







 本文介绍层次分析法(AHP),一种用于复杂决策问题的多准则决策分析方法。通过构建递阶层次结构,比较判别矩阵,计算特征向量,进行一致性检验,最后得出总排序权重,帮助决策者做出最优选择。
本文介绍层次分析法(AHP),一种用于复杂决策问题的多准则决策分析方法。通过构建递阶层次结构,比较判别矩阵,计算特征向量,进行一致性检验,最后得出总排序权重,帮助决策者做出最优选择。
层次分析法(AHP)
AHP(Analytic Hierarchy Process)方法,简称AHP,是指将与决策总是有关的元素分解成目标、准则、方案等层次,在此基础之上进行定性和定量分析的决策方法。该方法是美国运筹学家匹茨堡大学教授萨蒂于20世纪70年代初,在为美国国防部研究"根据各个工业部门对国家福利的贡献大小而进行电力分配"课题时,应用网络系统理论和多目标综合评价方法,提出的一种层次权重决策分析方法。
下面来看一个具体的例子结合理论来具体学习游:
小白打算去旅游,打算使用层次分析法选择旅游目的地。
1、建立递阶层次结构
将决策的目标、考虑的因素(决策准则)和决策对象按它们之间的相互关系分为最高层、中间层和最低层。 最高层是指决策的目的、要解决的问题。 最低层是指决策时的备选方案。 中间层是指考虑的因素、决策的准则。对于相邻的两层,称高层为目标层,低层为因素层。
目标层
选择旅游目的地的
准则层
不要超过9个因素,这里选取5个:景色、费用、居住、饮食、旅途
方案层
广州、昆明、拉萨
2、构造比较判别矩阵
在确定各层次各因素之间的权重时,如果只是定性的结果,则常常不容易被别人接受,因而Saaty等人提出一致矩阵法,即不把所有因素放在一起比较,而是两两相互比较,对此时采用相对尺度,以尽可能减少性质不同的诸因素相互比较的困难,以提高准确度。如对某一准则,对其下的各方案进行两两对比,并按其重要性程度评定等级。按两两比较结果构成的矩阵称作判断矩阵。
标度表
| 标度 | 含义 |
|---|---|
| 1 | 同等重要 |
| 3 | 稍微重要 |
| 5 | 较强重要 |
| 7 | 强烈重要 |
| 9 | 极端重要 |
| 2,4,6,8 | 两相邻判断的中间值 |
准则层次比较矩阵
矩阵的特征向量可以作为权重的值。( 为什么特征向量可以作为权重? )求解特征向量的精确值,步骤比较繁琐。在编程中,可以采用数学库,直接计算特征向量,特征值。决策中使用的是正互反矩阵,根据该类矩阵的特点可以采用近似法求解,这里我们选用和法,根法(实际上只需要选一种,这里采用两种纯粹是为了展示两种不同的算法),也可以选用幂法。计算得到的特征向量可作为权重值使用。
和法步骤:
- 将矩阵A每一列归一化;
- 对归一化的结果按行求和;
- 将求和结果归一化,作为特征向量ω;
- 求 λ = 1 n \lambda={\frac{1}{n}} λ=n1 ∑ i = 1 n ( A ω ) i ω i \displaystyle \sum^{n}_{i=1}{\frac{(Aω)_i}{ω_i}} i=1∑nωi(Aω)i,其中i表示向量中的第i个数。
和法实际上是将矩阵的列向量归一化后取平均值作为特征向量。因为当矩阵为一致矩阵时,他的每一列向量都是特征向量,所以若矩阵的不一致性不严重,则取归一化后的列向量平均值作为特征向量是合理的。
准则层次比较矩阵
| 景色 | 费用 | 居住 | 饮食 | 旅途 | |
|---|---|---|---|---|---|
| 景色 | 1 | 1/2 | 4 | 3 | 3 |
| 费用 | 2 | 1 | 7 | 5 | 5 |
| 居住 | 1/4 | 1/7 | 1 | 1/2 | 1/3 |
| 饮食 | 1/3 | 1/5 | 2 | 1 | 1 |
| 旅途 | 1/3 | 1/5 | 3 | 1 | 1 |
求特征向量
采用根法,在此我没有对矩阵进行归一化,计算的结果与和进行归一化的结果几乎没有差别。和法,不做归一化时一些差别。
| 景色 | 费用 | 居住 | 饮食 | 旅途 | 每行乘积 | 乘积五次方根 | 标准化特征向量 (权重值) | |
|---|---|---|---|---|---|---|---|---|
| 景色 | 1 | 1/2 | 4 | 3 | 3 | 18 | 1.7826 | 0.264 |
| 费用 | 2 | 1 | 7 | 5 | 5 | 350 | 3.2271 | 0.477 |
| 居住 | 1/4 | 1/7 | 1 | 1/2 | 1/3 | 0.0060 | 0.3589 | 0.053 |
| 饮食 | 1/3 | 1/5 | 2 | 1 | 1 | 0.1333 | 0.6683 | 0.099 |
| 旅途 | 1/3 | 1/5 | 3 | 1 | 1 | 0.2 | 0.7248 | 0.107 |
| 方根总和 | 6.762 |
特征向量 ω \omega ω= ( 0.264 , 0.477 , 0.053 , 0.099 , 0.107 ) T (0.264,0.477,0.053,0.099,0.107)^T (0.264,0.477,0.053,0.099,0.107)T
景色情况判断矩阵
| 广州 | 昆明 | 拉萨 | |
|---|---|---|---|
| 广州 | 1 | 2 | 5 |
| 昆明 | 1/2 | 1 | 2 |
| 拉萨 | 1/5 | 1/2 | 1 |
这里采用和法
| 广州 | 昆明 | 拉萨 | 每行求和 | 归一化求和结果(权重值) | |
|---|---|---|---|---|---|
| 广州 | 0.5882 | 0.5714 | 0.6250 | 1.7846 | 0.5949 |
| 昆明 | 0.2941 | 0.2857 | 0.2500 | 0.8298 | 0.2766 |
| 拉萨 | 0.1176 | 0.1429 | 0.1250 | 0.3855 | 0.1285 |
- 特征向量 ω = ( 0.5949 , 0.2766 , 0.1285 ) T \omega=(0.5949,0.2766,0.1285)^T ω=(0.5949,0.2766,0.1285)T
- 通过公式
A
ω
=
λ
ω
A\omega=\lambda\omega
Aω=λω便可以求得
λ
\lambda
λmax,特征向量所在的张成空间不会发生变化,与
λ
\lambda
λ作用相同。注意:A为归一化之前的矩阵。
- λ \lambda λmax ω 1 = 1 ∗ 0.5949 + 2 ∗ 0.2766 + 5 ∗ 0.1285 = 1.7906 \omega_1=1*0.5949+2*0.2766+5*0.1285=1.7906 ω1=1∗0.5949+2∗0.2766+5∗0.1285=1.7906
- λ \lambda λmax ω 2 = 1 2 ∗ 0.5949 + 1 ∗ 0.2766 + 2 ∗ 0.1285 = 0.8311 \omega_2=\frac12*0.5949+1*0.2766+2*0.1285=0.8311 ω2=21∗0.5949+1∗0.2766+2∗0.1285=0.8311
- λ \lambda λmax ω 3 = 1 5 ∗ 0.5949 + 1 2 ∗ 0.2766 + 1 ∗ 0.1285 = 0.3858 \omega_3=\frac15*0.5949+\frac12*0.2766+1*0.1285=0.3858 ω3=51∗0.5949+21∗0.2766+1∗0.1285=0.3858
- λ \lambda λmax = 1 3 ( A ω 1 ω 1 + A ω 2 ω 2 + A ω 3 ω 3 ) = 1 3 ( 1.7906 0.5949 + 0.8311 0.2766 + 0.3858 0.1285 ) = 3.006 =\frac{1}{3}(\frac{A\omega_1}{\omega_1}+\frac{A\omega_2}{\omega_2}+\frac{A\omega_3}{\omega_3})=\frac{1}{3}(\frac{1.7906}{0.5949}+\frac{0.8311}{0.2766}+\frac{0.3858}{0.1285}) =3.006 =31(ω1Aω1+ω2Aω2+ω3Aω3)=31(0.59491.7906+0.27660.8311+0.12850.3858)=3.006
因为小数点后位数取舍不同,以及选用的近似算法不同,所得到的结果也会不同。决策需要的精度不高,完全可以满足要求。
费用情况判断矩阵
| 广州 | 昆明 | 拉萨 | |
|---|---|---|---|
| 广州 | 1 | 1/3 | 1/8 |
| 昆明 | 3 | 1 | 1/3 |
| 拉萨 | 8 | 3 | 1 |
费用情况判断矩阵-求特征向量和最大特征值
这里采用和法,首先对句子进行归一化处理。
| 广州 | 昆明 | 拉萨 | 每行求和 | 归一化求和结果(权重值) | |
|---|---|---|---|---|---|
| 广州 | 0.0833 | 0.0769 | 0.0857 | 0.2459 | 0.0820 |
| 昆明 | 0.2500 | 0.2308 | 0.2286 | 0.7094 | 0.2364 |
| 拉萨 | 0.6667 | 0.6923 | 0.6857 | 2.0447 | 0.6815 |
- 特征向量 ω = ( 0.0820 , 0.2364 , 0.6815 ) T \omega=(0.0820,0.2364,0.6815)^T ω=(0.0820,0.2364,0.6815)T
-
λ
\lambda
λmax
=
1
3
(
0.2460
0.0820
+
0.7095
0.2364
+
2.0467
0.6815
)
=
3.002
=\frac{1}{3}(\frac{0.2460}{0.0820}+\frac{0.7095}{0.2364}+\frac{2.0467}{0.6815})=3.002
=31(0.08200.2460+0.23640.7095+0.68152.0467)=3.002
- 具体求解过程见景色情况判断矩阵-求特征向量和最大特征值
居住情况判断矩阵
后面我们都将采用根法,并且不单独写错判断矩阵。网上看到相关视频中用的是根法,并且没有做归一化的步骤,为了偷懒,下面直接使用视频里的计算结果。前面使用和法是为了比较两种算法的结果。
| 广州 | 昆明 | 拉萨 | 每行乘积 | 乘积三次方根 | 标准化特征向量 (权重值) | |
|---|---|---|---|---|---|---|
| 广州 | 1 | 1 | 3 | 3 | 1.442 | 0.429 |
| 昆明 | 1 | 1 | 3 | 3 | 1.442 | 0.429 |
| 拉萨 | 1/3 | 1/3 | 1 | 0.1111 | 0.481 | 0.143 |
- 特征向量 ω = ( 0.429 , 0.429 , 0.143 ) T \omega=(0.429,0.429,0.143)^T ω=(0.429,0.429,0.143)T
- λ \lambda λmax = 3.000 =3.000 =3.000
对于三阶矩阵, λ m a x \lambda_{max} λmax等于3表示取值符合完美的一致性。从矩阵中的值也可以看出来,不存在任何矛盾。不存在A,B,C的值矛盾的地方。
- 具体求解过程与和法类似,参见景色情况判断矩阵-求特征向量和最大特征值
饮食情况判断矩阵
| 广州 | 昆明 | 拉萨 | 每行乘积 | 乘积三次方根 | 标准化特征向量 (权重值) | |
|---|---|---|---|---|---|---|
| 广州 | 1 | 3 | 4 | 12 | 2.289 | 0.634 |
| 昆明 | 1/3 | 1 | 1 | 0.333 | 0.693 | 0.192 |
| 拉萨 | 1/4 | 1 | 1 | 0.250 | 0.630 | 0.174 |
- 特征向量
ω
=
(
0.634
,
0.192
,
0.0.174
)
T
\omega=(0.634,0.192,0.0.174)^T
ω=(0.634,0.192,0.0.174)T
λ \lambda λmax = 3.009 =3.009 =3.009- 具体求解过程与和法类似,参见景色情况判断矩阵-求特征向量和最大特征值
旅途情况判断矩阵
| 广州 | 昆明 | 拉萨 | 每行乘积 | 乘积三次方根 | 标准化特征向量 (权重值) | |
|---|---|---|---|---|---|---|
| 广州 | 1 | 1 | 1/4 | 0.25 | 0.630 | 0.166 |
| 昆明 | 1 | 1 | 1/4 | 0.25 | 0.630 | 0.166 |
| 拉萨 | 4 | 4 | 1 | 16.000 | 2.520 | 0.665 |
- 特征向量 ω = ( 0.166 , 0.166 , 0.665 ) T \omega=(0.166,0.166,0.665)^T ω=(0.166,0.166,0.665)T
-
λ
\lambda
λmax
=
3.000
=3.000
=3.000
- 具体求解过程与和法类似,参见景色情况判断矩阵-求特征向量和最大特征值
3、计算单排序权向量并做一致性检验
对应于判断矩阵最大特征根
λ
\lambda
λmax的特征向量,经归一化(使向量中各元素之和等于1)后记为
ω
。
ω
\omega。\omega
ω。ω的元素为同一层次因素对于上一层次因素某因素相对重要性的排序权值,这一过程称为层次单排序。能否确认层次单排序,则需要进行一致性检验,所谓一致性检验是指对A确定不一致的允许范围。其中,n阶一致阵的唯一非零特征根为n;n 阶正互反阵A的最大特征根
λ
\lambda
λmax≥n,当且仅
λ
\lambda
λmax=n 时,A为一致矩阵。
则λ 比n 大的越多,A的不一致性越严重,一致性指标用CI计算,CI越小,说明一致性越大。用最大特征值对应的特征向量作为被比较因素对上层某因素影响程度的权向量,其不一致程度越大,引起的判断误差越大。因而可以用 λ-n 数值的大小来衡量A 的不一致程度。
C I = λ − n n − 1 CI=\frac{\lambda-n}{n-1} CI=n−1λ−n
CI=0,有完全的一致性;CI 接近于0,有满意的一致性;CI 越大,不一致越严重。为衡量CI 的大小,引入随机一致性指标 RI。
随机一致性指标RI和判断矩阵的阶数有关,一般情况下,矩阵阶数越大,则出现一致性随机偏离的可能性也越大。
本案例是三阶矩阵,所以RI值为0.58,不同的标准不同,RI的值也会有微小的差异
| 矩阵阶数 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| RI | 0 | 0 | 0.58 | 0.90 | 1.12 | 1.24 | 1.32 | 1.41 | 1.45 | 1.49 |
考虑到一致性的偏离可能是由于随机原因造成的,因此在检验判断矩阵是否具有满意的一致性时,还需将CI和随机一致性指标RI进行比较,得出检验系数CR。
一般,如果CR<0.1 ,则认为该判断矩阵通过一致性检验,否则就不具有满意一致性。
C R = C I R I CR=\frac{CI}{RI} CR=RICI
C
I
景
色
=
λ
m
a
x
−
n
n
−
1
=
3.005
−
3
3
−
1
=
0.003
CI_{景色}=\frac{\lambda_{max}-n}{n-1}=\frac{3.005-3}{3-1}=0.003
CI景色=n−1λmax−n=3−13.005−3=0.003
C
R
景
色
=
C
I
景
色
R
I
=
0.003
0.58
=
0.005
CR_{景色}=\frac{CI_{景色}}{RI}=\frac{0.003}{0.58}=0.005
CR景色=RICI景色=0.580.003=0.005
其他因素的算法一样,过程就不列了。结果入下表所示:
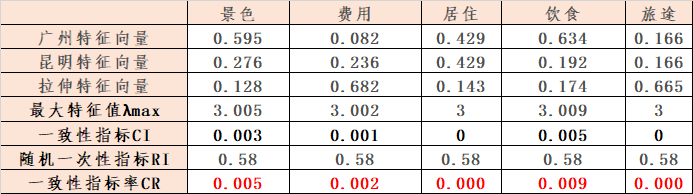
从CR值(都为正数,并且小于0.1)可以看出,我们的矩阵时非常符合一致性的矩阵。可以进入下一步计算
4、总的排序选优
计算某一层次所有因素对于最高层(总目标)相对重要性的权值,称为层次总排序。这一过程是从最高层次到最低层次依次进行的。总排序的权重可以通过方案层的特征向量乘以准则层的特征向量的转置得到,公式如下:
总 排 序 权 值 = s u m ( 方 案 层 特 征 向 量 ∗ 准 则 层 特 征 向 量 T ) 总排序权值=sum(方案层特征向量*准则层特征向量^T) 总排序权值=sum(方案层特征向量∗准则层特征向量T)
本案例计算结果如下:
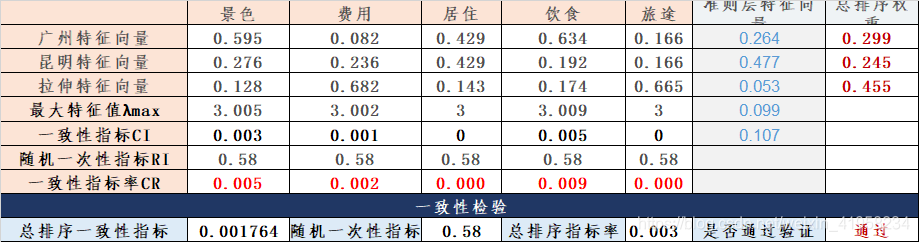
总排序一致性指标
=
ω
z
p
x
ω
z
c
c
T
=
(
0.003
,
0.001
,
0
,
0.005
,
0
)
(
0.264
,
0.477
,
0.053
,
0.099
,
0.107
)
T
=
0.001764
=\omega_{zpx}\omega_{zcc}^T=(0.003,0.001,0,0.005,0)(0.264,0.477,0.053,0.099,0.107)^T=0.001764
=ωzpxωzccT=(0.003,0.001,0,0.005,0)(0.264,0.477,0.053,0.099,0.107)T=0.001764
总排序指标率
=
总
排
序
一
致
性
指
标
R
I
=
0.001764
0.58
=
0.003
=\frac{总排序一致性指标}{RI}=\frac{0.001764}{0.58}=0.003
=RI总排序一致性指标=0.580.001764=0.003
小于0.1通过检验。
其中:
ω
z
p
x
为
一
致
性
指
标
C
I
特
征
向
量
。
\omega_{zpx}为一致性指标CI特征向量。
ωzpx为一致性指标CI特征向量。
ω
z
c
c
表
示
准
则
层
特
征
向
量
。
\omega_{zcc}表示准则层特征向量。
ωzcc表示准则层特征向量。
广 州 的 权 重 = ω g z ω z c c T = ( 0.595 , 0.082 , 0.429 , 0.634 , 0.166 ) ( 0.264 , 0.477 , 0.053 , 0.099 , 0.107 ) T = 0.299 其 中 ω g z 表 示 广 州 特 征 向 量 ; ω z c c 表 示 准 则 层 特 征 向 量 广州的权重=\omega_{gz}\omega_{zcc}^T=(0.595,0.082,0.429,0.634,0.166)(0.264,0.477,0.053,0.099,0.107)^T=0.299 其中\omega_{gz}表示广州特征向量; \omega_{zcc}表示准则层特征向量 广州的权重=ωgzωzccT=(0.595,0.082,0.429,0.634,0.166)(0.264,0.477,0.053,0.099,0.107)T=0.299其中ωgz表示广州特征向量;ωzcc表示准则层特征向量
可 以 理 解 为 上 一 层 的 权 重 值 , 等 于 ∑ ( 本 层 个 因 素 的 值 × 他 们 各 自 的 权 重 ) 。 ω g z ω z c c T 就 可 以 理 解 为 : ∑ ( 广 州 在 各 个 因 素 上 的 值 × 各 个 因 素 的 权 重 值 ) 可以理解为上一层的权重值,等于\sum(本层个因素的值×他们各自的权重)。\omega_{gz}\omega_{zcc}^T就可以理解为:\sum(广州在各个因素上的值×各个因素的权重值) 可以理解为上一层的权重值,等于∑(本层个因素的值×他们各自的权重)。ωgzωzccT就可以理解为:∑(广州在各个因素上的值×各个因素的权重值)
用同样的方法可以计算出,昆明和拉萨的权重,最终结果为:
广
州
的
权
重
=
0.299
;
广州的权重=0.299;
广州的权重=0.299;
昆
明
的
权
重
=
0.245
;
昆明的权重=0.245;
昆明的权重=0.245;
拉
萨
的
权
重
=
0.455
;
拉萨的权重=0.455;
拉萨的权重=0.455;
通过层次分析法,拉萨权重最大。小白决定去拉萨旅游。
多级处理
如果某一因素由多个子因素构成,则只需要通过层次分析法,先算出各个解决方案在该因素级别上的总权重即可。例如:饮食需要通过早餐、正餐、小吃来判断。则我们需要用上面同样的方法先计算出不同城市在饮食上的总权重(也就计算结果表中的总排序权重),这个过程中,也需要进行一致性检验。多级的情况,以此类推,只要有子因素的情况,就需要通过层次分析法进行汇总,计算出该级别的总排序权重,再代入上一级别进行计算。
通过这一点,我们也可以更好的理解只有一级的情况。计算饮食的时候,因为没有子因素,所以只需要做一次两两比较,计算特征向量即可。表中的总排序权重,实际上就是各个因素的权重,乘以各个因素的打分值。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









