







一.Performance
作者开篇就声明本书的一些方法并不适用所有情况。某些方法只在特定的数据量或者key分布有用。一个简单的例子是,当我们使用groupByKey时很容易就造成内存异常问题,但是对于一些有少量重复数据的情况,使用本书一些方法的效果比起使用这个算子,速度是一样的。所以理解数据结构,以及Spark如何与数据交互,是解决复杂问题的关键。
二.How Spark Fits into the Big Data Ecosystem

Spark是运行在分布式存储系统(eg:HDFS)和集群管理(YARN)之上的分布式计算框架。
三种集群管理器:
- Standalone – spark自带的简易管理器.
- Apache Mesos – 一个通用的集群管理
- Hadoop YARN – the resource manager in Hadoop 2.
三.Spark Components and Cluster Mode
Spark组件:Spark Core(RDD) Spark SQL(DataFrames/Datasets) MLlib GraphX
1.Spark Cluster Mode

流程说明:SparkContext(driver program)来负责统一管理,SparkContext可连接到不同的集群管理器(Spark’s own standalone cluster manager, Mesos or YARN),集群管理器负责分布资源(根据application的配置参数),链接之后在节点中得到executors,executors为applications执行计算和存储数据的工作,集群管理器将application代码(defined by JAR)发送到executors,最后SparkContext向executors发送task。
这种架构值得注意的点有:
1.每一个application拥有自己的executor流程,在application整个生命周期被占用,executor以多线程的形式执行tasks。这样不同applications独立,但数据不同共享(除非写入外部存储)
2.Spark对cluster manager不强依赖,cluster manager可并行处理其他应用
3.driver program整个生命周期监听executors(client模式driver program是在cluster manager中的cluster manager也因此不同宕停)
4.driver program调度tasks,因此driver应该和worker nodes物理连接靠近,最好在本地网络域,远程最好开RPC。
1.Application :基于Spark的应用程序 = 1 driver + executors
User program built on Spark.Consists of a driver program and executors on the cluster.
eg:spark0402.py pyspark/spark-shell
Spark applications依次运行多个并发Jobs(每个action对应一个Job)
2.Driver program:
The process running the main() function of the application,creating the SparkContext
3.Cluster manager:
An external service for acquiring resources on the cluster (e.g. standalone manager, Mesos, YARN)
eg:spark-submit --master local[2]/spark://hadoop000:7077/yarn
4.Worker node
Any node that can run application code in the cluster
standalone: slave节点 slaves配置文件
yarn: nodemanager
5.Executor:为applications执行计算和存储数据的工作
A process launched for an application on a worker node
runs tasks
keeps data in memory(内存) or disk(磁盘) storage across them
Each application has its own executors.
2.Spark Application
一个Spark application涉及到Spark Jobs的集合,这些jobs是在driver程序中被SparkContext定义。Spark application随着SparkContext启动开始。当SparkContext启动时,集群worker nodes上的a driver和一系列executors也随着启动。每一个executor都拥有自己的JVM,并且虽然每个节点可以拥有多个executors,但是一个exectors不能跨节点。
SparkContext决定每个executors会被分配多少资源,每个executor都有用于运行计算rdd所需任务的位置。

四.RDDs
1.RDD的概念
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是spark中最基本的数据抽象,它代表一个不可变,可分区,里面的元素可以并行计算的集合
Dataset:就是一个集合,用于存放数据的
Distributed:分布式,可以并行在集群计算
Resilient:表示弹性的,弹性表示
RDDs储存在executors(or slave nodes)上
由于RDD的不变性,在RDD基础上使用transformation操作将不会修改之前的RDD,而是返回一个新的RDD对象。
RDD可以通过三种方式创建:
- 通过transformaing一个存在的RDD
- 从一个SparkContext对象中创建(Spark application的API入口)
- 通过一个DataFrame或者Dataset对象转化
2.RDD的特性:
1.partitions
一个 RDD 会有若干个分区,分区的大小决定了对这个 RDD 计算的粒度,每个 RDD 的分区的计算都在一个单独的任务中进行

2. a function for computing each split/partition 作用在每一个分区中的函数 eg:y=f(x)-->rdd.map()
3.dependencies (rdd1==>rdd2==>rdd3==>rdd4)
一个RDD依赖于其他多个RDD,这个点很重要,RDD的容错机制就是依据这个特性而来的。
DAG-有向无环图:原始的RDD通过一系列转换就形成了DAG,描述RDD的依赖关系。
窄依赖:每一个 parent RDD 的 partition 最多被子 RDD 的一个 partition 使用(一子一亲) eg:map filter
宽依赖:多个子 RDD 的 partition 会依赖同一个 parent RDD的 partition(多子一亲) eg:groupByKey reduceByKey

4.Optionally,a Partitioner for key-value RDDs(eg:to say that the RDD is hash-partitioned):可选的,针对于kv类型的RDD才有这个特性,作用是决定了数据的来源以及数据处理后的去向
5.可选项,数据本地性,数据位置最优
五.Lazy Evaluation and in-memory storage
1.Lazy Evaluation:
Spark在执行action之前,不会开始计算partitions。actions会激发scheduler(调度程序),从而建立一个基于RDD之间transformation的有向无环图DAG。然后,scheduler可以用一系列步骤,被称为execution plan,来计算每一阶段的缺失partitions。
注意:不是所有transformations都是100%lazy的.sortByKey需要数据的范围,所以它同时涉及到transformation和action
Lazy机制的优势:
- 效率提升:lazy机制让Spark可以去结合那些不需要与driver交互的操作(transformation),从而避免额外的数据访问。例如:Spark可以发送map和filter命令到每个executor,然后在每一个partition上执行这两个命令。这个过程只需要访问数据一次,是原来计算复杂度的一半。
- 更简单使用:同样逻辑使用Spark要比MapReduce实现更简单
2.In-Memory Persistence and Memory Management:
比起MapReduce,Spark的性能优势最大的时候在于涉及到重复计算的情况。性能的增加主要是因为Spark使用了in-memory persistence(持久性),而不是每次访问数据都要写入硬盘。Spark可以选择把executors中的数据加载到内存(RDD.persist),然后每个partition上的数据每当被访问时都可以通过内存获取。
Spark内存管理方式
Spark提供了三种不同的内存管理方式,每一种都有不同的空间和时间上的优势:
序列与反序列化:
把对象转换为字节序列的过程称为对象的序列化
把字节序列恢复为对象的过程称为对象的反序列化
对象的序列化主要有两种用途:
1) 把对象的字节序列永久地保存到硬盘上,通常存放在一个文件中;
2) 在网络上传送对象的字节序列。在很多应用中,需要对某些对象进行序列化,让它们离开内存空间,入住物理硬盘,以便长期保存。比如最常见的是Web服务器中的Session对象,当有 10万用户并发访问,就有可能出现10万个Session对象,内存可能吃不消,于是Web容器就会把一些seesion先序列化到硬盘中,等要用了,再把保存在硬盘中的对象还原到内存中
- in-memory as deserialized data(反序列化) Java objects: 这是最快的一种方式,因为减少了序列化时间,但不是最省内存的方式,因为它把数据作为对象储存起来.
- in-memory as serialized data(序列化):用Java标准的序列化库,把Spark对象转化成字节流。
- on disk(硬盘):对于有些partitions因为太大而不能储存在内存中,就可以写入disk。这个策略对于重复操作会变慢,但是对于长序列的transformations具有更高的容错性,同时对于庞大的计算量,这种策略可能也是唯一可行的选择。
persist():
待补充...
六.Spark Job Scheduling
1.Resource Allocation(资源分配) Across Applications
Spark提供了两种资源分配方式:静态static和动态dynamic
静态分配:每一个application被分配到的节点资源是有限的,在application持续期间(只要SparkContext还在运行)。
动态分配:executors可以依需要被添加或者删除。
七.DAG的生成和Spark的任务调度
1.The Anatomy(分析) of a Spark Job
对于每一个action,Spark scheduler会建立一个执行图,同时发起一个Spark job。每一个job由若干个stages组成。
每个Stages是task的集合,tasks代表了在executors上执行的并行计算任务。

2.DAG
DAG(Directed Acyclic Graph)叫做有向无环图,原始的RDD通过一系列的转换就形成了DAG,根据RDD之间依赖关系的不同将DAG划分成不同的Stage(调度阶段)。
对于窄依赖,partition的转换处理在一个Stage中完成计算。
对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算,因此宽依赖是划分Stage的依据。
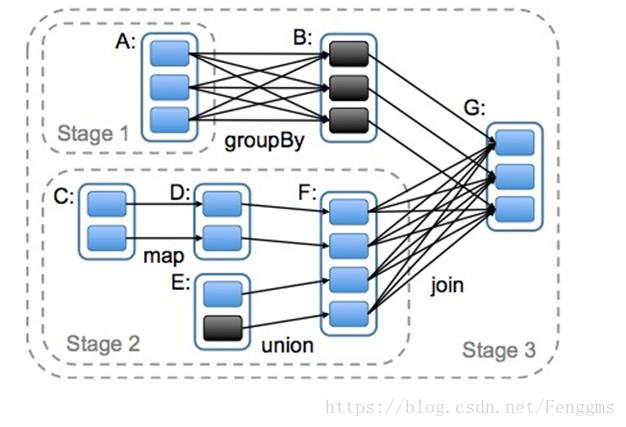
3.任务调度流程
各个RDD之间存在着依赖关系,这些依赖关系就形成有向无环图DAG。
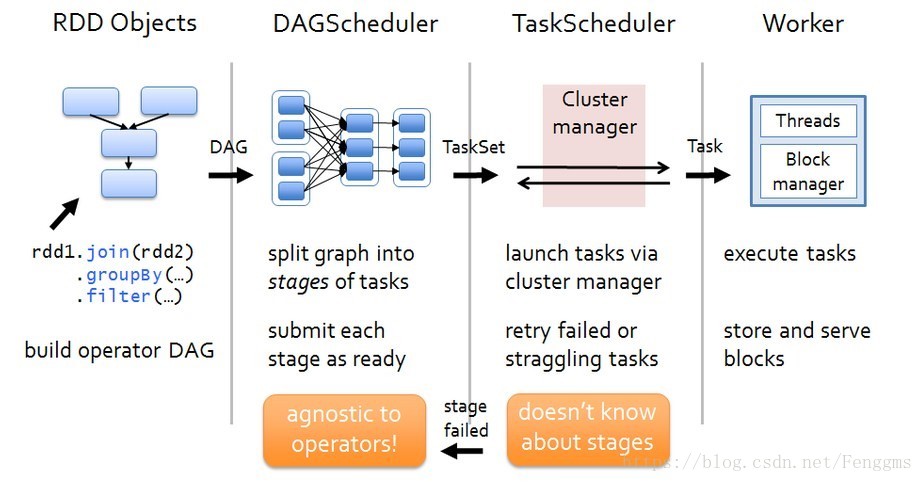
DAGScheduler对这些依赖关系形成的DAG进行Stage划分,划分的规则很简单,从后往前回溯,遇到窄依赖加入本stage,遇见宽依赖进行Stage切分。完成了Stage的划分。DAGScheduler基于每个Stage生成TaskSet,并将TaskSet提交给TaskScheduler。TaskScheduler 负责具体的task调度,最后在Worker节点上启动task。














 1996
1996











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









