







在李宏毅GAN教程(3) 的基础上增添修改内容
为了让GAN容易训练
JS散度不是很适合
最原始的GAN量的是Pg和Pdata之间的JS散度;但是有一个严重的问题:可能两个分布没有任何的重叠,一方面的原因是由于image在高维空间中的分布其实是低维的流形(二维平面折叠在三维空间中),高维空间中的低维流形几乎是可以忽略的,高维空间中随意抽样只有非常小的范围是图片;另一方面,在衡量Pg和Pdata的散度的时候,我们是从两个分布中sample得到两堆data,再去量他们之间的散度,即使计算分布有重叠,但是抽样出的data之间是没有重叠的,我们完全可以视data的得到的分布没有任何交集(可以用弯曲的线划开)

由于Pg和Pdata没有任何的重合,JS散度会有很大的问题?
只要两个分布没有重叠,不管他们是不是接近,算出来的JS散度就是log2。例子如图:虽然G1比G0更接近Pdata,但是从JS散度看起来,两者是没有差别的。这样的话,train起来是有问题的;(实际上在训练的时候,我们的生成器的目标是最小化Pg和Pdata之间的散度,然后你用判别器量出散度,但是对生成器来说Pg0和Pg1是一样的,因此生成器不会将Pg0更新为Pg1.)

下面从直觉角度看:为什么只要两个分布没有重叠,散度就是log2.
我们是怎样求两个分布的散度的呢?实际上的操作是:我们有两群data,把它视为两个class,然后判别器就是一个二元分类器,然后最小化交叉熵损失;只要两堆数据没有重合,就能够很好地分成两类,那么他们的loss就是一样的,这意味着量出来的JS散度是一样的。
在原始GAN里面,当你train的是一个二元分类器时,你会发现是比较难以train的,因为没有重叠就是一样差的。 
另外一个直观的想法是:当你learn一个二元分类器的话,会给蓝色的点0分,绿色点1分;output是sigmoid函数,在接近0或1的地方特别平,原本是希望Generator可以顺着红色的线把蓝色的点往右移,更接近真实图像,但如果用二分类做discriminator的话,蓝色点附近的梯度都是零,蓝色的点几乎是不动的。 过去一个方法是不要把二元分类器训练的特别好(??),太好了就梯度为0了。 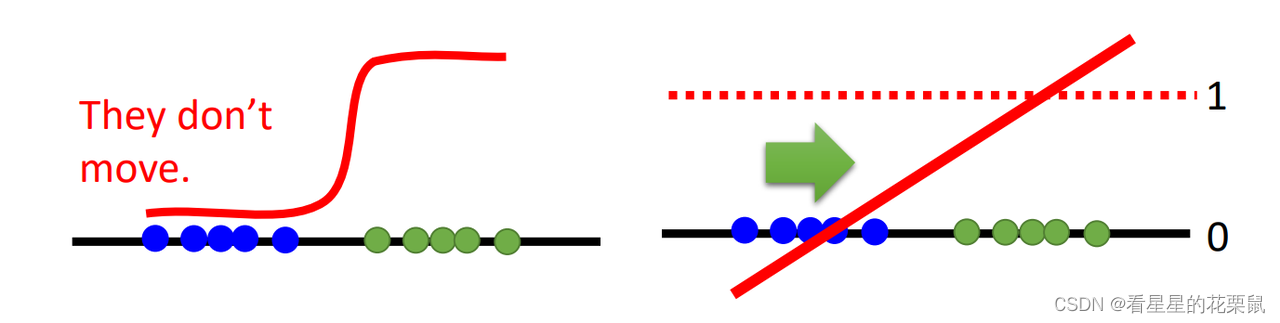
原本是希望Generator可以顺着红色的线把蓝色的点往右移,更接近真实图像。但如果用二分类做discriminator的话,蓝色点附近的梯度都是零,点不会移动。
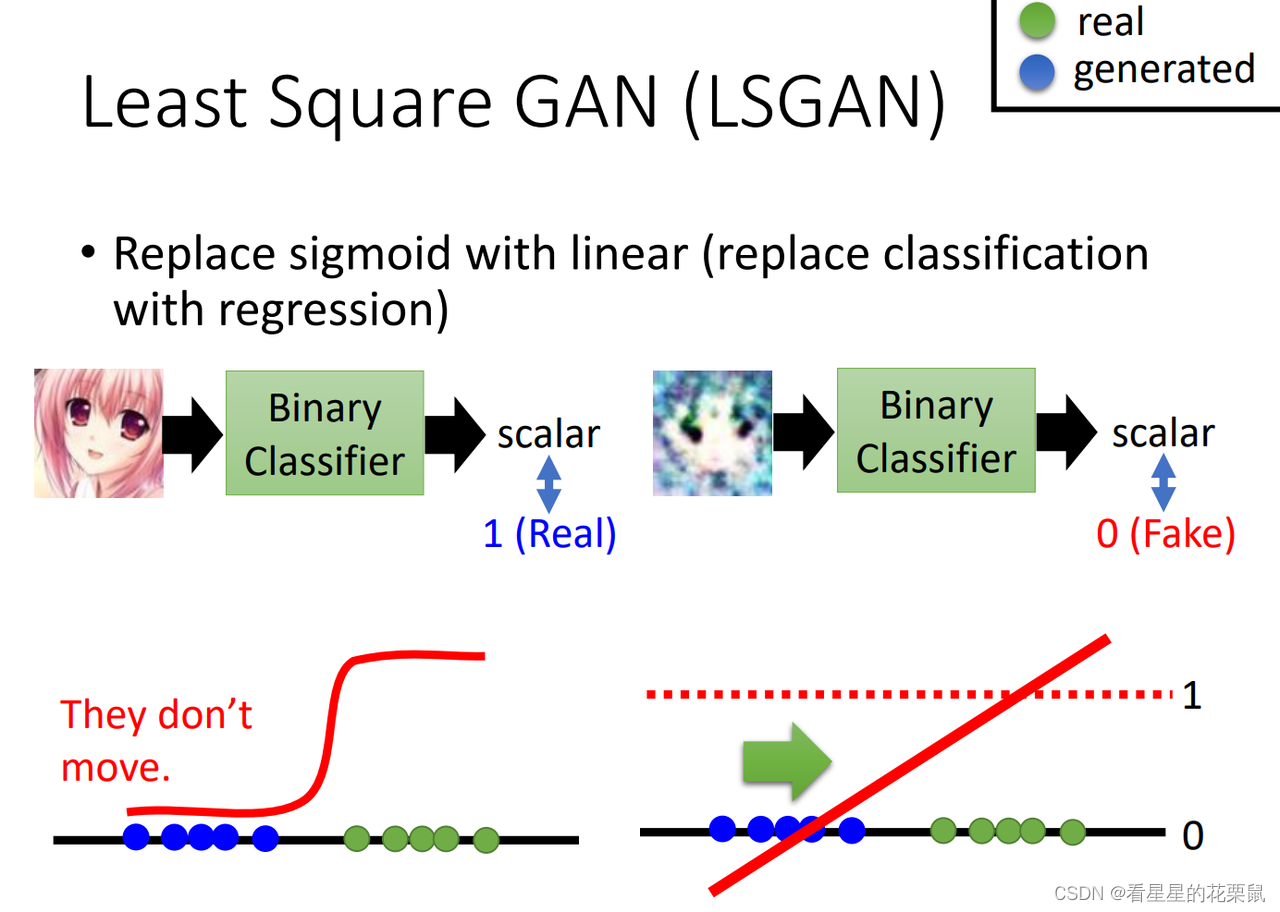
LSGAN
将输出的sigmiod换成linear,从分类问题,变成了回归问题。正样本越接近1越好,负样本越接近0越好。
二、Wasserstein GAN (WGAN)
可以用任何其他的F divergence,(WGAN其实不属于F divergence,不属于f GAN)。
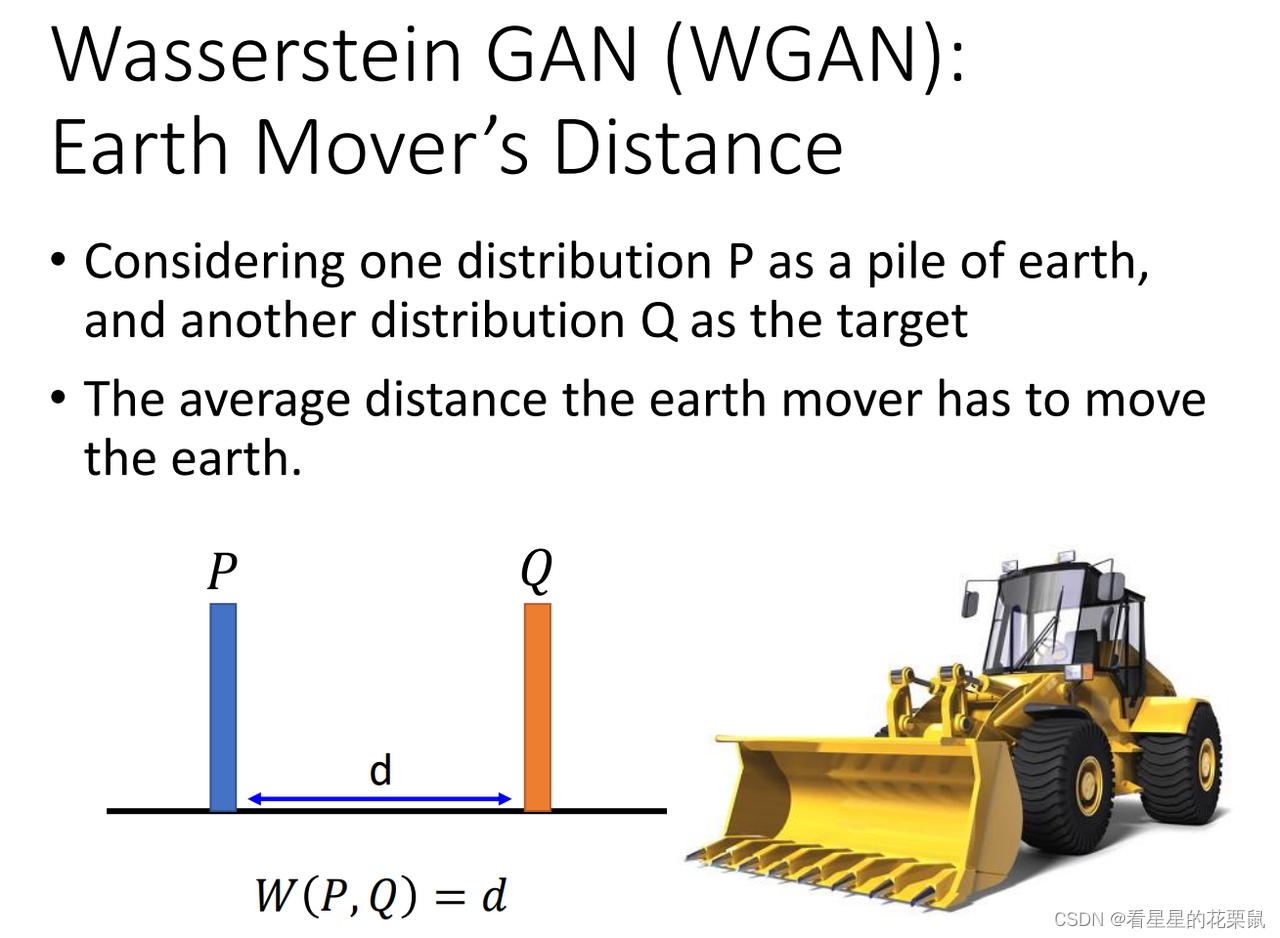
换一种方式来衡量Pg和Pdata,用的是Wasserstein distance /earth mover’s distance; 意思是假设你有两堆data P 和 Q,而你开着一个推土机,将 P土 推到 Q土 ,移动的平均距离就叫Wasserstein distance。
出现一个问题:同样的分布,推土机可能走过的路程不一样,
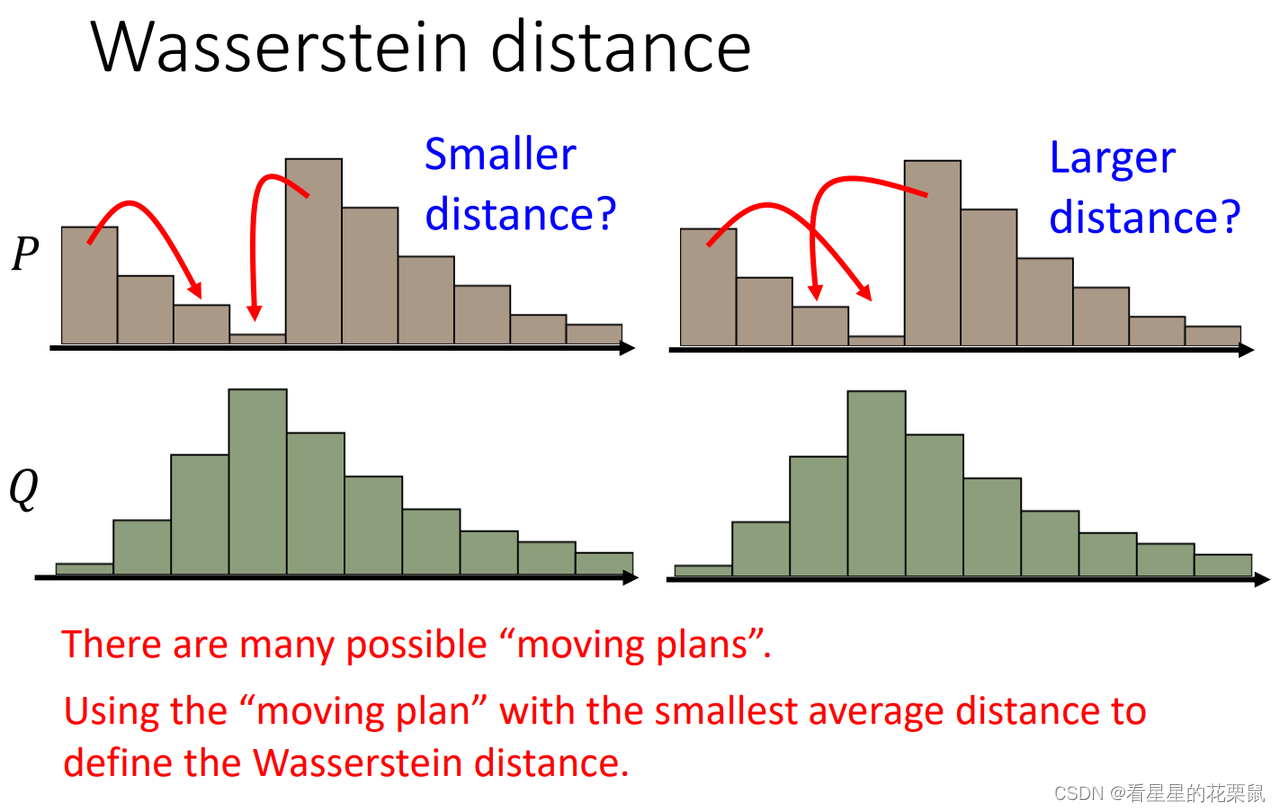
有很多移动土的方法,穷举所有可能的铲土的方法(moving plan),哪个方法的距离最小,就是earth mover’s distance。
更正式的定义:想要把P挪到Q;我们首先要定义一个moving plans,其实就是一个矩阵,每一个元素指的是从纵坐标的挪多少土到横坐标;越亮表示挪的图越多。(这里先不管两个位置的距离)
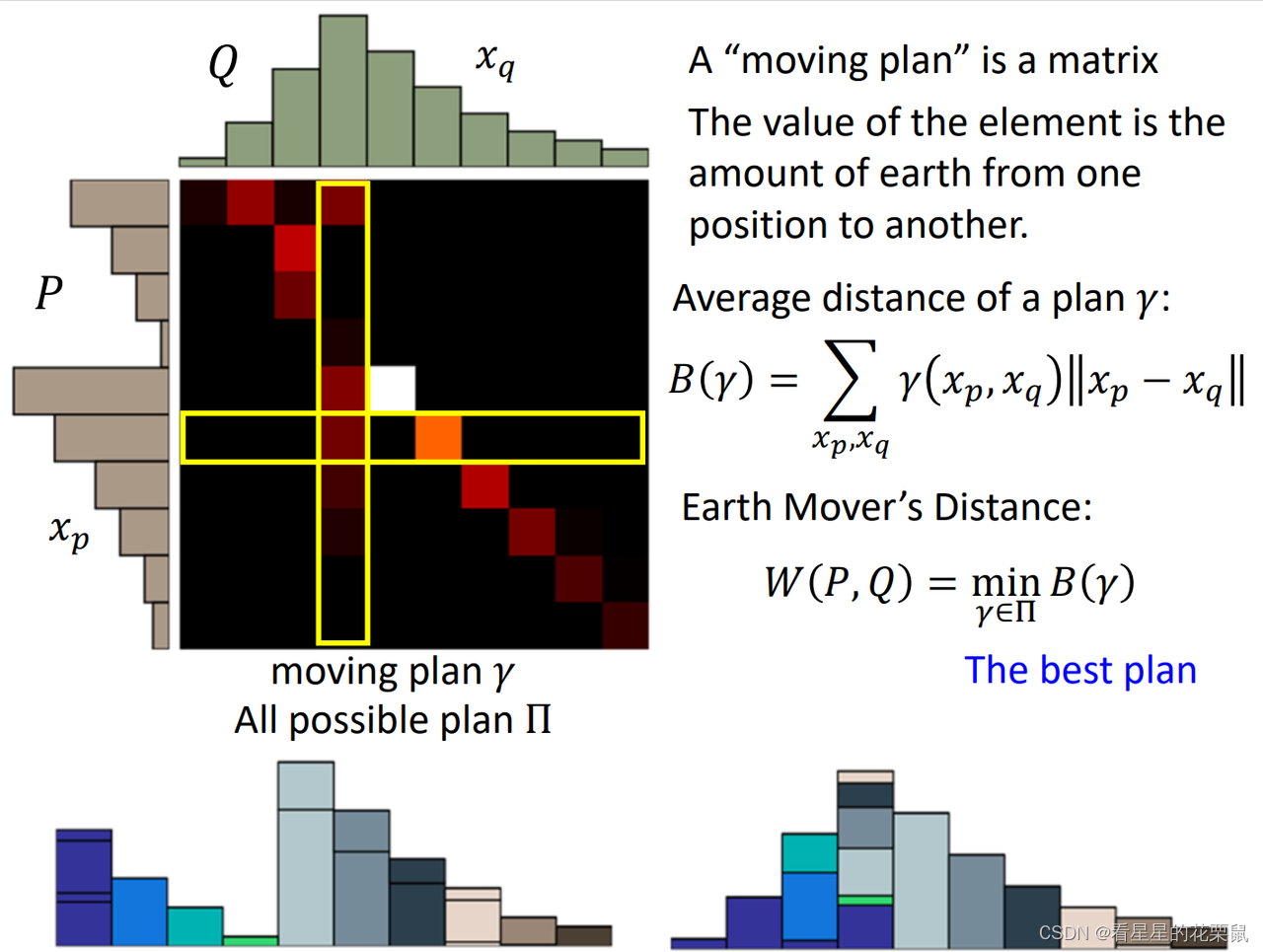
假设给你一个moving plans,叫做gamma;每个格子代表要移动的土,每行加起来就是左边P的高度,每列加起来就是上面Q的高度。那么根据它所走的距离是多少呢?
穷举所有的位置:
γ
(
x
p
,
x
q
)
\gamma(x_p,x_q)
γ(xp,xq)每个位置你要挪多少土,然后再算xp与xq之间的距离。
接下来,穷举所有的gamma,看哪个gamma最小,就是Wasserstein distance。所以算W distance是非常复杂的,每次都要解一个optimization problem。
使用JS散度的时候,不重叠都是log2;当使用W散度的时候,当两个分布虽然不重叠但是当距离变小的时候,散度也变小。

我们怎样改判别器,才能使判别器得到的结果是wassertein distance呢?(最大化之前的V(也就是二分类训练)得到的结果是衡量JS散度的)我们怎样改V才能使最大化V是wassertein distance呢?
- 如果y是从Pdata中sample出来的,让它的判别器输出越大越好;
- 如果y是从PG中生成的,让它的判别器输出越小越好;
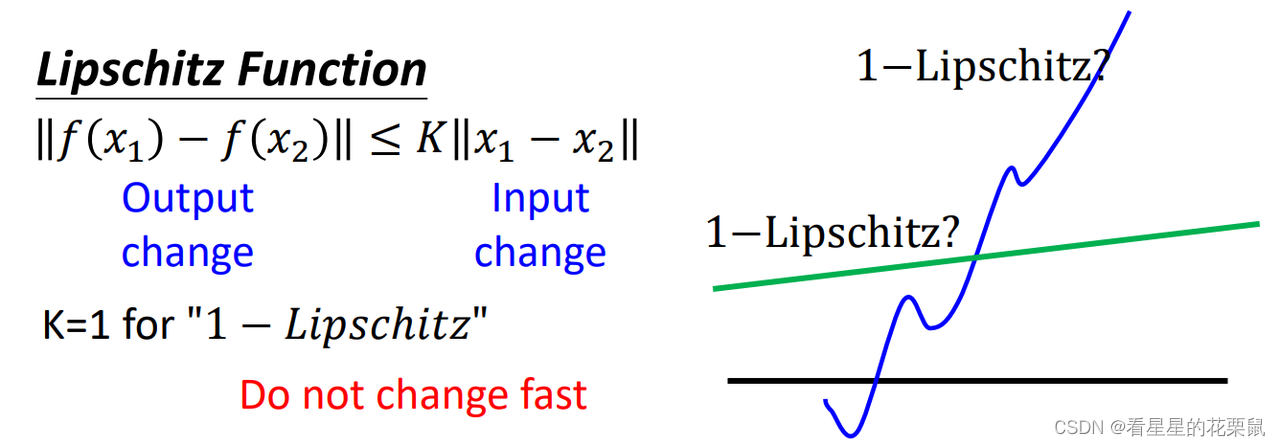
除此之外,还要有一个约束,就是判别器必须是一个1-Lipschitz函数;一个重要特点就是它很平滑
如果没有这个约束,判别器一味着让:real的分数就越来越高,generated的分数越来越低;那么就崩溃了,永远不会收敛(高度可以一直变化到无穷大无穷小)
因此必须有额外的限制,让判别器必须是平滑的

意思是说discriminator是平滑的,不可以变动很剧烈。也就是说如果real和generated距离很近的话就不可以差异很大,如果距离很远,他们的值就可以差很多。
Lipschitz函数:input之间的差距乘K要大于等于output之间的差异,也就是说output差距不能太大。
当K=1的时候就是1-Lipschitz函数,output变化比input小。
怎样来训练这个判别器网络呢?
1、weight clipping(最原始的方法,稍微限制了平滑性,没有限制在1-Lipschitz)
仍然使用梯度上升来max V 但是当你发现某个参数w大于你设定好的c就设定为c,小于你设定好的-c就设定为-c

2、improve WGAN(WGAN-GP)
Gradient 的penalty。如果一个函数是1-Lipschitz的话,等价于:每一个位置的gradient的norm都小于等于1;
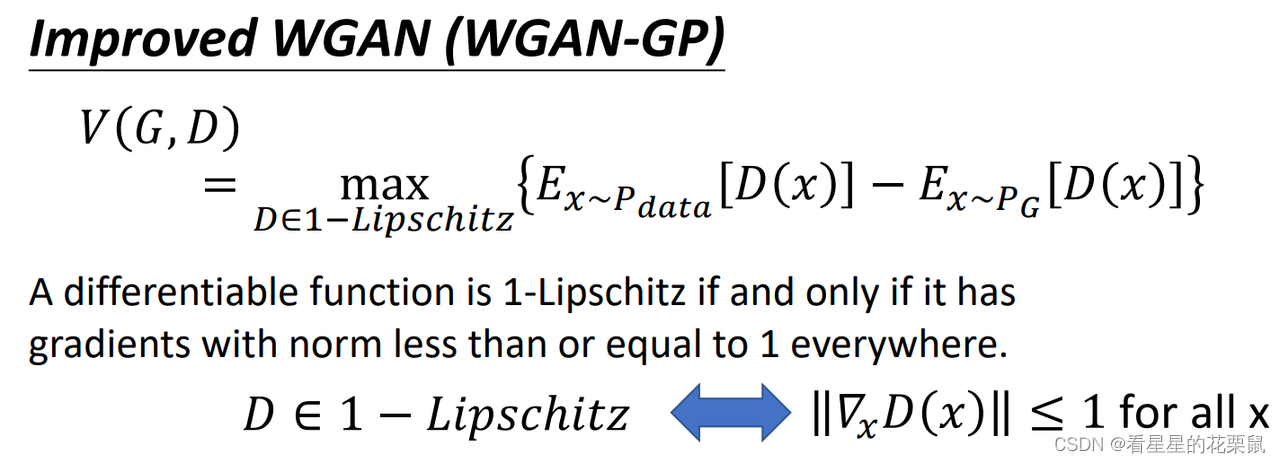
近似等价于:在原来的这项后面加上一个正则化项,对所有的x做积分,被积函数是:如果梯度范数小于等于1,这一项为0,否则为梯度范数减1。希望梯度范数对所有的x都要满足小于1;
但是我们不能对所有x积分,因此我们是假设X是从某一个事先定好的分布中Ppenalty中sample出来的,只管这部分的x,其他的就不管了。
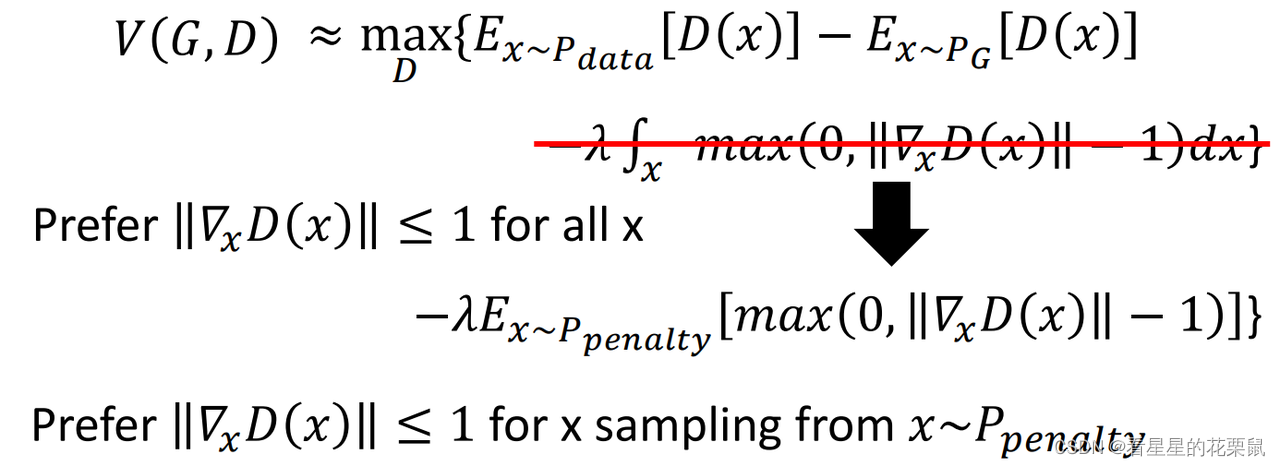
Ppenalty长什么样子呢?
就是从Pdata和Pg选取两个点,连成直线,从直线间sample当作Ppenalty中的x;为什么可以只对中间部分penalty呢?因为我们是想让PG往Pdata移动,PG是看着中间部分的斜率移动的,只有中间的区域才会影响结果,才需要考虑discrimination的形状。

除此之外,本来我们希望的是梯度的范数如果大于1,给它惩罚;小于1 不用惩罚;实际上我们在训练的时候是希望范数越接近1越好。收敛更快
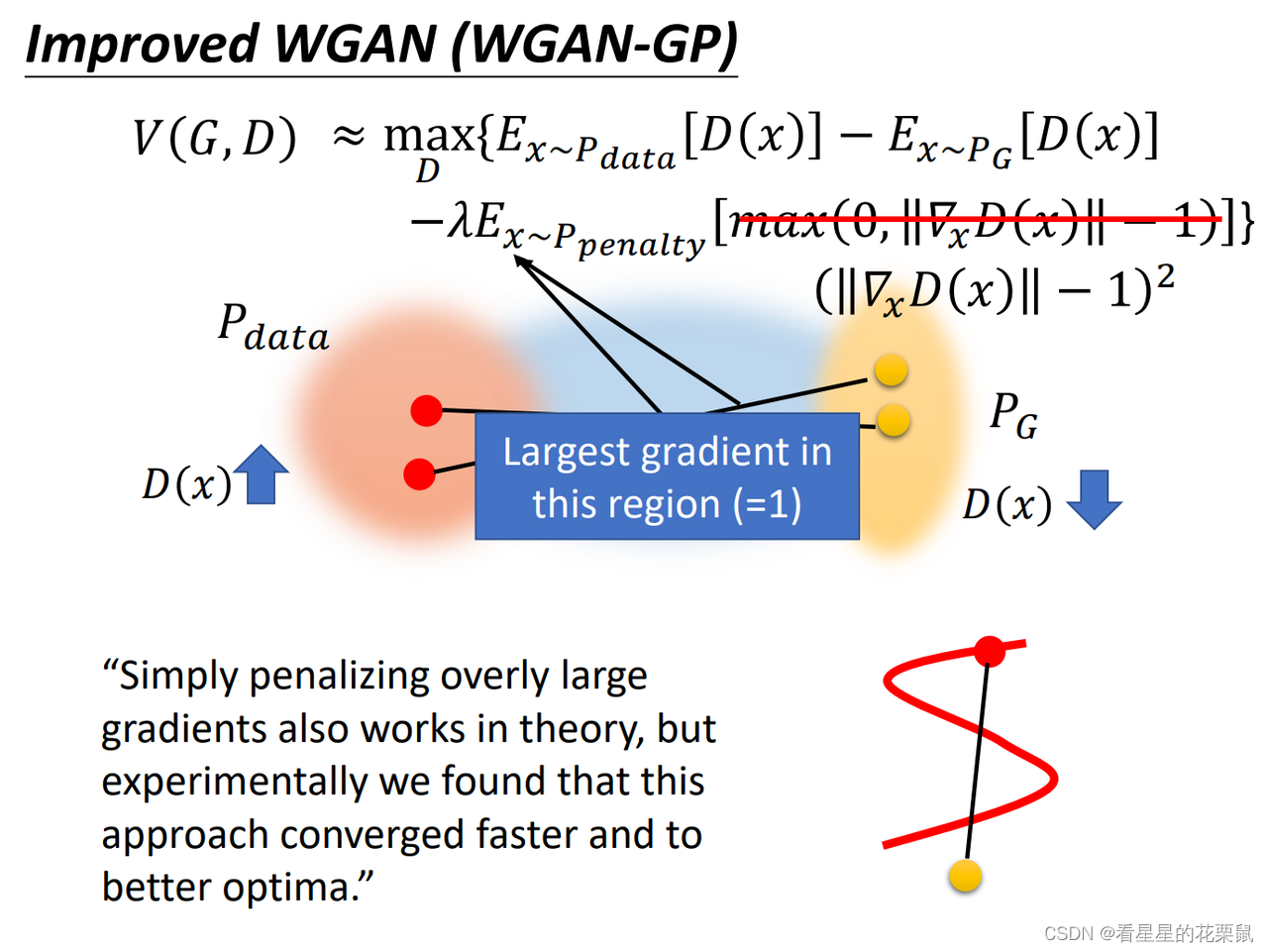
其实好像应该选择在data中抽取的样本中,与生成样本最近的点,只penalize这两个点之间的gradient。也有人说gradient penalty应该在P_data区域
3、Spectrum Norm(SNGAN)
真的可以限制discriminator在每一个位置的梯度范数都小于1(之前只是大概限制了某个范围内的):

怎样从GAN 改成 WGAN
我们首先看一下原始GAN 的算法:

WGAN: 要改四个地方:
1、改V,log去掉
2、 sigmoid拿掉变成线性
3、加上正则化项,Weight clipping/Gradient Penalty,否则可能不收敛
4、改生成器更新公式

EBGAN
把判别器从二分类器改成了 autoencoder。算auto encoder的reconstruction error重建误差,用负的重建误差作为判别器的输出
认为一张图片能被reconstruction的越好,质量越高
好处:二分类器需要正负样本同时输入进行训练,无法pre-train,只能逐渐变强;但是autoencoder的判别器可以pre-train,可以只用正样本进行预训练,让它minimize reconstruction error就好;一开始的判别器会很强,这样你的生成器一开始就会产生很好的image;
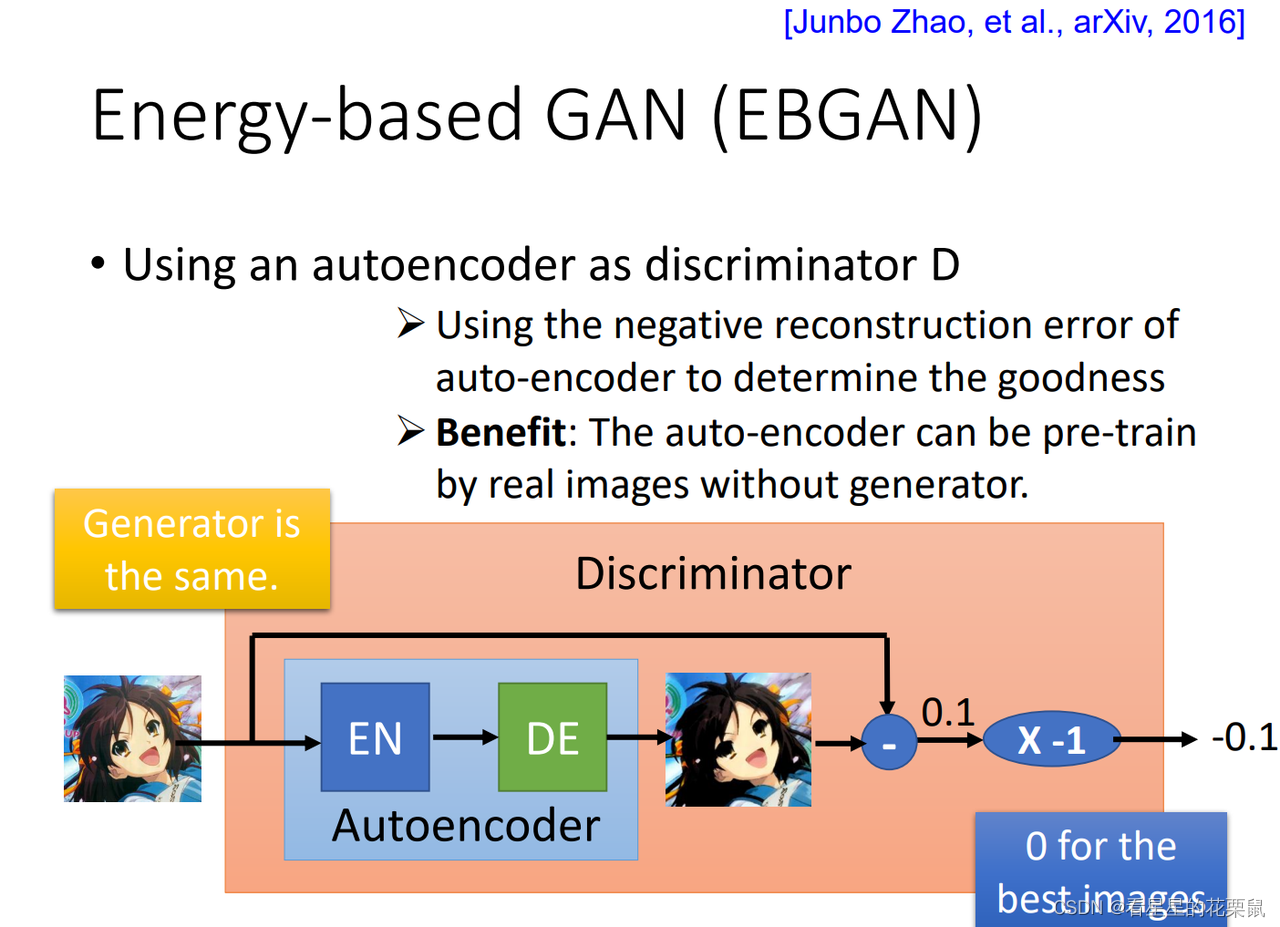
要注意的地方:并不是让generated的example分数越小越好,或是reconstruction error越大越好。
因为建设比较难但是破坏很简单,如果目标是最大化重建误差的话,会导致discriminator看到什么图片都输出噪声。
实际训练的时候,会设置一个参数当小于时就定值。margin要手动调。

LSGAN(Loss-sensitive GAN)
加了margin,希望x’分数很低,x’'分数只要低于margin就好

仍然存在的问题
Discriminator无法分辨差异,generator就无法生成更准确的图片,二者其中一个无法进步时另一个也无法进步了。而且训练中无法调整超参数。

GAN for Sequence Generation
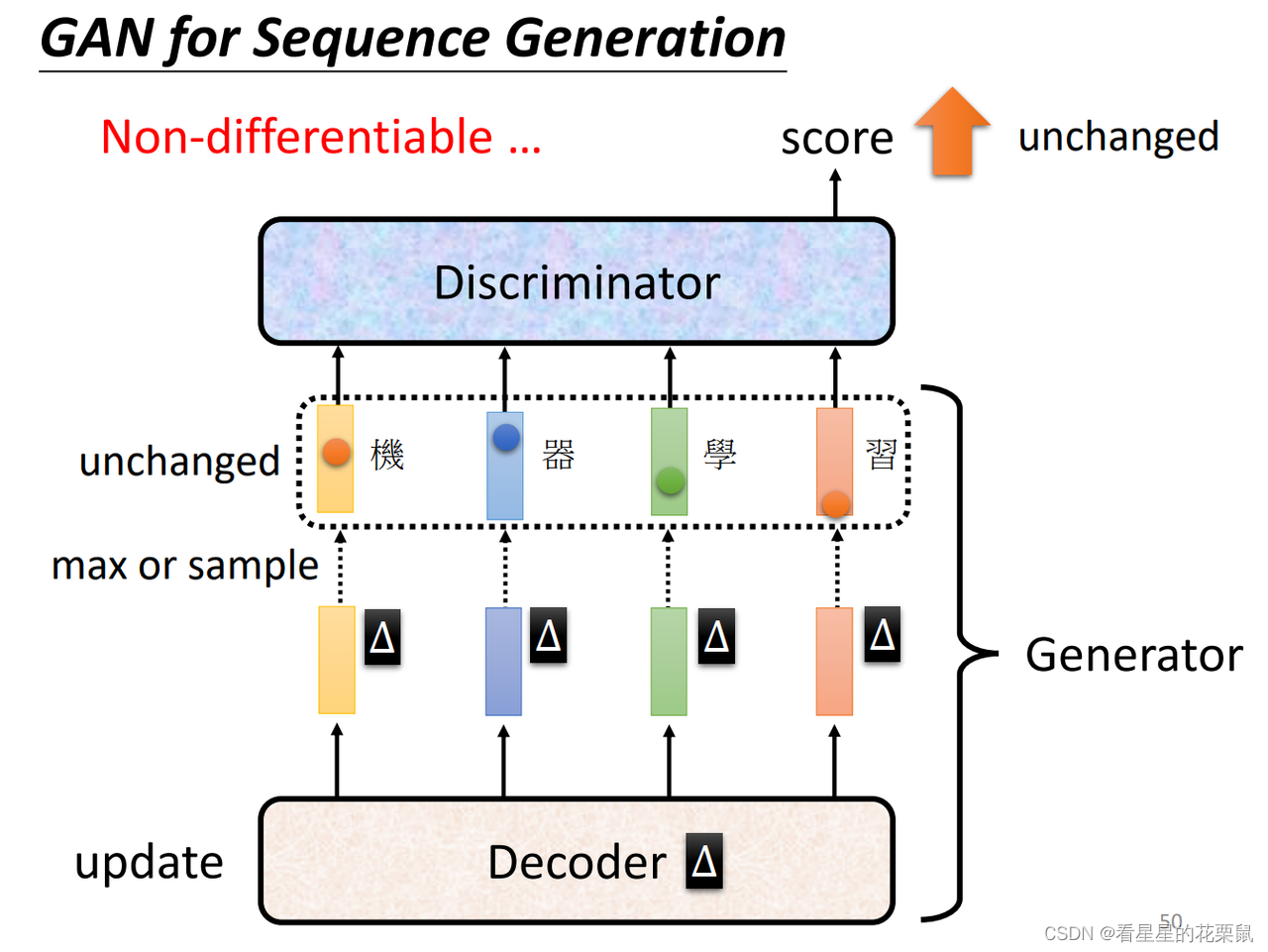
token:自己定义的,类似于词元,每次生成的单位
Decoder的参数发生小变化的时候,可能并不会对token的最大输出产生影响,所以discriminator的结果可能是没有变化的,这种情况下没有办法做gradient descent。
在做max polling的时候,我们知道哪个元素导致了这个最大值,在做back propagation的时候,只需要考虑这一个元素即可,其他元素置零。而对于GAN来说,我们不知道是哪个元素导致了这些字的输出。
不能用gradient descent的问题可以就当做reinforcement learning,RL+GAN很难训练
















 6176
6176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









