









本人公众号上线啦!!!
公众号与博客名一样:没有腹肌的程序猿
公众号文章类型:工作上所遇到的需求实现方案分享。
此外也会提供一些数据集供大家使用。(这个还在规划中,毕竟打工人时间挺紧的,哈哈哈哈)
到时候也会不定期给大家抽一些小东西哦。
python爬虫之requests
request是python爬虫的一个基本的库,功能十分齐全。
下面对一些常用的方法进行说明:
(response----指接受返回的响应)
-
requests.get(url,params,headers)
url:发送请求的链接。 params:携带的参数。 headers:头部信息。 -
requests.post(url,data,headers)
url:发送请求的链接。 data:携带的json参数。 headers:头部信息。 -
response.raise_for_status
如果返回的状态码不是200,通过此方法能够抛出异常。 -
response.encoding
返回信息的编码格式。 -
response.apparent_encoding
解析返回数据是什么编码格式,一般使用方式 response.encoding = response.apparent_encoding。 通常用在爬取中文的网页,防止乱码。 -
response.json()
获取返回回来的json数据。 -
response.text
获取返回回来的html文本信息。 -
response.content
Html响应的二进制信息。
- 案例1:爬取百度网页
链接:https://www.baidu.com/
一般网站都有反爬机制,因此我们需要做最基本的UA伪装。
url = 'https://www.baidu.com/'
header = {
'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
}
response = requests.get(url=url, headers=header)
response.raise_for_status()
response.encoding = response.apparent_encoding
concent = response.text
print(concent)
- 案例2:爬取百度翻译
百度翻译链接:https://fanyi.baidu.com/?aldtype=16047#auto/zh
1.进入百度翻译后,我们随便输入一个单词,发现它是实时的局部刷新,因此我们可以打开控制台查看一下它发送的ajax请求,看看能不能通过该请求获得数据。
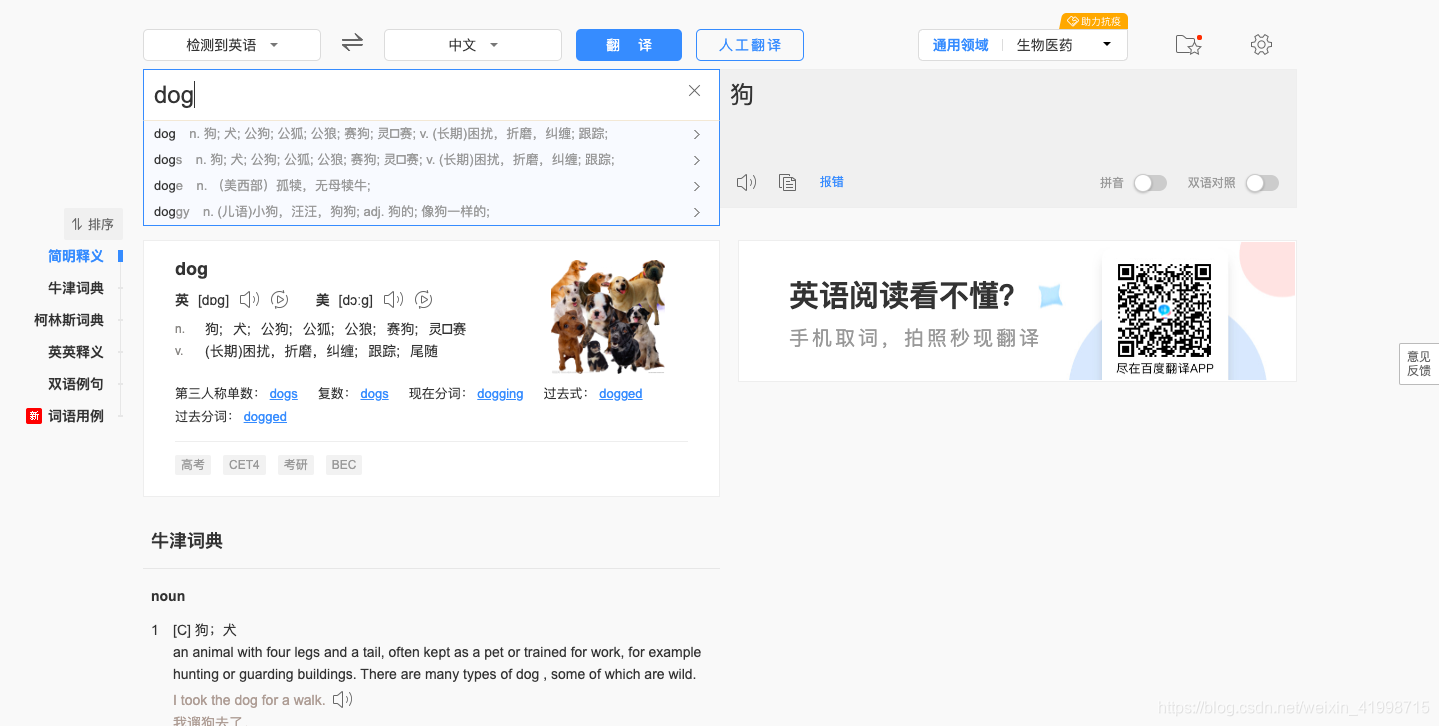
2.通过抓包分析,可以看到我们输入dog,三个单词,它就发送了三次请求。
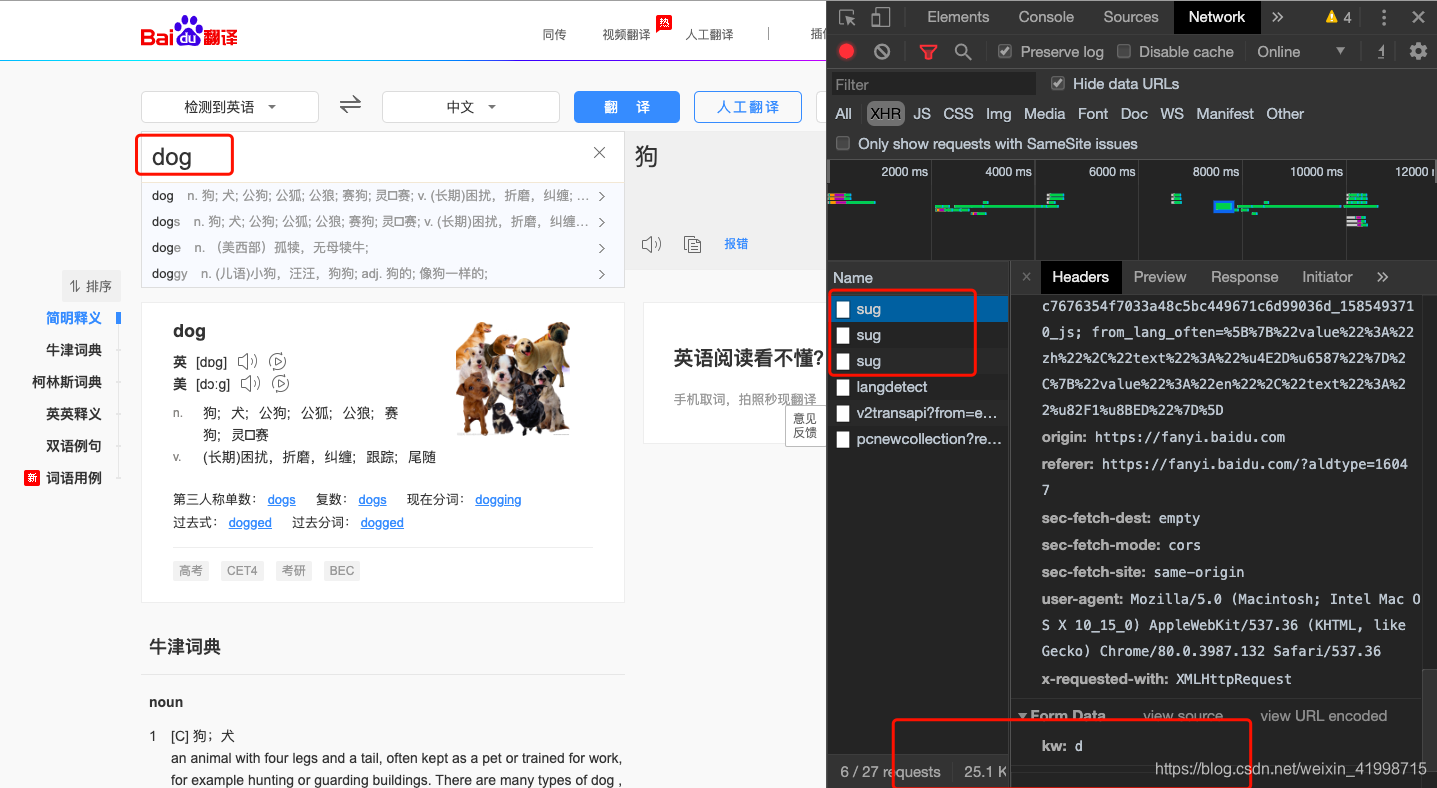
3.我们可以对该请求做进一步的分析。分析之后我们发现该请求是一个Post请求,且返回的数据是Json格式,也就是翻译后的内容的json格式。因此,我们只要向该链接发送请求我们就能获取到数据。
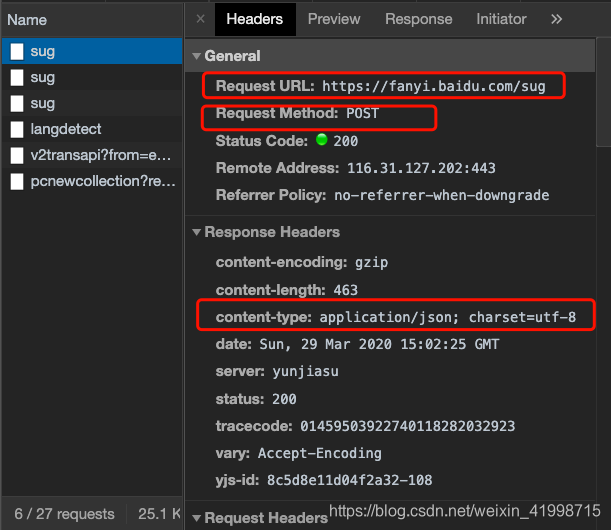
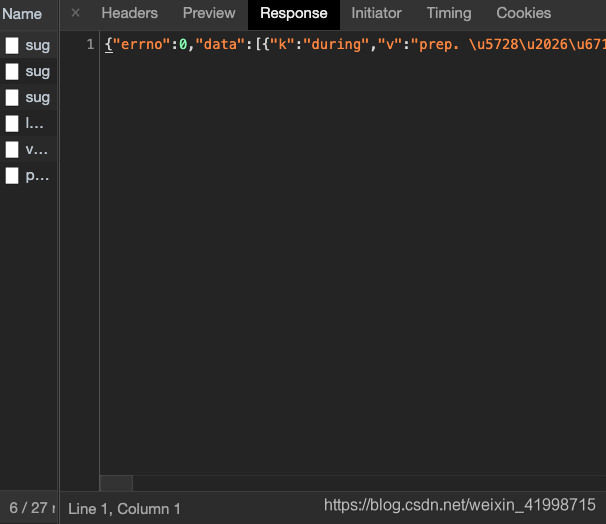
4.分析结束我们就可以编写代码。
#百度翻译
import json
url='https://fanyi.baidu.com/sug'
kw = input('enter you want fanyi')
kw = {
'kw':kw
}
header = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
}
response = requests.post(url=url, data=kw, headers=header)
response.raise_for_status
response.encoding = response.apparent_encoding
content_json = response.json()
#默认转成ascii编码,因此需要设置成false
content = json.dumps(content_json,ensure_ascii=False)
result = json.loads(content)
print(result["data"])
- 案例3:爬取豆瓣电影的排行榜
豆瓣网页:https://movie.douban.com/chart
1.随便进去一个分类
2.在这个页面将右侧的滚动轮拉到就下,页面就会自动刷新,发送ajax请求。通过抓包分析,我们可以发现该请求返回是json数据,也就是电影的json数据,且有发送的参数。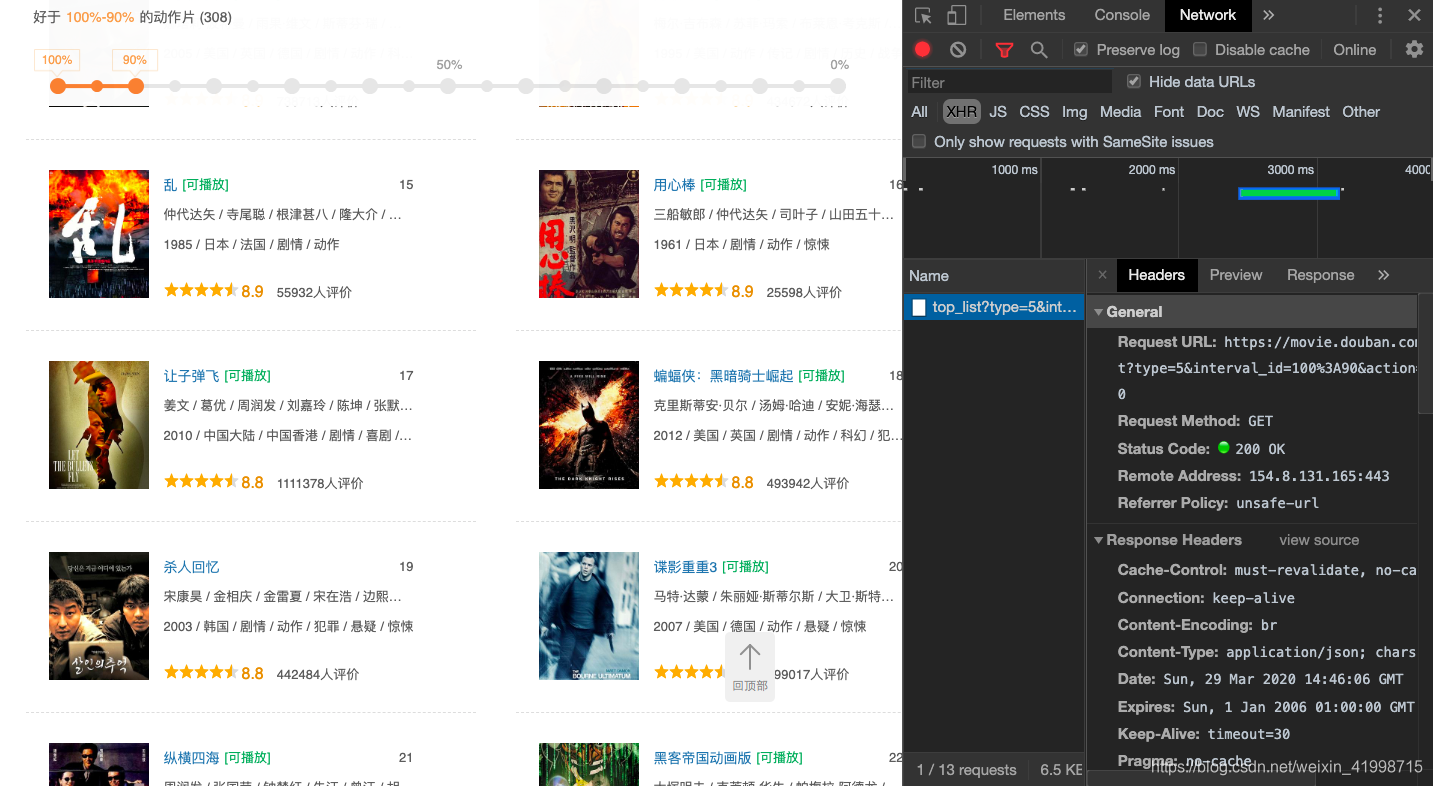
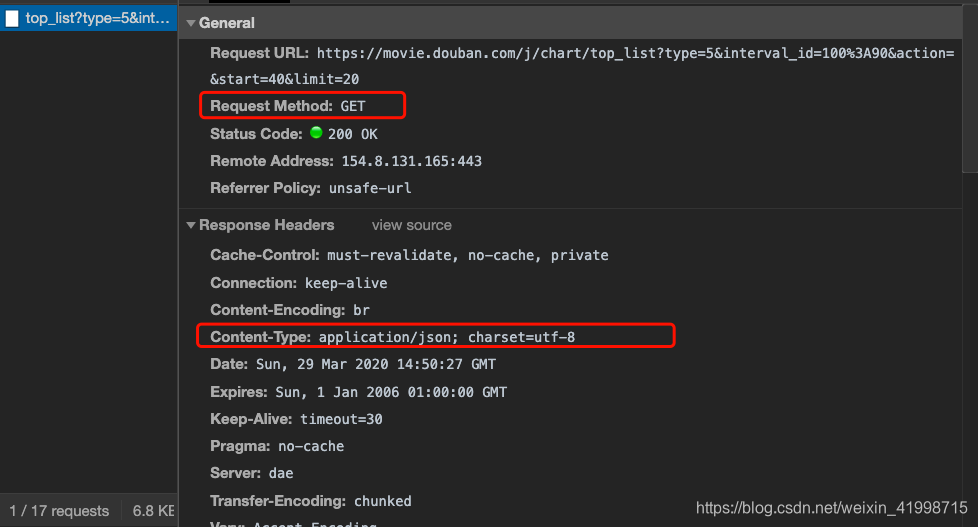
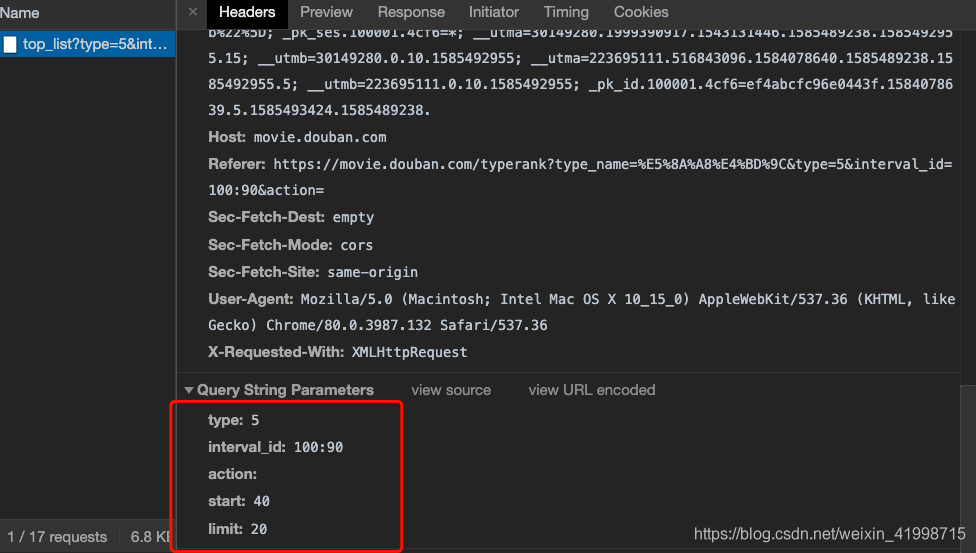
3.因此我们可以直接通过该链接跟参数直接发送请求获得数据。
#豆瓣电影排行
url = 'https://movie.douban.com/j/chart/top_list'
params = {
'type': '5',
'interval_id':'100:90',
'action': '',
'start':'0',
'limit': '20'
}
header = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
}
response = requests.get(url=url,params=params, headers=header)
content = response.json()
#在使用dumps时候,会默认将汉子转成ascii编码格式,因此我们需要手动设置成False
content1 = json.dumps(content,ensure_ascii=False)
print(content1)
案例四:爬取肯德基指定位置有多少家餐厅
肯德基链接:http://www.kfc.com.cn/kfccda/index.aspx
1.进入网页,进入餐厅查询页面。在页面的最下面。
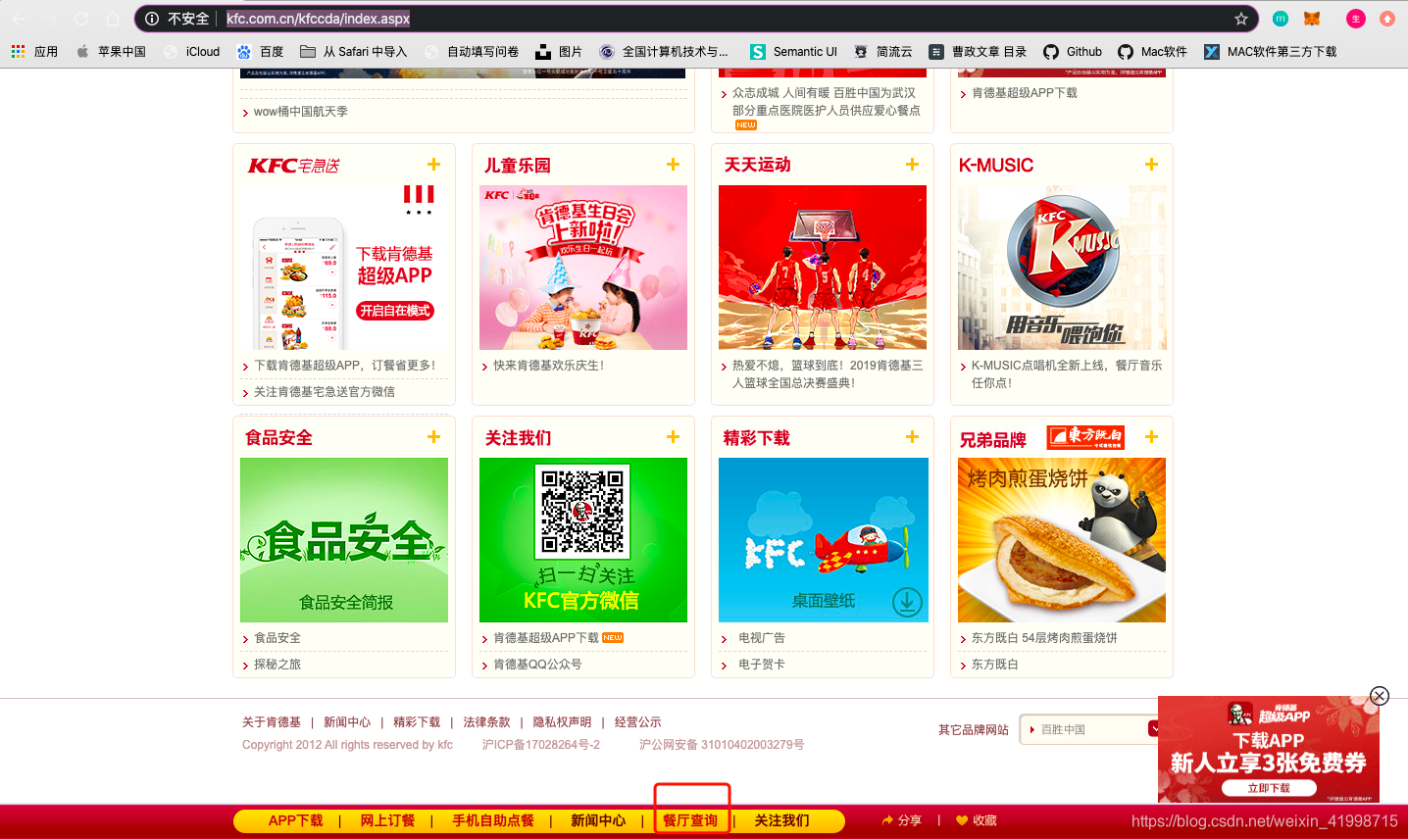
2.在该页面进行实验查询。通过实验发现,输入地名后点击查询,地址栏的url并没有发生变化,因此我们可以判断是通过ajax请求进行的局部页面的刷新。
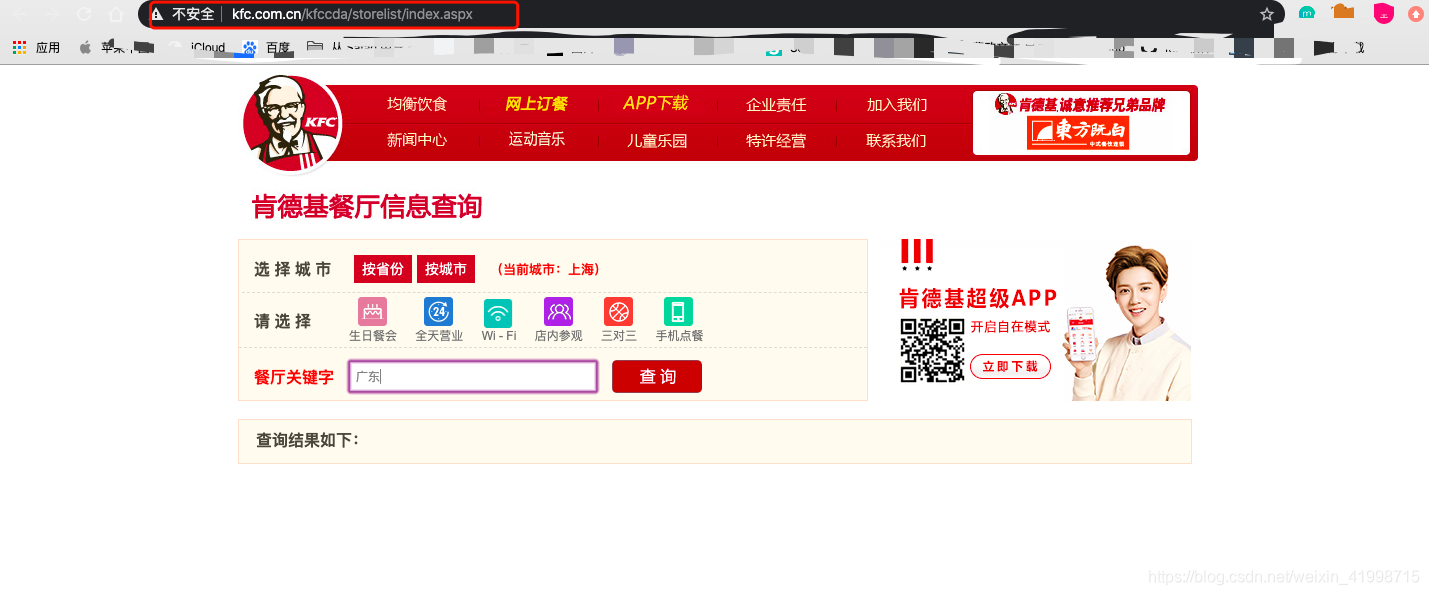
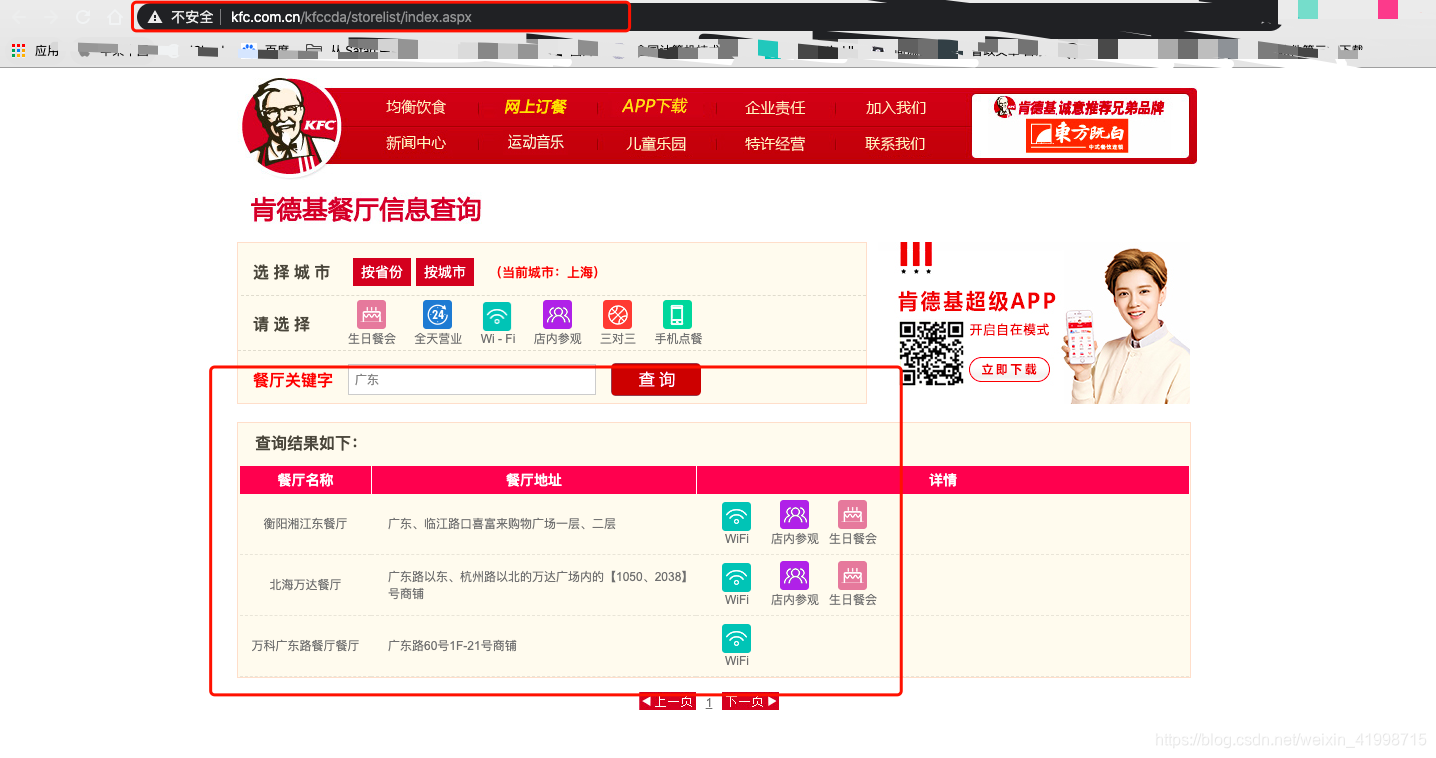
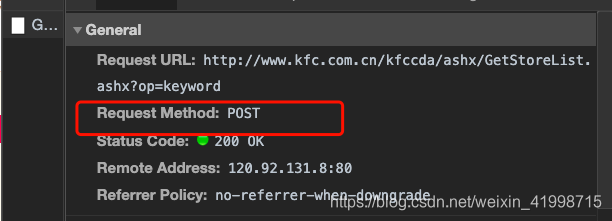
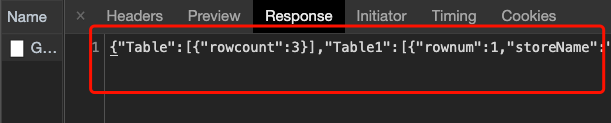
3.打开控制台进行分析,我们发现该请求是Post请求,且返回的json数据,查看json数据发现就是餐厅位置的信息。因此我们可以通过发送请求并携带参数进行获取数据。
4.编写代码。
#爬取肯德基指定位置有多少家餐厅。
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
keyword = input('请输入要查询的地名:')
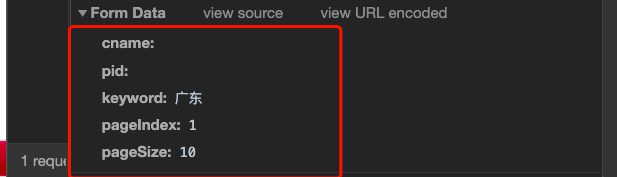
data = {
'cname':'',
'pid': '',
'keyword': '广东',
'pageIndex': '1',
'pageSize': '10'
}
header = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'
}
response = requests.post(url=url, data=data, headers=header)
content_json = response.json()
content_json = json.dumps(content_json,ensure_ascii=False)
result = json.loads(content_json)
rowcount = result['Table'][0]['rowcount']
print(rowcount)


















 770
770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









