






目录
2.对于同一层次的各元素关于上一层次中某一准则的重要性进行两两比较,构造两两比较矩阵(判断矩阵)。
3.由判断矩阵计算被比较元素对于该准则的相对权重,并进行一致性检验(检验通过权重才能用)。
层次分析法(The analytic hierarchy process, 简称AHP) 建模比赛中最基础的模型之一,其主要用于解决评价类问题(例如:选择哪种方案最好、哪位运动员或者员工表现的更优秀)。
层次分析法的主要特点是通过建立递阶层次结构,把人类的判断转化到若干因素两两之间重要度的比较上,从而把难于量化的定性判断转化为可操作的重要度的比较上面。在许多情况下,决策者可以直接使用AHP进行决策,极大地提高了决策的有效性、可靠性和可行性,但其本质是一种思维方式,它把复杂问题分解成多个组成因素,又将这些因素按支配关系分别形成递阶层次结构,通过两两比较的方法确定决策方案相对重要度的总排序。整个过程体现了人类决策思维的基本特征,即分解、判断、综合,克服了其他方法回避决策者主观判断的缺点。
一:问题的引入
解决评价类问题,首先要想到以下三个问题:1 我们 评价的目标 是什么?答:为小明同学选择最佳的旅游景点。2 我们为了达到这个 目标 有哪几种可选 的方案 ?答:三种,分别是去苏杭、去北戴河和去桂林。3 评价的准则 或者说指标是什么?(我们根据什么东西来评价好坏)答:景色、花费、居住、饮食、交通。
二:模型的建立
1.分析系统中各因素之间的关系,建立系统的递阶层次结构。
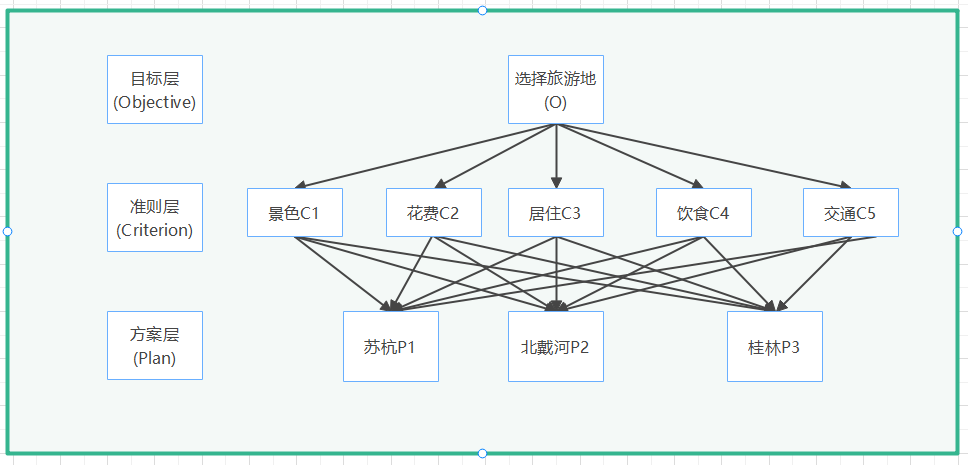
图2.1旅游地选择层次结构图
2.对于同一层次的各元素关于上一层次中某一准则的重要性进行两两比较,构造两两比较矩阵(判断矩阵)。
层次分析法最重要使用的表格格式为:
| 指标权重 | 方案1 | 方案2 | 方案3 | ...... | |
| 指标1 | |||||
| 指标2 | |||||
| 指标3 | |||||
| ...... |
注意:同颜色的单元格的和为1,它们表示的针对某一因素所占的权重(或得分) 。
那么对应本问题,所要填写的表格如下表所示:
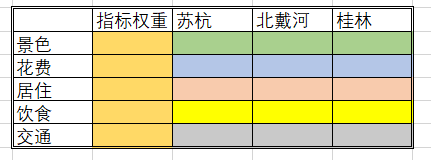
实际上,建模的最终结果就是填满权重矩阵。
| 标度 | 含义 |
|---|---|
| 1 |
表示两个因素相比,具有同样重要性
|
| 3 |
表示两个因素相比,一个因素比另一个因素稍微重要
|
| 5 |
表示两个因素相比,一个因素比另一个因素明显重要
|
| 7 |
表示两个因素相比,一个因素比另一个因素强烈重要
|
| 9 |
表示两个因素相比,一个因素比另一个因素极端重要
|
| 2、4、6、8 |
上述两相邻判断的中值
|
| 倒数 |
A和 B
相比如果标度为
3
,那么
B
和
A
相比就是
1/3
|
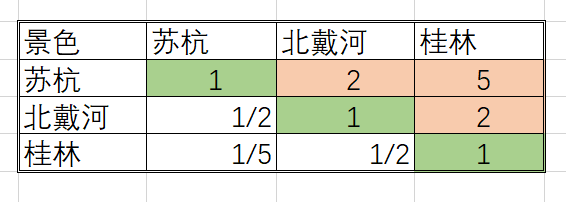
填写判断矩阵:
| O | 景色 | 花费 | 居住 | 饮食 | 交通 |
| 景色 | 1 | 1/2 | 4 | 3 | 3 |
| 花费 | 2 | 1 | 7 | 5 | 5 |
| 居住 | 1/4 | 1/7 | 1 | 1/2 | 1/3 |
| 饮食 | 1/3 | 1/5 | 2 | 1 | 1 |
| 交通 | 1/3 | 1/5 | 3 | 1 | 1 |
总结:上面这个表是一个 5*5 的方阵,我们记为A,对应的元素为𝑎ij .
这个方阵有如下特点:
1.aij表示的意义是,与指标𝑗相比,𝑖的重要程度。
2.当 i = 𝑗 时,两个指标相同,因此同等重要记为1,这就解释了主对角线元素为1。
如何计算苏杭、北戴河和桂林在景色、花费等方面多占的权重(得分)???
仍然使用1‐9表示重要程度,按照确定权重的方法来填写判断矩阵:
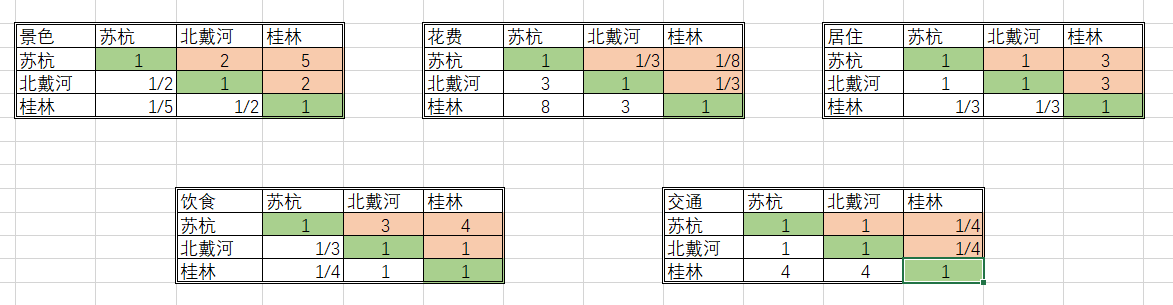
3.由判断矩阵计算被比较元素对于该准则的相对权重,并进行一致性检验(检验通过权重才能用)。
在上述五个表格中,若填写的判断矩阵为下述示例,可能会存在一个问题:
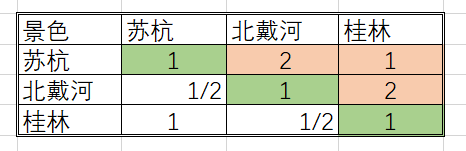
我们看景色一栏的对比,苏杭的景色比北戴河的好一点 即 苏杭 > 北戴河
苏杭的景色和桂林的景色一样好 即 苏杭 = 桂林
北戴河的景色比桂林的景色好一点 即 北戴河 > 桂林
此时,出现了矛盾的地方。

一致性检验原理:检验我们构造的判断矩阵和一致矩阵是否有太大的差别。
 若正互反矩阵(判断矩阵)满足𝑎ij * aji = aik ,则我们称其为一致矩阵。此外,n 阶正互反矩阵 A 为一致矩阵时当且仅当最大特征值 λmax = n ,且当正互反矩阵 A 非一致时,一定,满q足 λmax > n 。总而言之,判断矩阵越不一致时,最大特征值与 n 相差就越大。
若正互反矩阵(判断矩阵)满足𝑎ij * aji = aik ,则我们称其为一致矩阵。此外,n 阶正互反矩阵 A 为一致矩阵时当且仅当最大特征值 λmax = n ,且当正互反矩阵 A 非一致时,一定,满q足 λmax > n 。总而言之,判断矩阵越不一致时,最大特征值与 n 相差就越大。
一致性检验的步骤:
<1>:计算一致性指标CI
<2>:查找对应的平均随机一致性指标RI
注:在实际运用中,n很少超过10,如果指标的个数大于10,则可考虑建立二级指标体系,或使用我们以后要学习的模糊综合评价模型。 RI我们只需要会查表即可。
<3>:计算一致性比例CR。
如果CR < 0.1, 则可认为判断矩阵的一致性可以接受;否则需要对判断矩阵进行修正。

4. 根据权重矩阵计算得分,并进行排序。
使用第一列的数据作示例,计算出来权重:
苏杭 = 1 /(1+0.5+0.2)= 0.5882
北戴河 = 0.5 /(1+0.5+0.2)= 0.2941
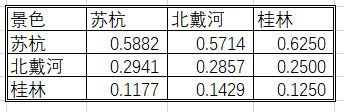
<1>:算数平均法求权重
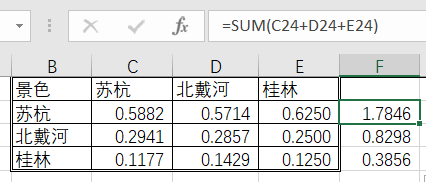
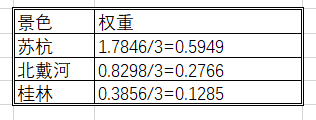
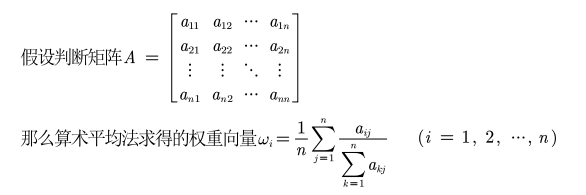
公式可写作:
<2>:几何平均法求权重

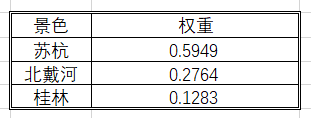
上图为几何法的计算结果。
<3>:特征值法求权重
使用二-3中求一致性检验的方法
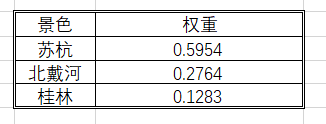
上图为特征值法的计算结果。
5.填充权重矩阵
其余的矩阵按照上述的方式进行计算,得出最终的结果,在此处,不再一一计算,直接给出结果:
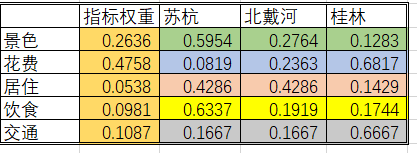
6.根据权重矩阵计算得分,并进行排序
苏杭:
0.5954×0.2636+0.0819×0.4758+0.4286×0.0538+0.6337×0.0981+0.1667×0.1087=0.299
同理:北戴河得分为0.245,桂林得分为0.455。
0.455 > 0.299 > 0.245 即 桂林 > 苏杭 > 北戴河
三:局限性
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









