







文章目录
1. 前言
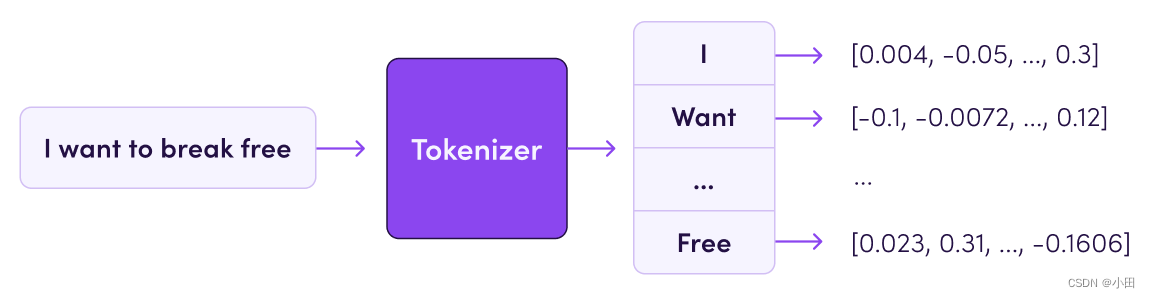
Tokenizer是一个用于向量化文本,将文本转换为序列的类。计算机在处理语言文字时,无法理解文字的含义,通常会把一个词转换为一个正整数,把一个文本转换为一个序列,然后再对序列进行向量化,向量化之后的数据送进模型进行处理。
Tokenizer 允许使用两种方法向量化一个文本语料库: 将每个文本转化为一个整数序列(每个整数都是词典中标记的索引); 或者将其转化为一个向量,其中每个标记的系数可以是二进制值、词频、TF-IDF权重等。
Tokenizer 分词算法是NLP大模型最基础的组建,基于Tokenizer可以将文本转换成独立的token列表,进而转换成输入的向量成为计算机可以理解的输入形式。本文会对分词器进行系统梳理,包括分词模型的演化路径,可用工具,并演算每个tokenizer的具体实现。
Transformer使用的三种主要的分词器:BPE、WordPiece 和 SentencePiece。在BertTokenizer分词器中可以看到使用的是WordPiece。
- 根据不同的切分粒度可以把tokenizer分为: 基于词的切分,基于字的切分和基于subword的切分。 基于subword的切分是目前的主流切分方式。
- subword的切分包括: BPE(/BBPE), WordPiece 和 Unigram三种分词模型。其中WordPiece可以认为是一种特殊的BPE。
- 完整的分词流程包括:文本归一化,预切分,基于分词模型的切分,后处理。
- SentencePiece是一个分词工具,内置BEP等多种分词方法,基于Unicode编码并且将空格视为特殊的token。这是当前大模型的主流分词方案。
| 分词方法 | 典型模型 |
|---|---|
| BPE | GPT, GPT-2, GPT-J, GPT-Neo, RoBERTa, BART, LLaMA, ChatGLM-6B, Baichuan |
| WordPiece | BERT, DistilBERT,MobileBERT |
| Unigram | AlBERT, T5, mBART, XLNet |
2. 示例
如何将下面一个英文句子进行分词:
Don’t you love 🤗 Transformers? We sure do.
按空格分:
[“Don’t”, “you”, “love”, “🤗”, “Transformers?”, “We”, “sure”, “do.”]
问题:Transformers? 与 do. 都含有标点符号。如果采用这种方式分词每一种标点符号与单词的组合模型都要学习到一种向量表示,这样就大大增加了模型训练的复杂度,因此需要进行优化,把标点符号 单独标识出来
[“Don”, “'”, “t”, “you”, “love”, “🤗”, “Transformers”, “?”, “We”, “sure”, “do”, “.”]
问题:Don`t 本来是 do not的缩写被拆分成Don 和t 不太合理。如果拆分成"Do", "nt"可能会更合理一些。所以到此可以看出来,不同的模型对于上述情况会采用不同的处理方式。对于一段文本,采用的切词规则不同,也可能得到不同的输出。因此,要想正确地使用一个预训练模型,首先要注意的就是,模型输入所用的切分规则必须与模型训练保持一致。一个预训练模型,对应一个与之匹配的tokenizer。
spaCy 和Moses 是两个比较流行的基于规则的tokenizer。上述句子会被切分成:
[“Do”, “n’t”, “you”, “love”, “🤗”, “Transformers”, “?”, “We”, “sure”, “do”, “.”]
该切分规则是将 句子基于空格、标点和缩写词规则进行了切分。优点: 分词方式直观且易于理解。缺点:海量文本语料场景,会出现一些问题。如 基于空格和标点切分会生成非常大的词表(对所有单词和标点去重后得到的集合)。例如 TransformXl使用这种切词规则,生成的词的规模为267735。
这种规模的词表,将使得模型维护一个庞大的词向量矩阵,加大了运算的时间复杂度和占用内存。实际上Transformer模型的词汇很少超过50000,尤其是在一中语言上进行预训练时。
既然这种符合直觉的简单分词方式并不令人满意,那为何不将句子直接拆分为字母(字符级)呢?
虽然将句子直接拆分为字母非常简单并且会大大减少内存占用和时间复杂度,但它使模型学习有意义的输入表示变得更加困难。例如,对于字母"t" ,学习它的上下文无关且有意义的向量表示比学习单词"today"的向量表示要难得多。这也就是说,直接字母表示通常会导致性能下降。
既然如此,为了两全其美,transformers 模型使用了词级切分和字符级切分的混合,称为子词(subword)切分。
3. 对比
基于subword的切分能很好平衡基于词切分和基于字切分的优缺点,也是目前主流最主流的切分方式。基于词和字的切分都会存在一定的问题,直接应用的效果比较差。
基于词的切分,缺点:
- 词表规模过大
- 一定会存在UNK,造成信息丢失
- 不能学习到词缀之间的关系,例如:dog与dogs,happy与unhappy
基于字的切分,缺点:
- 每个token的信息密度低
- 序列过长,解码效率很低
所以基于词和基于字的切分方式是两个极端,其优缺点也是互补的。而折中的subword就是一种相对平衡的方案。
subword的基本切分原则是:
- 高频词依旧切分成完整的整词
- 低频词被切分成有意义的子词,例如 dogs => [dog, ##s]
基于subword的切分可以实现:
- 词表规模适中,解码效率较高
- 不存在UNK,信息不丢失
- 能学习到词缀之间的关系
基于subword的切分包括:BPE,WordPiece 和 Unigram 三种分词模型。
4. 子词切分
子词切分原则:常用词不应该被切分;罕见词应该被切分为更有意义的子词。例如,单词"annoyingly"是一个罕见词,因此,可以被切分为"annoying"和"ly"——"annoying"和"ly"更加常见,且"annoyingly"的含义可以由"annoying"和"ly"组合生成。
子词切分允许模型保持一个规模相对合理的词汇量,同时能够学习有意义的上下文无关表示。此外,子词切分还可以使模型能够处理它以前从未见过的词,将它们分解为已知的子词。例如,使用BertTokenizer来切分句子"I have a new GPU!",其结果如下
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased") # 不区分大小写的模型
tokenizer.tokenize("I have a new GPU!")
["i", "have", "a", "new", "gp", "##u", "!"]
另外一个例子,我们使用XLNetTokenizer:
from transformers import XLNetTokenizer
tokenizer = XLNetTokenizer.from_pretrained("xlnet-base-cased")
tokenizer.tokenize("Don't you love 🤗 Transformers? We sure do.")
["▁Don", "'", "t", "▁you", "▁love", "▁", "🤗", "▁", "Transform", "ers", "?", "▁We", "▁sure", "▁do", "."]
有关其中的"_ “的含义,在下面讲SentencePiece时再进行说明。如你所见,不常见的单词"Transformers"已经被切分为两个更常见的子词"Transform"和"ers”。
4.1 字节对编码(Byte-Pair Encoding, BPE)
BPE首次在论文Neural Machine Translation of Rare Words with Subword Units(Sennrich et al., 2015)中被提出。BPE首先需要依赖一个可以预先将训练数据切分成单词的tokenizer,它们可以是一些简单的基于空格的tokenizer,如GPT-2,Roberta等;也可以是一些更加复杂的、增加了一些规则的tokenizer,如XLM、FlauBERT。
在使用了这些tokenizer后,我们可以得到一个在训练数据中出现过的单词的集合以及它们对应的频数。下一步,BPE使用这个集合中的所有符号(将单词拆分为字母)创建一个基本词表,然后学习合并规则以将基本词表的两个符号形成一个新符号,从而实现对基本词表的更新。它将持续这一操作,直到词表的大小达到了预置的规模。值得注意的是,这个预置的词表大小是一个超参数,需要提前指定。
举个例子,假设经过预先切分后,单词及对应的频数如下:
(“hug”, 10), (“pug”, 5), (“pun”, 12), (“bun”, 4), (“hugs”, 5)
因此,基本词表的内容为[“b”, “g”, “h”, “n”, “p”, “s”, “u”]。对应的,将所有的单词按照基本词表中的字母拆分,得到:
(“h” “u” “g”, 10), (“p” “u” “g”, 5), (“p” “u” “n”, 12), (“b” “u” “n”, 4), (“h” “u” “g” “s”, 5)
接下来,BPE计算任意两个字母(符号)拼接到一起时,出现在语料中的频数,然后选择频数最大的字母(符号)对。接上例,"hu"组合的频数为15("hug"出现了10次,“hugs"中出现了5次)。在上面的例子中,频数最高的符号对是"ug”,一共有20次。因此,tokenizer学习到的第一个合并规则就是将所有的"ug"合并到一起。于是,基本词表变为:
(“h” “ug”, 10), (“p” “ug”, 5), (“p” “u” “n”, 12), (“b” “u” “n”, 4), (“h” “ug” “s”, 5)
应用相同的算法,下一个频数最高的组合是"un",出现了16次,于是"un"被添加到词表中;接下来是"hug",即"h"与第一步得到的"ug"组合的频数最高,共有15次,于是"hug"被添加到了词表中。
此时,词表的内容为[“b”, “g”, “h”, “n”, “p”, “s”, “u”, “ug”, “un”, “hug”],原始的单词按照词表拆分后的内容如下:
(“hug”, 10), (“p” “ug”, 5), (“p” “un”, 12), (“b” “un”, 4), (“hug” “s”, 5)
假定BPE的训练到这一步就停止,接下来就是利用它学习到的这些规则来切分新的单词(只要新单词中没有超出基本词表之外的符号)。例如,单词"bug"将会被切分为[“b”, “ug”],但是单词"mug"将会被切分为[“”, “ug”]——这是因为"m"不在词表中。
正如之前提到的,词表的规模——也就是基本词表的大小加上合并后的单词的数量——是一个超参数。例如,对于GPT而言,其词表的大小为40,478,其中,基本字符一共有478个,合并后的词有40,000个。
字节级的BPE
一个包含所有基本字符的词表也可以非常的大,例如,如果将所有的unicode字符视为基本字符。针对这一问题,GPT-2使用字节来作为基本词表,这种方法保证了所有的基本字符都包含在了词表中,且基本词表的大小被限定为256。再加上一些用于处理标点的规则,GPT2的tokenizer可以切分任何英文句子,而不必引入符号。GPT-2的词表大小为50,257,包含了256个字节级的基本词表,一个用于标识句子结尾的特殊字符,以及学习到的50,000个合并单词。
4.1.1 训练阶段
目标是:给定语料,通过训练算法,生成合并规则和词表。BPE算法是从一个字符级别的词表为基础,合并pair并添加到词表中,逐步形成大词表。合并规则为选择相邻pair词频最大的进行合并。
预训练的语料(已经进行归一化处理)的四个句子:
corpus = [
"This is the Hugging Face Course.",
"This chapter is about tokenization.",
"This section shows several tokenizer algorithms.",
"Hopefully, you will be able to understand how they are trained and generate tokens.",
]
首先进行预切分处理。这里采用gpt2的预切分逻辑。 具体会按照空格和标点进行切分,并且空格会保留成特殊的字符“Ġ”。
from transformers import AutoTokenizer
# init pre tokenize function
gpt2_tokenizer = AutoTokenizer.from_pretrained("gpt2")
pre_tokenize_function = gpt2_tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str
# pre tokenize
pre_tokenized_corpus = [pre_tokenize_str(text) for text in corpus]
获得的pre_tokenized_corpus如下,每个单元分别为[word, (start_index, end_index)]
[
[('This', (0, 4)), ('Ġis', (4, 7)), ('Ġthe', (7, 11)), ('ĠHugging', (11, 19)), ('ĠFace', (19, 24)), ('ĠCourse', (24, 31)), ('.', (31, 32))],
[('This', (0, 4)), ('Ġchapter', (4, 12)), ('Ġis', (12, 15)), ('Ġabout', (15, 21)), ('Ġtokenization', (21, 34)), ('.', (34, 35))],
[('This', (0, 4)), ('Ġsection', (4, 12)), ('Ġshows', (12, 18)), ('Ġseveral', (18, 26)), ('Ġtokenizer', (26, 36)), ('Ġalgorithms', (36, 47)), ('.', (47, 48))],
[('Hopefully', (0, 9)), (',', (9, 10)), ('Ġyou', (10, 14)), ('Ġwill', (14, 19)), ('Ġbe', (19, 22)), ('Ġable', (22, 27)), ('Ġto', (27, 30)), ('Ġunderstand', (30, 41)), ('Ġhow', (41, 45)), ('Ġthey', (45, 50)), ('Ġare', (50, 54)), ('Ġtrained', (54, 62)), ('Ġand', (62, 66)), ('Ġgenerate', (66, 75)), ('Ġtokens', (75, 82)), ('.', (82, 83))]
]
进一步统计每个整词的词频
word2count = defaultdict(int)
for split_text in pre_tokenized_corpus:
for word, _ in split_text:
word2count[word] += 1
获得word2count如下
defaultdict(<class 'int'>, {'This': 3, 'Ġis': 2, 'Ġthe': 1, 'ĠHugging': 1, 'ĠFace': 1, 'ĠCourse': 1, '.': 4, 'Ġchapter': 1, 'Ġabout': 1, 'Ġtokenization': 1, 'Ġsection': 1, 'Ġshows': 1, 'Ġseveral': 1, 'Ġtokenizer': 1, 'Ġalgorithms': 1, 'Hopefully': 1, ',': 1, 'Ġyou': 1, 'Ġwill': 1, 'Ġbe': 1, 'Ġable': 1, 'Ġto': 1, 'Ġunderstand': 1, 'Ġhow': 1, 'Ġthey': 1, 'Ġare': 1, 'Ġtrained': 1, 'Ġand': 1, 'Ġgenerate': 1, 'Ġtokens': 1})
因为BPE是从字符级别的小词表,逐步合并成大词表,所以需要先获得字符级别的小词表。
vocab_set = set()
for word in word2count:
vocab_set.update(list(word))
vocabs = list(vocab_set)
获得的初始小词表vocabs如下:
['i', 't', 'p', 'o', 'r', 'm', 'e', ',', 'y', 'v', 'Ġ', 'F', 'a', 'C', 'H', '.', 'f', 'l', 'u', 'c', 'T', 'k', 'h', 'z', 'd', 'g', 'w', 'n', 's', 'b']
基于小词表就可以对每个整词进行切分
word2splits = {word: [c for c in word] for word in word2count}
'This': ['T', 'h', 'i', 's'],
'Ġis': ['Ġ', 'i', 's'],
'Ġthe': ['Ġ', 't', 'h', 'e'],
...
'Ġand': ['Ġ', 'a', 'n', 'd'],
'Ġgenerate': ['Ġ', 'g', 'e', 'n', 'e', 'r', 'a', 't', 'e'],
'Ġtokens': ['Ġ', 't', 'o', 'k', 'e', 'n', 's']
基于word2splits统计vocabs中相邻两个pair的词频pair2count
def _compute_pair2score(word2splits, word2count):
pair2count = defaultdict(int)
for word, word_count in word2count.items():
split = word2splits[word]
if len(split) == 1:
continue
for i in range(len(split) - 1):
pair = (split[i], split[i + 1])
pair2count[pair] += word_count
return pair2count
获得pair2count如下:
defaultdict(<class 'int'>, {('T', 'h'): 3, ('h', 'i'): 3, ('i', 's'): 5, ('Ġ', 'i'): 2, ('Ġ', 't'): 7, ('t', 'h'): 3, ..., ('n', 's'): 1})
统计当前频率最高的相邻pair
def _compute_most_score_pair(pair2count):
best_pair = None
max_freq = None
for pair, freq in pair2count.items():
if max_freq is None or max_freq < freq:
best_pair = pair
max_freq = freq
return best_pair
经过统计,当前频率最高的pair为: (‘Ġ’, ‘t’), 频率为7次。 将(‘Ġ’, ‘t’)合并成一个词并添加到词表中。同时在合并规则中添加(‘Ġ’, ‘t’)这条合并规则。
merge_rules = []
best_pair = self._compute_most_score_pair(pair2score)
vocabs.append(best_pair[0] + best_pair[1])
merge_rules.append(best_pair)
此时的vocab词表更新成:
['i', 't', 'p', 'o', 'r', 'm', 'e', ',', 'y', 'v', 'Ġ', 'F', 'a', 'C', 'H', '.', 'f', 'l', 'u', 'c', 'T', 'k', 'h', 'z', 'd', 'g', 'w', 'n', 's', 'b',
'Ġt']
根据更新后的vocab重新对word2count进行切分。具体实现上,可以直接在旧的word2split上应用新的合并规则(‘Ġ’, ‘t’)
def _merge_pair(a, b, word2splits):
new_word2splits = dict()
for word, split in word2splits.items():
if len(split) == 1:
new_word2splits[word] = split
continue
i = 0
while i < len(split) - 1:
if split[i] == a and split[i + 1] == b:
split = split[:i] + [a + b] + split[i + 2:]
else:
i += 1
new_word2splits[word] = split
return new_word2splits
从而获得新的word2split
{'This': ['T', 'h', 'i', 's'],
'Ġis': ['Ġ', 'i', 's'],
'Ġthe': ['Ġt', 'h', 'e'],
'ĠHugging': ['Ġ', 'H', 'u', 'g', 'g', 'i', 'n', 'g'],
...
'Ġtokens': ['Ġt', 'o', 'k', 'e', 'n', 's']}
可以看到新的word2split中已经包含了新的词"Ġt"。
重复上述循环直到整个词表的大小达到预先设定的词表大小。
while len(vocabs) < vocab_size:
pair2score = self._compute_pair2score(word2splits, word2count)
best_pair = self._compute_most_score_pair(pair2score)
vocabs.append(best_pair[0] + best_pair[1])
merge_rules.append(best_pair)
word2splits = self._merge_pair(best_pair[0], best_pair[1], word2splits)
假定最终词表的大小为50,经过上述迭代后我们获得的词表和合并规则如下:
vocabs = ['i', 't', 'p', 'o', 'r', 'm', 'e', ',', 'y', 'v', 'Ġ', 'F', 'a', 'C', 'H', '.', 'f', 'l', 'u', 'c', 'T', 'k', 'h', 'z', 'd', 'g', 'w', 'n', 's', 'b', 'Ġt', 'is', 'er', 'Ġa', 'Ġto', 'en', 'Th', 'This', 'ou', 'se', 'Ġtok', 'Ġtoken', 'nd', 'Ġis', 'Ġth', 'Ġthe', 'in', 'Ġab', 'Ġtokeni', 'Ġtokeniz']
merge_rules = [('Ġ', 't'), ('i', 's'), ('e', 'r'), ('Ġ', 'a'), ('Ġt', 'o'), ('e', 'n'), ('T', 'h'), ('Th', 'is'), ('o', 'u'), ('s', 'e'), ('Ġto', 'k'), ('Ġtok', 'en'), ('n', 'd'), ('Ġ', 'is'), ('Ġt', 'h'), ('Ġth', 'e'), ('i', 'n'), ('Ġa', 'b'), ('Ġtoken', 'i'), ('Ġtokeni', 'z')]
至此我们就根据给定的语料完成了BPE分词器的训练。
4.1.2 推理阶段
在推理阶段,给定一个句子,我们需要将其切分成一个token的序列。 具体实现上需要先对句子进行预分词并切分成字符级别的序列,然后根据合并规则进行合并。
def tokenize(self, text: str) -> List[str]:
# pre tokenize
words = [word for word, _ in self.pre_tokenize_str(text)]
# split into char level
splits = [[c for c in word] for word in words]
# apply merge rules
for merge_rule in self.merge_rules:
for index, split in enumerate(splits):
i = 0
while i < len(split) - 1:
if split[i] == merge_rule[0] and split[i + 1] == merge_rule[1]:
split = split[:i] + ["".join(merge_rule)] + split[i + 2:]
else:
i += 1
splits[index] = split
return sum(splits, [])
例如:
>>> tokenize("This is not a token.")
>>> ['This', 'Ġis', 'Ġ', 'n', 'o', 't', 'Ġa', 'Ġtoken', '.']
可以看出 not 并没有被 识别出来
4.1.3 BBPE
2019年提出的Byte-level BPE (BBPE)算法是上面BPE算法的进一步升级。具体参见:Neural Machine Translation with Byte-Level Subwords。 核心思想是用byte来构建最基础的词表而不是字符。首先将文本按照UTF-8进行编码,每个字符在UTF-8的表示中占据1-4个byte。 在byte序列上再使用BPE算法,进行byte level的相邻合并。编码形式如下图所示:
通过这种方式可以更好的处理跨语言和不常见字符的特殊问题(例如,颜文字),相比传统的BPE更节省词表空间(同等词表大小效果更好),每个token也能获得更充分的训练。
但是在解码阶段,一个byte序列可能解码后不是一个合法的字符序列,这里需要采用动态规划的算法进行解码,使其能解码出尽可能多的合法字符。
4.2 WordPiece
WordPiece是一种被应用于BERT,DistilBERT和Electra中的子词切分算法,它与BPE算法非常像。
- 首先,它初始化一个包含所有出现在训练数据中的字符的词表
- 然后递归地学习一些合并规则。
- 与BPE不同的是,WordPiece并不选择出现的频数最高的组合,而是选择可以最大化训练数据可能性的组合。
仍然拿上面的例子来说明。最大化训练数据的可能性就等同于找到这样的符号对,它的概率除以其第一个符号的概率与其第二个符号的概率的乘积,所得的值是所有可能的符号对中最大的。例如,如果"ug"的概率除以"u"的概率再除以"g"的概率得到的结果比其他任何一种组合的结果都大,那么就将"ug"组合起来。从直觉上说,WordPiece在合并两个符号前,评估了一下这种合并所带来的损失(合并后的概率除以合并前的概率),以确保这种合并是有价值的。
4.2.1 训练阶段
在训练环节,给定语料,通过训练算法,生成最终的词表。 WordPiece算法也是从一个字符级别的词表为基础,逐步扩充成大词表。合并规则为选择相邻pair互信息最大的进行合并。
corpus = [
"This is the Hugging Face Course.",
"This chapter is about tokenization.",
"This section shows several tokenizer algorithms.",
"Hopefully, you will be able to understand how they are trained and generate tokens.",
]
首先进行预切分处理。这里采用BERT的预切分逻辑。具体会按照空格和标点进行切分。
from transformers import AutoTokenizer
# init pre tokenize function
bert_tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
pre_tokenize_function = bert_tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str
# pre tokenize
pre_tokenized_corpus = [pre_tokenize_str(text) for text in corpus]
获得的pre_tokenized_corpus如下,每个单元分别为[word, (start_index, end_index)]
[
[('This', (0, 4)), ('is', (5, 7)), ('the', (8, 11)), ('Hugging', (12, 19)), ('Face', (20, 24)), ('Course', (25, 31)), ('.', (31, 32))],
[('This', (0, 4)), ('chapter', (5, 12)), ('is', (13, 15)), ('about', (16, 21)), ('tokenization', (22, 34)), ('.', (34, 35))],
[('This', (0, 4)), ('section', (5, 12)), ('shows', (13, 18)), ('several', (19, 26)), ('tokenizer', (27, 36)), ('algorithms', (37, 47)), ('.', (47, 48))],
[('Hopefully', (0, 9)), (',', (9, 10)), ('you', (11, 14)), ('will', (15, 19)), ('be', (20, 22)), ('able', (23, 27)), ('to', (28, 30)), ('understand', (31, 41)), ('how', (42, 45)), ('they', (46, 50)), ('are', (51, 54)), ('trained', (55, 62)), ('and', (63, 66)), ('generate', (67, 75)), ('tokens', (76, 82)), ('.', (82, 83))]
]
进一步统计词频
word2count = defaultdict(int)
for split_text in pre_tokenized_corpus:
for word, _ in split_text:
word2count[word] += 1
获得word2count如下
defaultdict(<class ‘int’>, {‘This’: 3, ‘is’: 2, ‘the’: 1, ‘Hugging’: 1, ‘Face’: 1, ‘Course’: 1, ‘.’: 4, ‘chapter’: 1, ‘about’: 1, ‘tokenization’: 1, ‘section’: 1, ‘shows’: 1, ‘several’: 1, ‘tokenizer’: 1, ‘algorithms’: 1, ‘Hopefully’: 1, ‘,’: 1, ‘you’: 1, ‘will’: 1, ‘be’: 1, ‘able’: 1, ‘to’: 1, ‘understand’: 1, ‘how’: 1, ‘they’: 1, ‘are’: 1, ‘trained’: 1, ‘and’: 1, ‘generate’: 1, ‘tokens’: 1})
获得的初始小词表vocabs如下:
[‘##a’, ‘##b’, ‘##c’, ‘##d’, ‘##e’, ‘##f’, ‘##g’, ‘##h’, ‘##i’, ‘##k’, ‘##l’, ‘##m’, ‘##n’, ‘##o’, ‘##p’, ‘##r’, ‘##s’, ‘##t’, ‘##u’, ‘##v’, ‘##w’, ‘##y’, ‘##z’, ‘,’, ‘.’, ‘C’, ‘F’, ‘H’, ‘T’, ‘a’, ‘b’, ‘c’, ‘g’, ‘h’, ‘i’, ‘s’, ‘t’, ‘u’, ‘w’, ‘y’]
基于小词表对每个词进行切分
word2splits = {word: [word[0]] + ['##' + c for c in word[1:]] for word in word2count}
{'This': ['T', '##h', '##i', '##s'],
'is': ['i', '##s'],
'the': ['t', '##h', '##e'],
'Hugging': ['H', '##u', '##g', '##g', '##i', '##n', '##g'],
...
'generate': ['g', '##e', '##n', '##e', '##r', '##a', '##t', '##e'],
'tokens': ['t', '##o', '##k', '##e', '##n', '##s']}
进一步统计vocabs中相邻两个pair的互信息
def _compute_pair2score(word2splits, word2count):
"""
计算每个pair的分数
score=(freq_of_pair)/(freq_of_first_element×freq_of_second_element)
:return:
"""
vocab2count = defaultdict(int)
pair2count = defaultdict(int)
for word, word_count in word2count.items():
splits = word2splits[word]
if len(splits) == 1:
vocab2count[splits[0]] += word_count
continue
for i in range(len(splits) - 1):
pair = (splits[i], splits[i + 1])
vocab2count[splits[i]] += word_count
pair2count[pair] += word_count
vocab2count[splits[-1]] += word_count
scores = {
pair: freq / (vocab2count[pair[0]] * vocab2count[pair[1]])
for pair, freq in pair2count.items()
}
return scores
获得每个pair的互信息如下:
{('T', '##h'): 0.125,
('##h', '##i'): 0.03409090909090909,
('##i', '##s'): 0.02727272727272727,
('a', '##b'): 0.2,
...
('##n', '##s'): 0.00909090909090909}
统计出互信息最高的相邻pair
def _compute_most_score_pair(pair2score):
best_pair = None
max_score = None
for pair, score in pair2score.items():
if max_score is None or max_score < score:
best_pair = pair
max_score = score
return best_pair
此时互信息最高的pair为: (‘a’, ‘##b’) 将(‘a’, ‘##b’)合并成一个词’ab’并添加到词表中
best_pair = self._compute_most_score_pair(pair2score)
vocabs.append(best_pair[0] + best_pair[1])
这样vocab词表更新成:
[‘##a’, ‘##b’, ‘##c’, ‘##d’, ‘##e’, ‘##f’, ‘##g’, ‘##h’, ‘##i’, ‘##k’, ‘##l’, ‘##m’, ‘##n’, ‘##o’, ‘##p’, ‘##r’, ‘##s’, ‘##t’, ‘##u’, ‘##v’, ‘##w’, ‘##y’, ‘##z’, ‘,’, ‘.’, ‘C’, ‘F’, ‘H’, ‘T’, ‘a’, ‘b’, ‘c’, ‘g’, ‘h’, ‘i’, ‘s’, ‘t’, ‘u’, ‘w’, ‘y’,
‘ab’]
根据更新的vocab重新对word2count进行切分。
def _merge_pair(a, b, word2splits):
new_word2splits = dict()
for word, split in word2splits.items():
if len(split) == 1:
new_word2splits[word] = split
continue
i = 0
while i < len(split) - 1:
if split[i] == a and split[i + 1] == b:
merge = a + b[2:] if b.startswith("##") else a + b
split = split[:i] + [merge] + split[i + 2:]
else:
i += 1
new_word2splits[word] = split
return new_word2splits
获得新的word2split
{'This': ['T', '##h', '##i', '##s'],
'is': ['i', '##s'], 'the': ['t', '##h', '##e'],
'Hugging': ['H', '##u', '##g', '##g', '##i', '##n', '##g'],
'about': ['ab', '##o', '##u', '##t'],
'tokens': ['t', '##o', '##k', '##e', '##n', '##s']}
可以看到新的word2split中已经包含了新的词"ab"。
重复上述步骤,直到整个词表的大小达到预先设定的词表大小。
while len(vocabs) < vocab_size:
pair2score = self._compute_pair2score(word2splits, word2count)
best_pair = self._compute_most_score_pair(pair2score)
word2splits = self._merge_pair(best_pair[0], best_pair[1], word2splits)
new_token = best_pair[0] + best_pair[1][2:] if best_pair[1].startswith('##') else best_pair[1]
vocabs.append(new_token)
假定最终词表的大小为70,经过上述迭代后我们获得的词表如下:
vocabs = [‘##a’, ‘##b’, ‘##c’, ‘##ct’, ‘##d’, ‘##e’, ‘##f’, ‘##fu’, ‘##ful’, ‘##full’, ‘##fully’, ‘##g’, ‘##h’, ‘##hm’, ‘##i’, ‘##k’, ‘##l’, ‘##m’, ‘##n’, ‘##o’, ‘##p’, ‘##r’, ‘##s’, ‘##t’, ‘##thm’, ‘##thms’, ‘##u’, ‘##ut’, ‘##v’, ‘##w’, ‘##y’, ‘##z’, ‘##za’, ‘##zat’, ‘,’, ‘.’, ‘C’, ‘F’, ‘Fa’, ‘Fac’, ‘H’, ‘Hu’, ‘Hug’, ‘Hugg’, ‘T’, ‘Th’, ‘a’, ‘ab’, ‘b’, ‘c’, ‘ch’, ‘cha’, ‘chap’, ‘chapt’, ‘g’, ‘h’, ‘i’, ‘is’, ‘s’, ‘sh’, ‘t’, ‘th’, ‘u’, ‘w’, ‘y’, ‘[CLS]’, ‘[MASK]’, ‘[PAD]’, ‘[SEP]’, ‘[UNK]’]
注意词表中添加了特殊的token:[CLS], [MASK], [PAD], [SEP], [UNK] 至此我们就根据给定的语料完成了WordPiece分词器的训练。
4.2.2 推理阶段
在推理阶段,给定一个句子,需要将其切分成一个token的序列。 具体实现上需要先对句子进行预分词,然后对每个词进行在词表中进行最大前向的匹配。如果词表中不存在则为UNK。
def _encode_word(self, word):
tokens = []
while len(word) > 0:
i = len(word)
while i > 0 and word[:i] not in self.vocabs:
i -= 1
if i == 0:
return ["[UNK]"]
tokens.append(word[:i])
word = word[i:]
if len(word) > 0:
word = f"##{word}"
return tokens
def tokenize(self, text):
words = [word for word, _ in self.pre_tokenize_str(text)]
encoded_words = [self._encode_word(word) for word in words]
return sum(encoded_words, [])
>>> tokenize("This is the Hugging Face course!")
>>> ['Th', '##i', '##s', 'is', 'th', '##e', 'Hugg', '##i', '##n', '##g', 'Fac', '##e', 'c', '##o', '##u', '##r', '##s', '##e', '[UNK]']
4.3 Unigram
论文Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates提出了基于子词的Unigram的切分方法。与BPE和WordPiece不同的是,Unigram以一个大规模的符号库作为其初始词表,然后采用迭代的方式来不断降低词表的规模。例如,初始词表可以是一个包含所有的预先切分的单词和所有常见子词的集合。
在每一个训练步中,Unigram算法在给定当前词表和一元语言模型的情况下定义了训练数据的损失函数(通常为对数似然函数)。然后,对于词表中的每一个符号,算法都会计算出如果将该符号从词表中移除,全局损失会增加多少。随后,Unigram会移除一定百分比(通常是10%或20%)的那些使损失增加最少的符号。
重复上述训练过程,直到词表达到预定的规模。由于Unigram总是保留基本字符,因此它可以切分任何单词。
由于Unigram并不像BPE和WordPiece那样依赖合并规则,所以,经过训练的Unigram在切分文本时可能会有多种选择。假设一个Unigram tokenizer的词表如下:
[“b”, “g”, “h”, “n”, “p”, “s”, “u”, “ug”, “un”, “hug”],
单词"hugs"可以被切分为[“hug”, “s”]、[“h”, “ug”, “s”]或[“h”, “u”, “g”, “s”]。那么,究竟该选择哪一种呢?Unigram在保存词表的基础上,也保存了训练语料库中每个token的概率,以便在训练后计算每一种可能的切分的概率。Unigram在实践中只是简单地选择概率最大的切分作为最终结果,但也提供了根据概率对可能的切分进行采样的能力。
4.3.1 训练阶段
在训练环节,目标是给定语料,通过训练算法,生成最终的词表,并且每个词有自己的概率值。 Unigram算法是从大词表为基础,逐步裁剪成小词表。裁剪规则是根据Unigram语言模型的打分依次裁剪重要度相对较低的词。
下面进行具体手工实现。
假定训练的语料(已归一化处理)为
corpus = [
"This is the Hugging Face Course.",
"This chapter is about tokenization.",
"This section shows several tokenizer algorithms.",
"Hopefully, you will be able to understand how they are trained and generate tokens.",
]
首先进行预切分处理。这里采用xlnet的预切分逻辑。具体会按照空格进行切分,标点不会切分。并且空格会保留成特殊字符"▁",句子开头也会添加特殊字符"▁"。
from transformers import AutoTokenizer
# init pre tokenize function
xlnet_tokenizer = AutoTokenizer.from_pretrained("xlnet-base-cased")
pre_tokenize_function = xlnet_tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str
# pre tokenize
pre_tokenized_corpus = [pre_tokenize_str(text) for text in corpus]
获得的pre_tokenized_corpus如下,每个单元分别为[word, (start_index, end_index)]
[
[('▁This', (0, 4)), ('▁is', (5, 7)), ('▁the', (8, 11)), ('▁Hugging', (12, 19)), ('▁Face', (20, 24)), ('▁Course.', (25, 32))],
[('▁This', (0, 4)), ('▁chapter', (5, 12)), ('▁is', (13, 15)), ('▁about', (16, 21)), ('▁tokenization.', (22, 35))],
[('▁This', (0, 4)), ('▁section', (5, 12)), ('▁shows', (13, 18)), ('▁several', (19, 26)), ('▁tokenizer', (27, 36)), ('▁algorithms.', (37, 48))],
[('▁Hopefully,', (0, 10)), ('▁you', (11, 14)), ('▁will', (15, 19)), ('▁be', (20, 22)), ('▁able', (23, 27)), ('▁to', (28, 30)), ('▁understand', (31, 41)), ('▁how', (42, 45)), ('▁they', (46, 50)), ('▁are', (51, 54)), ('▁trained', (55, 62)), ('▁and', (63, 66)), ('▁generate', (67, 75)), ('▁tokens.', (76, 83))]
]
进一步统计词频
word2count = defaultdict(int)
for split_text in pre_tokenized_corpus:
for word, _ in split_text:
word2count[word] += 1
获得word2count如下
defaultdict(<class 'int'>, {'▁This': 3, '▁is': 2, '▁the': 1, '▁Hugging': 1, '▁Face': 1, '▁Course.': 1, '▁chapter': 1, '▁about': 1, '▁tokenization.': 1, '▁section': 1, '▁shows': 1, '▁several': 1, '▁tokenizer': 1, '▁algorithms.': 1, '▁Hopefully,': 1, '▁you': 1, '▁will': 1, '▁be': 1, '▁able': 1, '▁to': 1, '▁understand': 1, '▁how': 1, '▁they': 1, '▁are': 1, '▁trained': 1, '▁and': 1, '▁generate': 1, '▁tokens.': 1})
统计词表的全部子词和词频,取前300个词,构成最初的大词表。为了避免OOV,char级别的词均需要保留。
char2count = defaultdict(int)
sub_word2count = defaultdict(int)
for word, count in word2count.items():
for i in range(len(word)):
char2count[word[i]] += count
for j in range(i + 2, len(word) + 1):
sub_word2count[word[i:j]] += count
sorted_sub_words = sorted(sub_word2count.items(), key=lambda x: x[1], reverse=True)
# init a large vocab with 300
tokens = list(char2count.items()) + sorted_sub_words[: 300 - len(char2count)]
获得的初始小词表vocabs如下:
[('▁', 31), ('T', 3), ('h', 9), ('i', 13), ('s', 13), ..., ('several', 1)]
进一步统计每个子词的概率,并转换成Unigram里的loss贡献
token2count = {token: count for token, count in tokens}
total_count = sum([count for token, count in token2count.items()])
model = {token: -log(count / total_count) for token, count in token2count.items()}
model = {
'▁': 2.952892114877499,
'T': 5.288267030694535,
'h': 4.189654742026425,
...,
'sever': 6.386879319362645,
'severa': 6.386879319362645,
'several': 6.386879319362645
}
基于每个子词的loss以及Viterbi算法就可以求解出,输入的一个词的最佳分词路径。即整体语言模型的loss最小。词的长度为N,解码的时间复杂度为O(N^2)。
def _encode_word(word, model):
best_segmentations = [{"start": 0, "score": 1}] + [{"start": None, "score": None} for _ in range(len(word))]
for start_idx in range(len(word)):
# This should be properly filled by the previous steps of the loop
best_score_at_start = best_segmentations[start_idx]["score"]
for end_idx in range(start_idx + 1, len(word) + 1):
token = word[start_idx:end_idx]
if token in model and best_score_at_start is not None:
score = model[token] + best_score_at_start
# If we have found a better segmentation (lower score) ending at end_idx
if (
best_segmentations[end_idx]["score"] is None
or best_segmentations[end_idx]["score"] > score
):
best_segmentations[end_idx] = {"start": start_idx, "score": score}
segmentation = best_segmentations[-1]
if segmentation["score"] is None:
# We did not find a tokenization of the word -> unknown
return ["<unk>"], None
score = segmentation["score"]
start = segmentation["start"]
end = len(word)
tokens = []
while start != 0:
tokens.insert(0, word[start:end])
next_start = best_segmentations[start]["start"]
end = start
start = next_start
tokens.insert(0, word[start:end])
return tokens, score
例如:
>>> tokenize("This")
>>> (['This'], 6.288267030694535)
>>> tokenize("this")
>>>(['t', 'his'], 10.03608902044192)
基于上述的函数,可以获得任一个词的分词路径,以及loss。这样就可以计算整个语料上的loss。
def _compute_loss(self, model, word2count):
loss = 0
for word, freq in word2count.items():
_, word_loss = self._encode_word(word, model)
loss += freq * word_loss
return loss
尝试移除model中的一个子词,并计算移除后新的model在全部语料上的loss,从而获得这个子词的score,即删除这个子词使得loss新增的量。
def _compute_scores(self, model, word2count):
scores = {}
model_loss = self._compute_loss(model, word2count)
for token, score in model.items():
# We always keep tokens of length 1
if len(token) == 1:
continue
model_without_token = copy.deepcopy(model)
_ = model_without_token.pop(token)
scores[token] = self._compute_loss(model_without_token, word2count) - model_loss
return scores
scores = self._compute_scores(model, word2count)
为了提升迭代效率,批量删除前10%的结果,即让整体loss增量最小的前10%的词。(删除这些词对整体loss的影响不大。)
sorted_scores = sorted(scores.items(), key=lambda x: x[1])
# Remove percent_to_remove tokens with the lowest scores.
for i in range(int(len(model) * 0.1)):
_ = token2count.pop(sorted_scores[i][0])
获得新的词表后,重新计算每个词的概率,获得新的模型。并重复以上步骤,直到裁剪到词表大小符合要求。
while len(model) > vocab_size:
scores = self._compute_scores(model, word2count)
sorted_scores = sorted(scores.items(), key=lambda x: x[1])
# Remove percent_to_remove tokens with the lowest scores.
for i in range(int(len(model) * percent_to_remove)):
_ = token2count.pop(sorted_scores[i][0])
total_count = sum([freq for token, freq in token2count.items()])
model = {token: -log(count / total_count) for token, count in token2count.items()}
假定预设的词表的大小为100,经过上述迭代后我们获得词表如下:
model = {
'▁': 2.318585434340487,
'T': 4.653960350157523,
'h': 3.5553480614894135,
'i': 3.1876232813640963,
...
'seve': 5.752572638825633,
'sever': 5.752572638825633,
'severa': 5.752572638825633,
'several': 5.752572638825633
}
4.3.2 推理阶段
在推理阶段,给定一个句子,需要将其切分成一个token的序列。 具体实现上先对句子进行预分词,然后对每个词基于Viterbi算法进行解码。
def tokenize(self, text):
words = [word for word, _ in self.pre_tokenize_str(text)]
encoded_words = [self._encode_word(word, self.model)[0] for word in words]
return sum(encoded_words, [])
例如
>>> tokenize("This is the Hugging Face course!")
>>> ['▁This', '▁is', '▁the', '▁Hugging', '▁Face', '▁', 'c', 'ou', 'r', 's', 'e', '.']
基于Viterbi的切分获得的是最佳切分,基于unigram可以实现一个句子的多种切分方式,并且可以获得每种切分路径的打分。
4.4 SentencePiece
上文介绍了所有的切分算法都有一个共同的问题:它们都假定输入的文本使用空格进行单词划分。然而,并不是所有的语言都是这样的。针对这一点,一种解决方案是,使用基于特定语言的tokenizer进行预先分词,例如,XLM使用了针对中文、日文和泰文的tokenizer。一个更一般的解决方案,在论文SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing(Kudo et al., 2018)中被提出。这种方法将输入的文本视为元输入流,进而将空格包含在要使用的字符集中。然后,它再使用BPE或Unigram算法来构建一个合适的词表。
XLNetTokenizer使用了SentencePiece,这也就是为什么在上面的例子中,"_ “出现在其切分结果中。基于SentencePiece的解码非常容易:将各个token拼接起来,把”_ "替换为空格即可。
SentencePiece是Google出的一个分词工具:
- 内置BPE,Unigram,char和word的分词方法
- 无需预分词,以unicode方式直接编码整个句子,空格会被特殊编码为▁
- 相比传统实现进行优化,分词速度速度更快
当前主流的大模型都是基于sentencepiece实现,例如ChatGLM的tokenizer。
class TextTokenizer:
def __init__(self, model_path):
self.sp = spm.SentencePieceProcessor()
self.sp.Load(model_path)
self.num_tokens = self.sp.vocab_size()
def encode(self, text):
return self.sp.EncodeAsIds(text)
def decode(self, ids: List[int]):
return self.sp.DecodeIds(ids)
https://huggingface.co/THUDM/chatglm-6b/blob/main/tokenization_chatglm.py#L21
4.4.1 byte回退
当SentencePiece在训练BPE的时开启–byte_fallback, 在效果上类似BBPE,遇到UNK会继续按照byte进行进一步的切分。参见:https://github.com/google/sentencepiece/issues/621 具体实现上是将<0x00> … <0xFF>这256个token添加到词表中。
分析ChatGLM的模型,可以发现ChatGLM就是开启了–byte_fallback
from sentencepiece import sentencepiece_model_pb2
m = sentencepiece_model_pb2.ModelProto()
with open('chatglm-6b/ice_text.model', 'rb') as f:
m.ParseFromString(f.read())
print('ChatGLM tokenizer\n\n'+str(m.trainer_spec))
output:
ChatGLM tokenizer
input: “/root/train_cn_en.json”
model_prefix: “new_ice_unigram”
vocab_size: 130000
character_coverage: 0.9998999834060669
split_digits: true
user_defined_symbols: “< n>”
byte_fallback: true
pad_id: 3
train_extremely_large_corpus: true
可以看到byte_fallback: true
同样的方法,可以验证LLaMA, ChatGLM-6B, Baichuan这些大模型都是基于sentencepiece实现的BPE的分词算法,并且采用byte回退。
5. 语法
Tokenizer定义
keras.preprocessing.text.Tokenizer(num_words=None,
filters='!"#$%&()*+,-./:;<=>?@[]^_`{|}~ ‘,
lower=True,
split=’ ',
char_level=False,
oov_token=None,
document_count=0)
参数说明:
num_words: 需要保留的最大词数,基于词频。只有最常出现的 num_words 词会被保留。
filters: 一个字符串,其中每个元素是一个将从文本中过滤掉的字符。默认值是所有标点符号,加上制表符和换行符,减去 ’ 字符。
lower: 布尔值。是否将文本转换为小写。
split: 字符串。按该字符串切割文本。
char_level: 如果为 True,则每个字符都将被视为标记。
oov_token: 如果给出,它将被添加到 word_index 中,并用于在 text_to_sequence 调用期间替换词汇
Tokenizer方法
(1)fit_on_texts(texts)
参数 texts:要用以训练的文本列表。
返回值:无。
(2)texts_to_sequences(texts)
参数 texts:待转为序列的文本列表。
返回值:序列的列表,列表中每个序列对应于一段输入文本。
(3)texts_to_sequences_generator(texts)
本函数是texts_to_sequences的生成器函数版。
参数 texts:待转为序列的文本列表。
返回值:每次调用返回对应于一段输入文本的序列。
(4)texts_to_matrix(texts, mode) :
参数 texts:待向量化的文本列表。
参数 mode:‘binary’,‘count’,‘tfidf’,‘freq’ 之一,默认为 ‘binary’。
返回值:形如(len(texts), num_words) 的numpy array。
(5)fit_on_sequences(sequences) :
参数 sequences:要用以训练的序列列表。
返回值:无
(6)sequences_to_matrix(sequences) :
参数 sequences:待向量化的序列列表。
参数 mode:‘binary’,‘count’,‘tfidf’,‘freq’ 之一,默认为 ‘binary’。
返回值:形如(len(sequences), num_words) 的 numpy array。
Tokenizer属性
(1)word_counts
类型:字典
描述:将单词(字符串)映射为它们在训练期间出现的次数。仅在调用fit_on_texts之后设置。
(2)word_docs
类型:字典
描述:将单词(字符串)映射为它们在训练期间所出现的文档或文本的数量。仅在调用fit_on_texts之后设置。
(3)word_index
类型:字典,
描述:将单词(字符串)映射为它们的排名或者索引。仅在调用fit_on_texts之后设置。
(4)document_count
类型:整数。
描述:分词器被训练的文档(文本或者序列)数量。仅在调用fit_on_texts或fit_on_sequences之后设置。
5.1 英文文本向量化
默认情况下,删除所有标点符号,将文本转换为空格分隔的单词序列(单词可能包含 ’ 字符)。 这些序列然后被分割成标记列表。然后它们将被索引或向量化。0是不会被分配给任何单词的保留索引。
from keras.preprocessing.text import Tokenizer
texts = ["Life is a journey, and if you fall in love with the journey, you will be in love forever.",
"Dreams are like stars, you may never touch them, but if you follow them, they will lead you to your destiny.",
"Memories are the heart's treasures, they hold the wisdom and beauty of our past.",
"Nature is the most beautiful artist, its paintings are endless and always breathtaking.",
"True happiness is not about having everything, but about being content with what you have.",
"Wisdom comes with age, but more often with experience.",
"Music has the power to transport us to a different place, a different time.",
"Love is blind, but often sees more than others.",
"Time heals all wounds, but only if you let it.",
"Home is where the heart is, and for many, that is where the memories are."]
tokenizer = Tokenizer(num_words=64, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n',
lower=True, split=' ', char_level=False, oov_token=None,
document_count=0)
# 根据输入的文本列表更新内部字典
tokenizer.fit_on_texts(texts)
print("处理的文档数量,document_count: ", tokenizer.document_count)
print("单词到索引的映射,word_index: \n", tokenizer.word_index)
print("索引到单词的映射,index_word: \n", tokenizer.index_word)
print("每个单词出现的总频次,word_counts: \n", tokenizer.word_counts)
print("出现单词的文档的数量,word_docs: \n", tokenizer.word_docs)
print("单词索引对应的出现单词的文档的数量,index_docs: \n", tokenizer.index_docs)
结果如下:
处理的文档数量,document_count: 10
单词到索引的映射,word_index:
{'is': 1, 'you': 2, 'the': 3, 'but': 4, 'and': 5, 'with': 6, 'are': 7, 'a': 8, 'if': 9, 'love': 10, 'to': 11, 'journey': 12, 'in': 13, 'will': 14, 'them': 15, 'they': 16, 'memories': 17, 'wisdom': 18, 'about': 19, 'more': 20, 'often': 21, 'different': 22, 'time': 23, 'where': 24, 'life': 25, 'fall': 26, 'be': 27, 'forever': 28, 'dreams': 29, 'like': 30, 'stars': 31, 'may': 32, 'never': 33, 'touch': 34, 'follow': 35, 'lead': 36, 'your': 37, 'destiny': 38, "heart's": 39, 'treasures': 40, 'hold': 41, 'beauty': 42, 'of': 43, 'our': 44, 'past': 45, 'nature': 46, 'most': 47, 'beautiful': 48, 'artist': 49, 'its': 50, 'paintings': 51, 'endless': 52, 'always': 53, 'breathtaking': 54, 'true': 55, 'happiness': 56, 'not': 57, 'having': 58, 'everything': 59, 'being': 60, 'content': 61, 'what': 62, 'have': 63, 'comes': 64, 'age': 65, 'experience': 66, 'music': 67, 'has': 68, 'power': 69, 'transport': 70, 'us': 71, 'place': 72, 'blind': 73, 'sees': 74, 'than': 75, 'others': 76, 'heals': 77, 'all': 78, 'wounds': 79, 'only': 80, 'let': 81, 'it': 82, 'home': 83, 'heart': 84, 'for': 85, 'many': 86, 'that': 87}
索引到单词的映射,index_word:
{1: 'is', 2: 'you', 3: 'the', 4: 'but', 5: 'and', 6: 'with', 7: 'are', 8: 'a', 9: 'if', 10: 'love', 11: 'to', 12: 'journey', 13: 'in', 14: 'will', 15: 'them', 16: 'they', 17: 'memories', 18: 'wisdom', 19: 'about', 20: 'more', 21: 'often', 22: 'different', 23: 'time', 24: 'where', 25: 'life', 26: 'fall', 27: 'be', 28: 'forever', 29: 'dreams', 30: 'like', 31: 'stars', 32: 'may', 33: 'never', 34: 'touch', 35: 'follow', 36: 'lead', 37: 'your', 38: 'destiny', 39: "heart's", 40: 'treasures', 41: 'hold', 42: 'beauty', 43: 'of', 44: 'our', 45: 'past', 46: 'nature', 47: 'most', 48: 'beautiful', 49: 'artist', 50: 'its', 51: 'paintings', 52: 'endless', 53: 'always', 54: 'breathtaking', 55: 'true', 56: 'happiness', 57: 'not', 58: 'having', 59: 'everything', 60: 'being', 61: 'content', 62: 'what', 63: 'have', 64: 'comes', 65: 'age', 66: 'experience', 67: 'music', 68: 'has', 69: 'power', 70: 'transport', 71: 'us', 72: 'place', 73: 'blind', 74: 'sees', 75: 'than', 76: 'others', 77: 'heals', 78: 'all', 79: 'wounds', 80: 'only', 81: 'let', 82: 'it', 83: 'home', 84: 'heart', 85: 'for', 86: 'many', 87: 'that'}
每个单词出现的总频次,word_counts:
OrderedDict([('life', 1), ('is', 7), ('a', 3), ('journey', 2), ('and', 4), ('if', 3), ('you', 7), ('fall', 1), ('in', 2), ('love', 3), ('with', 4), ('the', 7), ('will', 2), ('be', 1), ('forever', 1), ('dreams', 1), ('are', 4), ('like', 1), ('stars', 1), ('may', 1), ('never', 1), ('touch', 1), ('them', 2), ('but', 5), ('follow', 1), ('they', 2), ('lead', 1), ('to', 3), ('your', 1), ('destiny', 1), ('memories', 2), ("heart's", 1), ('treasures', 1), ('hold', 1), ('wisdom', 2), ('beauty', 1), ('of', 1), ('our', 1), ('past', 1), ('nature', 1), ('most', 1), ('beautiful', 1), ('artist', 1), ('its', 1), ('paintings', 1), ('endless', 1), ('always', 1), ('breathtaking', 1), ('true', 1), ('happiness', 1), ('not', 1), ('about', 2), ('having', 1), ('everything', 1), ('being', 1), ('content', 1), ('what', 1), ('have', 1), ('comes', 1), ('age', 1), ('more', 2), ('often', 2), ('experience', 1), ('music', 1), ('has', 1), ('power', 1), ('transport', 1), ('us', 1), ('different', 2), ('place', 1), ('time', 2), ('blind', 1), ('sees', 1), ('than', 1), ('others', 1), ('heals', 1), ('all', 1), ('wounds', 1), ('only', 1), ('let', 1), ('it', 1), ('home', 1), ('where', 2), ('heart', 1), ('for', 1), ('many', 1), ('that', 1)])
出现单词的文档的数量,word_docs:
defaultdict(<class 'int'>, {'a': 2, 'journey': 1, 'is': 5, 'if': 3, 'will': 2, 'and': 4, 'forever': 1, 'life': 1, 'love': 2, 'in': 1, 'fall': 1, 'be': 1, 'you': 4, 'the': 5, 'with': 3, 'dreams': 1, 'touch': 1, 'lead': 1, 'stars': 1, 'but': 5, 'your': 1, 'may': 1, 'to': 2, 'never': 1, 'like': 1, 'follow': 1, 'destiny': 1, 'are': 4, 'they': 2, 'them': 1, 'memories': 2, 'treasures': 1, 'of': 1, 'past': 1, 'wisdom': 2, 'hold': 1, 'beauty': 1, 'our': 1, "heart's": 1, 'paintings': 1, 'most': 1, 'breathtaking': 1, 'beautiful': 1, 'nature': 1, 'always': 1, 'endless': 1, 'artist': 1, 'its': 1, 'having': 1, 'not': 1, 'content': 1, 'everything': 1, 'about': 1, 'happiness': 1, 'have': 1, 'being': 1, 'what': 1, 'true': 1, 'comes': 1, 'age': 1, 'more': 2, 'often': 2, 'experience': 1, 'power': 1, 'place': 1, 'us': 1, 'has': 1, 'transport': 1, 'time': 2, 'music': 1, 'different': 1, 'blind': 1, 'others': 1, 'sees': 1, 'than': 1, 'it': 1, 'all': 1, 'only': 1, 'heals': 1, 'let': 1, 'wounds': 1, 'where': 1, 'heart': 1, 'for': 1, 'many': 1, 'that': 1, 'home': 1})
单词索引对应的出现单词的文档的数量,index_docs:
defaultdict(<class 'int'>, {8: 2, 12: 1, 1: 5, 9: 3, 14: 2, 5: 4, 28: 1, 25: 1, 10: 2, 13: 1, 26: 1, 27: 1, 2: 4, 3: 5, 6: 3, 29: 1, 34: 1, 36: 1, 31: 1, 4: 5, 37: 1, 32: 1, 11: 2, 33: 1, 30: 1, 35: 1, 38: 1, 7: 4, 16: 2, 15: 1, 17: 2, 40: 1, 43: 1, 45: 1, 18: 2, 41: 1, 42: 1, 44: 1, 39: 1, 51: 1, 47: 1, 54: 1, 48: 1, 46: 1, 53: 1, 52: 1, 49: 1, 50: 1, 58: 1, 57: 1, 61: 1, 59: 1, 19: 1, 56: 1, 63: 1, 60: 1, 62: 1, 55: 1, 64: 1, 65: 1, 20: 2, 21: 2, 66: 1, 69: 1, 72: 1, 71: 1, 68: 1, 70: 1, 23: 2, 67: 1, 22: 1, 73: 1, 76: 1, 74: 1, 75: 1, 82: 1, 78: 1, 80: 1, 77: 1, 81: 1, 79: 1, 24: 1, 84: 1, 85: 1, 86: 1, 87: 1, 83: 1})
5.2 对中文文本向量化
# -*- coding:utf-8 -*-
import jieba
from keras._tf_keras.keras.preprocessing.text import Tokenizer
from keras.preprocessing import sequence
def cut_text(text):
seg_list = jieba.cut(text)
return ' '.join(seg_list)
texts = ["生活就像一场旅行,如果你爱上了这场旅行,你将永远充满爱。",
"梦想就像天上的星星,你可能永远无法触及,但如果你追随它们,它们将引领你走向你的命运。",
"真正的幸福不在于拥有一切,而在于满足于你所拥有的。",
"记忆是心灵的宝藏,它们蕴含着我们过去的智慧和美丽。",
"大自然是最美丽的艺术家,它的画作无边无际,总是令人叹为观止。",
"智慧往往随着年龄的增长而增加,但更多时候是随着经验的积累而到来。",
"音乐有能力将我们带到一个不同的地方、一个不同的时间。",
"爱是盲目的,但往往比别人看得更清楚。",
"时间可以治愈一切伤痛,但前提是你必须让它过去。",
"家是心灵的归宿,对许多人来说,也是记忆的所在。"]
tokenizer = Tokenizer(num_words=64, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n,。', )
tokenizer.fit_on_texts([cut_text(text) for text in texts])
print("处理的文档数量,document_count: ", tokenizer.document_count)
print("词语到索引的映射,word_index: \n", tokenizer.word_index)
print("索引到词语的映射,index_word: \n", tokenizer.index_word)
print("每个词语出现的总频次,word_counts: \n", tokenizer.word_counts)
print("出现词语的文档的数量,word_docs: \n", tokenizer.word_docs)
print("词语索引对应的出现词语的文档的数量,index_docs: \n", tokenizer.index_docs)
splits = [cut_text(text) for text in texts]
tokens = tokenizer.texts_to_sequences(splits)
tokens_pad = sequence.pad_sequences(tokens, maxlen=32, padding='post', truncating='pre')
print("splits:\n", splits)
print("tokens:\n", tokens)
print("tokens_pad:\n", tokens_pad)
显示结果如下:
处理的文档数量,document_count: 10
词语到索引的映射,word_index:
{'的': 1, '你': 2, '是': 3, '但': 4, '将': 5, '它们': 6, '而': 7, '就': 8, '像': 9, '旅行': 10, '如果': 11, '爱': 12, '永远': 13, '在于': 14, '拥有': 15, '一切': 16, '记忆': 17, '心灵': 18, '我们': 19, '过去': 20, '智慧': 21, '美丽': 22, '它': 23, '往往': 24, '随着': 25, '更': 26, '一个': 27, '不同': 28, '时间': 29, '生活': 30, '一场': 31, '上': 32, '了': 33, '这场': 34, '充满': 35, '梦想': 36, '天上': 37, '星星': 38, '可能': 39, '无法': 40, '触及': 41, '追随': 42, '引领': 43, '走向': 44, '命运': 45, '真正': 46, '幸福': 47, '不': 48, '满足': 49, '于': 50, '所': 51, '宝藏': 52, '蕴含着': 53, '和': 54, '大自然': 55, '最': 56, '艺术家': 57, '画作': 58, '无边无际': 59, '总是': 60, '令人': 61, '叹为观止': 62, '年龄': 63, '增长': 64, '增加': 65, '多': 66, '时候': 67, '经验': 68, '积累': 69, '到来': 70, '音乐': 71, '有': 72, '能力': 73, '带到': 74, '地方': 75, '、': 76, '爱是': 77, '盲目': 78, '比': 79, '别人': 80, '看得': 81, '清楚': 82, '可以': 83, '治愈': 84, '伤痛': 85, '前提': 86, '必须': 87, '让': 88, '家': 89, '归宿': 90, '对': 91, '许多': 92, '人': 93, '来说': 94, '也': 95, '所在': 96}
索引到词语的映射,index_word:
{1: '的', 2: '你', 3: '是', 4: '但', 5: '将', 6: '它们', 7: '而', 8: '就', 9: '像', 10: '旅行', 11: '如果', 12: '爱', 13: '永远', 14: '在于', 15: '拥有', 16: '一切', 17: '记忆', 18: '心灵', 19: '我们', 20: '过去', 21: '智慧', 22: '美丽', 23: '它', 24: '往往', 25: '随着', 26: '更', 27: '一个', 28: '不同', 29: '时间', 30: '生活', 31: '一场', 32: '上', 33: '了', 34: '这场', 35: '充满', 36: '梦想', 37: '天上', 38: '星星', 39: '可能', 40: '无法', 41: '触及', 42: '追随', 43: '引领', 44: '走向', 45: '命运', 46: '真正', 47: '幸福', 48: '不', 49: '满足', 50: '于', 51: '所', 52: '宝藏', 53: '蕴含着', 54: '和', 55: '大自然', 56: '最', 57: '艺术家', 58: '画作', 59: '无边无际', 60: '总是', 61: '令人', 62: '叹为观止', 63: '年龄', 64: '增长', 65: '增加', 66: '多', 67: '时候', 68: '经验', 69: '积累', 70: '到来', 71: '音乐', 72: '有', 73: '能力', 74: '带到', 75: '地方', 76: '、', 77: '爱是', 78: '盲目', 79: '比', 80: '别人', 81: '看得', 82: '清楚', 83: '可以', 84: '治愈', 85: '伤痛', 86: '前提', 87: '必须', 88: '让', 89: '家', 90: '归宿', 91: '对', 92: '许多', 93: '人', 94: '来说', 95: '也', 96: '所在'}
每个词语出现的总频次,word_counts:
OrderedDict([('生活', 1), ('就', 2), ('像', 2), ('一场', 1), ('旅行', 2), ('如果', 2), ('你', 8), ('爱', 2), ('上', 1), ('了', 1), ('这场', 1), ('将', 3), ('永远', 2), ('充满', 1), ('梦想', 1), ('天上', 1), ('的', 15), ('星星', 1), ('可能', 1), ('无法', 1), ('触及', 1), ('但', 4), ('追随', 1), ('它们', 3), ('引领', 1), ('走向', 1), ('命运', 1), ('真正', 1), ('幸福', 1), ('不', 1), ('在于', 2), ('拥有', 2), ('一切', 2), ('而', 3), ('满足', 1), ('于', 1), ('所', 1), ('记忆', 2), ('是', 6), ('心灵', 2), ('宝藏', 1), ('蕴含着', 1), ('我们', 2), ('过去', 2), ('智慧', 2), ('和', 1), ('美丽', 2), ('大自然', 1), ('最', 1), ('艺术家', 1), ('它', 2), ('画作', 1), ('无边无际', 1), ('总是', 1), ('令人', 1), ('叹为观止', 1), ('往往', 2), ('随着', 2), ('年龄', 1), ('增长', 1), ('增加', 1), ('更', 2), ('多', 1), ('时候', 1), ('经验', 1), ('积累', 1), ('到来', 1), ('音乐', 1), ('有', 1), ('能力', 1), ('带到', 1), ('一个', 2), ('不同', 2), ('地方', 1), ('、', 1), ('时间', 2), ('爱是', 1), ('盲目', 1), ('比', 1), ('别人', 1), ('看得', 1), ('清楚', 1), ('可以', 1), ('治愈', 1), ('伤痛', 1), ('前提', 1), ('必须', 1), ('让', 1), ('家', 1), ('归宿', 1), ('对', 1), ('许多', 1), ('人', 1), ('来说', 1), ('也', 1), ('所在', 1)])
出现词语的文档的数量,word_docs:
defaultdict(<class 'int'>, {'这场': 1, '旅行': 1, '一场': 1, '将': 3, '爱': 1, '充满': 1, '了': 1, '像': 2, '如果': 2, '生活': 1, '永远': 2, '上': 1, '你': 4, '就': 2, '梦想': 1, '但': 4, '天上': 1, '它们': 2, '追随': 1, '的': 8, '可能': 1, '无法': 1, '引领': 1, '走向': 1, '星星': 1, '命运': 1, '触及': 1, '一切': 2, '而': 2, '真正': 1, '拥有': 1, '在于': 1, '幸福': 1, '于': 1, '不': 1, '满足': 1, '所': 1, '记忆': 2, '和': 1, '是': 5, '智慧': 2, '我们': 2, '美丽': 2, '蕴含着': 1, '心灵': 2, '过去': 2, '宝藏': 1, '它': 2, '无边无际': 1, '叹为观止': 1, '令人': 1, '最': 1, '总是': 1, '大自然': 1, '艺术家': 1, '画作': 1, '经验': 1, '往往': 2, '随着': 1, '时候': 1, '更': 2, '增加': 1, '年龄': 1, '多': 1, '积累': 1, '增长': 1, '到来': 1, '、': 1, '带到': 1, '一个': 1, '地方': 1, '音乐': 1, '有': 1, '不同': 1, '能力': 1, '时间': 2, '看得': 1, '比': 1, '盲目': 1, '别人': 1, '清楚': 1, '爱是': 1, '可以': 1, '前提': 1, '治愈': 1, '伤痛': 1, '必须': 1, '让': 1, '对': 1, '也': 1, '许多': 1, '归宿': 1, '来说': 1, '所在': 1, '家': 1, '人': 1})
词语索引对应的出现词语的文档的数量,index_docs:
defaultdict(<class 'int'>, {34: 1, 10: 1, 31: 1, 5: 3, 12: 1, 35: 1, 33: 1, 9: 2, 11: 2, 30: 1, 13: 2, 32: 1, 2: 4, 8: 2, 36: 1, 4: 4, 37: 1, 6: 2, 42: 1, 1: 8, 39: 1, 40: 1, 43: 1, 44: 1, 38: 1, 45: 1, 41: 1, 16: 2, 7: 2, 46: 1, 15: 1, 14: 1, 47: 1, 50: 1, 48: 1, 49: 1, 51: 1, 17: 2, 54: 1, 3: 5, 21: 2, 19: 2, 22: 2, 53: 1, 18: 2, 20: 2, 52: 1, 23: 2, 59: 1, 62: 1, 61: 1, 56: 1, 60: 1, 55: 1, 57: 1, 58: 1, 68: 1, 24: 2, 25: 1, 67: 1, 26: 2, 65: 1, 63: 1, 66: 1, 69: 1, 64: 1, 70: 1, 76: 1, 74: 1, 27: 1, 75: 1, 71: 1, 72: 1, 28: 1, 73: 1, 29: 2, 81: 1, 79: 1, 78: 1, 80: 1, 82: 1, 77: 1, 83: 1, 86: 1, 84: 1, 85: 1, 87: 1, 88: 1, 91: 1, 95: 1, 92: 1, 90: 1, 94: 1, 96: 1, 89: 1, 93: 1})
splits:
['生活 就 像 一场 旅行 , 如果 你 爱 上 了 这场 旅行 , 你 将 永远 充满 爱 。', '梦想 就 像 天上 的 星星 , 你 可能 永远 无法 触及 , 但 如果 你 追随 它们 , 它们 将 引领 你 走向 你 的 命运 。', '真正 的 幸福 不 在于 拥有 一切 , 而 在于 满足 于 你 所 拥有 的 。', '记忆 是 心灵 的 宝藏 , 它们 蕴含着 我们 过去 的 智慧 和 美丽 。', '大自然 是 最 美丽 的 艺术家 , 它 的 画作 无边无际 , 总是 令人 叹为观止 。', '智慧 往往 随着 年龄 的 增长 而 增加 , 但 更 多 时候 是 随着 经验 的 积累 而 到来 。', '音乐 有 能力 将 我们 带到 一个 不同 的 地方 、 一个 不同 的 时间 。', '爱是 盲目 的 , 但 往往 比 别人 看得 更 清楚 。', '时间 可以 治愈 一切 伤痛 , 但 前提 是 你 必须 让 它 过去 。', '家 是 心灵 的 归宿 , 对 许多 人 来说 , 也 是 记忆 的 所在 。']
tokens:
[[30, 8, 9, 31, 10, 11, 2, 12, 32, 33, 34, 10, 2, 5, 13, 35, 12], [36, 8, 9, 37, 1, 38, 2, 39, 13, 40, 41, 4, 11, 2, 42, 6, 6, 5, 43, 2, 44, 2, 1, 45], [46, 1, 47, 48, 14, 15, 16, 7, 14, 49, 50, 2, 51, 15, 1], [17, 3, 18, 1, 52, 6, 53, 19, 20, 1, 21, 54, 22], [55, 3, 56, 22, 1, 57, 23, 1, 58, 59, 60, 61, 62], [21, 24, 25, 63, 1, 7, 4, 26, 3, 25, 1, 7], [5, 19, 27, 28, 1, 27, 28, 1, 29], [1, 4, 24, 26], [29, 16, 4, 3, 2, 23, 20], [3, 18, 1, 3, 17, 1]]
tokens_pad:
[[30 8 9 31 10 11 2 12 32 33 34 10 2 5 13 35 12 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]
[36 8 9 37 1 38 2 39 13 40 41 4 11 2 42 6 6 5 43 2 44 2 1 45
0 0 0 0 0 0 0 0]
[46 1 47 48 14 15 16 7 14 49 50 2 51 15 1 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]
[17 3 18 1 52 6 53 19 20 1 21 54 22 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]
[55 3 56 22 1 57 23 1 58 59 60 61 62 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]
[21 24 25 63 1 7 4 26 3 25 1 7 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]
[ 5 19 27 28 1 27 28 1 29 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]
[ 1 4 24 26 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]
[29 16 4 3 2 23 20 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]
[ 3 18 1 3 17 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0]]
参考
[1] https://huggingface.co/docs/transformers/main/en/tokenizer_summary














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









