









目录
前提
github:https://github.com/mouna99/dien/tree/1f314d16aa1700ee02777e6163fb8ca94e3d2810/script
阿里CTR模型三剑客即
(1)Deep Interest Network for Click-Through Rate Prediction
(2)Deep Interest Evolution Network for Click-Through Rate Prediction
(3)Deep Session Interest Network for Click-Through Rate Prediction
其中第一篇是DIN,第二篇就是DIEN,今天的主角就是DIEN,原理不在此论述,可以参考原论文或其他博客,本博客主要目的是看一下其代码逻辑。
关于DIEN的代码解读也有一篇了:[论文解读] 阿里DIEN整体代码结构_罗西的思考-CSDN博客
很详细了,笔者也参考了很多,这里再填充一下。
(1)我们开始想用一个模型的时候其实最重要的就是看懂其输入格式是什么?然后才可以适配自己的数据。
对应到当前代码,看懂data_iterator.py比较关键。
(2)再进一步我们想优化的话,就要看懂Model
对应到当前代码,就是script/model.py
在下面的介绍中,重点也是看上面两块。
总体代码:
prepare_data.sh
就是包括数据和数据的预处理脚本,处理后得到的数据就是data,data1,data2,所以我们可以直接跑啦,如果想看数据的处理逻辑可以看prepare_data中得逻辑。
解压完上述数据后大概会得到如下数据文件:
(1)cat_voc.pkl:用户字典,用户名和其对应的id
(2)mid_voc.pkl:movie名字典, item和其对应的id
(3)uid_voc.pkl:movie种类字典,category对应的id
(4)local_train_splitByUser:训练数据,一行格式为:label(是否点击了query)、用户名、目标item(query)、 目标item类别(query类别)、历史item、历史item对应类别;
(5)local_test_splitByUser : 类似local_train_splitByUser
(6)reviews-info: review 元数据,格式为:userID,itemID,评分,时间戳,后续用于进行负采样的数据;
(7)item-info:movie到category映射,即 item对应的category信息
run.sh
就是跑总体的代码,可以看到总入口是train.py。
看一下script目录下的
这里面比较重要的就是:
train.py
基本逻辑就是使用data_iterator加载数据生成迭代器train_data和test_data,然后声明网络(WideDeep,论文中DIEN的各种变种模型等)model
最后就是从train_data和test_data不断取数据在model中训练。
值得说的是这里有个prepare_data函数,这里我放到和data_iterator.py一起讲。
data_iterator.py
数据迭代器构造,里面包括各组建batch,将item,category转化为id,负采样等等
其返回值是 source, target
其中sorce是一个列表(batch),每一个元素也是一个列表
[uid, mid, cat, mid_list, cat_list, noclk_mid_list, noclk_cat_list]
target是一个列表(batch),每一个元素也是一个列表
[float(ss[0]), 1-float(ss[0])]
其中
uid :用户id,一个数
mid : 目标movie id(query),待预测是否点击的movie id,一个数
cat: 目标movie category id(query),待预测是否点击的movie category id,一个数
mid_list : 用户 历史点击的 movie id ,其实一个列表(长度不定的)
cat_list :用户 历史点击的 movie category id ,其实一个列表(长度和mid_list一样)
noclk_mid_list、noclk_cat_list:负采样的movie id和category id,这里的逻辑代码在174-193行
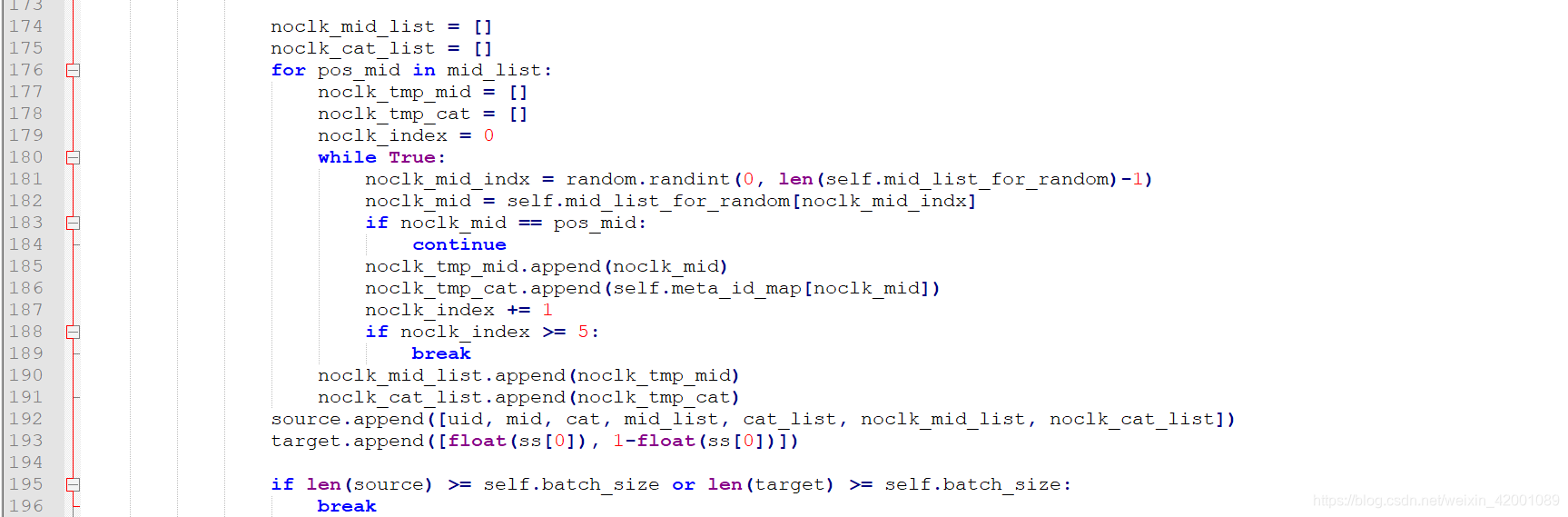
mid_list_for_randoms是一个列表,是从reviews-info中提取的movie id 集合(很暴力,也没用到打标分数啥的就是,全部统计放到一个列表中)
过程就是:可以看到其是一个一个从mid_list(历史行为序列)中拿movie id(pos_mid) ,然后在mid_list_for_randoms随机抽取一个位置(对应一个movie id即noclk_mid),然后看看pos_mid和noclk_mid是不是一样,一样就跳过,不一样就可以作为一个负样本啦,同时看到188行,大于5就结束了,所以都是抽出5个负样本。注意抽取的负样本noclk_mid_list是一个二维列表[length,5],length就是该用户历史行为中点击的商品个数。
再说的详细点就是假设用户历史点击的商品有[1,45,34]
那么我们先取出1,其对应抽5个负样本[2,3,4,5,6]
再取出45,其对应抽5个负样本[7,8,2,9,1]
再取出34,其对应抽5个负样本[89,56,23,67,3]
最后noclk_mid_list的形式就是[[2,3,4,5,6], [7,8,2,9,1], [89,56,23,67,3]]
target就是一个列表,[0,1]或者[1,0] 标签。
-----------------------------------------------------------------------------------------------------------------
有了上面的source 和target,接着看一下train.py中的prepare_data函数
再从上述iterator取出一个batch后,都要经过该函数进行一下预处理,其实该函数目的就一个就是将行为序列长度归化到100,
我们知道每个用户的历史点击行为序列长度大小不一,我们得规划到100.
所以需要规范化的字段主要就四个,其他保持原状就可以
mid_list、cat_list、noclk_mid_list、noclk_cat_list
逻辑如下:
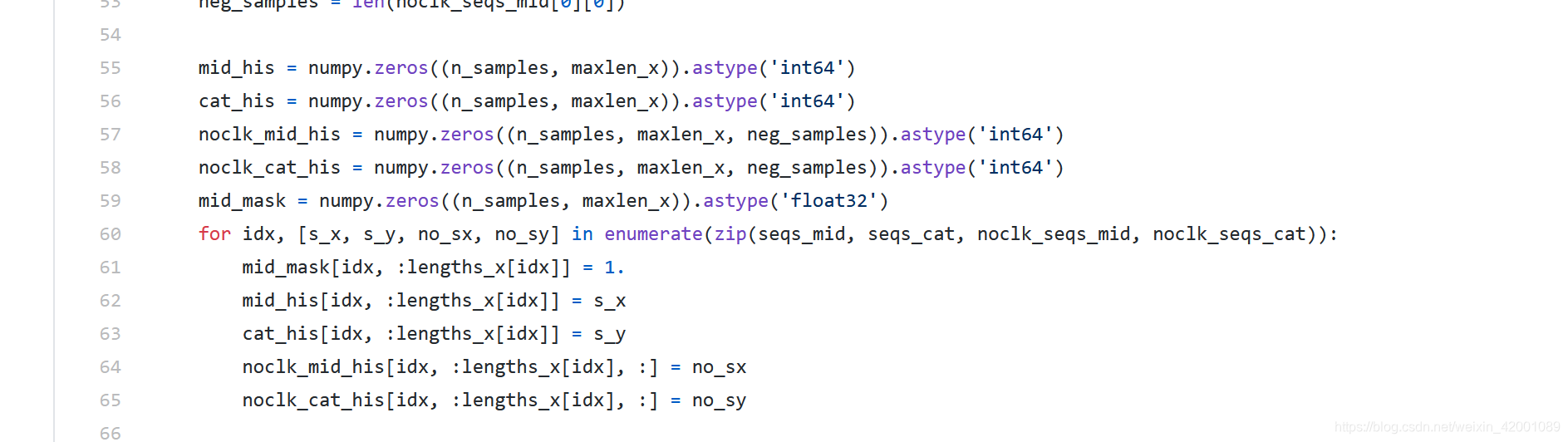
55-59先统一申请一个规范的数据形式,代码中maxlen_x=100
lengths_x是一个列表,代表着各个用户的真实长度比如[3,4,100]就是说第一个用户的真实历史序列长度为3,需要说明的是,如果一个用户的真实历史点击序列长度大于100啦,那么就截取后100个来做(31-35行代码),并将它的长度设为100,小于100的话就正常保留。
然后s_x,s_y是两个列表,代表着真实的序列item,所以 mid_his[idx, :lengths_x[idx]] 中:lengths_x[idx]代表着真实长度,其中lengths_x[idx]==len(s_x)的,如果lengths_x[idx]==100,那就恰好填满了,100全是真实序列,如果lengths_x[idx]=40那么前40个是真实的,后60个是0(就是padding啦)
cat_his、noclk_mid_his、noclk_cat_his同理,这里还多了一个mid_mask这个就是来记录padding啦,1代表的就是真实的,0就是填充的。
所以总结一下就是该函数就是将mid_list、cat_list、noclk_mid_list、noclk_cat_list长度为100的,短padding,长截取,这个信息记录在mid_mask。
model.py
这里定义了所有模型
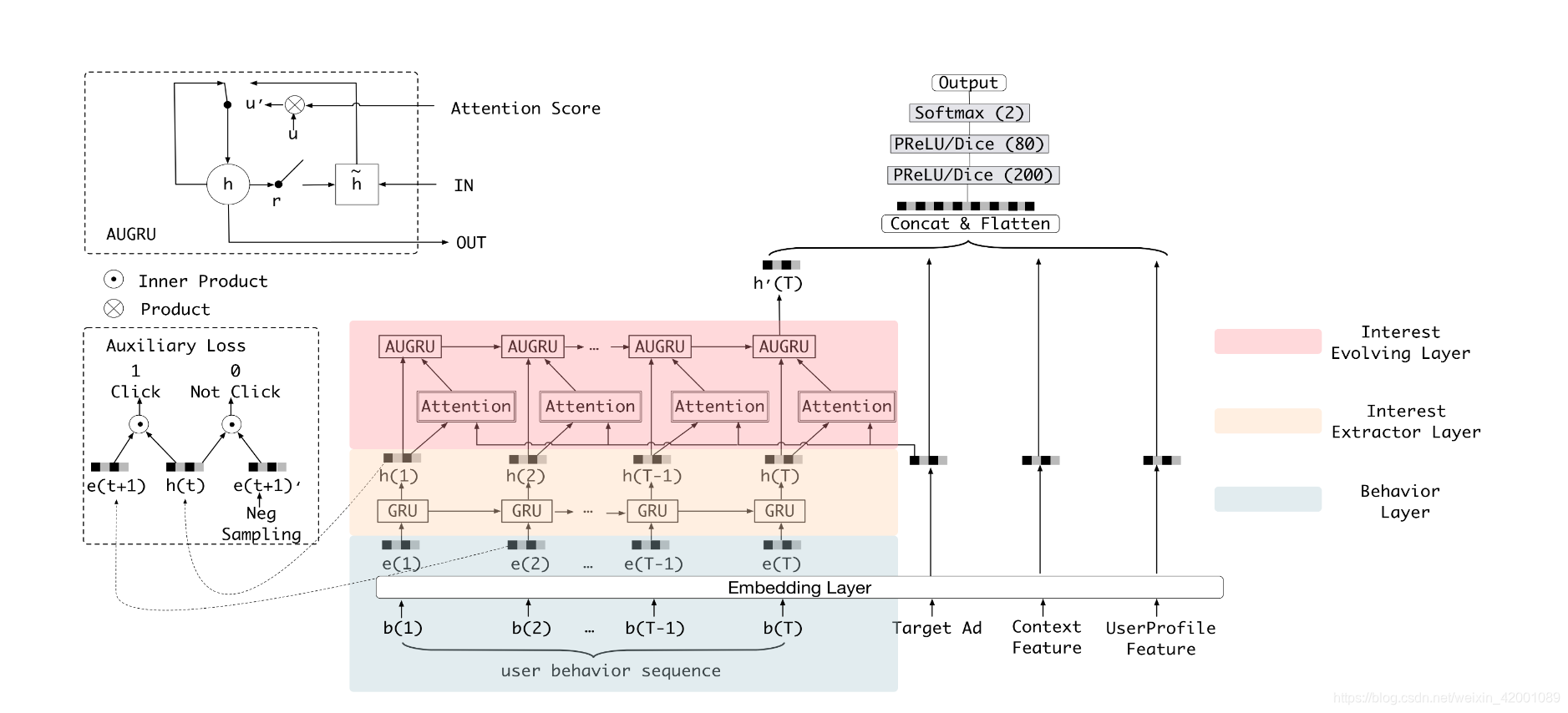
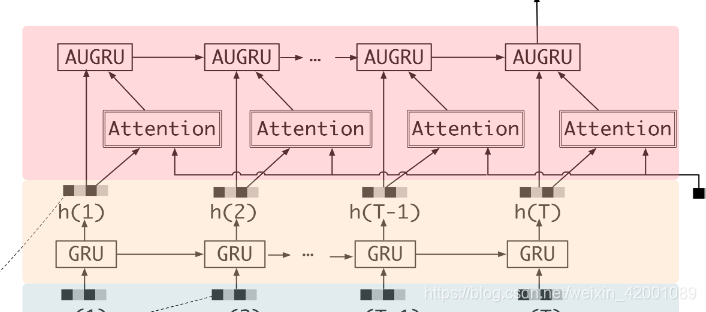
这里看一下DIEN给出的总体模型图
Model是基类主要是定义了:

(1)初始化中定义了placeholder,Embedding_layer层对应的就是

基本思想就是将movie ID和 movie category ID 的emb 进行concat

self.item_eb就是目前item(query)的 movie id 和movie category ID的emb concat ,其维度是[batch,EMBEDDING_DIM*2]
self.item_his_eb 就是历史序列行为的 movie id 和movie category ID的emb concat 其维度是[batch,100,EMBEDDING_DIM*2]
self.item_his_eb_sum 就是将100个序列行为进行相加得到一个总的其维度是[batch,EMBEDDING_DIM*2]
self.noclk_his_eb类似self.item_his_eb只不过其对应的是负样本,其维度是[batch,100,5,EMBEDDING_DIM*2]
self.noclk_his_eb_sum_1就是将5个负样本加起来维度是[batch,100,EMBEDDING_DIM*2]
self.noclk_his_eb_sum 就是在self.noclk_his_eb_sum_1基础上将100加起来维度是[batch,EMBEDDING_DIM*2]
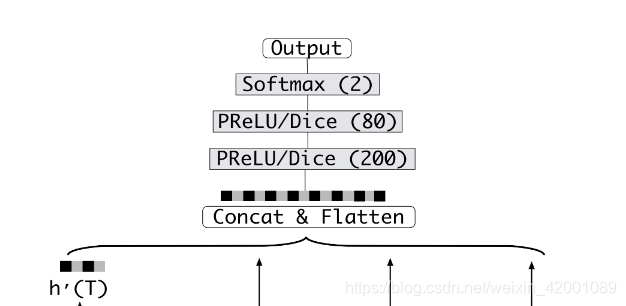
(2)build_fcn_net其实对应的是这部分
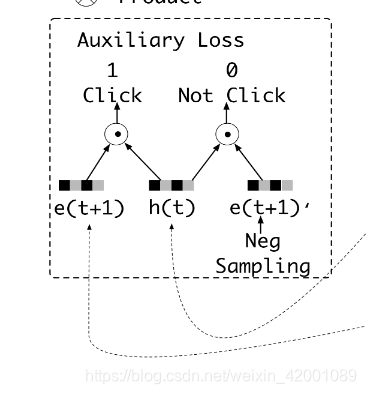
(3)auxiliary_loss 计算的就是论文说的辅助loss,auxiliary_net就是计算该loss需要的网络生成。对应的是这部分:
(4)train和calculate就是训练和预测
(5)save和restore就是模型的保存和加载。
所以上述是基类都定义好,对各个模型基本都一样,下面各个子类其实改变的就是下面的部分
下面我们就看一个Model_DIN_V2_Gru_Vec_attGru_Neg这个子类,别的模型一样的代码逻辑:
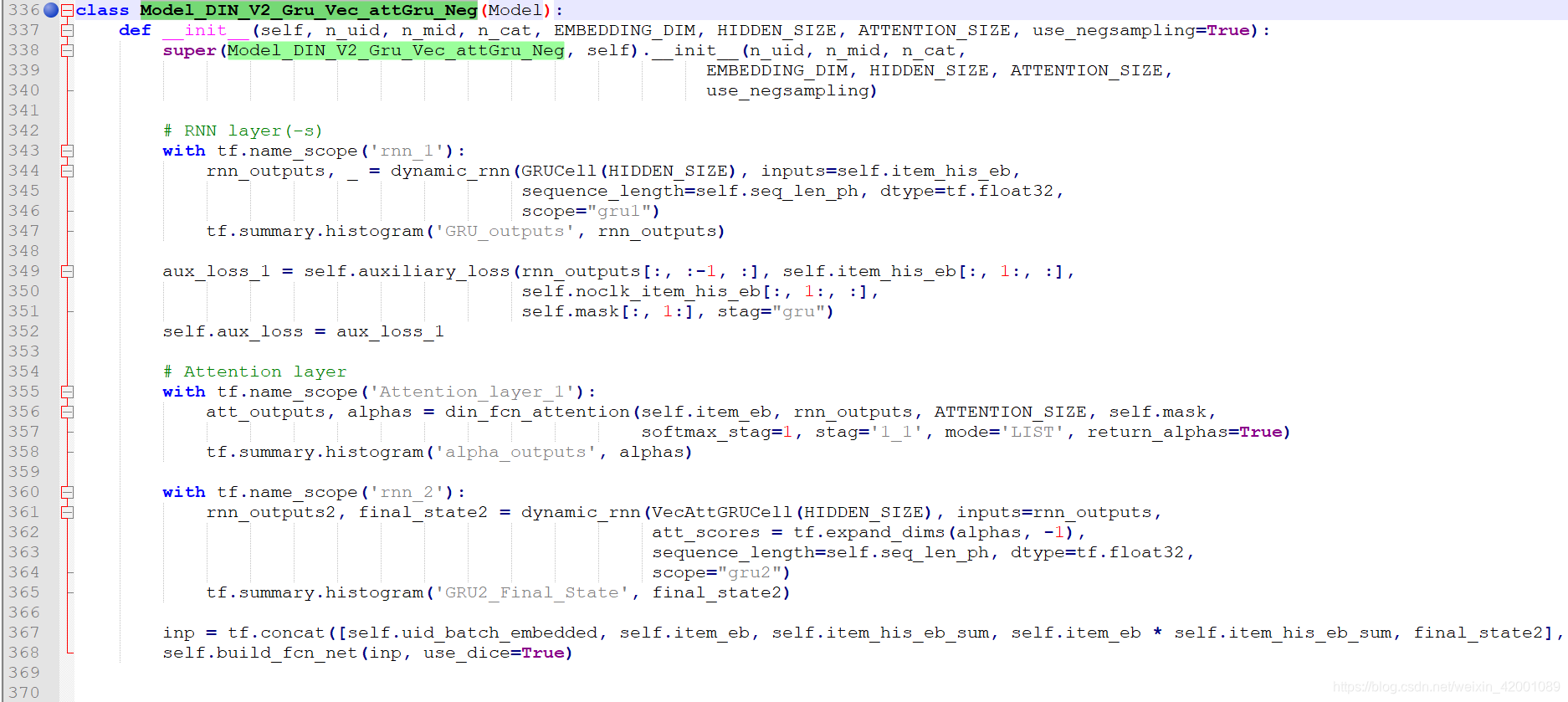
(1)337行的初始化其实无疑已经构建好了很多网络,如上述在基类所说的一些网络
(2)334行就是在构建第一层的gru层也就是论文所说的兴趣提取层(rnn_1),其输入就是self.item_his_eb,没什么好说的
(3)349就是计算辅助Loss了,需要主要看其输入是rnn_outputs[:, :-1, :] ,其是gru各个中间状态的输出,但是不包括最后一个
self.item_his_eb[:, 1:, :]和self.noclk_item_his_eb[:, 1:, :]分别对应的是正样本和负样本,但是不包括第一个。
这里的逻辑就是依据上一个时刻的兴趣来预测下一个时刻的行为
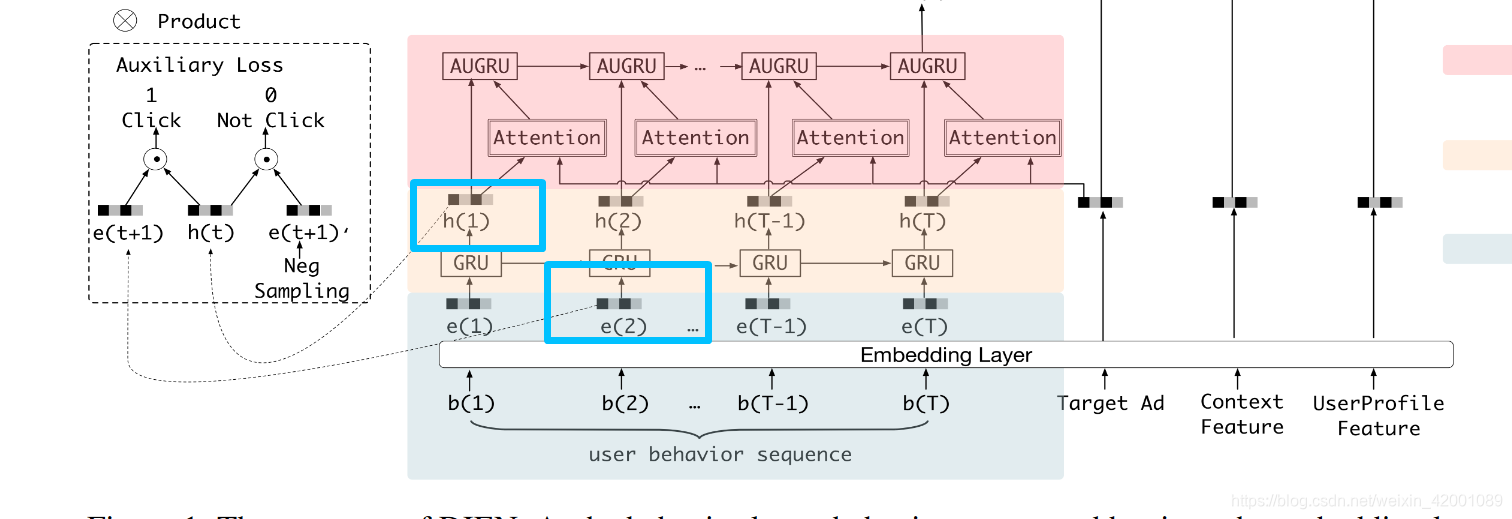
所以这样推下去的话,gru就是不包括最后一个,正负样本不包括第一个啦
下面我们来详细看看怎么计算辅助loss
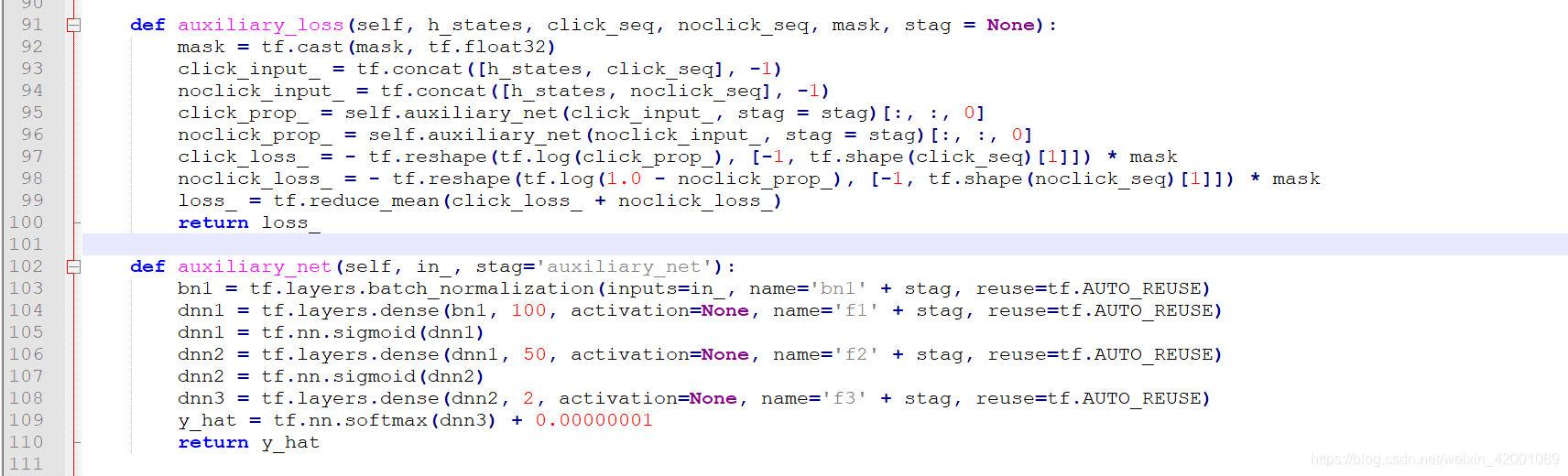
h_states 是gru的输出维度是[batch,99,gru_hidden_size]
click_seq是正样本,维度是[batch,99,emb_size]
noclick_seq 是负样本 维度是[batch,99,emb_size]
mask 就是记录的padding信息 维度是[batch,99,emb_size]
其是将正负样本都分别和兴趣concat 即
click_input :[batch,99,emb_size+ gru_hidden_size]
noclick_input_: [batch,99,emb_size+ gru_hidden_size]
然后分别通过auxiliary_net网络,这里是一个3层mlp网络,其输出维度是[batch,99,2]
click_prop和noclick_prop_是取了最后一维的第一个作为预测概率(95,96行代码)所以维度是[batch,99],代表着这99个行为序列的预测结果,然后计算分别计算loss,相加,即论文公式:
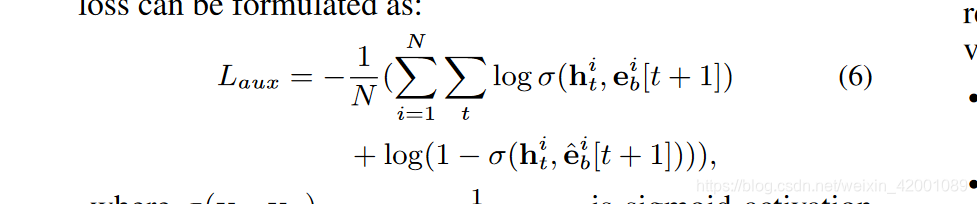
注意代码中(97,98行)在计算Loss 的时候还乘以了mask,就是去除padding的影响,只计算真实的(即最后的loss并不一定是99个的loss)
(4)接着看Model_DIN_V2_Gru_Vec_attGru_Neg这个子类的355-358行,即attention层即下图绿色框的部分
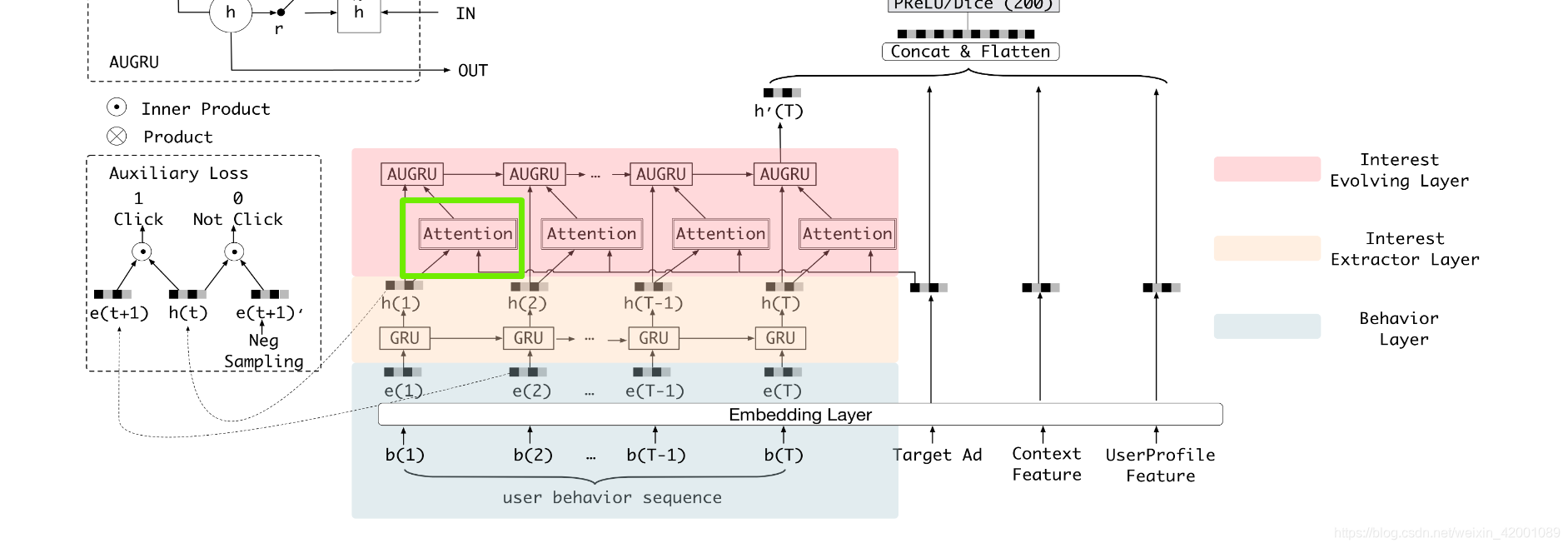
该部分主要就是din_fcn_attention这个函数,位于utils.py 的283行
其输入
query = self.item_eb 维度是 [batch,emb_size] 就是上图中的target AD的emb
facts = rnn_outputs 维度是 [batch, 100, hidden_size] 就是上图中部的h(1)
mask = self.mask 维度是 [batch ,100],记录中padding的情况
attention逻辑:
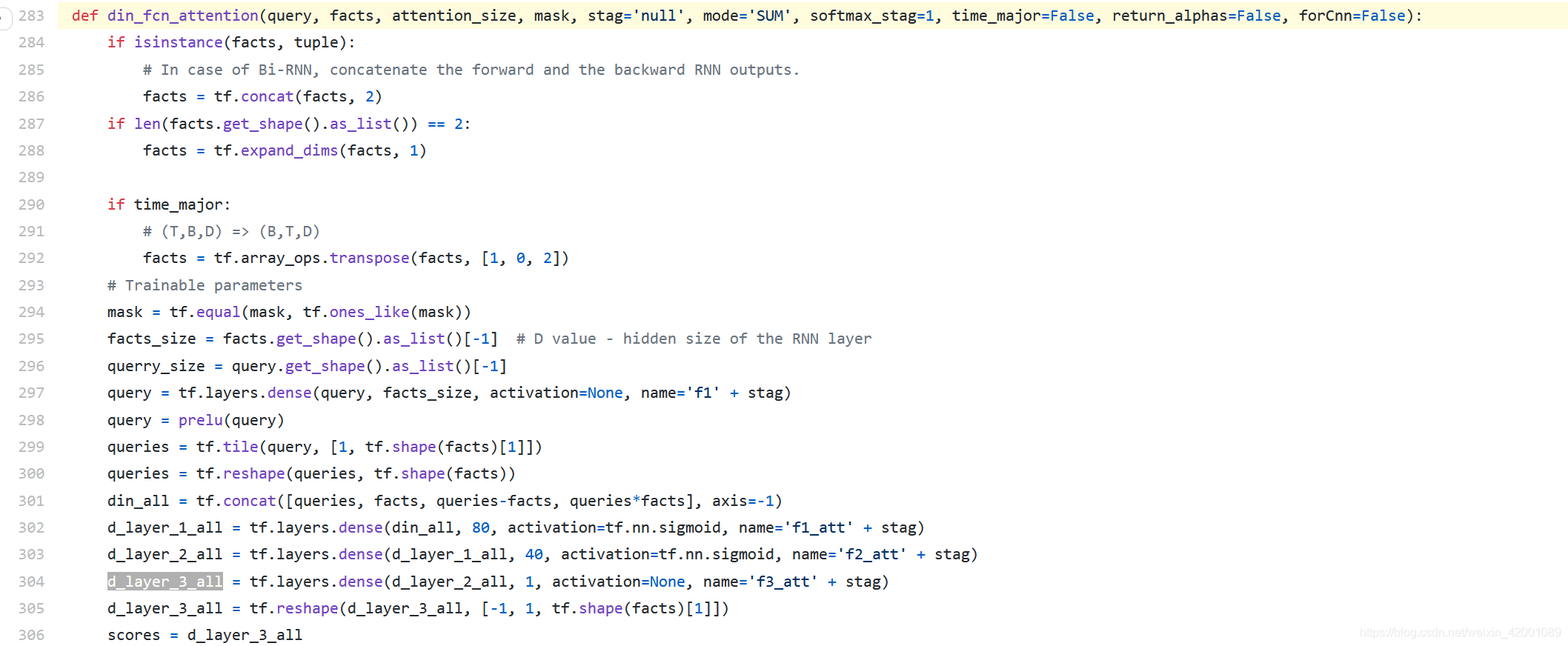
297行先将query通过一层MLP转化为[batch,hidden_size]
299行将其第二维复制100份即queries的维度是[batch,hidden_size*100]
300行将queries变成和facts同纬度即 [batch, 100, hidden_size] ,其实就是将query重复复制了100份,好和历史记录的每一个行为兴趣(facts)做运算
301行就是各种concat(咱们甚至可以再加一个queries+facts),所以din_all维度就是[batch, 100, hidden_size*3]
302-304就是过了3层MLP,d_layer_3_all维度是[batch, 100, 1]
305行d_layer_3_all reshape维度后是[batch, 1, 100]
此时scores就是d_layer_3_all即[batch, 1, 100],每一个兴趣(一共100个)一个分数

在这里我们还是要屏蔽掉padding的影响,即给padding的位置的score即赋值0,这样在score*value的时候就消除了该部分影响,但是并不是真的赋值0,而是赋值一个接近0的数即(-2)**32+1
怎么做呢就是用tf.where函数
310行 声明一个和scores形状相同的paddings tensor,其所有值都是(-2)**32+1
然后312行就是根据条件(key_masks)判断该位置是不是padding,不是的话就用真实计算出来的score,否者的话就用(-2)**32+1替换
key_masks的产生在294,309行其维度是[batch,1,100],元素是一个bool类型,其中294行通过tf.equal将mask和一个全1的矩阵比较,相同的位置就是true(非padding),padding位置就是false啦
所以312行得到的就是一个除去padding的score啦,319行就是softmax归一化
323行就是[batch,1,100] * [batch, 100, hidden_size] 得到输出output的维度是[batch,1, hidden_size]
output就是一个考虑attention机制算出来的兴趣,scores 就是分数 ,两者即是绿框最后的输出。
(5)接着看Model_DIN_V2_Gru_Vec_attGru_Neg这个子类的360-365行看,对应论文的兴趣转移层(rnn_2)即
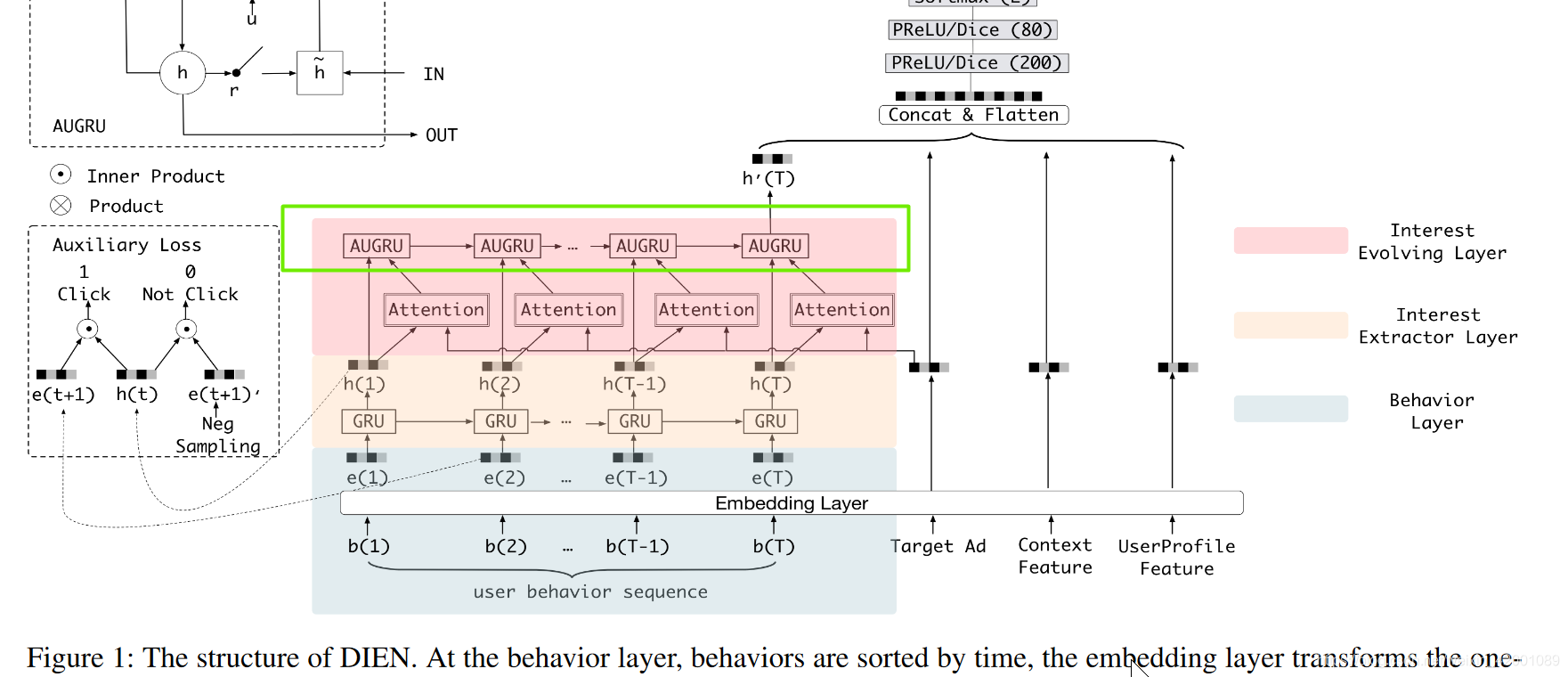
这里其实本质也没什么特殊的,就是一个gru,但是其改造了一下即论文中的:

其中门直接用的是上述attention计算出的score即356行的alphas

这个改造的gru就是361的VecAttGRUCell的,即utils.py下的142-144行(https://github.com/mouna99/dien/blob/1f314d16aa1700ee02777e6163fb8ca94e3d2810/script/utils.py#L141)
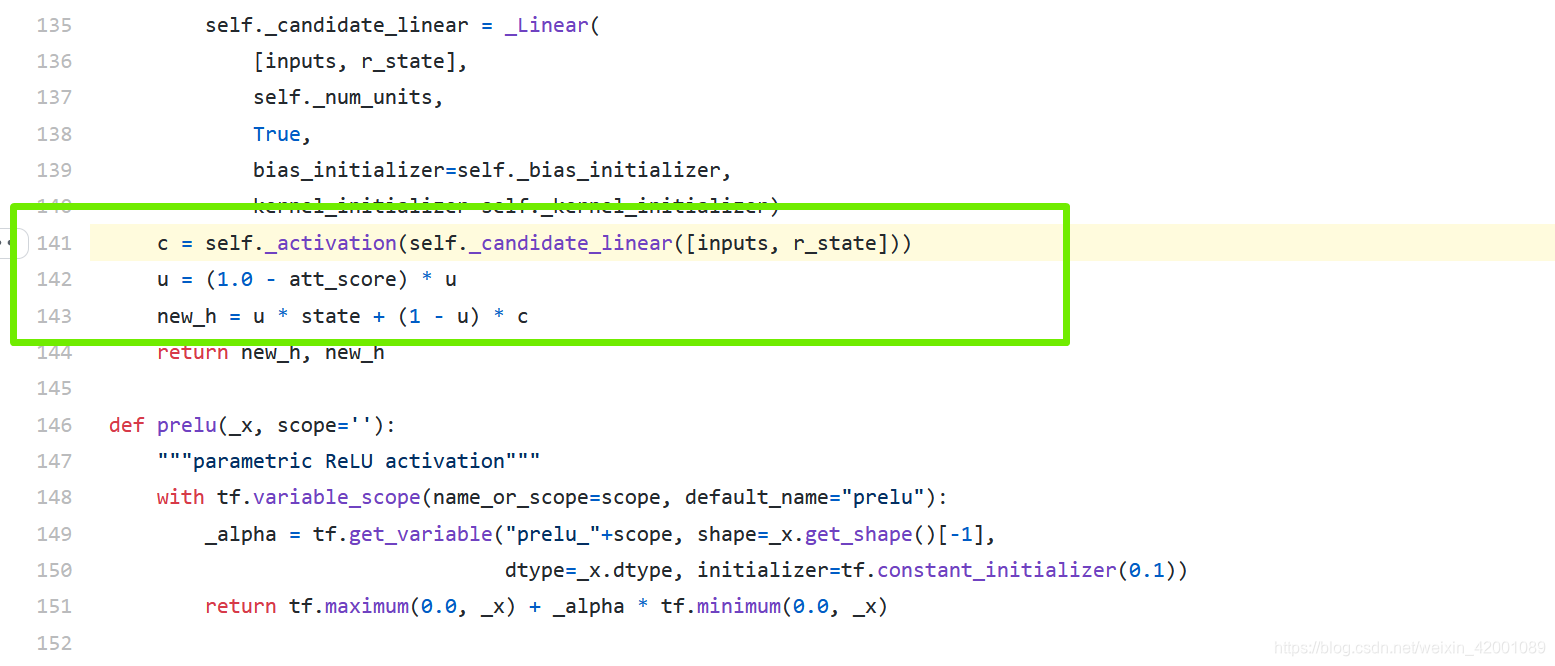
注意,在utils.py中定义了各种rnn基本cell,其中在兴趣提取层(rnn_1)用的是基本GRUCell,在这里的兴趣转移层(rnn_2)用的是VecAttGRUCell。
然后都是用dynamic_rnn这个函数包起来cell形成rnn
(6)接着看Model_DIN_V2_Gru_Vec_attGru_Neg这个子类的367行即对应的是
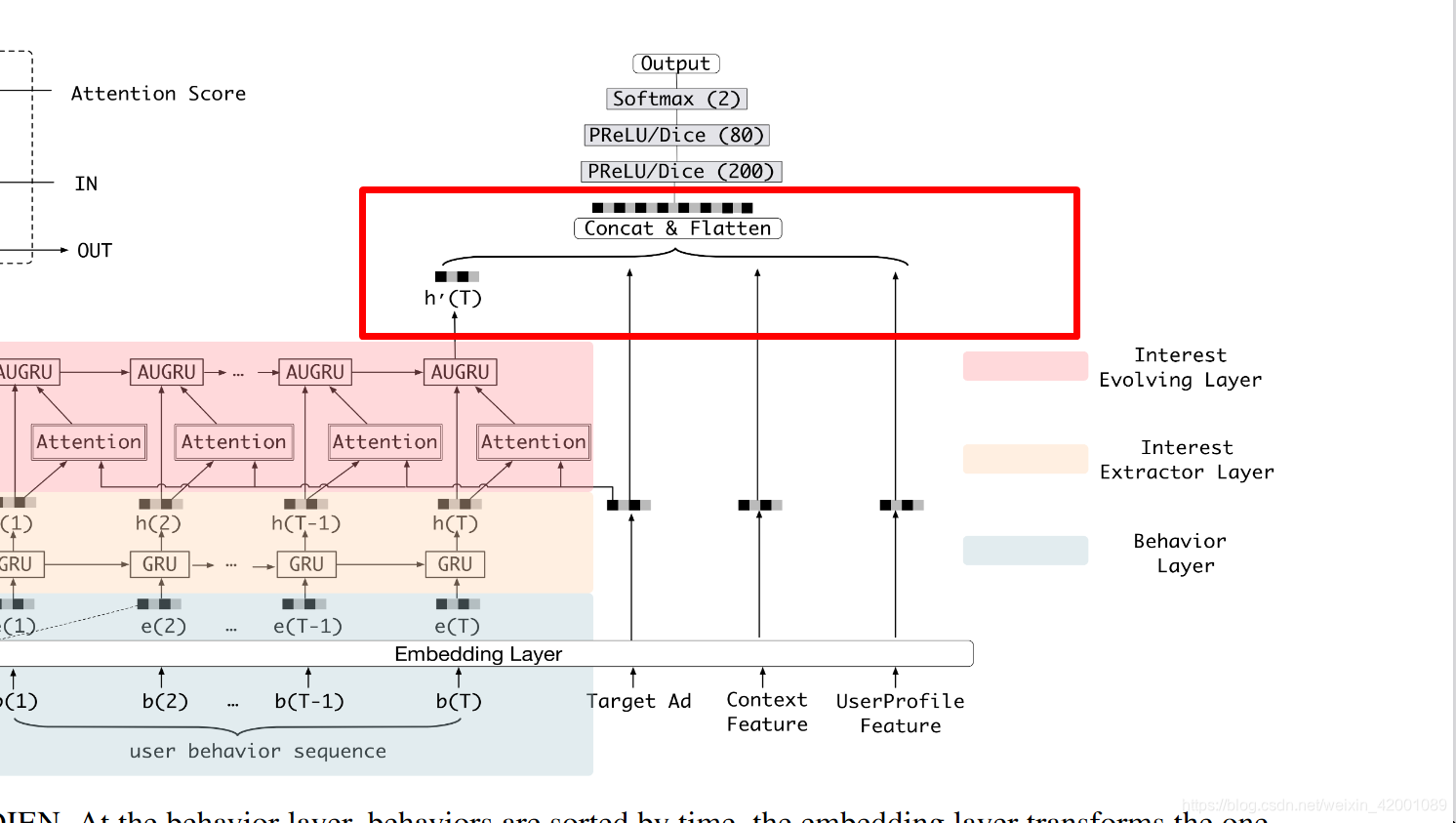
其concat的有
final_state2即上图中的h`(T)
self.item_eb即上图中的Tarfet Ad
self.item_eb * self.item_his_eb_sum 和 self.item_his_eb_sum 是上下文 Context Feature
self.uid_batch_embedded 是UserProfile Feature
(7)接着看Model_DIN_V2_Gru_Vec_attGru_Neg这个子类的368行即对应的是基类定义的输出层函数build_fcn_net即
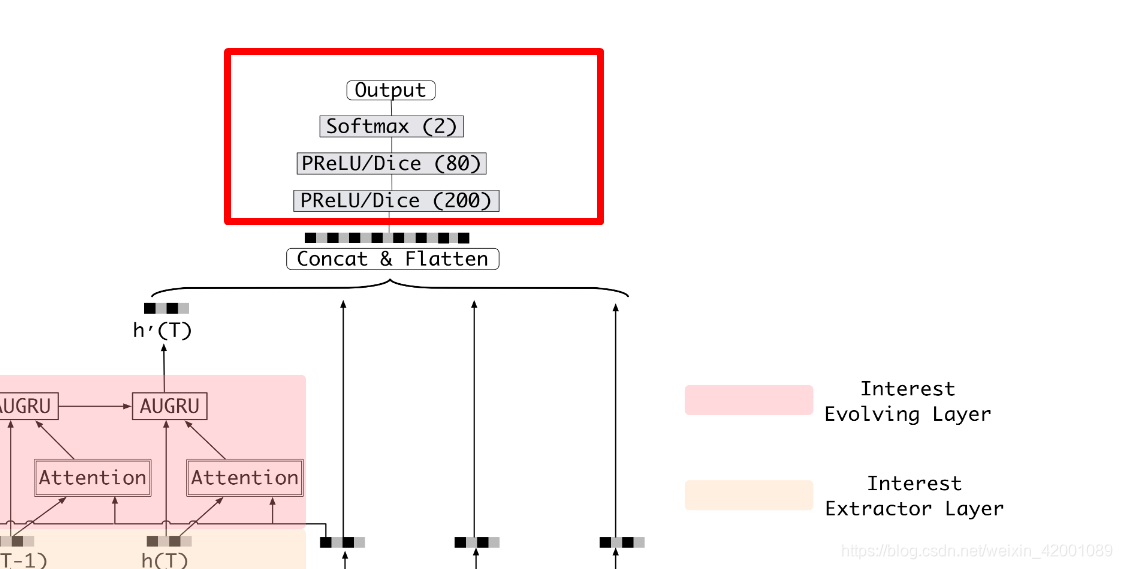
逻辑

比较简单,不再累述,总的来说就是三层MLP,然后计算交叉熵和acc
总结
(1)总的来说比较重要的就是看两部分代码
data_iterator.py :数据规范化处理部分
model.py :模型定义部分(上述只看了一个子类模型Model_DIN_V2_Gru_Vec_attGru_Neg,还有很多,可以借鉴看比如WideDeep等)
然后就是使用train.py联合两部分进行训练啦
(2)通过上面可以看到,模型用的数据其实只是一个:用户历史点击item的序列(利用了该item的一个属性即category,基本上就是两则concat一起使用)和当前要预测的query
(3)最近京东放出一篇CTR sort论文:https://arxiv.org/pdf/2010.00985.pdf
代码没有开源,但论文中也说了其是在该阿里代码上面做的
欢迎大家关注笔者微信公众号和知乎

知乎:

















 2079
2079

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









