









目录
前言
聚类很常见了,很多场景下都需要聚类,笔者当前遇到一个问题是实体消歧,实体是一个个小短句,没有标注没有任何先验知识,想到的就是通过聚类将一些相似实体聚在一起达到目的。
当前聚类有两大种,比如需要提前定义簇中心个数的,以Kmeans最为大家熟知,原理简单有效。还有一种是不需要提前定义簇中心个数的,比如流式聚类。一般情况下,簇中心个数是很难知道的,所以可以选流式聚类等等,但今天要说说收录在AAAI 2021的一篇论文《Discovering New Intents with Deep Aligned Clustering》
论文链接: https://arxiv.org/pdf/2012.08987.pdf
代码链接: https://github.com/thuiar/DeepAligned-Clustering
其是基于Kmeans的一种半监督聚类,一些想法我们可以借鉴。
以下部分解读来自于:
大家也可以直接看上面的解读。这里就简单先过一遍,最后主要说说一些感想。
总模型

特征提取
这里没什么创新,就是取预训练模型提取最后一层输出的词嵌入表示。然后,通过平均池化(mean-pooling)操作获得句向量表示,再经过一层致密层(Dense Layer)获得意图特征:

知识迁移
这里体现了半监督的味道,假设有一小部分标签数据(尽管我们不知道总的类别数有多少,但是我们就是有一部分有标签的数据),然后定义一层全连接层(分类层)进行fintune,训练完后,我们去掉这后面定义的这一层,保留前面的层用以提取特征,至此体现了知识迁移。
这里还有一个重要的点就是既然要用Kmeans ,那么得提前定义簇中心个数,论文中是这样做的:
事先定义一个较大的簇数目K’(如实际值两倍),然后利用经过初始化的意图特征进行聚类。当聚类簇个数较大的时候,不同簇的大小往往有差别,我们将簇包含的样本数量看作其置信度。真正的意图簇由于簇内样本之间相似性较高,置信度会更大。尽管意图特征只在已知意图上进行训练,但是其学到的弱语义相似性特征仍然有助于新意图聚类。因此,我们通过移除低置信度聚类簇,计算满足条件的簇个数(置信度高于阈值)来预测K:
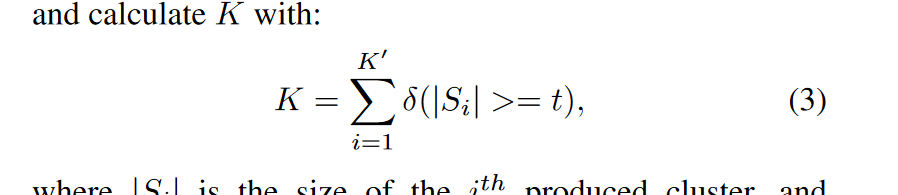
深度对齐聚类
这里就是全文主要创新点了,其主要是两步:无监督聚类和利用对齐伪标签进行自监督学习
(1)无监督聚类
没什么说的就是用Kmeans聚就完事了,特征就是从上面fintune完的模型提取
(2)自监督学习
聚完类那么每个样本就有类别标签,即所谓的伪标签,然后预训练模型依此进行分类训练
(3)交互
上述过程两个交替进行,相互促进,但是有个问题那就是由于Kmeans簇中心的学习是随机初始化,导致前后两次迭代,簇中心号对不上,即自监督学习过程定义的最后一层的分类层类别不对应,即上一次假设类别是1,2,3。但是下一次可能是2,1,3。但我们定义的最后一层是死的,位置类别一直是定死的。那怎么办呢?论文中利用匈牙利算法在欧式空间上获得当前迭代簇中心Cc和上一迭代簇中心Cl的对齐映射G:
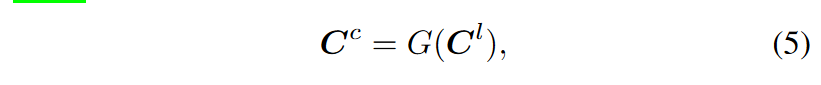
相邻迭代簇中心和簇分配的对齐映射是一致的,由于匈牙利算法产生的是一一映射,我们将逆映射作用在当前迭代产生的簇分配,获得和上一迭代对齐的簇分配作为伪标签:
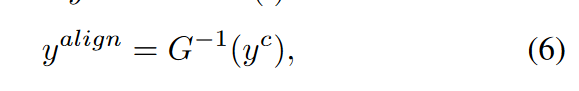
看着是不是还有点蒙,不知道咋回事,那我们看看这段逻辑所对应的代码吧

当然了第一次聚类的时候就直接用结果标签就行了,没有上一轮啥的即147-148行。第二次及以后都会利用上一轮簇中心进行映射,主要逻辑在129-144行。
上一轮的簇中心即old_centroids,新一轮的簇中心new_centroids
计算各个上一轮的簇中心和各个新一轮的簇中心的距离矩阵DistanceMatrix,然后使用匈牙利算法全局最优,说白了就是找到当前这个簇中心和上一轮哪一个簇中心最近比如和A,那上一轮A的标签是3,我当前虽然标签是2,那我为了对齐也更新为3,不知道匈牙利算法的可以看看
思考感想
(1)知识迁移那一步的利用少量标签进行fintune用于后续迁移,假设我们就是连这一小部分标签数据也没有呢?手头数据就是完完全全的无监督,不是半监督,那可不可以略过这一步,直接就用一些预训练模型进行深度对齐聚类呢?当然可以,效果可能不好,根据论文给出的效果说这个fintune还很重要对结果提示起到30%的作用。
(2)K的确定,论文中作者是根据个数来衡量,这个多多少少感觉不是很具有泛化性吧,也没有很强的说服力,时间复杂度允许的话可能传统的确定更好吧。
(3)深度对齐这里两个模型交替进行学习,这个挺有意思,还有匈牙利算映射这个也挺有想法,这个设计根据论文说是提升10%的作用。
总的来说吧,可以学习的就是两个模型交替进行学习,K的确定依然是一个比较难的东西,且对结果影响还是蛮大的。
欢迎关注笔者微信公众号,更多前沿代码解读和工程代码落地trick
















 1664
1664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









