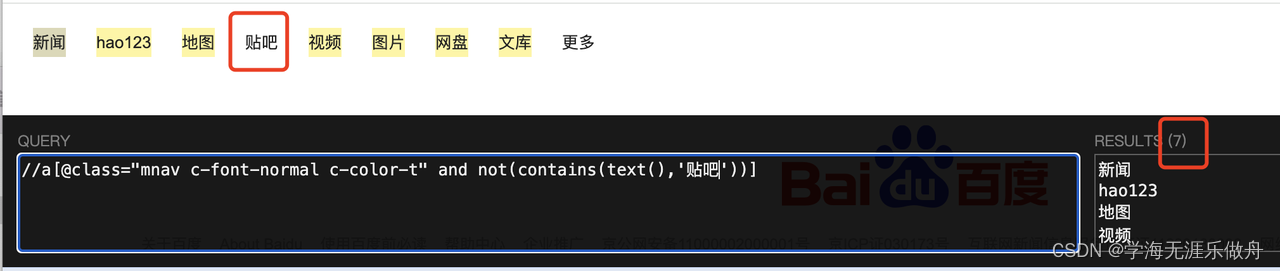
//a[@class="mnav c-font-normal c-color-t" and not(contains(text(),'贴吧'))]
四 !=
//a[@class="mnav c-font-normal c-color-t" and text()!='贴吧']and

not
使用运算符定位
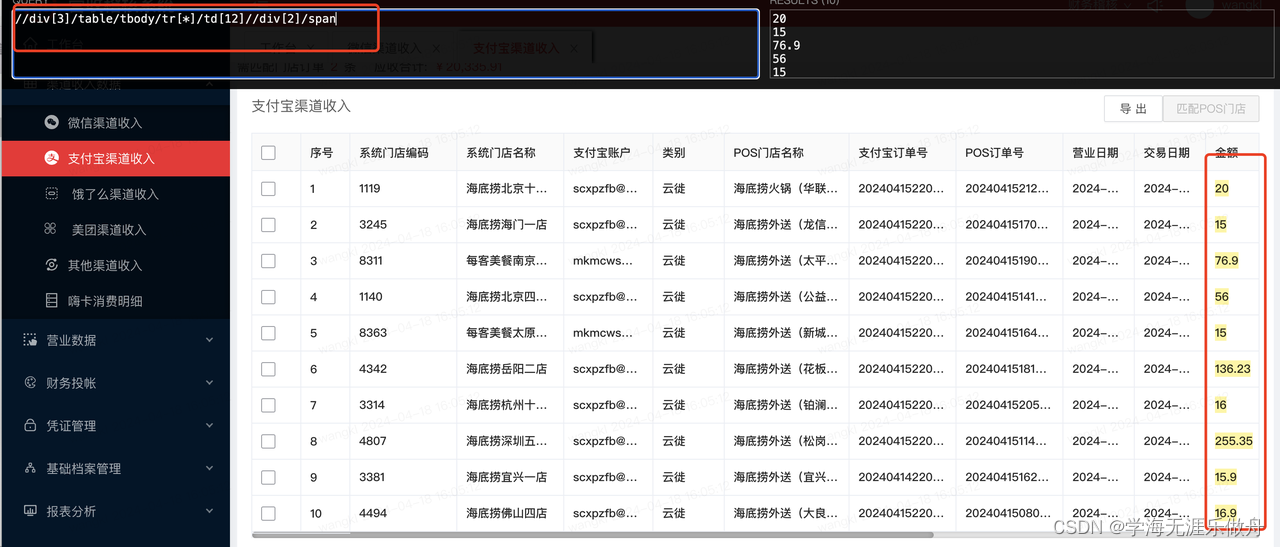
//div[3]/table/tbody/tr[*]/td[12]//div[2]/span
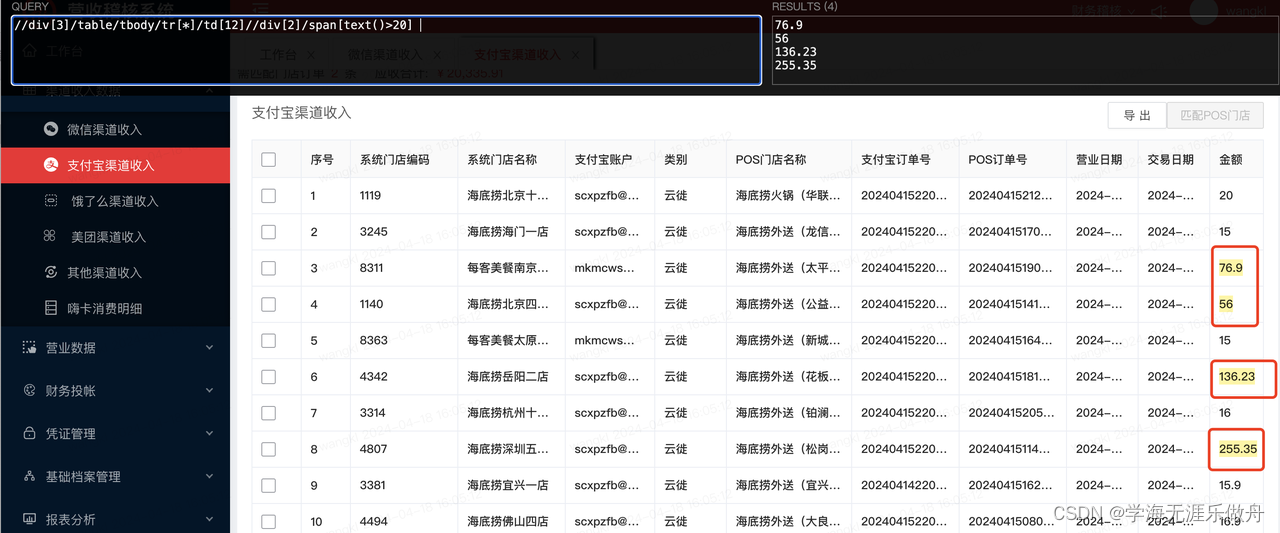
//div[3]/table/tbody/tr[*]/td[12]//div[2]/span[text()>20]
div 除法
//a[@id="title-content"][span div 2 =1]
mod 取余 mod计算除法的余数 5 mod 2 = 1
//a[@id="title-content"][span mod 3 =1]精准匹配
//标签名[(text()='内容')] //a[(text()='hao123')]
模糊匹配
//标签名[contains(text(), "内容"]
//a[contains(text(),"hao")]
starts-with
//标签名[starts-with(@id,'内容')]
//a[starts-with(text(),"hao")]
last()方法
当标签存在多个相同的时候,可以使用xpath中的last()方法,定位到最后一个 //标签名[last()]
//div[@id="s-top-left"]/a[last()]
//div[@id="s-top-left"]/a[last()-1]
//div[@id="s-top-left"]/a[2]last()示例

列表索引从1开始
position()
定位到的元素个数(顺序)
//div[@id="s-top-left"]/a[position()<4]
轴方式定位(了解)
轴表达式说明
parent::* :表示当前节点的父节点元素最多有一个(由子节点定位父节点)
ancestor::* :表示当前节点的祖先节点元素父元素 父的父元素等
child::* :表示当前节点的子元素 下层所有子节点(由父节点定位子节点)
descendant::* 该元素的后代,不包括该元素的同代;
self::* :表示当前节点的自身元素
ancestor-or-self::* :表示当前节点的及它的祖先节点元素
descendant-or-self::* :表示当前节点的及它们的后代元素
preceding 选取文档中当前节点的开始标签之前的所有节点
following 选取文档中当前节点的结束标签之后的所有节点
following-sibling::* :表示当前节点的后序所有兄弟节点元素
preceding-sibling::* :表示当前节点的前面所有兄弟节点元素(由弟弟节点定位哥哥节点)
parent::
当前节点的父节点元素
//*[@id="s-top-left"]/a[1]/parent::*

child::*
表示当前节点的子元素 下层所有子节点
//*[@id="s-top-left"]/child::*
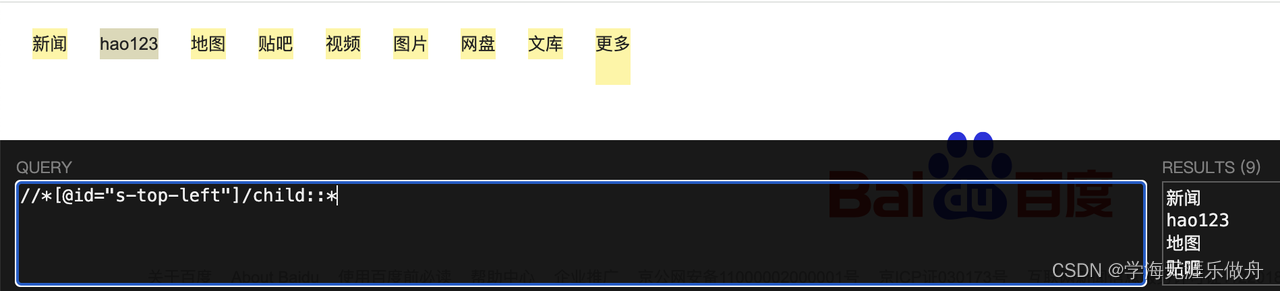
following-sibling::*
表示当前节点的后序所有兄弟节点元素
//*[@id="s-top-left"]/a[4]/following-sibling::*
preceding-sibling::*
表示当前节点的前面所有兄弟节点元素
//*[@id="s-top-left"]/a[4]/preceding-sibling::*

iframe
在主页面定位效果

切换ifram之后
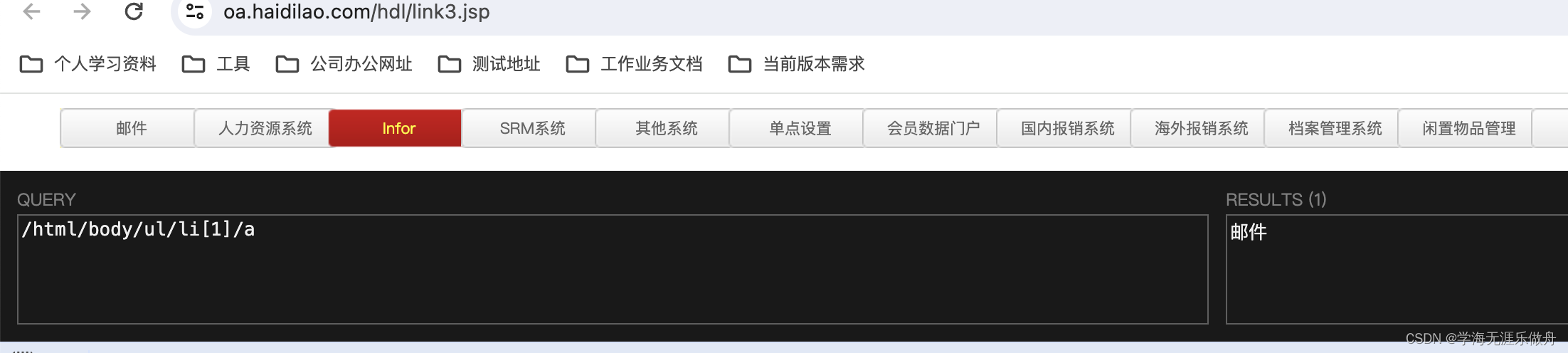
补充
1、八种元素定位的方式
# -*- coding: utf-8 -*-
# @Time : 2024/4/15 14:51
# @FileName: test.py
# @Software: PyCharm
import requests
from time import sleep
from selenium.webdriver.common.by import By
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
"""
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">
"""
# 1、标签定位
# driver.find_element(By.ID,"kw").send_keys("test") # ID定位
# driver.find_element(By.CLASS_NAME,"s_ipt").send_keys("test")# class
# driver.find_element(By.NAME,"wd").send_keys("test")# name
# driver.find_elements(By.TAG_NAME,'a')[9].click() # tag
# 2、文本定位
# driver.find_element(By.LINK_TEXT,'新闻').click() # 精准
# driver.find_element(By.PARTIAL_LINK_TEXT,'hao').click() # 模糊
# 3、表达式定位
# driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("test") #css定位
# driver.find_element(By.XPATH,"//*[@id='kw']").send_keys("test")
#特殊:
# svg:name属性 //[name()='svg]
sleep(3)2、iframe
#用id定位
driver.switch_to.frame("iframe")
#用name定位
driver.switch_to.frame("myiframe")
#用webElement对象定位
driver.switch_to.frame(driver.find_element_by_tag_name("iframe"))
切到frame中便不能继续操作主文档的元素,这时如果想操作主文档内容,则需切回主文档:
driver.switch_to.default_content()
#嵌套的iframe
driver.switch_to.frame("iframe1")
driver.switch_to.frame("iframe2")
#返回父iframe1,若当前就是iframe1,则返回父无效
driver.switch_to.patent_frame()
代码示例:
# -*- coding: utf-8 -*-
# @Time : 2024/4/19 10:55
# @FileName: iframe.py
# @Software: PyCharm
from selenium.webdriver.common.by import By
from logintest import Login
from time import sleep
class Iframe(Login):
def iframe(self):
self.login()
self.driver.implicitly_wait(10)
self.driver.switch_to.frame("ifrm_111")
self.driver.find_element(By.XPATH, '//html/body/ul/li[1]/a').click()
sleep(4)
if __name__ == '__main__':
Iframe().iframe()














 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









