








论文地址:https://ieeexplore.ieee.org/document/8953674
源码地址:尚未开源
1 Background of Paper
只需要很少的目标域图像,且这些图像的bbox标注很有限,用这些数据和源域数据一起实现小样本的域自适应目标检测。(提出疑点:小样本不应该是源域数据也很少吗?)为了解决这个问题,首先用配对的方法,将源域数据和目标域数据弄成一对对,降低数据量少带来的影响;然后提出一个双层的模块,来让源域中预训练的模型,适应到目标域中:1)基于图像级自适应模块的split pooling均匀地提取并对齐成对的局部图像块特征;2)实例级自适应模块从语义上对齐成对的目标特征,以避免造成类间的confusion;3)同时采用一个source model feature regularization来稳定两个模块的自适应过程。
这样设置的原因时在新域上收集一点点的数据不会很耗费过多的精力且还能降低由大量数据带来的不可避免的噪声。配对的方法将特征样本分成两组:第一组全是source的,第二组是source+target的,这方法也可以用在数据增强上。
2 Methods
目标:将一个在源训练数据上训练的检测模型,自适应到目标域上,且最小化检测结果的降低。

2.1 Image-level Adaptation

Split pooling(SP)
已知一个宽w和高h的grid,首先生成随机的位移量s_x和s_y,其中(0<s_x<w,s_y同理),这个grid在输入图像上表现为从输入左上角开始数起(s_x,s_y)。这一随机策略在可能产生有误差抽样的静态grid和耗尽所有grid坐标以产生冗余和过抽样之间取舍。
Grid的w和h设置方式和Faster RCNN中anchor boxes(scales和ratios)的设置方式差不多。在这里选择三个尺度(大256,中160,小96,对应于VGG16网络的relu_5_3层feat size16,10,6)以及三个长宽比(0.5,1,2),也就是9个w和h组合。对于每一个组合,生成一个grid,然后grid里的无边界矩形用ROI pooling pool成固定尺寸的特征。这个pooling使得不同尺寸的grid可以与单一个域分类器相匹配,而不用改变提取出来特征的patch-wise性质。SP的结果是三个尺度的特征。这些局部图像块的特征可以影响图像级的域漂移(光照、天气……),因为这些漂移更多的是发生在一整张图上,对于目标检测来说该现象更明显,因为输入图像通常是很大的。
接下来用成对的局部特征进行多尺度对齐
通过上面,得到了两组,每组三个尺度,对于小尺度有![]() ,其中
,其中![]() ,第一组只包含源域样本,而第二组包含一个源域样本,其他都是来自目标域,小尺度的目标函数:
,第一组只包含源域样本,而第二组包含一个源域样本,其他都是来自目标域,小尺度的目标函数:
![]()
目标:辨别器的作用是可以清楚的把源-源对和源-目标对分离开来,而生成器的作用是把两个域内特征进行转换,以至于辨别其分不清他们的模样。其他两个尺度同理。另外,这个模块是在无监督情况下运算的,于是它可以被用来无监督域自适应。
![]()
总目标函数如上,辨别器要最小化而生成器要最大化。
2.2 Instance-level Adaptation
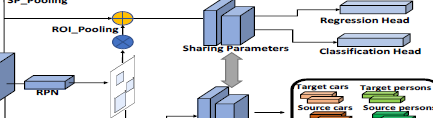

为了降低目标实例级的域漂移,提出instance-level的自适应模块,以从语义上对齐成对的目标特征。将FasterRCNN的ROI sampling拓展为实例ROI sampling,前者采样ROIs来给classification和regression head提供训练数据,它默认把背景和前景ROIs以0.5的IOU阈值分离开来,然后以一个特定的长宽比(1:3)从他们中间采样。不同的是,实例ROI sampling保留了所有具有更高IOU阈值(0.7)的前景ROIs,来确保ROIs更贴近真实的目标regions,更适合对齐。源域和目标域的前景ROI特征通过中间层(ROI pooling后head前),得到源域目标特征![]() 和目标域目标特征
和目标域目标特征![]() ,其中i∈[0, C]是类别标签,C是总类数。然后他们分成了两组
,其中i∈[0, C]是类别标签,C是总类数。然后他们分成了两组![]() 和
和![]() ,多路实例级判别器
,多路实例级判别器![]() 的输出维度是2×C,最小化目标函数:
的输出维度是2×C,最小化目标函数:
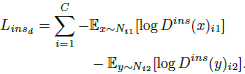
![]() 代表判别器在第一组第i类的输出。而与之对应,特征提取器的目标是最小化:
代表判别器在第一组第i类的输出。而与之对应,特征提取器的目标是最小化:
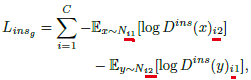
目标是confuse判别器,同时避免错误分类到其他类别。
2.3 Source Model Feature Regularization
训练不稳定性一直是对抗学习的一种常见问题,而且在训练数据少的情况下会更加严重,导致过自适应。用很少的target数据来fine-tune不可避免地出现过拟合。我们采用一种强正则化的方法,从l2 difference的角度,通过强制自适应模型产生与具有源输入的源模型一致的特征。目的是避免学到的表征朝着目标域样本过度更新以降低检测表现。相似的feat map上的l2惩罚法也会用在image to image translation上,来限制内容的改变。
![]()
但是,目标检测更多的是关注局部前景区域,因为背景通常带有噪声且面积更大。发现直接将正则化表达在全局feat map上会大大降低其表现力,所以提出将feat map的前景目标估计为anchor locations,它们与gt boxes的IOU大于一个阈值(0.5),设M为这个估计后的前景掩膜,故有:
![]()
其中k是positive mask location的数量,这是受《Unsupervised pixellevel domain adaptation with generative adversarial networks》中“内容相似性损失”的启发,使用可以接受的rendering imfo来在生成好的图像上施加l2惩罚项。
3 Training of FAFRCNN
第一步:关于整一个检测模型最小化![]() ;
;
第二步:关于域分类器最小化![]() ;
;















 887
887











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









