







Elastic Stack(ELK)
ElasticSearch + Logstash + Kibana
一、分布式带来的变革
1. 多个节点
分布式系统的特点:SOA,微服务架构,大规模集群网络
试想一下:
假设集群网络只有 100 台服务器。采用人肉运维的方式,处理服务器各种异常。
运维人员:每一台服务器打一个记号,Excel 记录下每一台机器运行特点,如果某一台服务器出现问题,运维人员直接定位机器,查询日志,修复问题。
如果是10000 台 服务器怎么办?那么如何收集海量服务器节点上的日志,进行分析,处理?
- 1、监控服务器状态
- 2、收集一些有用的数据,进行分析。
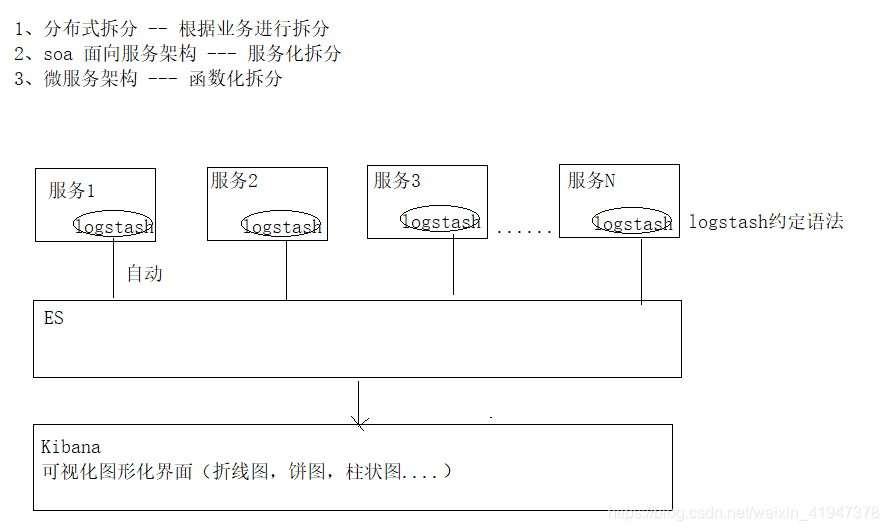
解决方案:
1、ELK (一周时间搞定的东西,ehcarts 图形化报表)
2、hadoop (一个月都搞不定)
E:elasticsearch 存储日志数据
L:logstash 收集日志
K:Kibana UI 视图,把收集的日志数据,进行图形化界面方式直接展示给用户
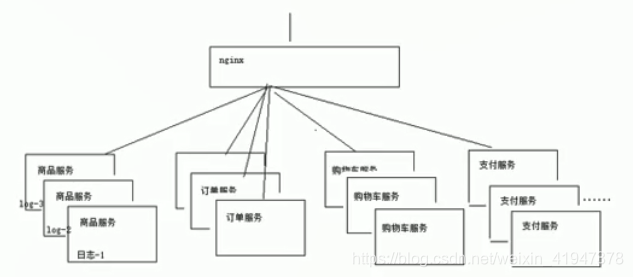
2. 日志分散
微服务,SOA(面向服务架构)—→ 分布式的架构 : 日志分散在每一个服务器
1000 台服务器:
A B …………………………………… 1000 台(请求恰好打到第 1000 台)
0 0 1
3. 运维成本高
通常,日志被分散在储存不同的设备上。如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志。这样是不是感觉很繁琐和效率低下。当务之急我们使用集中化的日志管理,例如:开源的 syslog,将所有服务器上的日志收集汇总。
集中化管理日志后,日志的统计和检索又成为一件比较麻烦的事情,一般我们使用 grep、awk 和 wc 等 Linux 命令能实现检索和统计,但是对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心。
Linux 命令方式:
tail -n 300 myes.log | grep 'node-1' ##搜索某个日志在哪里
tail -100f myes.log
二、Elastic Stack 认识
如果你没有听说过 Elastic Stack,那你一定听说过 ELK,实际上 ELK 是三款软件的简称,分别是 Elasticsearch、Logstash、Kibana 组成,在发展的过程中,又有新成员 Beats 的加入,所以就形成了 Elastic Stack。所以说,ELK 是旧的称呼,Elastic Stack 是新的名字。

全系的 Elastic Stack 技术栈包括:
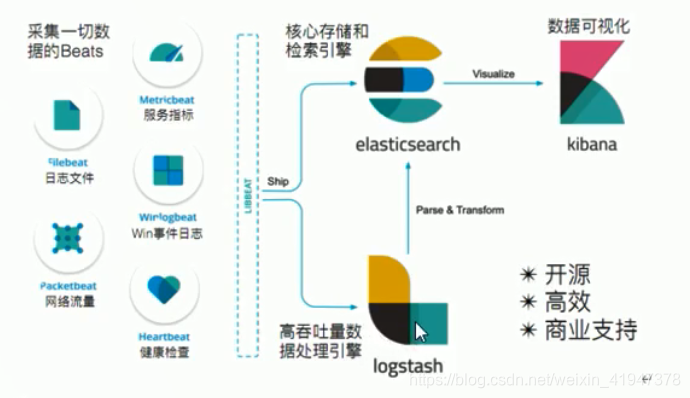
1)Elasticsearch
Elasticsearch 基于 java,是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful 风格接口,多数据源,自动搜索负载等。
2)Logstash
Logstash 基于 java,是一个开源的用于收集,分析和存储日志的工具。
3)Kibana
Kibana 基于 nodejs,也是一个开源和免费的工具,Kibana 可以为 Logstash 和 ElasticSearch提供的日志分析友好的 Web 界面,可以汇总、分析和搜索重要数据日志。
4)Beats
Beats 是 elastic 公司开源的一款采集系统监控数据的代理 agent,是在被监控服务器上以客户端形式运行的数据收集器的统称,可以直接把数据发送给 Elasticsearch 或者通过 Logstash发送给 Elasticsearch,然后进行后续的数据分析活动。
Beats 由如下组成:
- Packetbeat:是一个网络数据包分析器,用于监控、收集网络流量信息,Packetbeat 嗅探服务器之间的流量,解析应用层协议,并关联到消息的处理,其支 持 ICMP (v4 and v6)、DNS、HTTP、Mysql、PostgreSQL、Redis、MongoDB、Memcache 等协议;
- Filebeat:用于监控、收集服务器日志文件,其已取代 logstash forwarder;
- Metricbeat:可定期获取外部系统的监控指标信息,其可以监控、收集 Apache、HAProxy、MongoDB、MySQL、Nginx、PostgreSQL、Redis、System、Zookeeper 等服务;
- Winlogbeat:用于监控、收集 Windows 系统的日志信息;
三、Logstash
1. 基本语法
# 标准输入输出 -e 追加环境变量,设置启动参数
./logstash -e 'input{ stdin{} } output{ stdout{} }'
# 指定输出数据格式为 json 格式
./logstash -e 'input{ stdin{} } output{ stdout{ codec => json } }'
注意:输入输出基于事件机制,输入回车后触发标准输出事件,此时就会把输入的数据以某种格式进行输出。
效果:
官方文档:
https://www.elastic.co/guide/en/logstash/current/index.html
语法:




# 把数据输入到 es 当中
./logstash -e 'input{ stdin{} } output{ elasticsearch{ hosts => ["192.168.66.66:9200"]} stdout{ } }'
配置索引库名字:

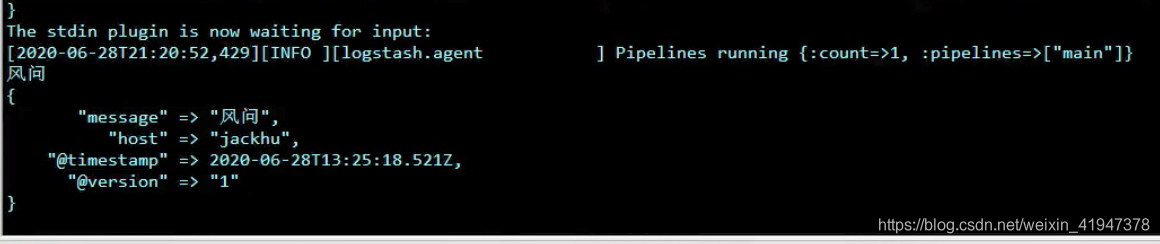
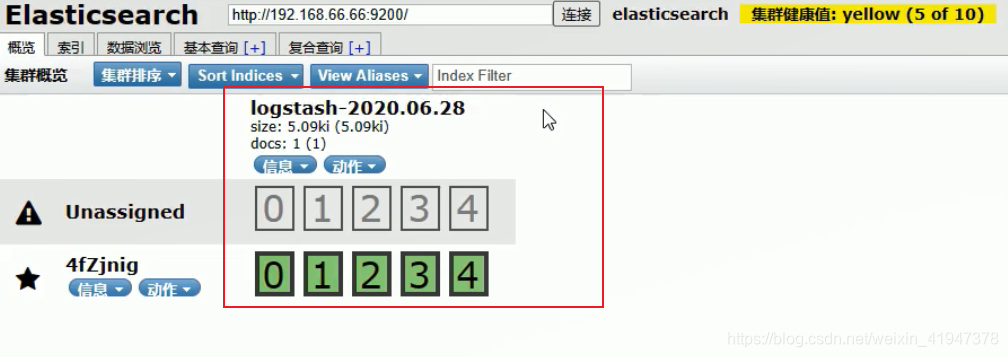
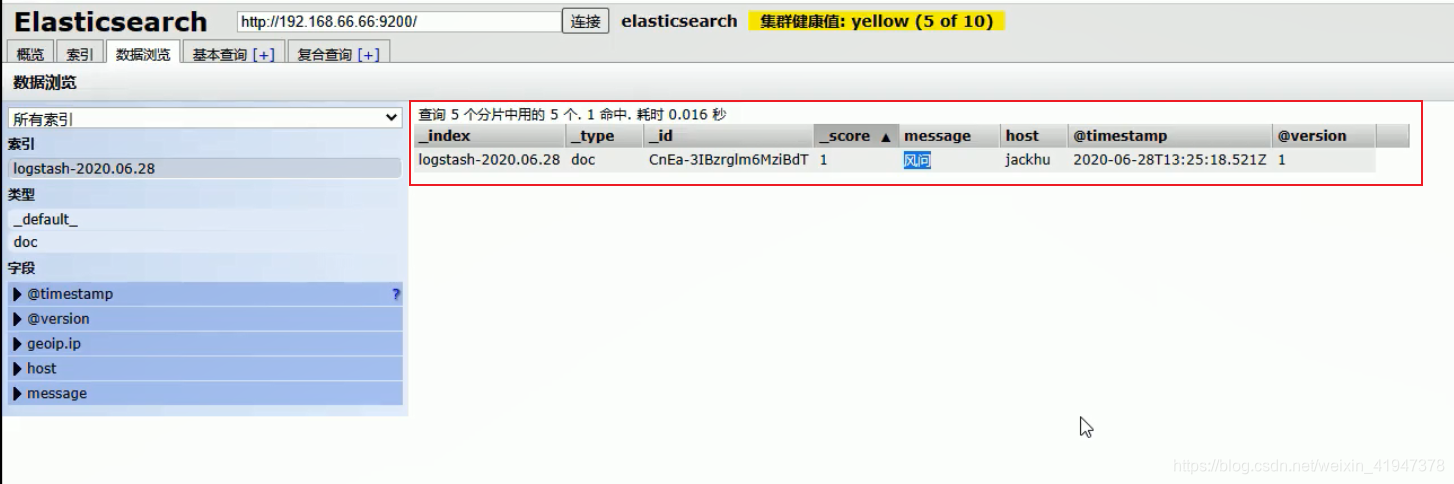
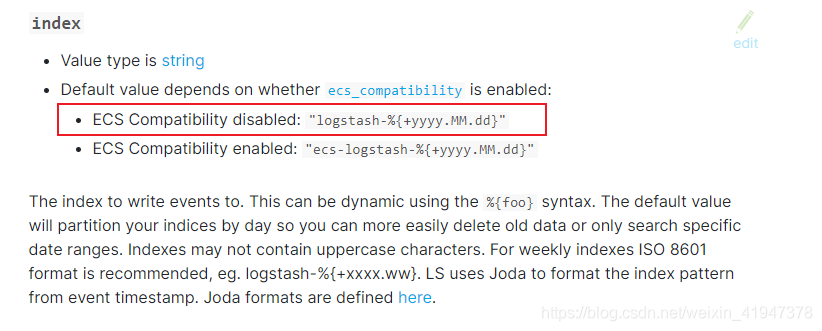
# 把数据输入到 es 中,同时指定索引库名称
./logstash -e 'input{ stdin{} } output{ elasticsearch{ hosts => ["192.168.66.66:9200"] index => "test001"} stdout{ } }'
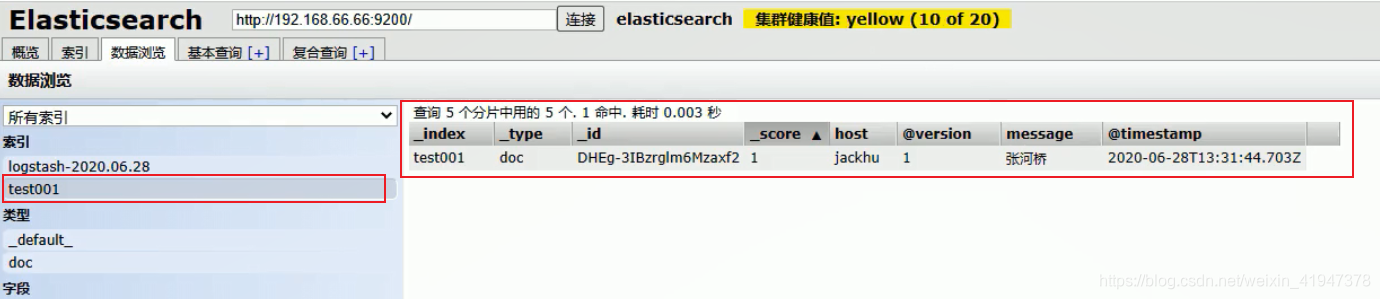
2. 配置文件方式启动
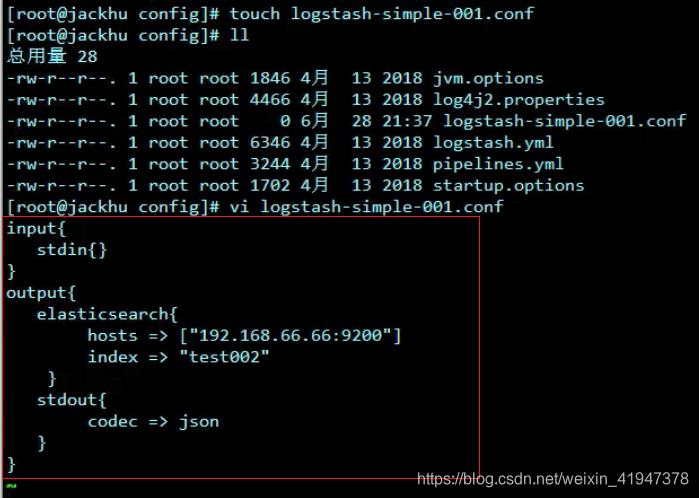
启动指令:./logstash -f xx.conf
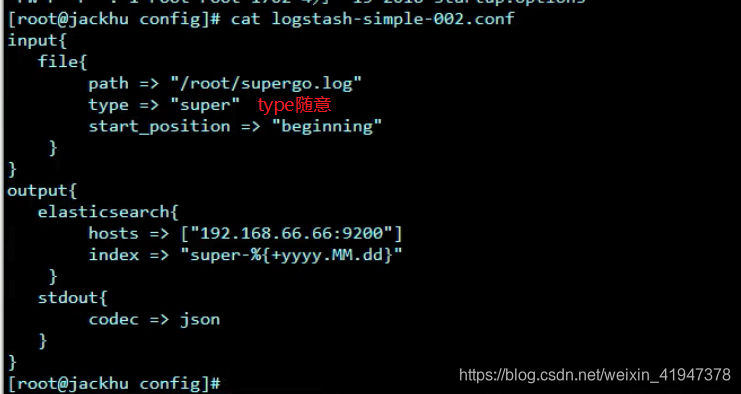
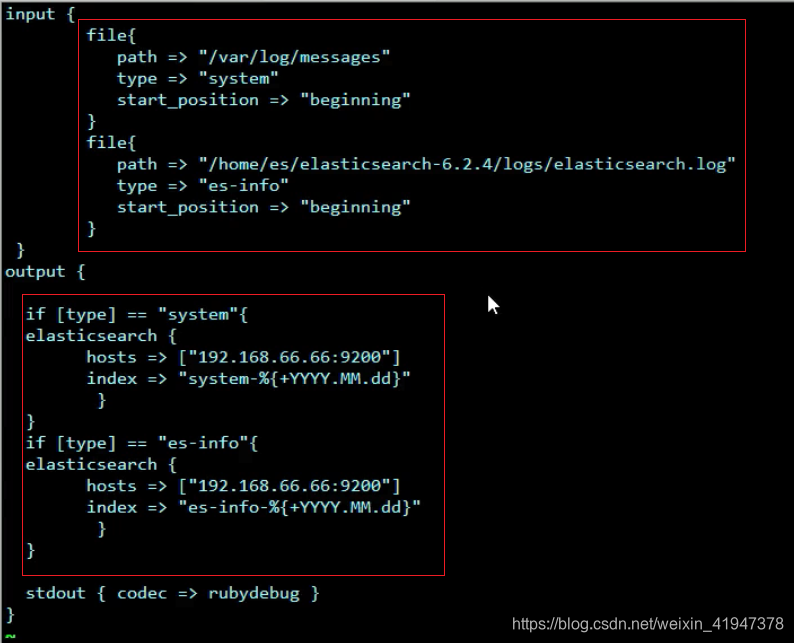
3. 读取文件日志
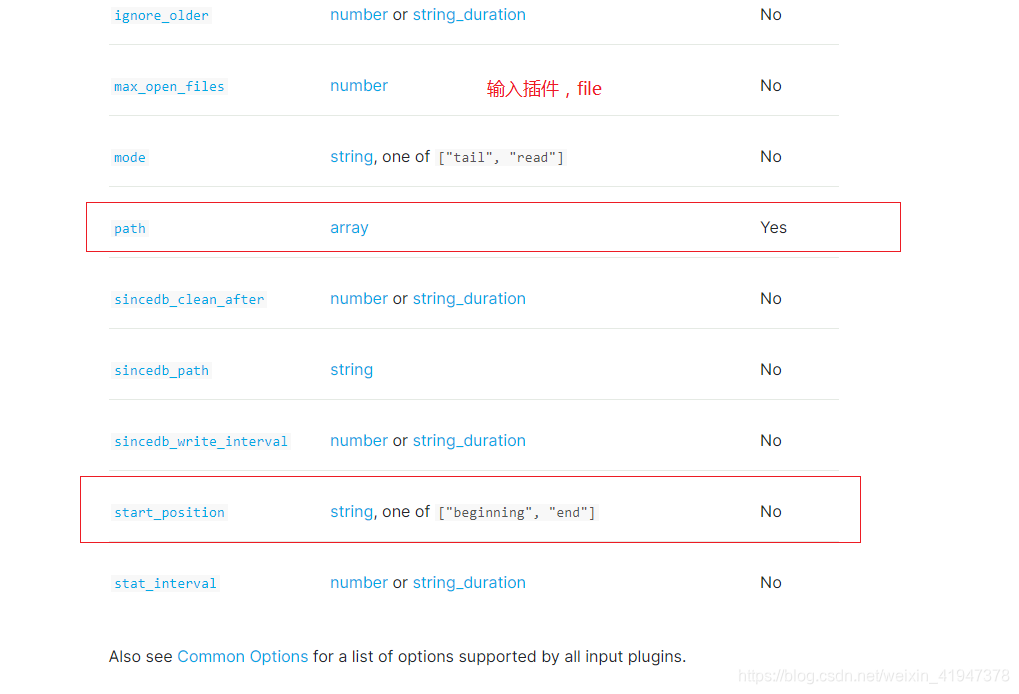
file插件属性:
path:指定日志文件的位置路径
start_position:表示日志读取位点,记录上次日志读取位置。读取日志有 2 种顺序,一个是从 beginning 开始读取。一个是从end 开始读取。
type:类型,相当于定义名称,随意
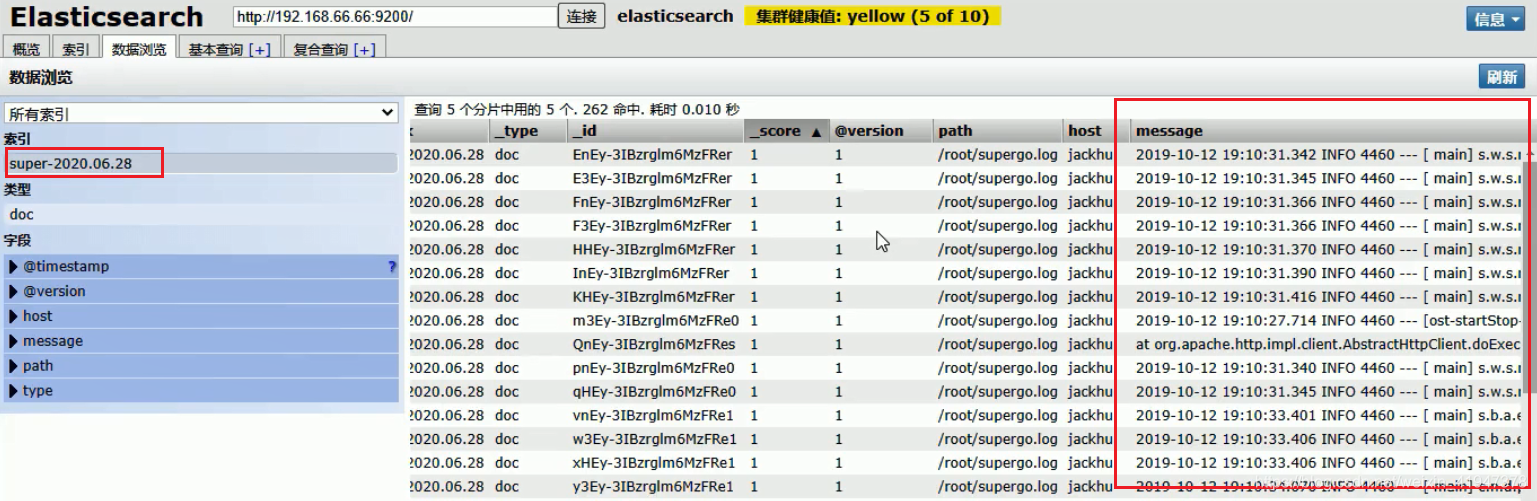
通过 file 插件从日志文件中读取数据,在把数据输入到 elasticsearch.
4. 条件输出到多个文件
有时,您只想在某些条件下过滤或输出事件。为此,您可以使用条件语句。
Logstash中的条件语句的外观和行为与它们在编程语言中的方式相同。条件语句支持if、else if和else语句,并且可以嵌套。
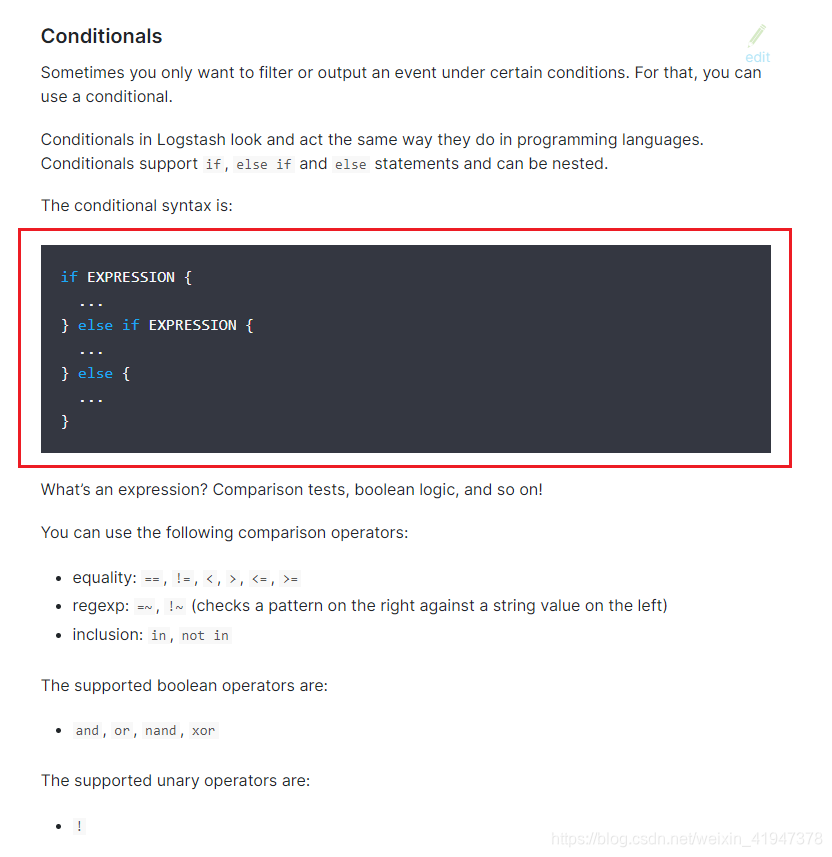
条件语法是:
表达式可以很长很复杂。表达式可以包含其他表达式,可以用!对表达式进行否定,还可以用括号对它们进行分组
例如,如果字段操作的值为login,下面的条件使用mutate过滤器来删除字段secret:
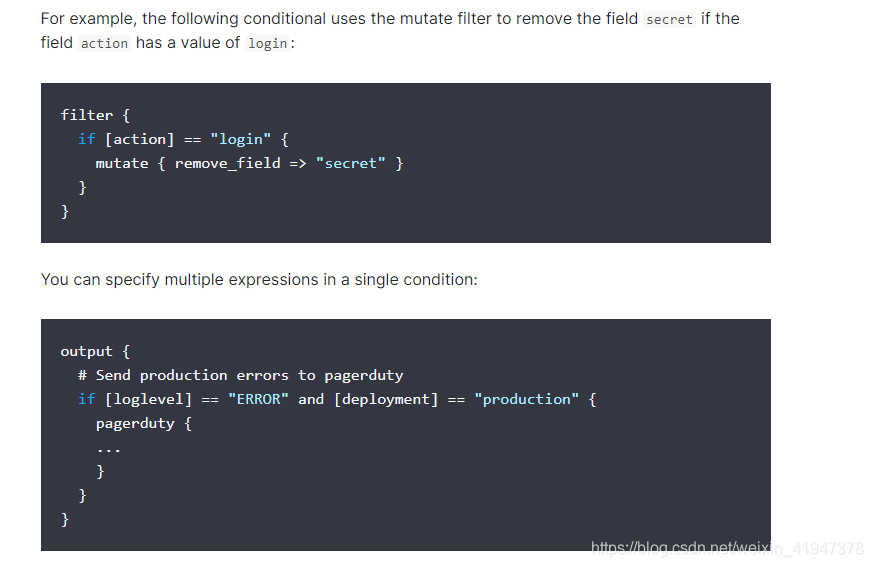
5. 项目日志
5.1 导入相关依赖
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>5.2</version>
</dependency>
5.2 配置文件
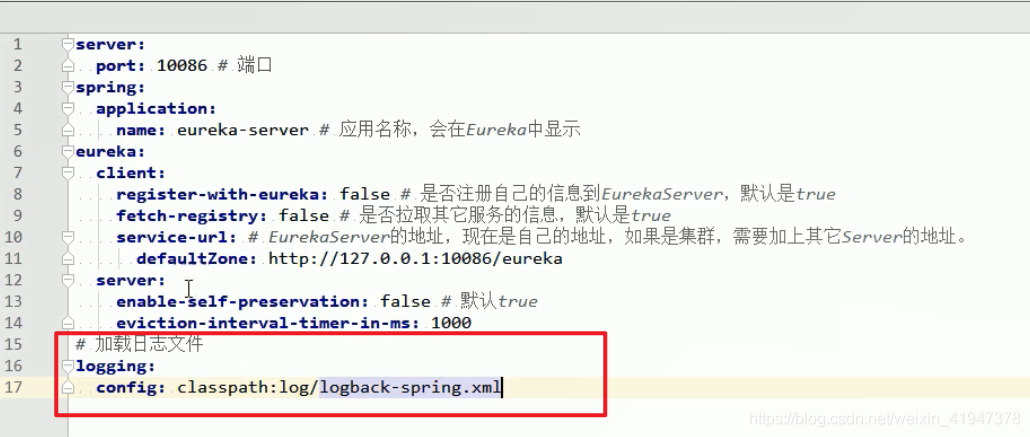
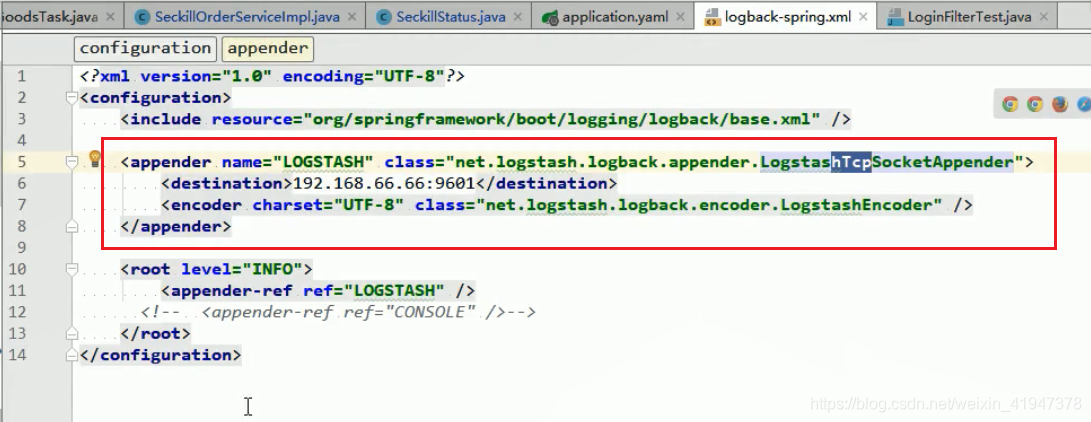
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<include resource="org/springframework/boot/logging/logback/base.xml"/>
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>192.168.66.66:9601</destination>
<encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder" />
</appender>
<root level="INFO">
<appender-ref ref="LOGSTASH" />
<!-- <appender-ref ref="CONSOLE" />-->
</root>
</configuration>
5.3 logstash 安装插件
./logstash-plugin install logstash-codec-json_lines
5.4 logstash 配置文件
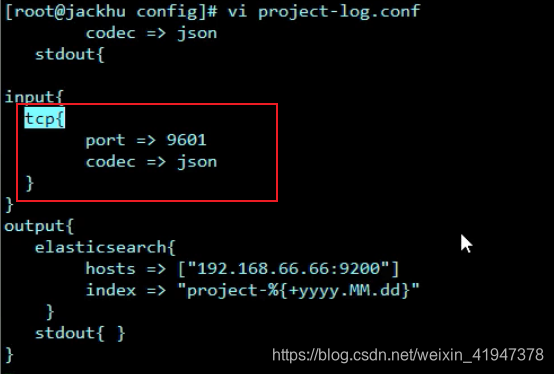
input {
tcp {
port => 9601
codec => json_lines
}
}
output {
elasticsearch {
hosts => ["192.168.66.66:9200"]
index => "kkb-log-%{+YYYY.MM.dd}"
}
stdout {codec => rubydebug }
}
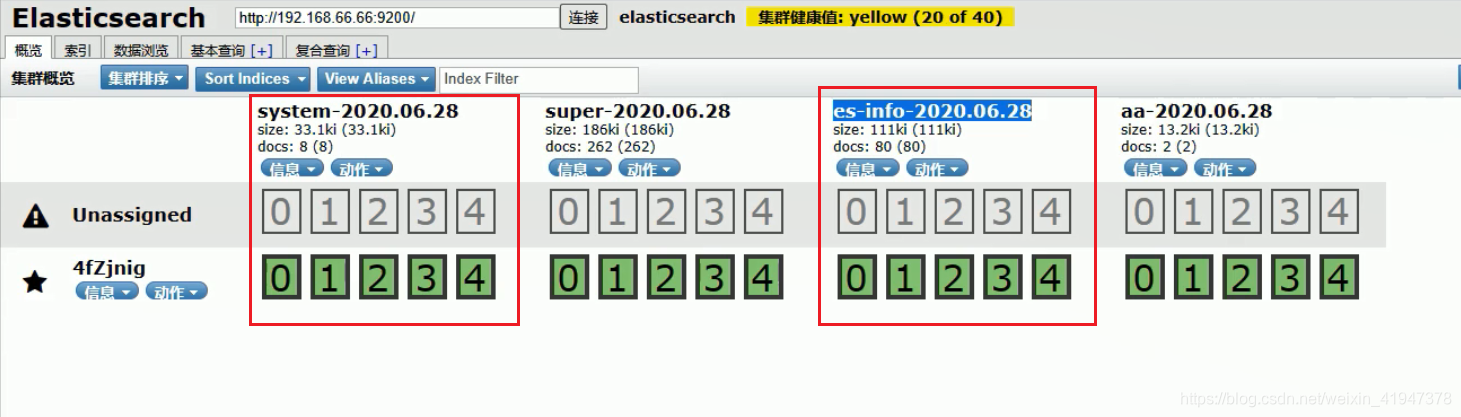
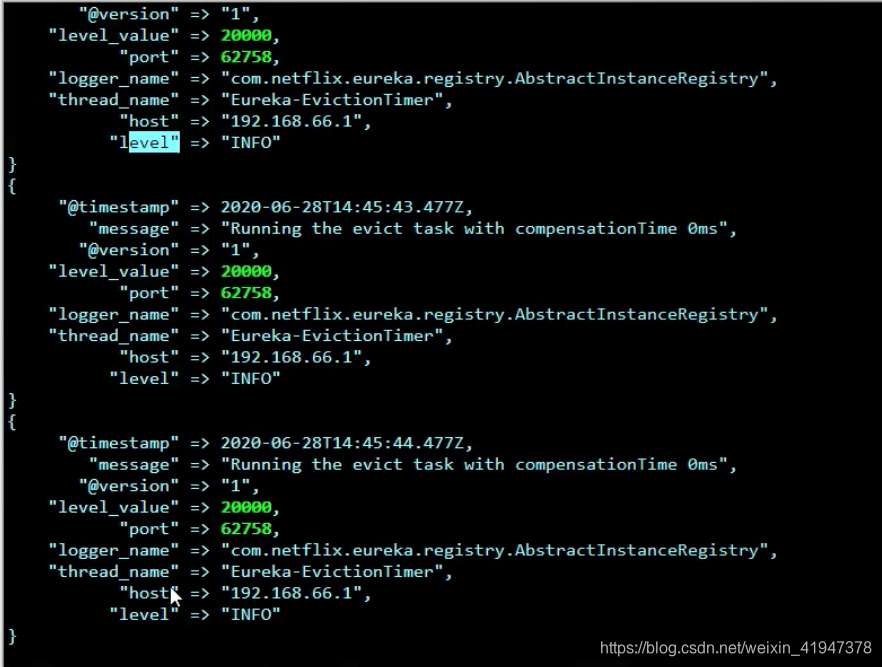
5.5 效果:
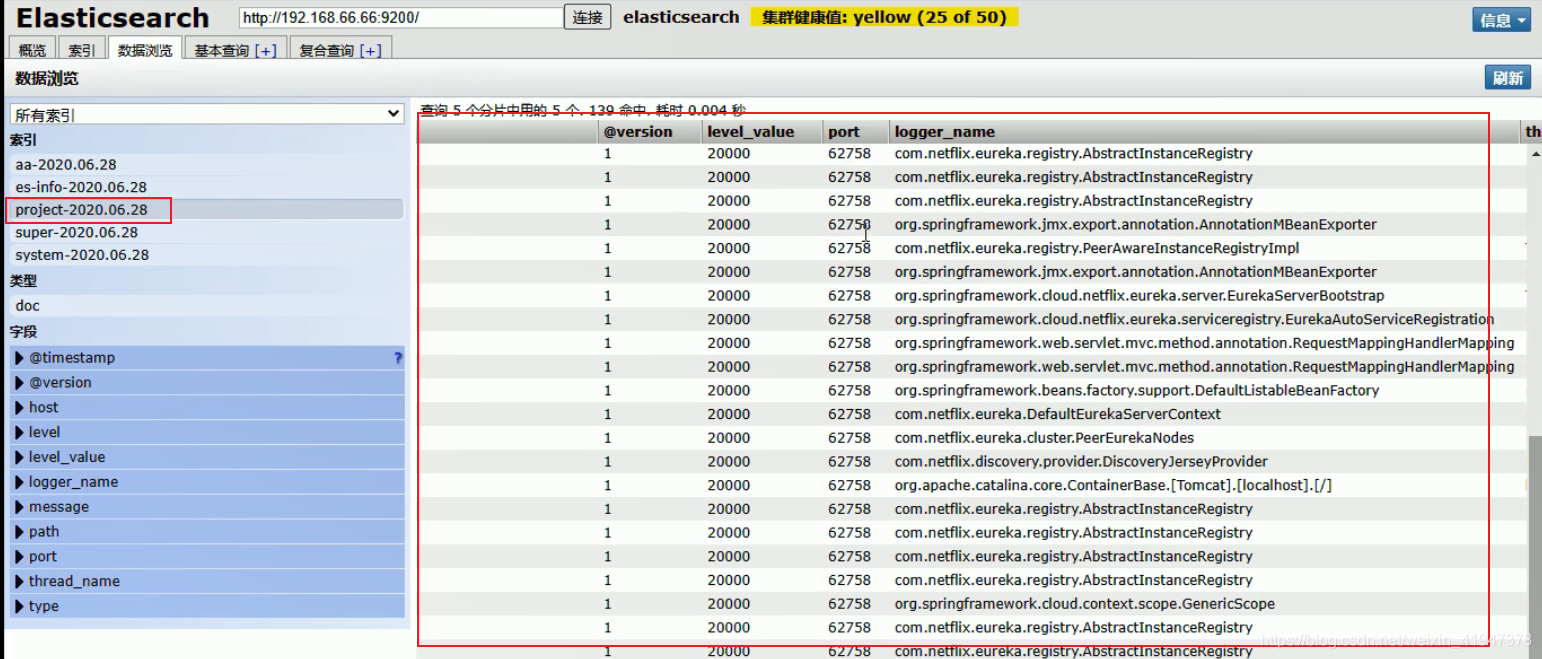
6. Nginx 日志
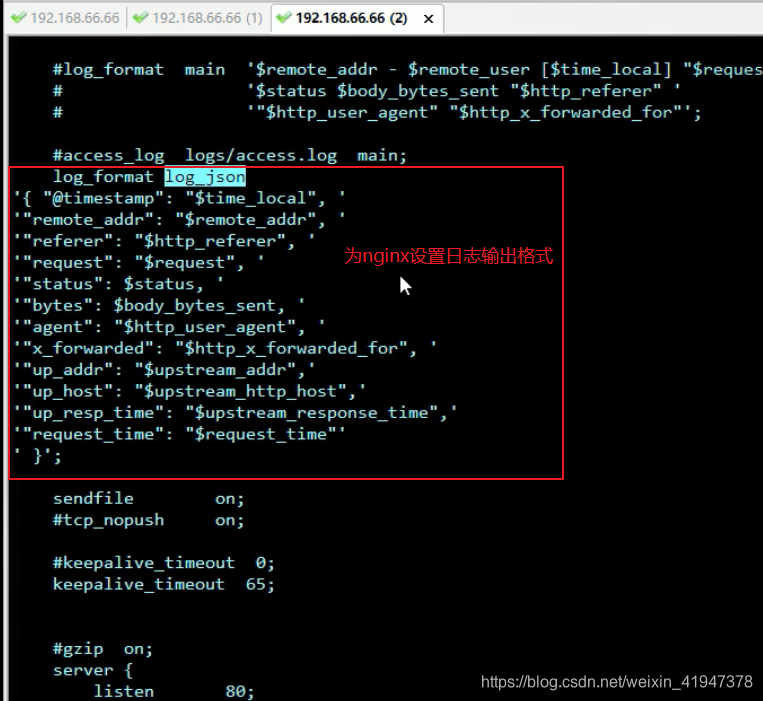
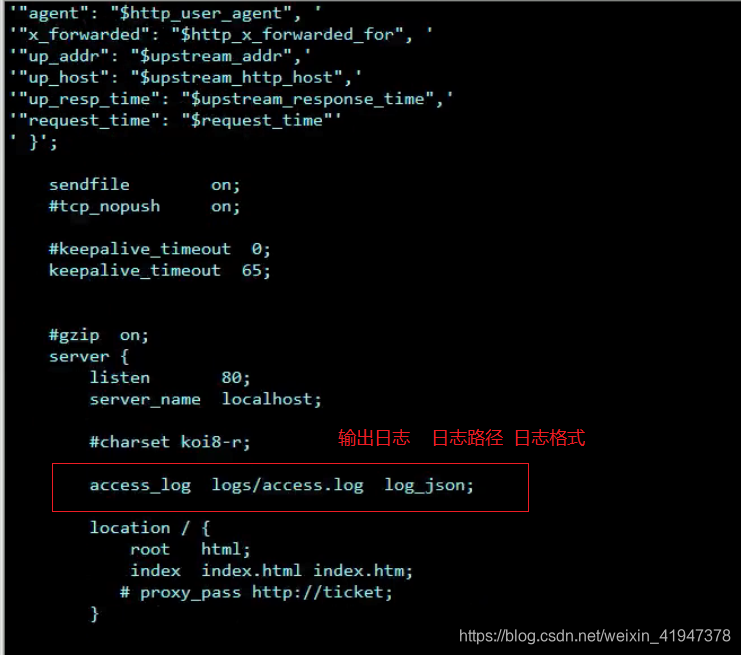
6.1 设置nginx日志输出格式
6.2 启动nginx
./nginx

启动后访问,查看日志:

6.3 设置logstash
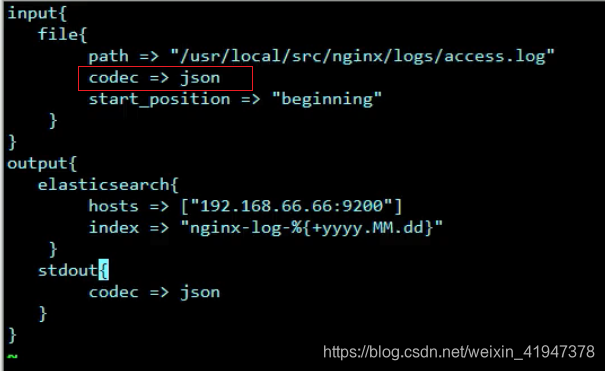
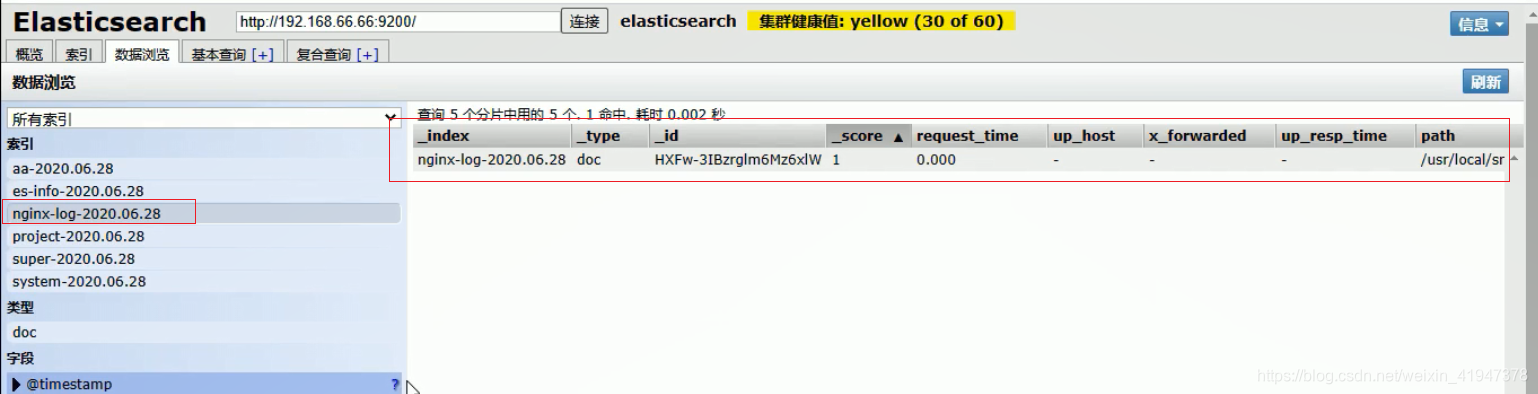
指定输入格式为json格式后,就会把json中的字段当成ES中索引库的字段
四、Kibana
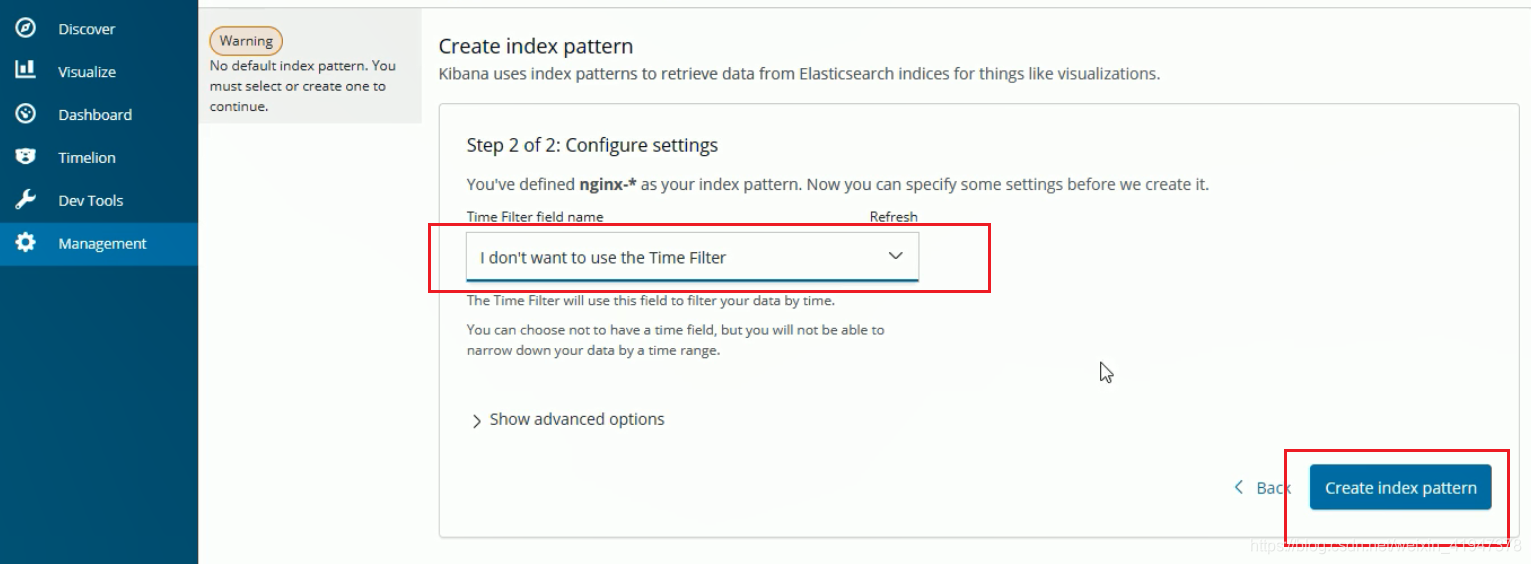
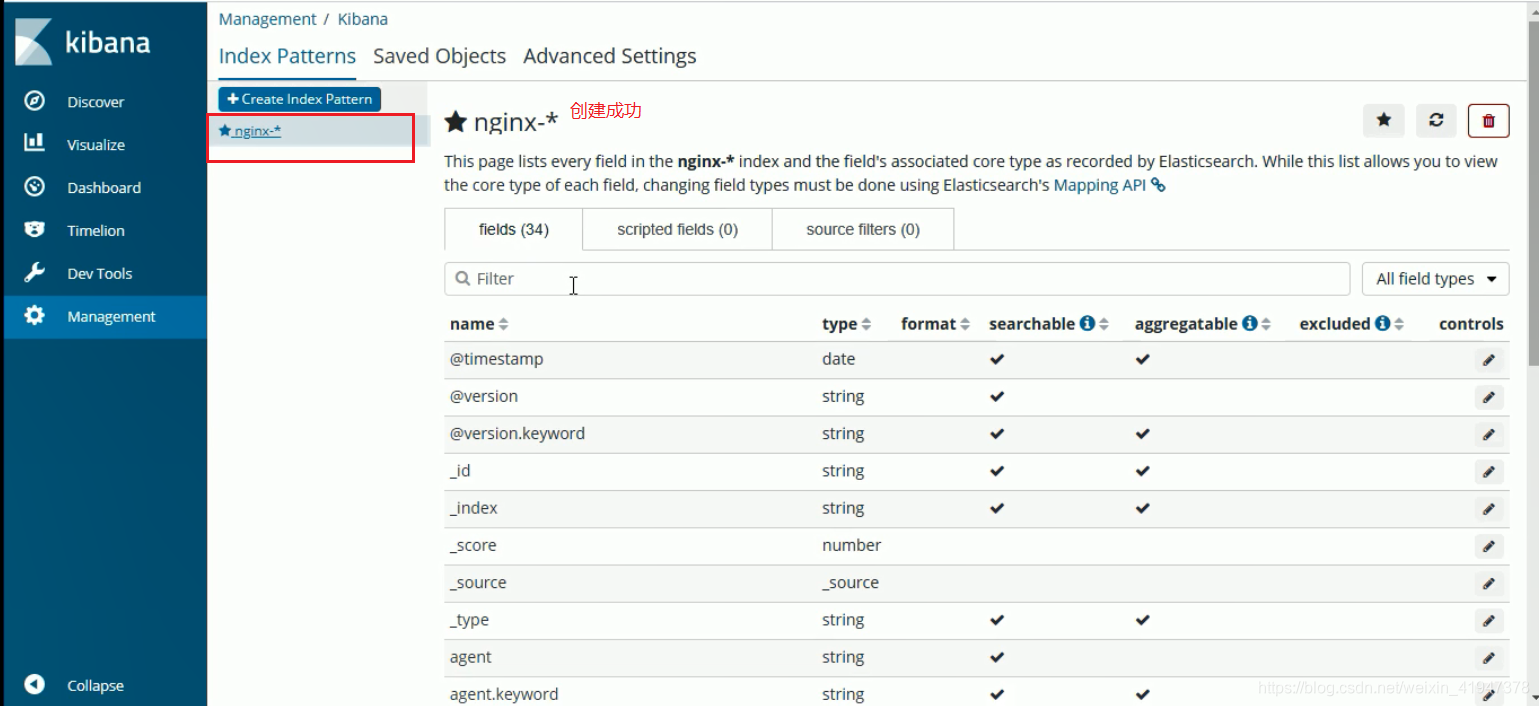
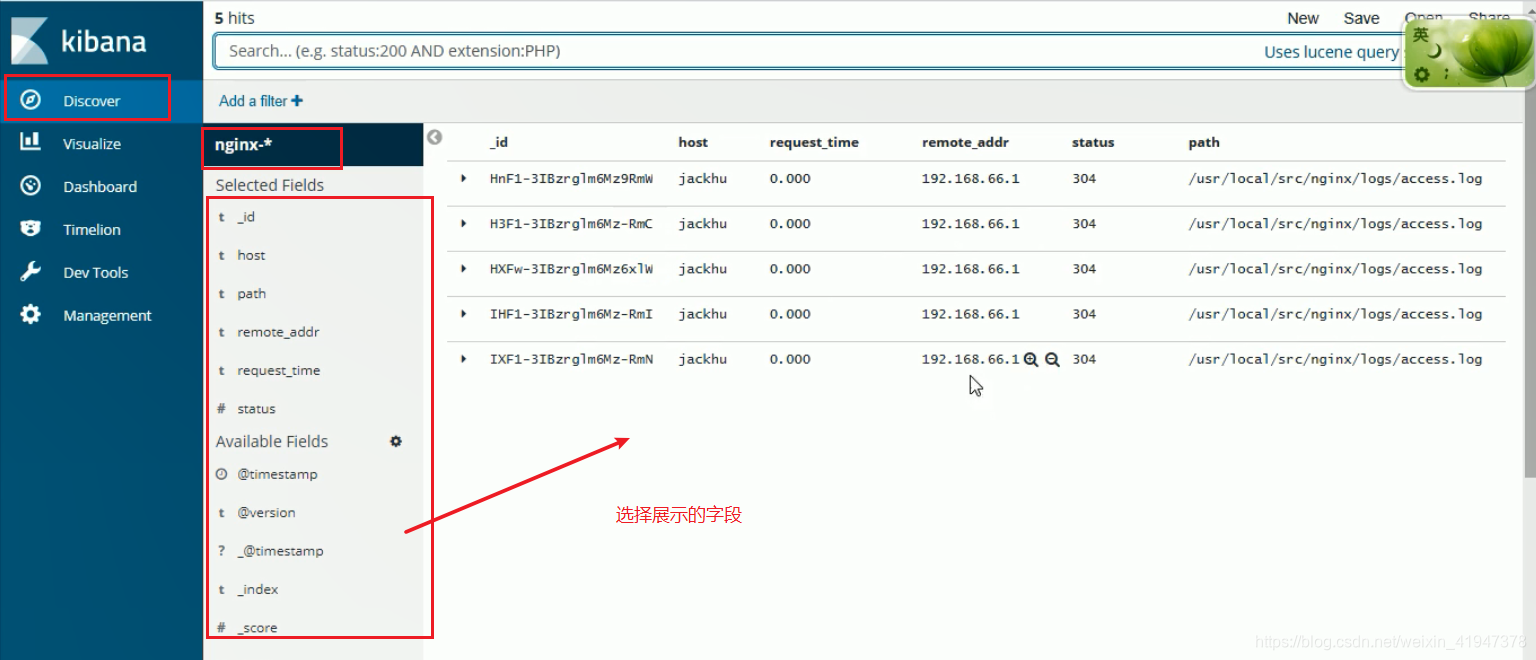
1. 日志视图
启动成功后:
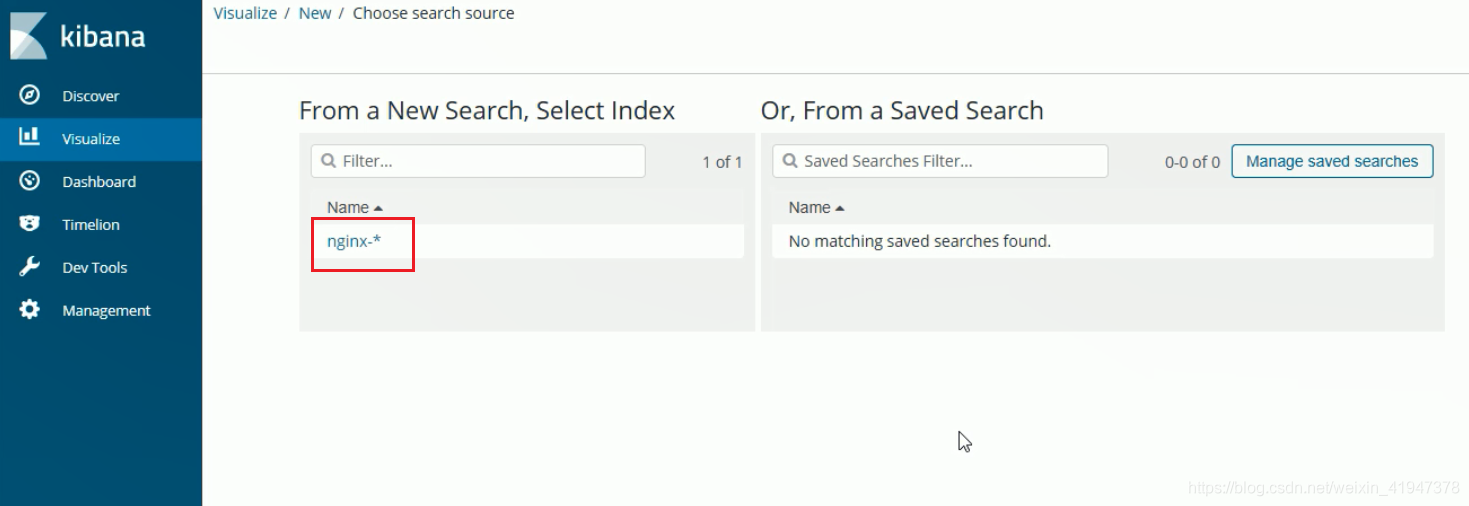
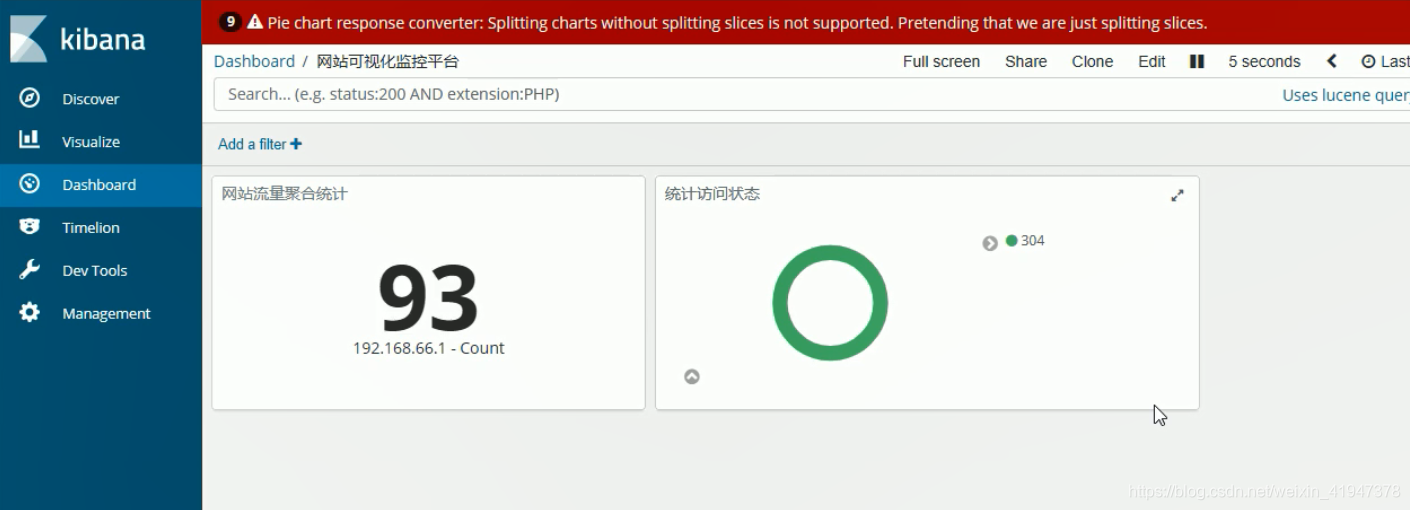
2. 可视化数据
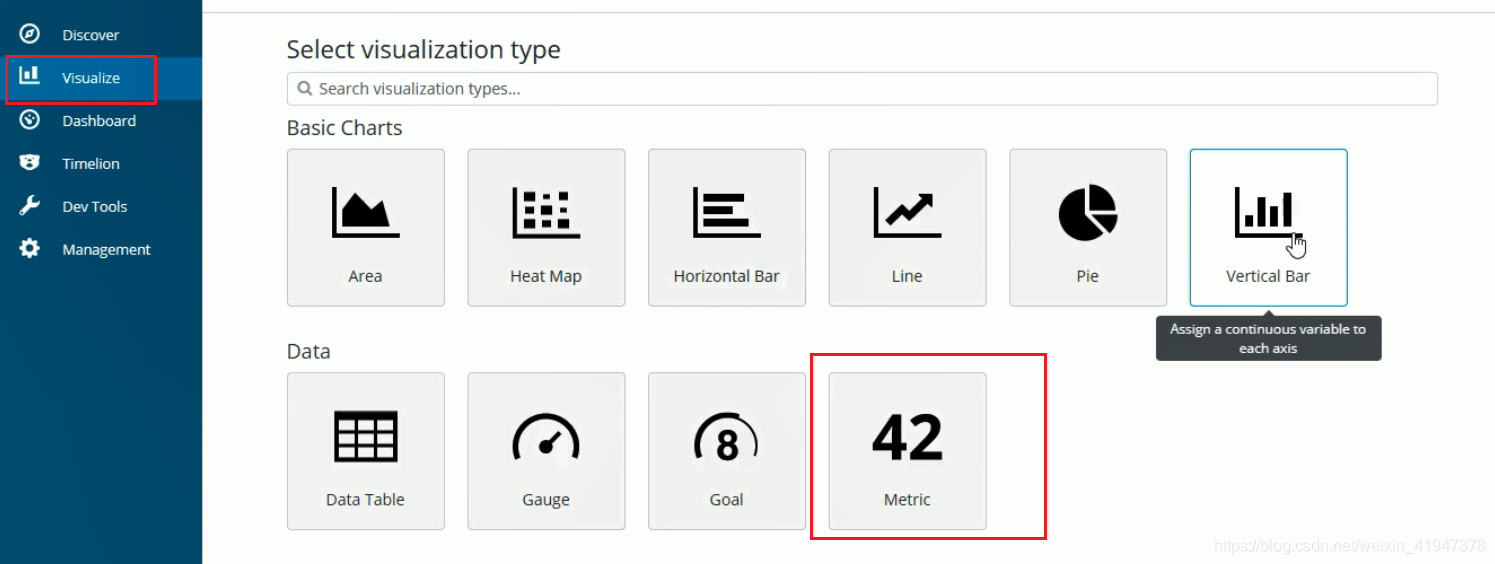
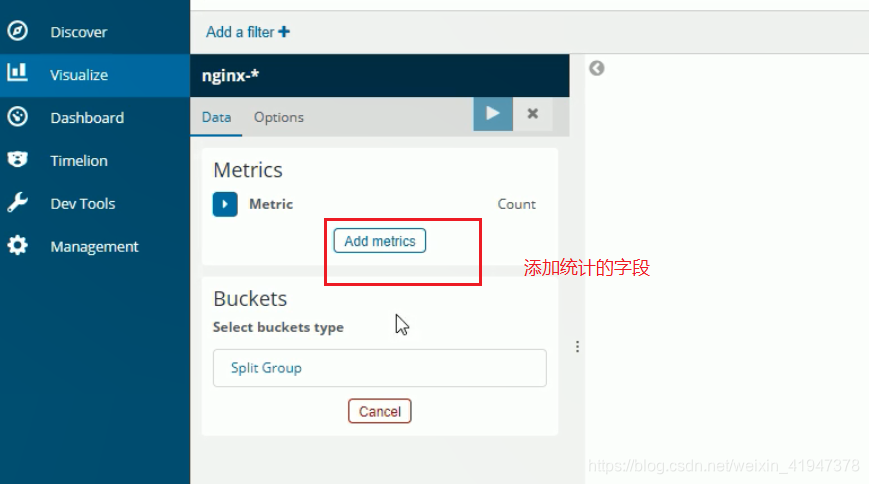
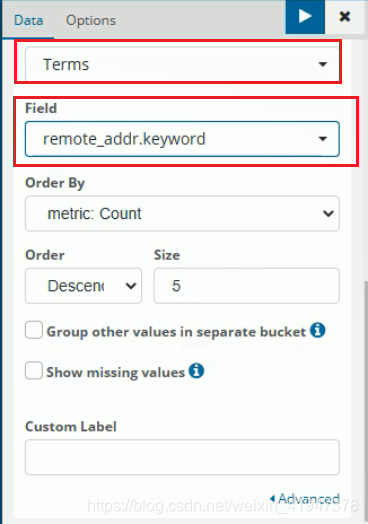
添加统计视图:
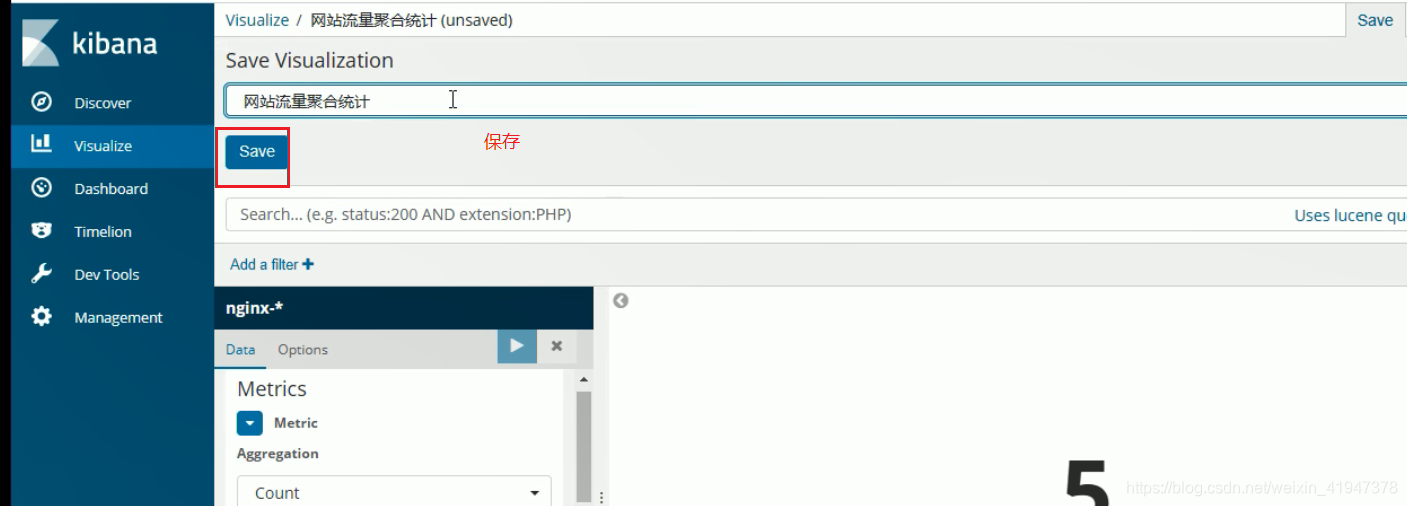
添加视图到仪表盘:
不停刷新

如果要收集大流量的数据,实时写入的数据量很高,就要把数据放入Kafka缓冲,在用Logstash从Kafka中读取,在放入ES中


















 1745
1745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











