







JS divergence is not suitable
大多数情况下PG和Pdata是没有重叠的(PG为generator生成数据的概率分布,Pdata是样本数据的概率分布,两者是分布函数)
我们在算divergence时,是从两个数据分布(PG&Pdata)中sampling数据,再用discriminator来量他们之间的divergence。但是我们在sampling时数据量是有限的,除非PG&Pdata的相似度很像,否则很难通过少量数据就反应出其overlap情况。因此我们可以近似认为PG&Pdata在早期没有overlap(通过JS divergence很难反映出其overlap)
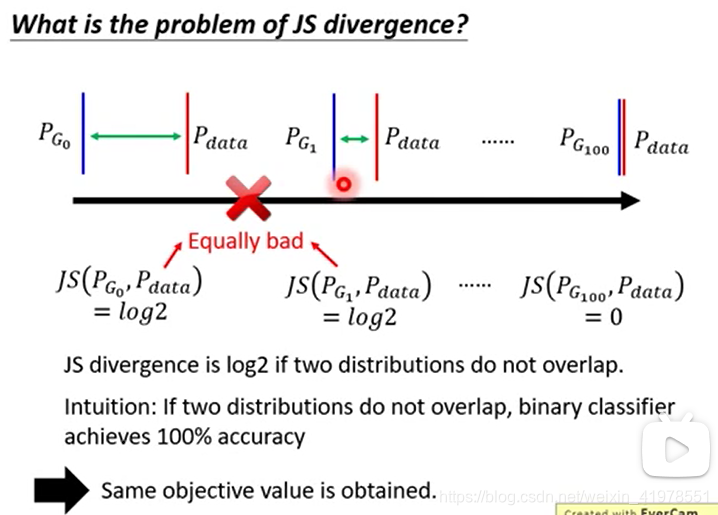
直观上PG1应该比PG0效果更好(因为generator的数据分布与样本数据分布更加接近了),但是对于JS divergence却很难反应出这个进步,因此generator并不会向着PG1的方向前进,因为对于generator来说PG1和PG0的loss是一样坏的,并没有进步。因此模型将会卡住
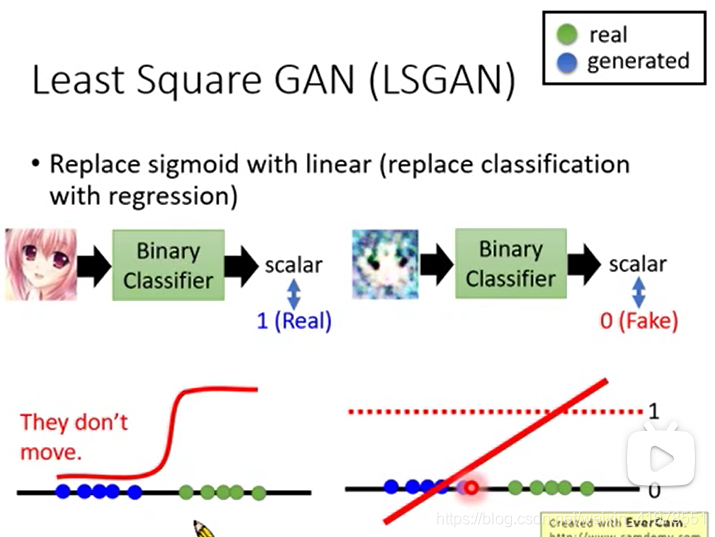
LSGAN
LSGAN提出的方法是将discriminator的输出层激活函数sigmoid换成linear,即将discriminator的二分类问题转化为回归问题,减少梯度消失的情况
WGAN
WGAN的方法是换一种方式来衡量PG和Pdata的相似程度
FGAN中提出了很多中divergence方法来衡量距离
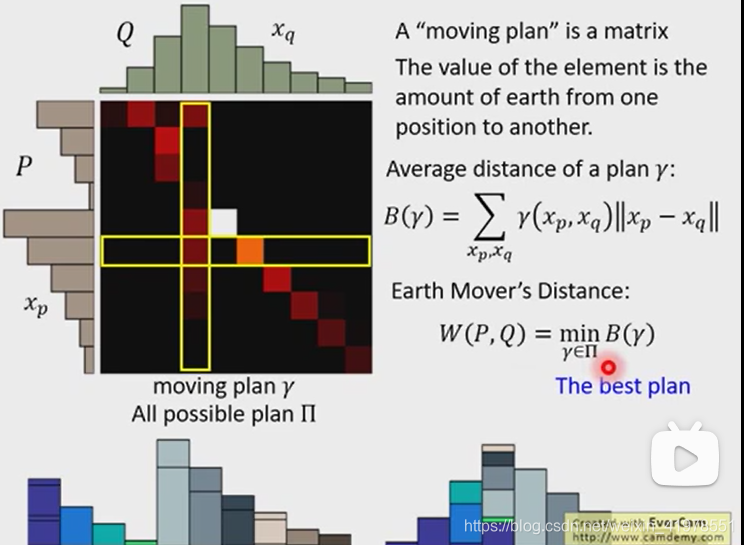
求divergence方法都是带入一个公式求解损失距离
earth movers distance则需要使用穷举的方法,列出可能的所以移动方案,找到移动距离最小的那一个
1.怎么样设计discriminator来使其train完后的值就是wasserstein distance

如果不对D(X)加以限制,就会导致real无穷大而fake无穷小,永远无解。
这里的做法就是限制D(x)的平滑程度,使其output change <= input change
而如何解这个带约束function,在最原始的WGAN中方法是weight clipping。我们同样使用梯度下降来求解,但是限制参数w的取值范围为[-c, c]。避免出现无穷情况。现实是这个方法行不通
2.Improved WGAN(WGAN-GP)

如何使D(X)为1-Lipschitz function。这里的方法是限制D(X)的梯度的L1值在处处小于1
将该条件作为惩罚项放入V(G,D)中
但不可能检查所有的输入来验证 ||D(X)|| <= 1
故规定只检验 Ppenalty上的 ||D(X)|| - 1 <= 0

所谓Ppenalty,就是在PG和Pdata上分布sampling一个点,在两个点连线之间random一个点,该点即为这个sampling上的Ppenalty点。
直觉是,Ppenalty就是介于PG和Pdata的一个概率分布,因为训练generator时就是通过discriminator指示的方向更新权重,使得PG向Pdata前进,期间会经过Ppenalty。
3.Spectrum Norm(2018)
WGAN只是限制D(X)的梯度在某一区域内<=1
而Spectrum Norm是能够使D(X)梯度在每个地方都<=1
GAN -> WGAN
最原始GAN的流程

WGAN的算法流程

EBGAN
EBGAN的generator保持不变,discriminator使用autoencoder来代替NN
由于经过AE后图片质量会下降,如果经过AE的reconstruction error越低,就可以认为generator生成的质量越好,经过discriminator后的得分也就越高。
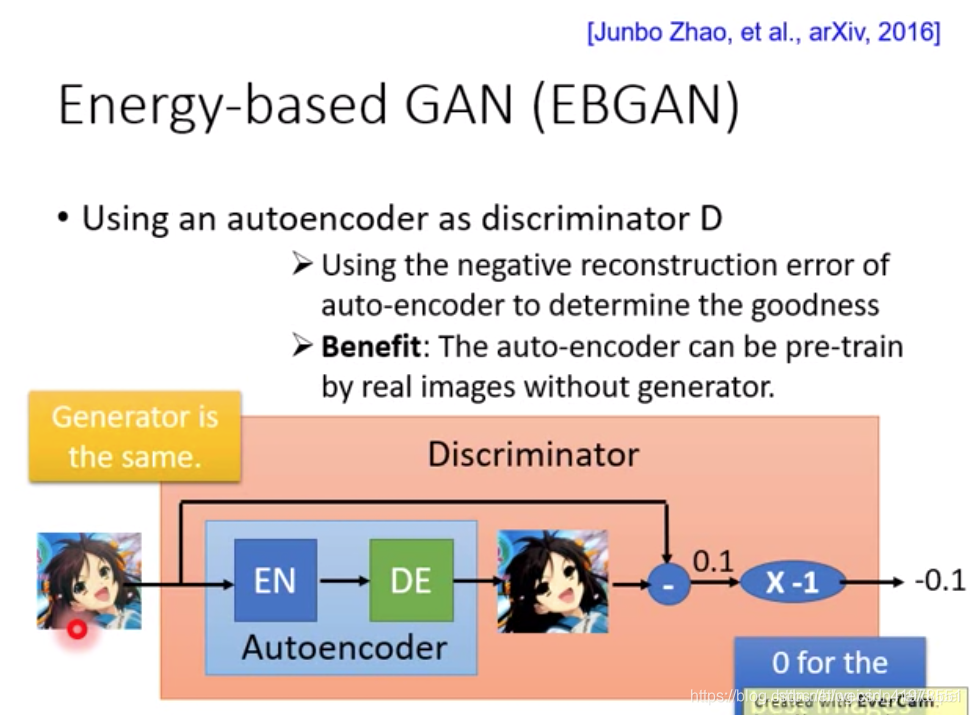
其好处在于我们可以使用real data来pre-train这个autoencoder
以前的discriminator训练是从样本数据里面sampling一些real data,从generator中sampling一些fake data来作为训练集的。这样存在的问题就是刚开始generator生成的数据很弱,因此训练出来的discriminator也很弱,这样就会导致前期generator成长的很慢。














 2802
2802











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









