







概述
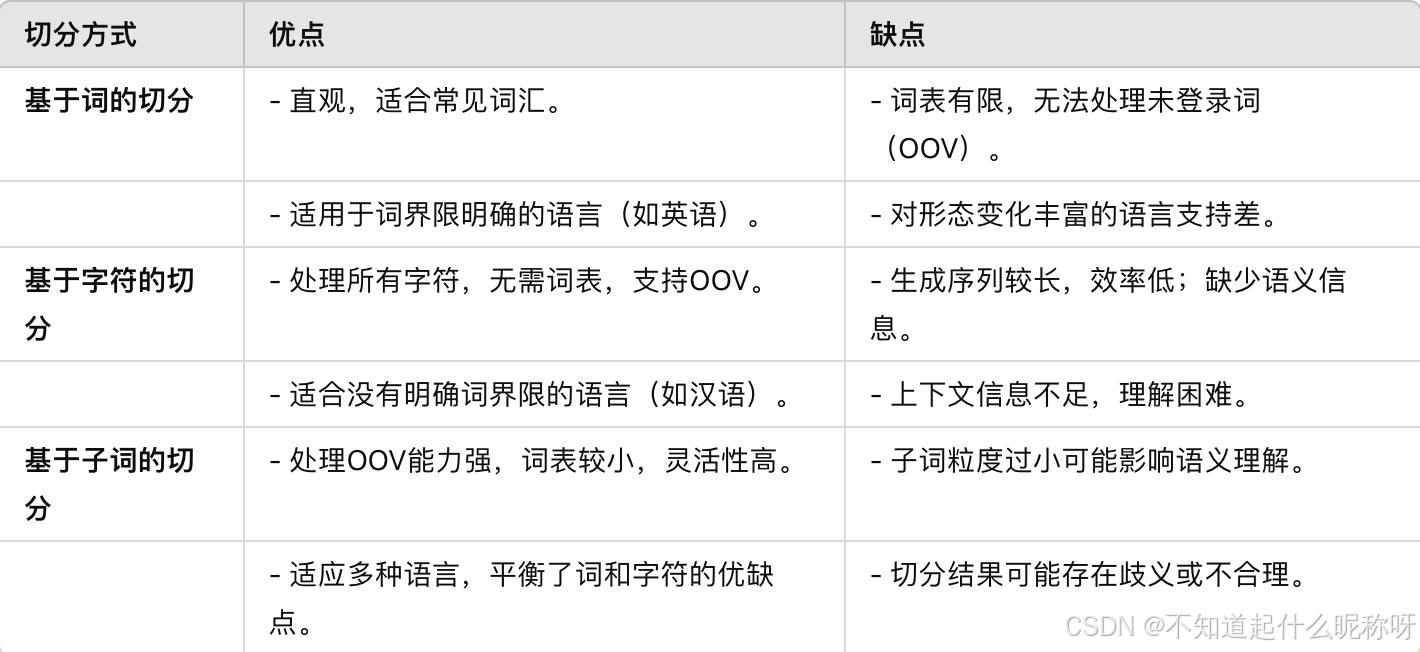
Tokenizer分词是大模型的基础组件,用于将文本转换成模型可以理解的形式。常见的分词方式包括基于词的切分(word-based)、基于字符的切分(character-based)、基于子词的切分(subword-based)。基于词的切分和基于字符的切分都比较简单容易理解,这里只介绍主流的分词方法subword-based。
subword-based方法的目的是通过一个有限的单词列表来解决所有单词的分词问题,同时将结果中token的数目降到最低。它的划分粒度介于词与字符之间,比如可以将”looking”划分为”look”和”ing”两个子词,而划分出来的”look”,”ing”又能够用来构造其它词,如”look”和”ed”子词可组成单词”looked”,因而subword-based方法能够大大降低词典的大小,同时对相近词能更好地处理。
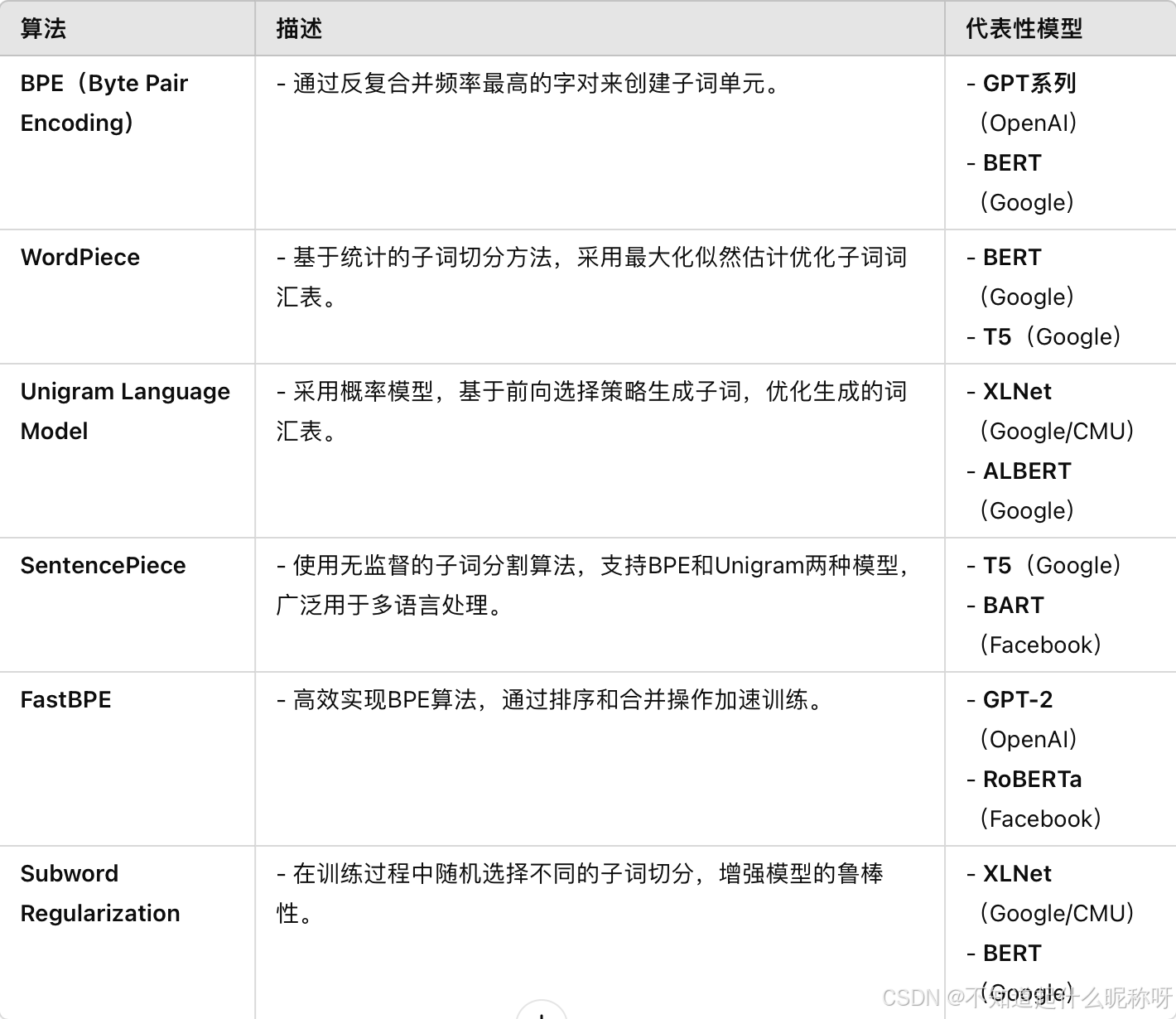
BPE算法
BPE的核心思想是不断合并出现频数最多的相邻子词对,来构建词表。
构建词表的过程
- 数据准备:准备足够大的训练语料,并确定期望的subword词表大小;
- 数据清洗:删除多余的空格和换行,以及一些有问题的单词;
- 预分词:将单词拆分为最小单元,比如英文中26个字母加上各种符号,这些作为初始词表;
- token合并:在语料上统计单词内相邻单元对的频数,选取频数最高的单元对合并成新的subword单元;
- 重复第4步直到达到第1步设定的subword词表大小或下一个最高频数为1;
下面是一个例子,来自飞桨

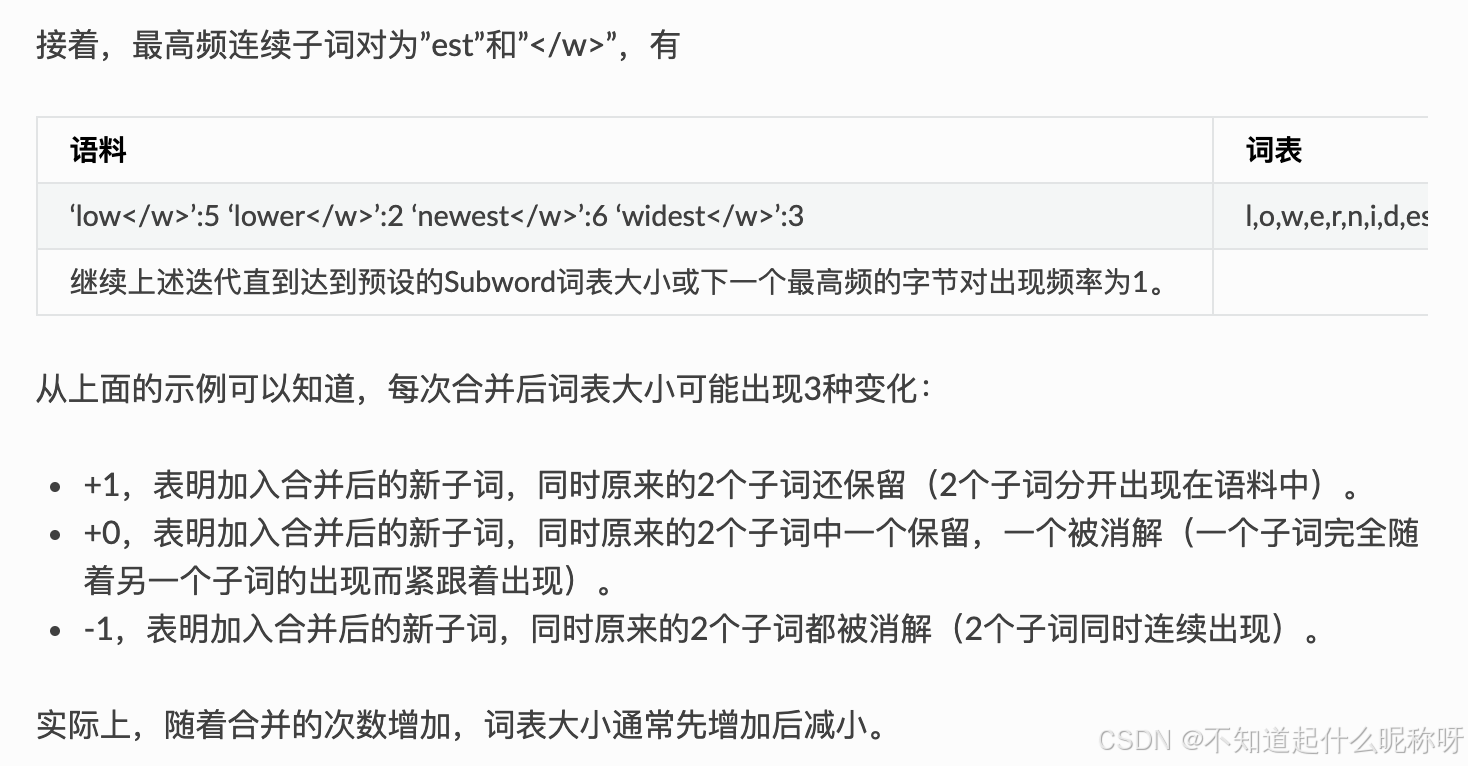
推理阶段
生成词表后,对句子进行编码生成token:
-
初始化分词,将句子切分成字符粒度;
-
从前到后遍历句子,看下词表中是否存在子词,选择频率最高(在生成词表过程中就已经计算好了)的进行合并,比如句子中包含自然语言,词表中包含自然语言、自然、语言,自然语言这个词会不会拆分成自然和语言取决于自然和自然语言在词表中出现的频率;
-
如果遍历完词表,仍然有子词没有匹配,则将子词替换为特殊符号,比如UNK;
调用预训练好的BPE算法
以下是使用transformers 库加载预训练模型并进行 BPE 分词的基本示例:
# -*- encoding:utf-8 -*-
from transformers import GPT2Tokenizer
# 加载预训练的 GPT-2 Tokenizer(GPT-2 默认使用 BPE)
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# 测试文本
text = "Hello, this is an example sentence. model from huggingface with gpt2"
# 使用 tokenizer 对文本进行编码(分词)
encoded = tokenizer.encode(text)
# 打印编码后的 ID 和对应的子词
print("Encoded IDs:", encoded)
print("Decoded Text:", tokenizer.decode(encoded))
# 使用 tokenizer 对文本进行拆分(获取子词)
tokens = tokenizer.tokenize(text)
print("Tokens:", tokens)输出结果:
Encoded IDs: [15496, 11, 428, 318, 281, 1672, 6827, 13, 2746, 422, 46292, 2550, 351, 308, 457, 17]
Decoded Text: Hello, this is an example sentence. model from huggingface with gpt2
Tokens: ['Hello', ',', 'Ġthis', 'Ġis', 'Ġan', 'Ġexample', 'Ġsentence', '.', 'Ġmodel', 'Ġfrom', 'Ġhugging', 'face', 'Ġwith', 'Ġg', 'pt', '2']其中Ġ表示空格或者分隔符。
WordPiece算法
构建词表的过程
流程基本和BPE算法类似,也是每次从词表中选出两个子词合并成新的子词。与BPE的最大区别是,如何选择两个子词进行合并:BPE选择频数最高的相邻子词进行合并,WordPiece选择能够提升语言模型概率最大(也可以说是互信息最大)的相邻子词加入词表。
语言模型的概率:
这里的是每个token的概率。
提升语言模型概率最大也就意味着合并之后的子词出现频率要大于合并之前token的概率的乘积。
即 P(pair出现的概率) > P(token1出现的概率) * P(token2出现的概率),也就是token1和token2的互信息更大,互信息越大说明两个token有更强的关联性或依赖性。
比如【我们】这个词,【我们】出现的概率肯定要比单独【我】和【们】出现的概率要小的多,【模型】这个词相对于【我们】就更容易合并到一起。
推理阶段
推理阶段和BPE算法一致,这里就不赘述了。
调用预训练好的WordPiece算法
# -*- encoding:utf-8 -*-
from transformers import BertTokenizer
# 加载一个预训练的 BERT 模型(比如中文模型)
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
# 输入文本
text = "你好,今天的天气真好!"
# 使用 tokenizer 对文本进行分词
tokens = tokenizer.tokenize(text)
# 打印分词结果
print("Tokens:", tokens)
# 使用 tokenizer 将分词后的 tokens 编码成 token ids
token_ids = tokenizer.encode(text, add_special_tokens=True) # 添加特殊符号 [CLS] 和 [SEP]
print("Token IDs:", token_ids)
# 使用 tokenizer 对 token ids 进行解码,还原成文本
decoded_text = tokenizer.decode(token_ids, skip_special_tokens=True) # 去除特殊符号
print("Decoded Text:", decoded_text)输出结果:
Tokens: ['你', '好', ',', '今', '天', '的', '天', '气', '真', '好', '!']
Token IDs: [101, 872, 1962, 8024, 791, 1921, 4638, 1921, 3698, 4696, 1962, 8013, 102]
Decoded Text: 你 好 , 今 天 的 天 气 真 好 !Unigram Language Model 算法
与WordPiece一样,Unigram Language Model(ULM)同样使用语言模型来挑选子词。不同之处在于,BPE和WordPiece算法的词表大小都是从小到大变化,属于增量法。而Unigram Language Model则是减量法,即先初始化一个大词表,根据评估准则不断丢弃词表,直到满足限定条件。ULM算法考虑了句子的不同分词可能,因而能够输出带概率的多个子词分段。
构建词表的过程
1、初始时,建立一个足够大的词表。一般,可用语料中所有字符加上常见的子字符串初始化词表,也可以通过BPE算法初始化;
2、针对当前词表,用EM算法求解每个子词在语料上的概率;
3、对于每个子词,计算当该子词被从词表中移除时,总的loss降低了多少,记为该子词的loss;
4、将子词按照loss大小进行排序,丢弃了一定比例loss最小的子词(比如20%),保留下来的子词生成新的词表。这里需要注意的是,单字符不能被丢弃,这是为了避免OOV的情况;
5、重复2-4步,直到词表大小减少到设定范围;
可以看出,ULM会保留那些以较高频率出现在很多句子的分词结果中的子词,如果这些子词被丢弃,损失会很大。
推理阶段
生成词表后,对句子进行编码生成token:
-
假设已经有一个包含所有子词(tokens)的词表,每个子词都有一个相应的 概率。通常,这个概率表示子词在语料库中出现的频率,或是根据统计语言模型训练的结果;
-
将输入的句子转换为字符序列;
-
使用滑动窗口从左到右扫描整个句子,在每个位置尝试找到词表中最匹配的子词(单元);
-
对每一个可能的切分位置,尝试所有子词组合,计算每个切分方案的 总概率。总概率是每个子词的概率的乘积。最终选择概率最大的子词划分,即总概率最高的分词方案;
-
通过计算并比较不同分词方案的总概率,选择总概率最高的切分方式作为最终的分词结果;
举例说明:
假如我们有以下词表:
这里单个字符的概率是在物料中出现的频率,子词的概率是互信息,BPE算法和WordPiece算法也有类似的概率,那里一般用的都是频率。
{
'我': 0.4,
'喜欢': 0.3,
'自然': 0.25,
'语言': 0.2,
'喜': 0.1,
'欢': 0.1,
'自然语言': 0.15,
'处理': 0.1
}
待分词句子是:我喜欢自然语言处理。
步骤一:拆分成字符序列
['我', '喜', '欢', '自', '然', '语', '言', '处', '理']步骤二:滑动窗口匹配,从左到右逐个尝试匹配词表中的子词,计算每一对字符的合并概率
比如我们得到了一种分词方式['我', '喜欢', '自然', '语言', '处理'],总概率是0.0006:
P('我') * P('喜欢') * P('自然') * P('语言') * P('处理') = 0.4 * 0.3 * 0.25 * 0.2 * 0.05 = 0.0006
另一个分词方式['我', '喜欢', '自然语言', '处理'],总概率是0.0009:
P('我') * P('喜欢') * P('自然语言') * P('处理') = 0.4 * 0.3 * 0.15 * 0.05 = 0.0009
所以会选择['我', '喜欢', '自然语言', '处理']这种分词方式。
调用预训练好的ULM算法
# -*- encoding:utf-8 -*-
from transformers import BertTokenizer
# 加载预训练的 BERT 分词器,这里使用的是 'bert-base-multilingual-cased' 模型
tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-cased')
# 输入文本
sentence = "Hello, how are you?"
# 使用 tokenizer 进行分词
encoded_input = tokenizer.encode(sentence, add_special_tokens=True)
# 获取分词后的结果
tokenized_input = tokenizer.tokenize(sentence)
# 打印分词后的 token 和对应的 token ids
print(f"原始句子: {sentence}")
print(f"分词后的 token: {tokenized_input}")
print(f"对应的 token ids: {encoded_input}")
# 解码成原始文本
decoded_output = tokenizer.decode(encoded_input)
print(f"解码后的句子: {decoded_output}")输出结果
原始句子: Hello, how are you?
分词后的 token: ['Hello', ',', 'how', 'are', 'you', '?']
对应的 token ids: [101, 31178, 117, 14796, 10301, 13028, 136, 102]
解码后的句子: [CLS] Hello, how are you? [SEP]SentencePiece算法
SentencePiece是谷歌推出的分词开源工具包,支持character-based和word-based,还支持BPE和ULM算法。更进一步,为了能够处理多语言问题,SentencePiece将句子视为Unicode编码序列,因为所有的语言都可以通过Unicode编码表示,所以这种分词方式不局限于语言的表示,更加通用。相比传统实现进行优化,分词速度速度更快,当前主流的大模型都是基于sentencepiece实现,例如ChatGLM的tokenizer。
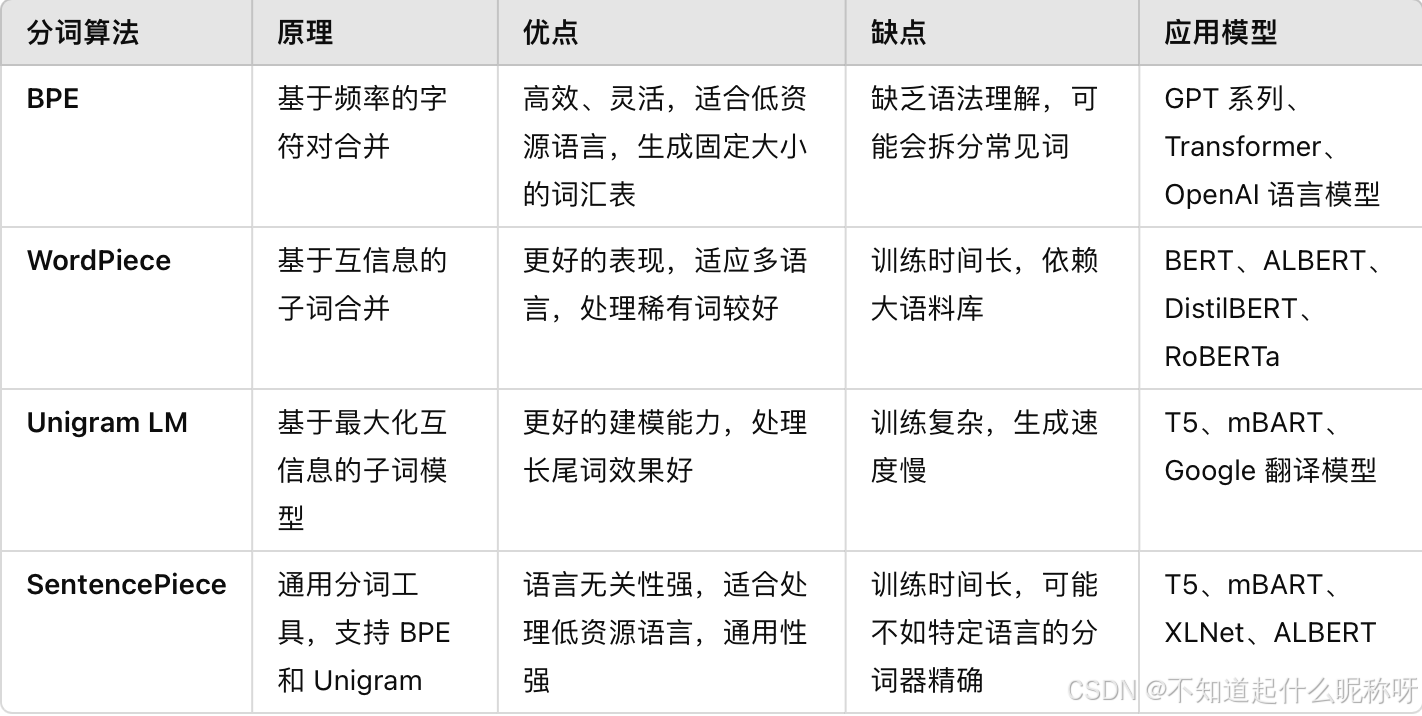
分词算法对比

















 55
55

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









