







北京智源人工智能研究院(BAAI)前沿报告——强化学习领域

本文参考于2021-2022年度智源人工智能研究员前沿报告中的强化学习领域篇。
1 提升训练效率成为强化学习领域的研究重点
近来,许多研究者期望能够探索出更为高效的强化学习算法,一是具有较好泛化能力,适用于多种场景;二是在输入数据较少或较为简单,类似真实环境的情形下,智能体依然能够取得较好的表现。目前已有 MuZero 等实现了这一目标。然而,强化学习也面临样本效率的挑战。从零开始训练智能体,往往需要通过成百上千万的步骤才能达到预期的性能表现,这会增加智能体对于算力的需求,不适合在真实场景下部署应用。
清华大学研究者提出小数据强化学习算法 EfficientZero
11月,清华大学交叉研究院高阳课题组发表论文,提出小数据强化学习算法 EfficientZero,仅需要两个小时的真实时间训练,该算法比人类在雅达利 100k 数据集上的评价表现高了190.4%,比中值表现高了116%。同时,EfficientZero 已接近 DQN 在2亿帧上的性能,但数据需求量降低了500倍。
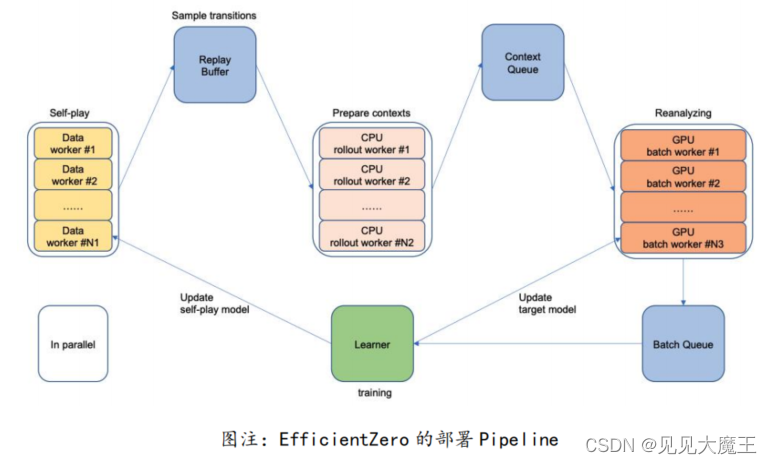
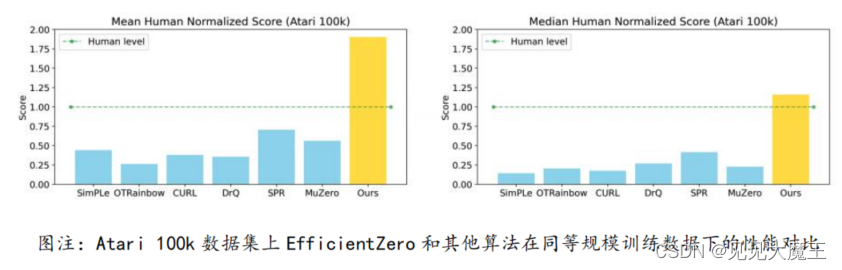
来源:https://arxiv.org/pdf/2111.00210.pdf
2 强化学习环境成为发展泛化性更强、适应复杂环境智能体的重要支撑
在强化学习的发展过程中,为智能体打造适合的训练环境,提供丰富多样的环境反馈,全面评价智能体的表现,是许多科研机构关注的问题。OpenAI 曾推出 Gym 和 Universe 两个强化学习平台,为训练新一代智能体提供了丰富的游戏、环境和评测支持。近年来,能够模拟
更为真实和复杂的训练环境,具有智能体配置、环境设置、训练、评价一条龙服务的强化学习平台不断涌现。
斯坦福大学李飞飞等学者提出深度进化强化学习框架
在自然界中,动物利用其形态来学习复杂的任务,获得显着程度的具身智能(Embodied Intelligence)。具身智能假设智能行为可以被具有对应形态的智能体通过适应环境的方式学习到。在强化学习中,创建具有特定形态的智能体,使其通过具身性获得智能能力是一大挑战。2月,斯坦福大学李飞飞等学者提出了名为 深度进化强化学习 (Deep Evolutionary Reinforcement Learning,DERL) 框架。该框架可以让智能体通过在复杂的任务和环境中,仅依赖低层次自我中心 (Low Level Ego-Centric) 传感信息的方式,逐步进化出多样的智能体形态。通过 DERL,研究者发现了一些环境复杂性和形态智能,控制学习能力等之间的关系。
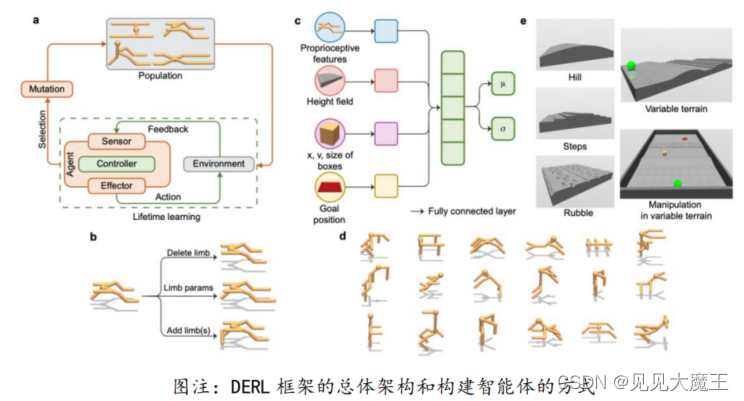
来源:https://arxiv.org/pdf/2102.02202.pdf
DeepMind 研究者提出 XLand 通用智能体强化学习训练环境
7月,DeepMind 研究者提出一种名为 XLand 的通用智能体强化学习训练环境。DeepMind 认为,泛化能力不足是限制当前强化学习算法应用的一大障碍。由于泛化能力并不是一蹴而就形成的,人类是从简单的任务开始,逐渐掌握复杂的任务。受此启发,DeepMind 提出 XLand,其中包含了数十亿个任务,涵盖雅达利、夺旗、Dota2、捉迷藏等不同的游戏、世界和玩家对象。AI 智能体首先学习简单任务,不断完善,然后逐渐在更为复杂的任务上训练。智能体在 XLand 的 4000 个独立世界中能够玩大约 70万 个独立游戏,涉及 340万 个独立任务。
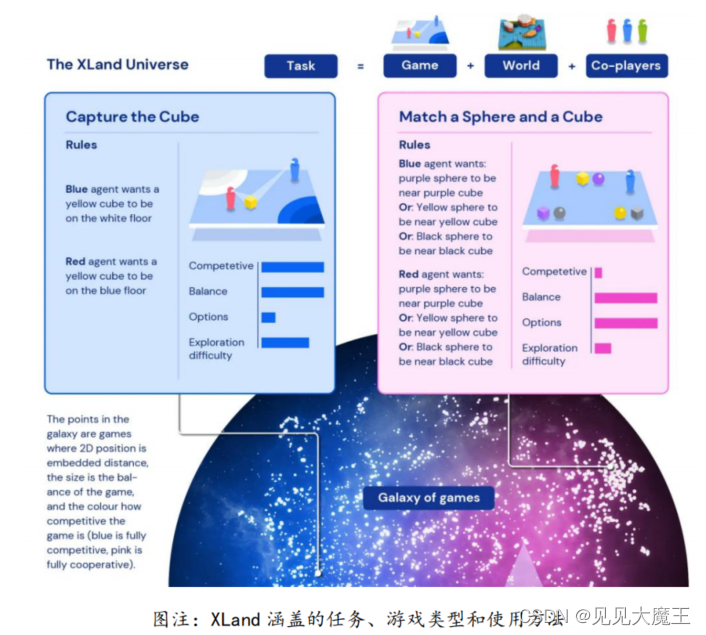
https://www.deepmind.com/blog/generally-capable-agents-emerge-from-open-ended-play
Transformer 渗透强化学习领域
Transformer 的快速发展,有望成为人工智能领域通用算法架构。许多研究者认为,将智能体的行为转换为序列,并进行建模,就可以在Transformer 架构中进行学习和训练,因此目前有许多研究者也在探究其对构建更高效智能体所带来的影响。
加州大学伯克利分校等研究者提出基于 Transformer 的强化学习架构
6月,加州大学伯克利分校、Facebook、谷歌的研究者提出了一种序列建模强化学习的方法,构建了基于Transformer的强化学习架构。实验显示,在 Atari、OpenAI Gym、Minigrid 进行测试,Decision Transformer 均可达到与其他算法媲美甚至超越的性能表现。
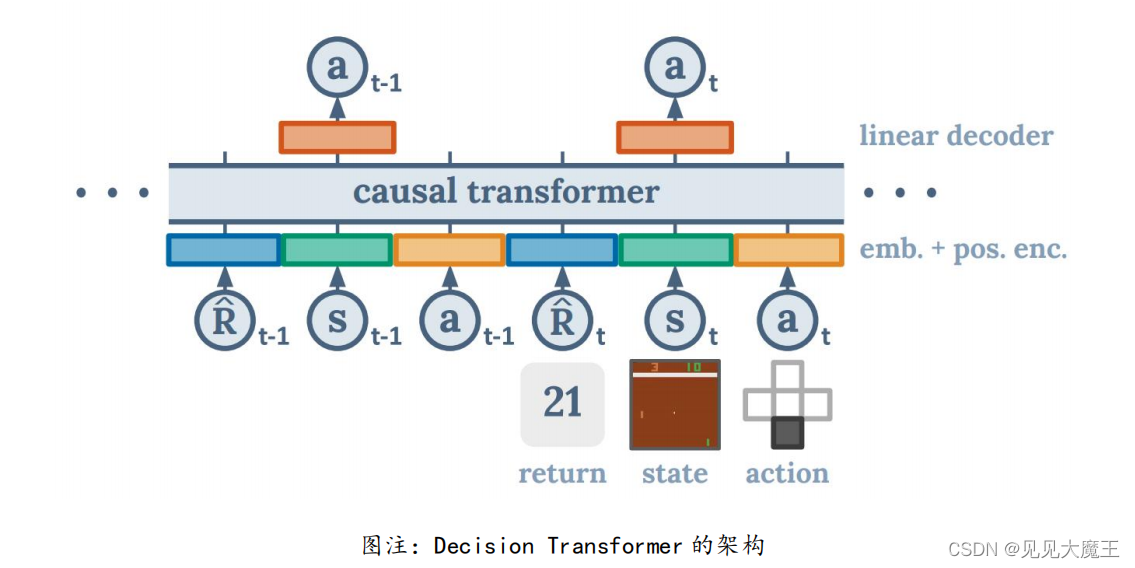
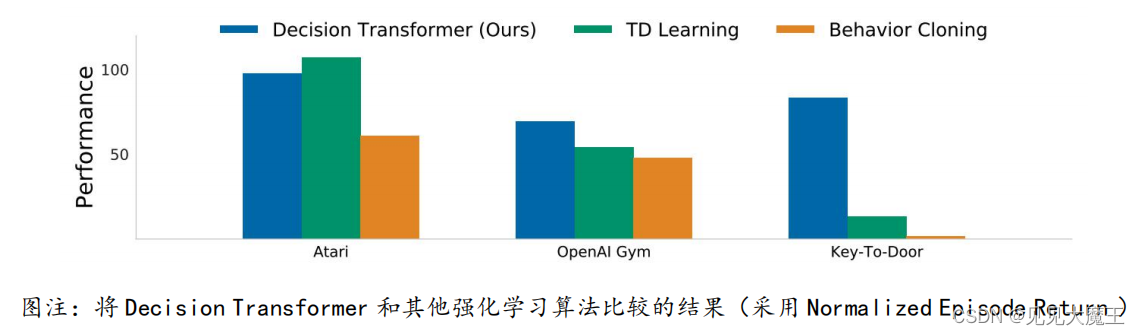
来源:https://arxiv.org/pdf/2106.01345.pdf



















 365
365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











