







文章目录
1 图计算简介
1.1 图结构数据
许多大数据都是以大规模图或网络的形式呈现,如社交网络、传染病传播途径、交通事故对路网的影响。
许多非图结构的大数据,也常常会被转换为图模型后进行分析。
图数据结构很好地表达了数据之间的关联性。关联性计算是大数据计算的核心——通过获得数据的关联性,可以从噪音很多的海量数据中抽取有用的信息。
- 比如,通过为购物者之间的关系建模,就能很快找到口味相似的用户,并为之推荐商品
- 在社交网络中,通过传播关系发现意见领袖
1.2 传统图计算解决方案的不足之处
很多传统的图计算算法都存在以下几个典型问题:
- 常常表现出比较差的内存访问局部性
- 针对单个顶点的处理工作过少
- 计算过程中伴随着并行度的改变
针对大型图(比如社交网络和网络图)的计算问题,可能的解决方案及其不足之处具体如下:
(1)为特定的图应用定制相应的分布式实现:通用性不好。
(2)基于现有的分布式计算平台进行图计算:在性能和易用性方面往往无法达到最优。
- 现有的并行计算框架像MapReduce还无法满足复杂的关联性计算。
- MapReduce作为单输入、两阶段、粗粒度数据并行的分布式计算框架,在表达多迭代、稀疏结构和细粒度数据时,力不从心。
- 比如,有公司利用MapReduce进行社交用户推荐,对于5000万注册用户,50亿关系对,利用10台机器的集群,需要超过10个小时的计算。
(3)使用单机的图算法库:比如BGL、LEAD、NetworkX、JDSL、Standford GraphBase和FGL等,但是,在可以解决的问题的规模方面具有很大的局限性
(4)使用已有的并行图计算系统:比如,Parallel BGL和CGM Graph,实现了很多并行图算法,但是,对大规模分布式系统非常重要的一些方面(比如容错),无法提供较好的支持
1.3 图计算通用软件
传统的图计算解决方案无法解决大型图的计算问题,因此,就需要设计能够用来解决这些问题的通用图计算软件。
针对大型图的计算,目前通用的图计算软件主要包括两种:
- 第一种主要是基于遍历算法的、实时的图数据库,如Neo4j、OrientDB、DEX和 Infinite Graph;
- 第二种则是以图顶点为中心的、基于消息传递批处理的并行引擎,如GoldenOrb、Giraph、Pregel和Hama,这些图处理软件主要是基于BSP模型实现的并行图处理系统。
一次 BSP(Bulk Synchronous Parallel Computing Model,又称“大同步”模型) 计算过程包括一系列全局超步(所谓的超步就是计算中的一次迭代),每个超步主要包括三个组件:
- 局部计算:每个参与的处理器都有自身的计算任务,它们只读取存储在本地内存中的值,不同处理器的计算任务都是异步并且独立的。
- 通讯:处理器群相互交换数据,交换的形式是,由一方发起推送(put)和获取(get)操作。
- 栅栏同步(Barrier Synchronization):当一个处理器遇到“路障”(或栅栏),会等到其他所有处理器完成它们的计算步骤;每一次同步也是一个超步的完成和下一个超步的开始。

2 Pregel
2.1 Pregel简介
谷歌公司在2003年到2004年公布了GFS、MapReduce和BigTable,成为后来云计算和Hadoop项目的重要基石。
谷歌在后Hadoop时代的新“三驾马车”——Caffeine、Dremel和Pregel,再一次影响着圈子与大数据技术的发展潮流。
Pregel是一种基于BSP模型实现的并行图处理系统。
-
为了解决大型图的分布式计算问题,Pregel搭建了一套可扩展的、有容错机制的平台,该平台提供了一套非常灵活的API,可以描述各种各样的图计算。
-
Pregel作为分布式图计算的计算框架,主要用于图遍历、最短路径、PageRank计算等等。
2.2 Pregel图计算模型
(1)有向图和顶点
Pregel计算模型以有向图作为输入;有向图的每个顶点都有一个String类型的顶点ID;每个顶点都有一个可修改的用户自定义值与之关联;每条有向边都和其源顶点关联,并记录了其目标顶点ID;边上有一个可修改的用户自定义值与之关联。

在每个超步S中,图中的所有顶点都会并行执行相同的用户自定义函数;每个顶点可以接收前一个超步(S-1)中发送给它的消息,修改其自身及其出射边的状态,并发送消息给其他顶点,甚至是修改整个图的拓扑结构;在这种计算模式中,“边”并不是核心对象,在边上面不会运行相应的计算,只有顶点才会执行用户自定义函数进行相应计算。

(2)顶点之间的消息传递
采用消息传递模型主要基于以下两个原因:
- 消息传递具有足够的表达能力,没有必要使用远程读取或共享内存的方式;
- 有助于提升系统整体性能。大型图计算通常是由一个集群完成的,集群环境中执行远程数据读取会有较高的延迟;Pregel的消息模式采用异步和批量的方式传递消息,因此可以缓解远程读取的延迟 。

(3)Pregel的计算过程
Pregel的计算过程是由一系列被称为“超步”的迭代组成的。
在每个超步中,每个顶点上面都会并行执行用户自定义的函数,该函数描述了一个顶点V在一个超步S中需要执行的操作。
该函数可以读取前一个超步(S-1)中其他顶点发送给顶点V的消息,执行相应计算后,修改顶点V及其出射边的状态,然后沿着顶点V的出射边发送消息给其他顶点,而且,一个消息可能经过多条边的传递后被发送到任意已知ID的目标顶点上去。
这些消息将会在下一个超步(S+1)中被目标顶点接收,然后象上述过程一样开始下一个超步(S+1)的迭代过程。

在Pregel计算过程中,一个算法什么时候可以结束,是由所有顶点的状态决定的。
在第0个超步,所有顶点处于活跃状态,都会参与该超步的计算过程。
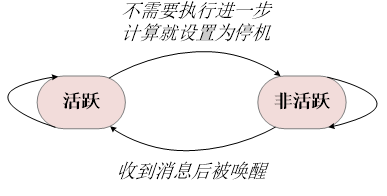
当一个顶点不需要继续执行进一步的计算时,就会把自己的状态设置为“停机”,进入非活跃状态。
一旦一个顶点进入非活跃状态,后续超步中就不会再在该顶点上执行计算,除非其他顶点给该顶点发送消息把它再次激活。
当一个处于非活跃状态的顶点收到来自其他顶点的消息时,Pregel计算框架必须根据条件判断来决定是否将其显式唤醒进入活跃状态。
当图中所有的顶点都已经标识其自身达到“非活跃(inactive)”状态,并且没有消息在传送的时候,算法就可以停止运行。
(4)实例

2.3 Pregel的C++ API
Pregel已经预先定义好一个基类——Vertex类:
template <typename VertexValue, typename EdgeValue, typename MessageValue>
class Vertex  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 132
132











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









