







一、简介
LinkedHashMap继承自HashMap,除了拥有HashMap的特性外,还提供了保持遍历顺序和插入顺序一致的功能。
LinkedHashMap维护了一条双向链表,从而保证了遍历与插入顺序的一致性。LinkedHashMap可以理解为LinkedList+HashMap的组合LinkedHashMap的绝大多数功能(查找、插入、删除等)直接来源于HashMap,因此本文主要研究双向链表的维护。如果对HashMap不了解,可以查看之前的文章:JDK源码解析之HashMap- 以
JDK1.8版本为准
二、底层数据结构
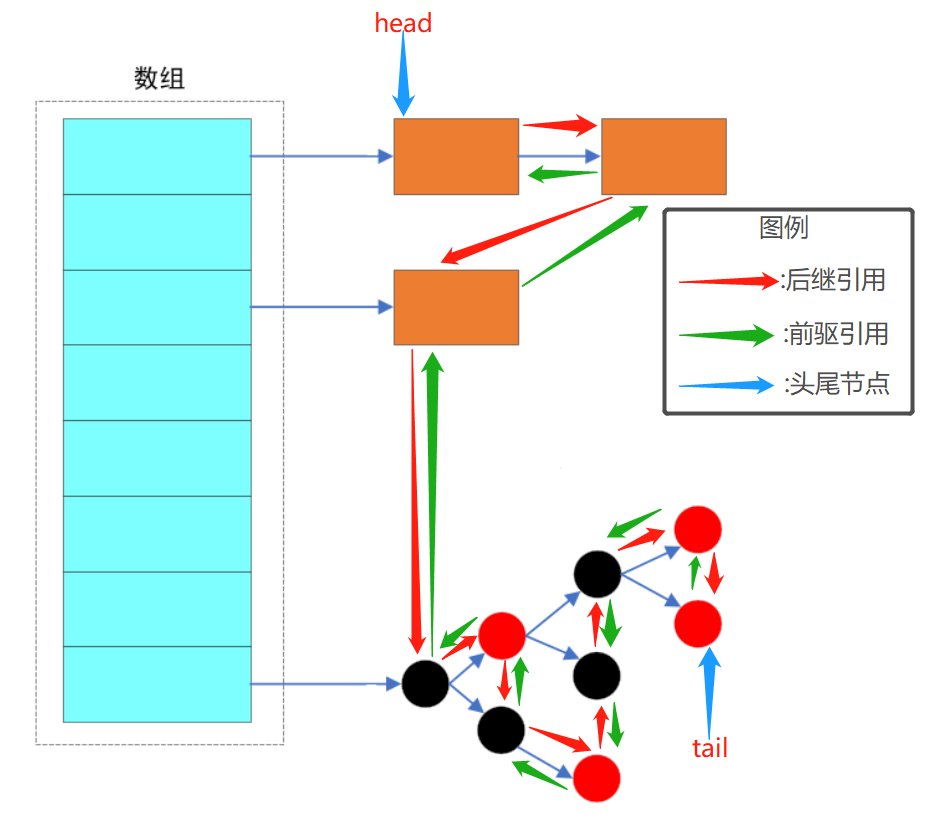
底层数据结构与HashMap一致,只不过在其基础上增加了一条双向链表,来控制其遍历的顺序。上图中的head和tail分别为这双向链表的头尾节点,每个节点都有其前驱和后继指向。
三、类图
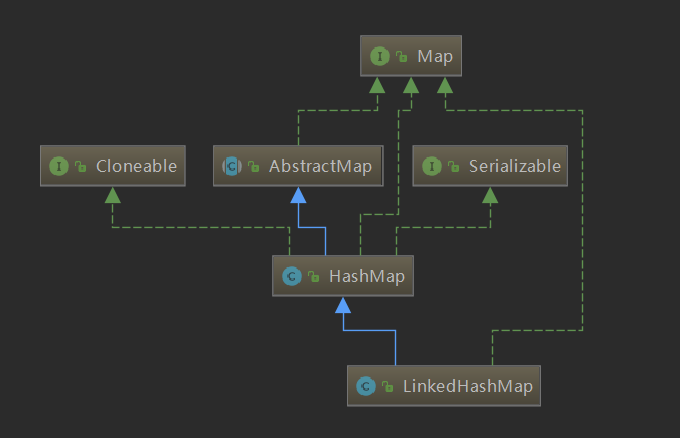
- 实现
java.util.Map接口。 - 继承
java.util.HashMap类。
四、属性和构造方法
1. 属性
//序列化版本号
private static final long serialVersionUID = 3801124242820219131L;
//头结点,指向的节点最老
transient LinkedHashMap.Entry<K,V> head;
//尾结点,指向的节点最新
transient LinkedHashMap.Entry<K,V> tail;
//是否按照访问的顺序,默认为false
//true:按照 key-value 的访问顺序进行访问。
//false:按照 key-value 的插入顺序进行访问(默认)
final boolean accessOrder;
主要包含两类属性
head和tail:分别为双向链表的头尾节点,控制着访问的顺序,即head=>tailaccessOrder:决定LinkedHashMap的顺序false:当节点被添加时,放置到链表的结尾,被tail指向。如果插入的key对应的节点已经存在,也会被放到结尾。true:当节点被访问时,放置到链表的结尾,被tail指向。
接下来重点介绍一下LinkedHashMap.Entry这个类,先来看下键值对节点的继承体系
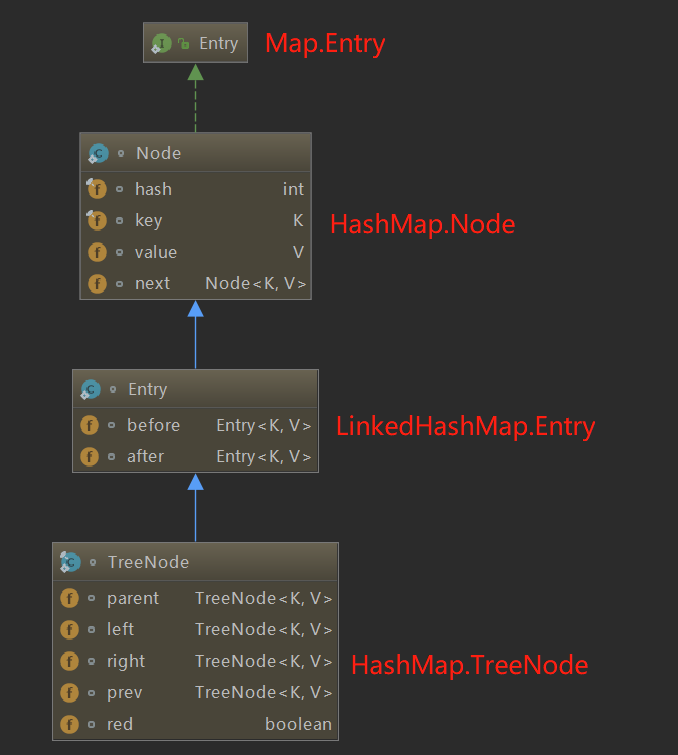
可以看到,LinkedHashMap内部类Entry继承自HashMap内部类Node,在继承原有属性的基础上新增了两个引用,分别是 before 和 after,分别代表节点的前驱和后继。
static class Entry<K,V> extends HashMap.Node<K,V> {
//前驱和后继节点
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
2. 构造方法
LinkedHashMap一共有5个构造方法,其中有4个与HashMap的构造方法基本一致。
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
这4个构造方法与HashMap唯一区别在默认设置了accessOrder为false,即默认按照插入顺序排序。
因此第5个构造函数自然就是可自定义accessOrder的参数为true或false
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
//自定义accessOrder参数
this.accessOrder = accessOrder;
}
五、节点的创建
双向链表的创建是在插入键值对的时候开始的。初始情况下,让 LinkedHashMap 的 head 和 tail 引用同时指向新节点,链表就算建立起来了。随后不断有新节点插入,通过将新节点接在 tail 引用指向节点的后面,即可实现链表的更新。
节点的新增调用的仍然是原HashMap的put方法,只不过在创建节点调用的newNode方法是LinkedHashMap重写的方法。
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
//创建Entry节点
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
//将新节点插入到双向链表的尾部
linkNodeLast(p);
return p;
}
//将新节点插入到双向链表的尾部
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
//保存原尾结点
LinkedHashMap.Entry<K,V> last = tail;
//将新节点赋值给尾结点
tail = p;
//如果尾节点为空,说明首次插入数据
if (last == null)
//新节点同时也赋值给头节点
head = p;
//否则将新节点连接到原尾结点后
else {
p.before = last;
last.after = p;
}
}
节点的创建逻辑很简单,即创建节点,链接节点到队尾。
六、节点操作回调
在 HashMap 的读取、添加、删除时会对节点造成影响,因此在执行相应操作结束后,HashMap会分别调用如下的回调方法,从而同步双向链表的状态。
afterNodeAccess(Node<K,V> e):节点被访问时触发(accessOrder为trues时)afterNodeInsertion(boolean evict):新增节点时触发afterNodeRemoval(Node<K,V> e):节点被移除时触发
接下来我们来具体分析这三个回调方法。
1. afterNodeAccess
在accessOrder属性设置为true的前提下,当节点被访问时,会放置到链表的结尾。
//将节点移到末尾
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
//只有在accessOrder为true且e不是尾结节点时才需要进行迁移到末尾
if (accessOrder && (last = tail) != e) {
//p保存当前节点;b为前驱节点;a为后继节点
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
//p的后继置空
p.after = null;
//如果b为null,代表p是头结点
if (b == null)
//p的后继更新为头节点
head = a;
//b不为null,说明p不是头节点,p处于链表的中间位置
else
//p的前驱的后续指向p的后继,也就是将p断开
b.after = a;
//如果a不为null,说明a不是尾节点
if (a != null)
//a的前驱指向b
a.before = b;
//这里的else不会执行,因为上面已经保证了e不是尾结点,所以这里的不明白为什么要做if-else判断
else
last = b;
//处理完b和a节点后,需要将p接到链表的尾部
//按理说last应该也不为空,不明白这里为啥也做判断
if (last == null)
head = p;
//将p接到链表的末尾
else {
p.before = last;
last.after = p;
}
//更新尾结点为当前节点
tail = p;
//修改次数+1
++modCount;
}
}
操作流程总结起来就是将目标节点从当前位置移到链表的末尾,逻辑较为简单。
2. afterNodeInsertion
插入元素的时候会调用该方法,但是该回调方法并不是在双向链表中插入节点(前面节点创建的时候已经插入到双向链表中了),而是根据条件判断是否需要移除元素,可以用于实现LRU策略的缓存,这个后面或详细讲解。
//参数evict表示是否允许移除元素,默认为false
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
//removeEldestEntry方法用于判断是否删除队首元素
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
//删除节点
removeNode(hash(key), key, null, false, true);
}
}
//判断是否删除队首元素,该方法默认返回false,即不删除,子类可以重写该方法定义自己的删除策略
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
上述代码在一般情况下不会执行,后面会专门利用该特性实现一个LRU策略的缓存
3. afterNodeRemoval
删除元素的时候会调用该方法
//从双向链表中删除该节点
void afterNodeRemoval(Node<K,V> e) { // unlink
//p保存当前节点;b保存p的前驱节点;a保存p的后继节点
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
//将该节点的前驱和后继置空
p.before = p.after = null;
//如果b为空,表示p为头结点,需要设置a为头结点
if (b == null)
//设置a为头结点
head = a;
//否则b不为空,表示p不为头结点,直接将b的后继指向a
else
b.after = a;
//如果a为空,表示p为尾结点,需要设置b为尾结点
if (a == null)
//设置b为尾结点
tail = b;
//a不为空,表示p不为尾结点,直接将a的前驱指向b
else
a.before = b;
}
上述逻辑较为简单,总结一下就是将目标节点从双向链表中移除。
七、其余操作
1. 查找
LinkedHashMap中对应部分的查找方法进行了重写,主要是为了上面的回调操作
-
get(Object key)
查找指定key对应的value,不存在则返回null
public V get(Object key) { Node<K,V> e; //正常的查找操作 if ((e = getNode(hash(key), key)) == null) return null; //如果accessOrder为true,则需要更新双向链表 if (accessOrder) afterNodeAccess(e); return e.value; }在原来查找的基础上,添加了更新双向链表的操作。
-
getOrDefault(Object key, V defaultValue)
获得key对应的 value ,如果不存在,则返回默认的defaultValue
public V getOrDefault(Object key, V defaultValue) { Node<K,V> e; //正常的查找操作 if ((e = getNode(hash(key), key)) == null) return defaultValue; //如果accessOrder为true,则需要更新双向链表 if (accessOrder) afterNodeAccess(e); return e.value; }逻辑同上
-
containsValue(Object value)
public boolean containsValue(Object value) { //通过头尾节点进行遍历 for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) { V v = e.value; if (v == value || (value != null && value.equals(v))) return true; } return false; }HashMap中的采用两个for循环查找,这里根据头尾节点进行一次遍历
2. 清空
public void clear() {
//调用父类的方法,清除节点信息
super.clear();
//头尾节点置空
head = tail = null;
}
八、基于LinkedHashMap实现LRU策略的缓存
根据LinkedHashMap的维护顺序的特性可以轻松实现一个LRU策略的缓存。前面介绍到afterNodeInsertion这个回调方法的时候,我们说到这个方法是控制在什么情况下可以移除最近最小被访问的节点,因此我们可以创建LinkedHashMap的子类,重写removeEldestEntry方法来实现LRU策略。代码如下
package com.jicl;
import java.util.LinkedHashMap;
import java.util.Map;
/**
* 自定义的LRU策略缓存
*
* @author : xianzilei
* @date : 2020/3/22 22:51
*/
public class MyLRUCache<K, V> extends LinkedHashMap<K, V> {
//默认最大容量
private static final Integer DEFAULT_MAXIMUM_CAPACITY = 100;
//默认负载因子
private static final float DEFAULT_LOAD_FACTOR = 0.75f;
//最大容量
private Integer maxCapacity;
public Integer getMaxCapacity() {
return maxCapacity;
}
public void setMaxCapacity(Integer maxCapacity) {
this.maxCapacity = maxCapacity;
}
//无参构造函数,最大容量默认为100
public MyLRUCache() {
this(DEFAULT_MAXIMUM_CAPACITY);
}
//有参构造函数,可自定义最大容量
public MyLRUCache(Integer maxCapacity) {
super(maxCapacity, DEFAULT_LOAD_FACTOR, true);
this.maxCapacity = maxCapacity;
}
//添加元素
public V save(K key, V val) {
return put(key, val);
}
//查找元素
public V find(K key) {
return get(key);
}
//判断key是否存在
public boolean existsKey(K key) {
return containsKey(key);
}
//判断value是否存在
public boolean existsValue(V value) {
return containsValue(value);
}
//重写父类方法,判断什么情况下删除最近最少访问的元素
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
//最大容量大于100时删除最近最少访问的元素
return size() > maxCapacity;
}
}
具体的测试代码就不再赘述了。
















 80
80











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









