







论文内容关键在于两点:
1.CLR提出了一种在神经网络训练中设置global learning rates的方法,用来解决手动实验去寻找最优学习率的问题,不需要额外的计算,且通常需要更少的迭代次数。它就是让学习率在迭代过程中周期性变化,而不是固定的值。
2.如何去估计CLR中的超参,如周期长度(cycle length)和边界值(boundary values)。
1.Cyclical Learning Rates
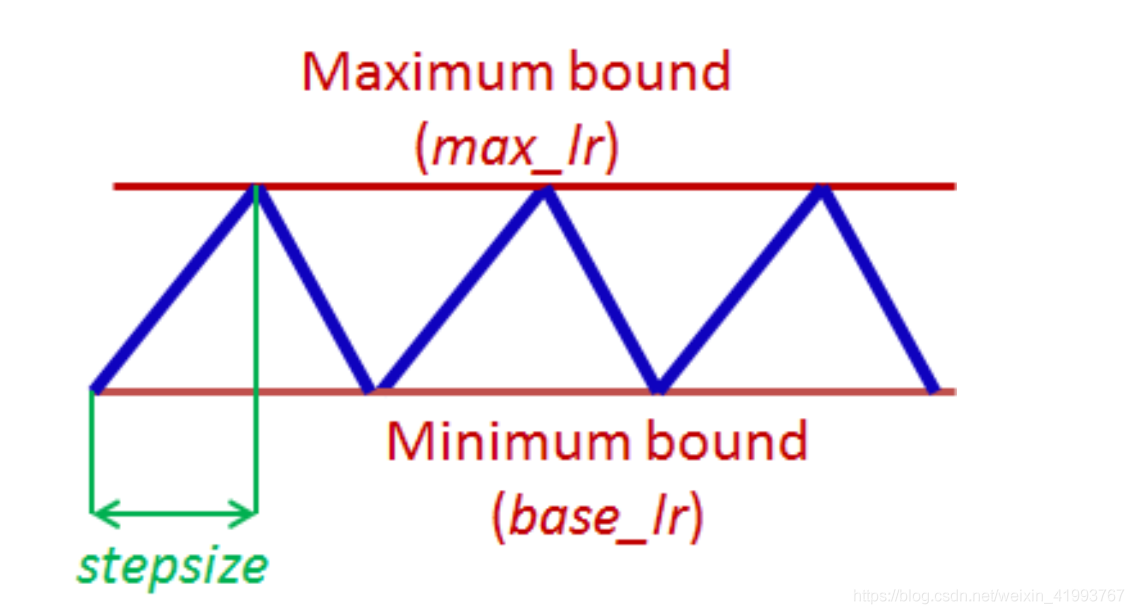
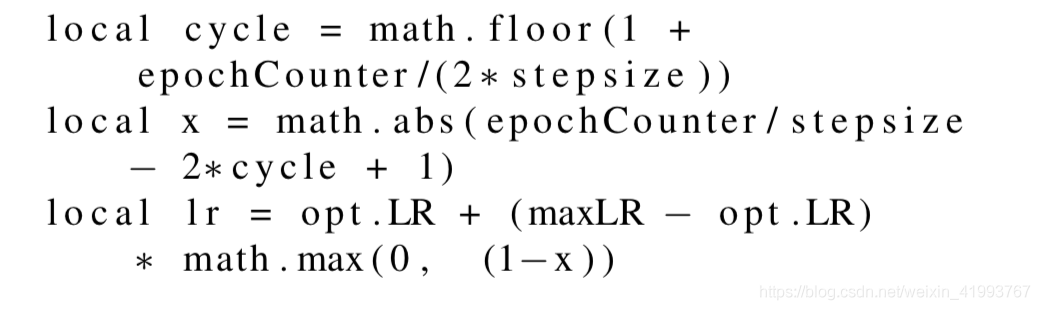
上图是Triangular learning rate policy(线性增加和减少),我们来看看计算式中的参数含义。
1.opt.LR是指定的最小学习率,等于图中的base_lr
2.epochCounter是当前epochs数
3.lr是当前用于迭代的学习率
4.stepsize是周期长度(cycle length)二分之一
5.max_lr是最大学习率,等于图中的max_lr
当epochCounter=stepsize时,x=0 lr=maxLR;当epochCounter=2*stepsize时,x=1,lr=base_lr;随着epochCounter的增加学习率在边界范围内周期变化。
另外两种策略如下

2.估计CLR中的超参
(1)cycle length = 2*stepsize
epoch = 训练集样本量/batchsize
stepsize等于2~10的epoch
(2)boundary
通过绘制accuracy VS learning rate,例如下图
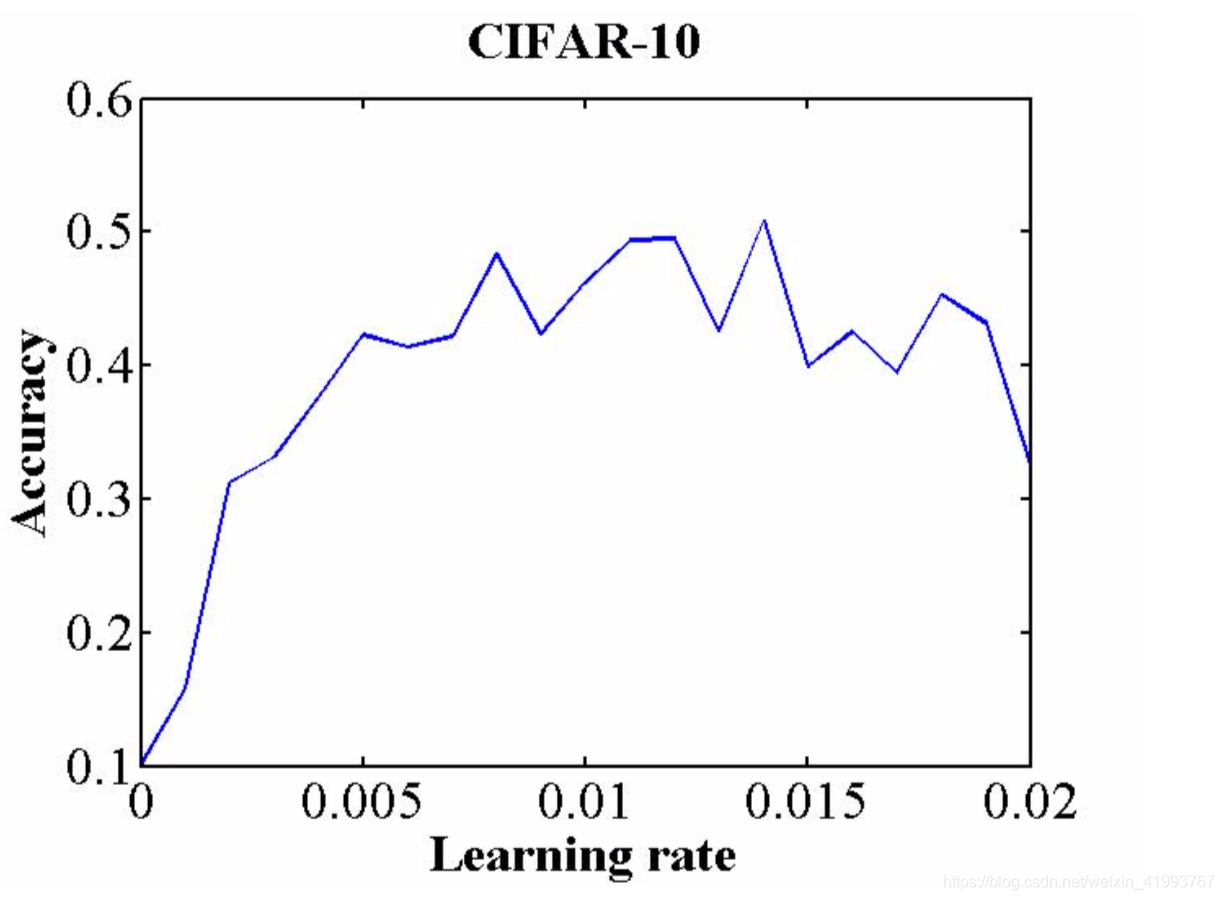
注意到准确率开始迅速增加的临界点和开始下降或者发生波动的临界点,这两种临界点就是边界值,base_lr和max_lr。
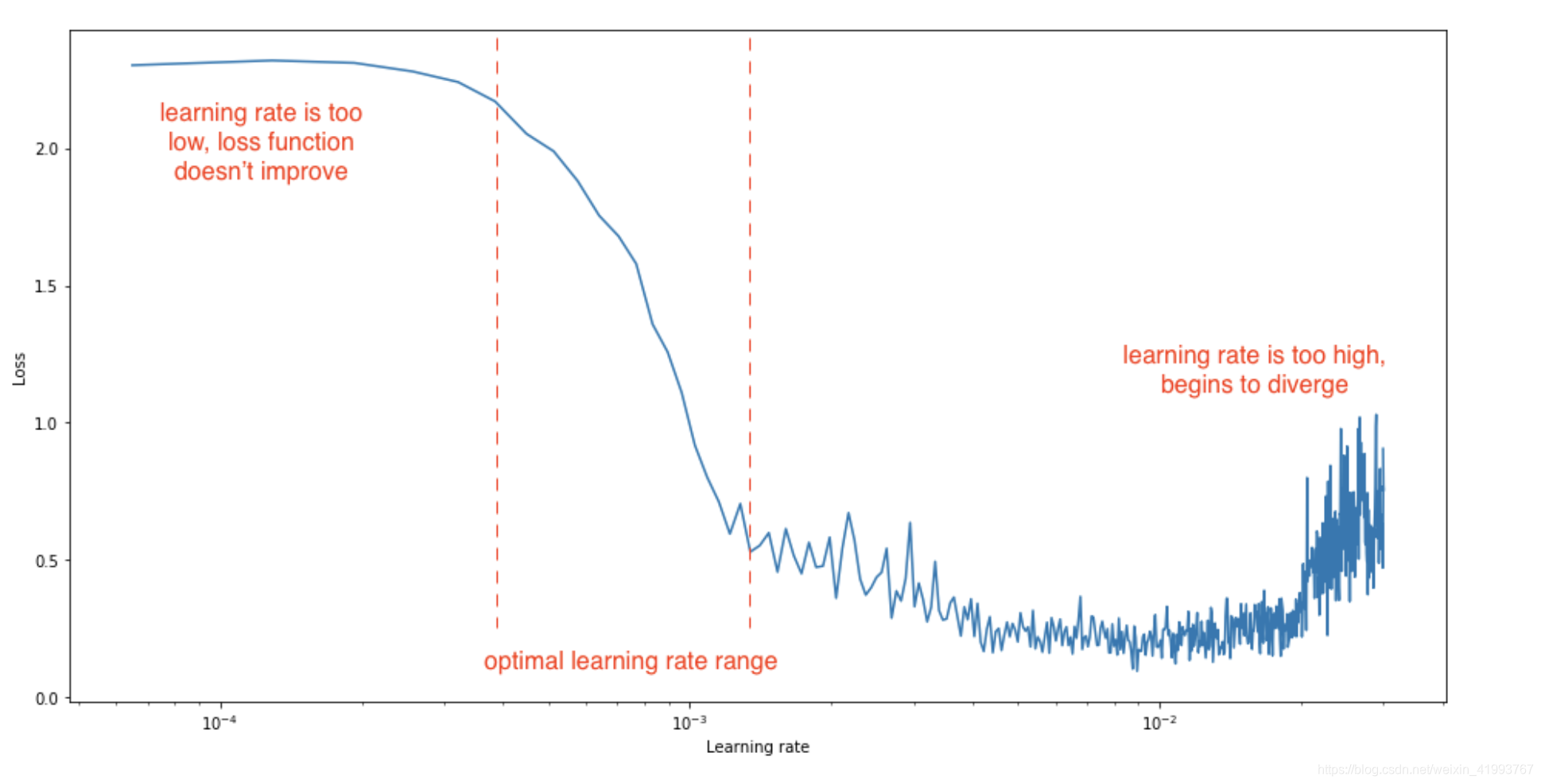
更一般的学习率和损失函数关系如下图
3.Pytorch中CLR的实现
# code inspired from: https://github.com/anandsaha/pytorch.cyclic.learning.rate/blob/master/cls.py
class CyclicLR(object):
def __init__(self, optimizer, base_lr=1e-3, max_lr=6e-3,
step_size=2000, mode='triangular', gamma=1.,
scale_fn=None, scale_mode='cycle', last_batch_iteration=-1):
if not isinstance(optimizer, Optimizer):
raise TypeError('{} is not an Optimizer'.format(
type(optimizer).__name__))
self.optimizer = optimizer
if isinstance(base_lr, list) or isinstance(base_lr, tuple):
if len(base_lr) != len(optimizer.param_groups):
raise ValueError("expected {} base_lr, got {}".format(
len(optimizer.param_groups), len(base_lr)))
self.base_lrs = list(base_lr)
else:
self.base_lrs = [base_lr] * len(optimizer.param_groups)
if isinstance(max_lr, list) or isinstance(max_lr, tuple):
if len(max_lr) != len(optimizer.param_groups):
raise ValueError("expected {} max_lr, got {}".format(
len(optimizer.param_groups), len(max_lr)))
self.max_lrs = list(max_lr)
else:
self.max_lrs = [max_lr] * len(optimizer.param_groups)
self.step_size = step_size
if mode not in ['triangular', 'triangular2', 'exp_range'] \
and scale_fn is None:
raise ValueError('mode is invalid and scale_fn is None')
self.mode = mode
self.gamma = gamma
if scale_fn is None:
if self.mode == 'triangular':
self.scale_fn = self._triangular_scale_fn
self.scale_mode = 'cycle'
elif self.mode == 'triangular2':
self.scale_fn = self._triangular2_scale_fn
self.scale_mode = 'cycle'
elif self.mode == 'exp_range':
self.scale_fn = self._exp_range_scale_fn
self.scale_mode = 'iterations'
else:
self.scale_fn = scale_fn
self.scale_mode = scale_mode
self.batch_step(last_batch_iteration + 1)
self.last_batch_iteration = last_batch_iteration
def batch_step(self, batch_iteration=None):
if batch_iteration is None:
batch_iteration = self.last_batch_iteration + 1
self.last_batch_iteration = batch_iteration
for param_group, lr in zip(self.optimizer.param_groups, self.get_lr()):
param_group['lr'] = lr
def _triangular_scale_fn(self, x):
return 1.
def _triangular2_scale_fn(self, x):
return 1 / (2. ** (x - 1))
def _exp_range_scale_fn(self, x):
return self.gamma**(x)
def get_lr(self):
step_size = float(self.step_size)
cycle = np.floor(1 + self.last_batch_iteration / (2 * step_size))
x = np.abs(self.last_batch_iteration / step_size - 2 * cycle + 1)
lrs = []
param_lrs = zip(self.optimizer.param_groups, self.base_lrs, self.max_lrs)
for param_group, base_lr, max_lr in param_lrs:
base_height = (max_lr - base_lr) * np.maximum(0, (1 - x))
if self.scale_mode == 'cycle':
lr = base_lr + base_height * self.scale_fn(cycle)
else:
lr = base_lr + base_height * self.scale_fn(self.last_batch_iteration)
lrs.append(lr)
return lrs4.Pytorch中CLR类的使用
model = NeuralNet()
model.cuda()
loss_fn = torch.nn.BCEWithLogitsLoss(reduction='sum')
step_size = 300
base_lr, max_lr = 0.001, 0.003
optimizer = torch.optim.Adam(filter(lambda p: p.requires_grad, model.parameters()),lr=max_lr)
################################################################################################
scheduler = CyclicLR(optimizer, base_lr=base_lr, max_lr=max_lr,
step_size=step_size, mode='exp_range',
gamma=0.99994)
###############################################################################################














 2583
2583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









