






目录
前言
论文:https://mp.weixin.qq.com/s/rbh91y3c1L24x5wtDqOOlA
代码:https://github.com/James-Yip/QuantiDCE
这是一篇解决对话指标的paper,即做对话系统模型的时候,希望最后的模型是越像人越好,输出的回复很真实,很连贯,而不是那么的机械,那怎么评判这种真实性或者说连贯性呢?本paper通过模型来评价:
主要就是构建了三种预训练loss,这里的理解笔者在第一次看paper的时候,有点疑惑,在看了代码后才恍然大悟【具体看下面pretrain中的小结】,关于详细解读论文,已有博客如下,本篇主要目的是解读代码,通过看代码将学习到在huggingface的transformers这一框架下三种Loss的具体实现以及蒸馏代码的实现
三种loss的实现代码在pretrain中的-----最关键的部分开始---
蒸馏代码的实现代码在fintune中
博客解读
https://mp.weixin.qq.com/s/rbh91y3c1L24x5wtDqOOlA
代码解读
比较有意思的就是那三个loss到底是怎么实现的。
全程代码用了importlib.import_module动态库导入,这里值得注意,笔者第一次看的时候还有点蒙,后面才逐渐熟悉。总体框架如下
preprocess:pretrain阶段前需要用到的数据的预处理
dataset:pretrain和fintune阶段数据加载部分
model:模型,只不过这里非常简单,只定义了模型的返回,最重要的loss计算逻辑却不在这里【和平常看到的多数代码不太一样】,而在trainer中
trainer:主流程的入口,其中最重要的loss设计也都在这里
util:main_utils.py 所有程序的入口,通过importlib这个包实现动态导入不同阶段【train/fintune】想使用的各自文件
数据预处理
项目的原始数据,在\preprocess\dataset\dailydialog++\目录下,有三个json数据集,对应着train/dev/test.
处理上述原始数据集的主逻辑函数是./preprocess/prepare_pretrain_data.py
该py其实是动态导入了./preprocess/processor_dailydialog_plusplus_mlr.py中的DailyDialogPlusPlusMLRLossProcessor类,然后调用了该类函数prepare()。而该类继承了./preprocess/processor_base.py中的DailyDialogPlusPlusProcessor类,当然DailyDialogPlusPlusProcessor类又是继承了同py文件中的DialogDataProcessor。总的来说是:
DialogDataProcessor->DailyDialogPlusPlusProcessor ->DailyDialogPlusPlusMLRLossProcessor
总的入口是类函数prepare,可以直接看基类DialogDataProcessor类下的prepare
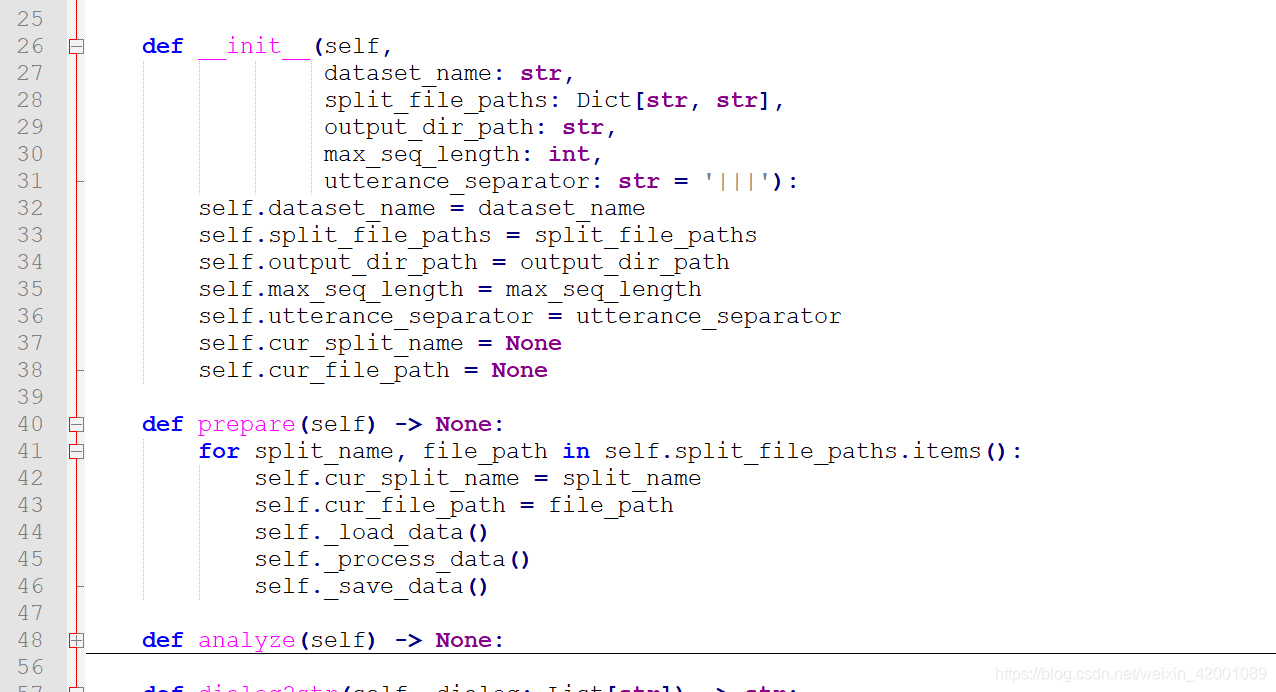
其实代码思路非常清晰,即加载数据、处理数据、保存数据这三步【即44-46行】,对应的代码函数就是
self._load_data()
self._process_data()
self._save_data()这三个函数,在DailyDialogPlusPlusProcessor类上重写了,所以直接看DailyDialogPlusPlusProcessor类上这三个函数就行:
(1) _load_data:没啥说的,就是加载原始数据集即json,加载为self.raw_dialog_data
(2) _process_data 主要逻辑如下:
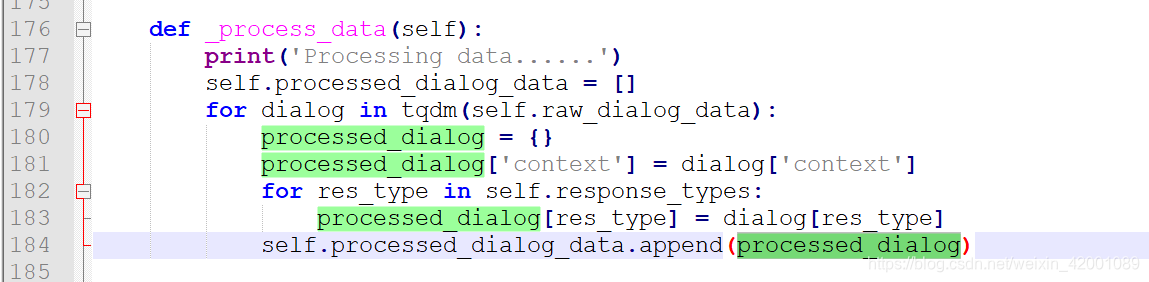
可以看到没啥说的,就是提取了正文【context】和reponse放到self.processed_dialog_data,这里的res_type就三种即

(3) _save_data
最后是保存数据如下,这里有必要看一下最后保存的形式,首先是创建数据保存目录,然后是保存了两种形式,即text和binary
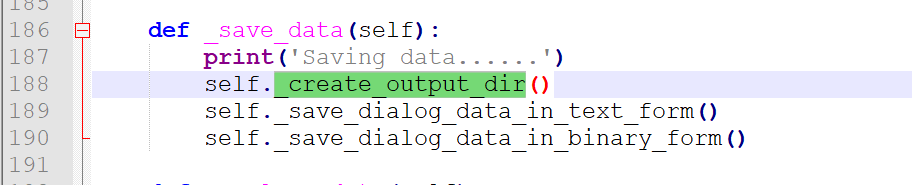
关于_save_dialog_data_in_text_form和_save_dialog_data_in_binary_form这两函数在DailyDialogPlusPlusMLRLossProcessor重写了,所以直接看DailyDialogPlusPlusMLRLossProcessor这个类对应的这两个函数,
下面是最重要的,即数据预处理后最终的保存形式【供模型使用】:
这两函数基本上都使用了两个变量即self.cur_pair_dir_paths和self.processed_dialog_data。
self.processed_dialog_data就是第二步处理得到的源数据,那self.cur_pair_dir_paths是什么呢?

说白了就是输出目录的命名,用cur_split_dir_path和res_type共同决定的
【_save_dialog_data_in_text_form】保存的最总文件是context_response.text形式

从这里可以看到每一行是context+reponse,注意一个context有多个reponse,比如当前一个context【ctx】有3个reponse【res1,res2,res2】,那么一共是保存成了3行即ctx+res1,ctx+res2,ctx+res3
【_save_dialog_data_in_binary_form】,保存的最总文件是context_response.pkl形式
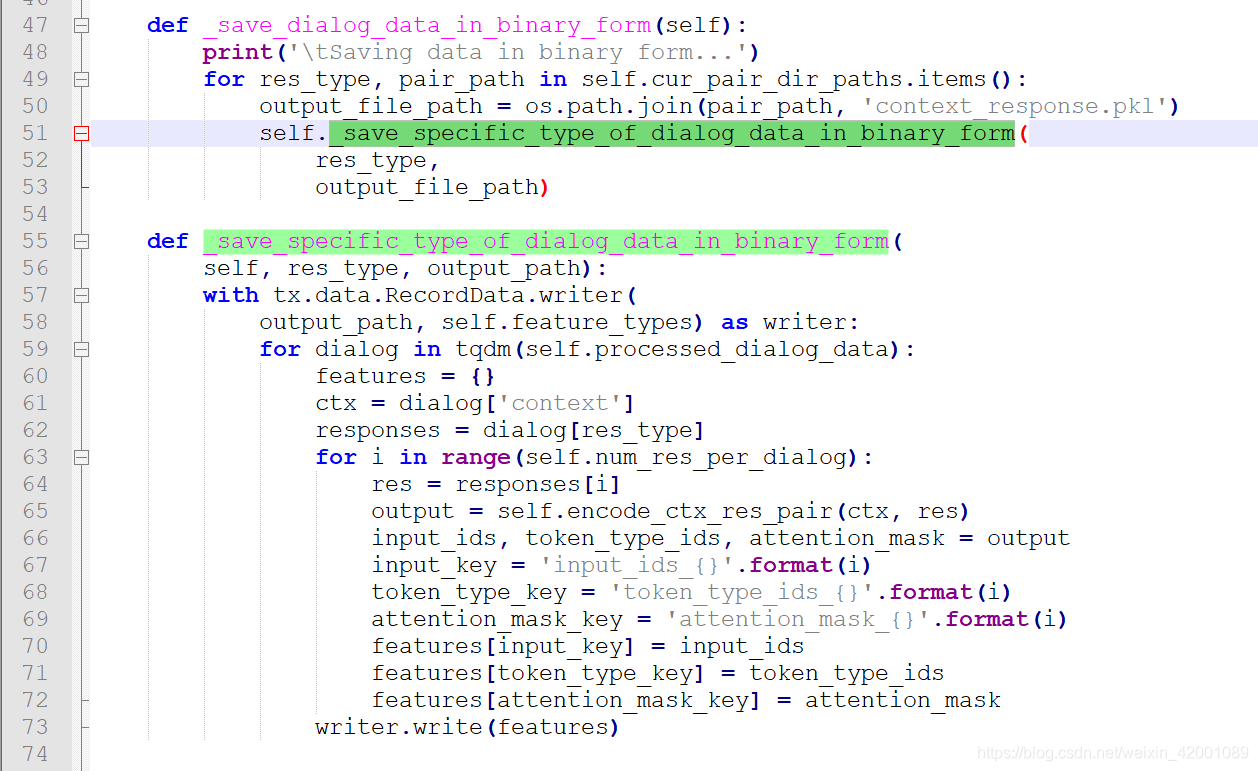
主要就是55行的_save_specific_type_of_dialog_data_in_binary_form函数,注意看59-63行的逻辑,是每一个完整的context-reponse保存到一个features字典,每一个reponse通过67-69的format(i)加以区分,每一个reponse都和context成pair的编码【就是bert的sent_a sep sent_b形式】,所以总结一下就是:
context_response.pkl最终保存的就是一个个字典features,每个features都包含一组完整的context-reponse[即多个reponse],每个reponse通过类似'attention_mask_{}'.format(i)中的i区分,假设如果该context有三个reponse,那features就会有6个key即
input_ids_0,token_type_ids_0,attention_mask_0
input_ids_1,token_type_ids_1,attention_mask_1
input_ids_2,token_type_ids_2,attention_mask_2
总的来说预训练阶段数据预处理用到的py逻辑大概就是preprocess目录下的
prepare_pretrain_data.py->processor_dailydialog_plusplus_mlr.py->processor_base.py
使用的类的逻辑大概就是:
DialogDataProcessor->DailyDialogPlusPlusProcessor ->DailyDialogPlusPlusMLRLossProcessor
最后处理完生成两个文件即
context_response.text和context_response.pkl
更具体来说就是生成了3个文件夹即train/test/dev,每个文件夹下都有3种context_response.pkl,分别是:
response_types = [
'positive_responses',
'adversarial_negative_responses',
'random_negative_responses',
]
这三种
pretrain
这部分主要就是通过代码看看论文的一个主要创新点,即论文当中的三个loss,具体是怎么实现的即sep,com,ord
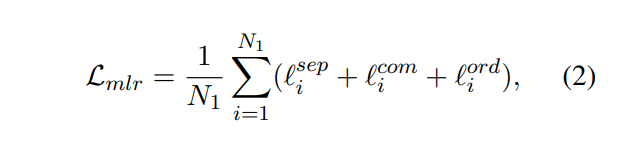
主入口就是pretrain.py函数,看这个函数就会发现其实主要是使用了./util/main_utils.py来声明相应的dataset,model,trainer
(1) dataset
这里主要是使用./dataset/dailydialog_plusplus_mlr.py中的DailyDialogPlusPlusMLR类,其是继承了./dataset/dailydialog_plusplus_base.py中的DailyDialogPlusPlus类,该类又继承了./dataset/dataset_base.py下的Dataset类,所以是:
DailyDialogPlusPlusMLR -> DailyDialogPlusPlus -> Dataset
其中Dataset基类的12行,得到data_iterator,这个就是模型用的数据迭代器,同时11行的get_data_config函数,在DailyDialogPlusPlusMLR 重写了,所以直接看该类的该函数即可
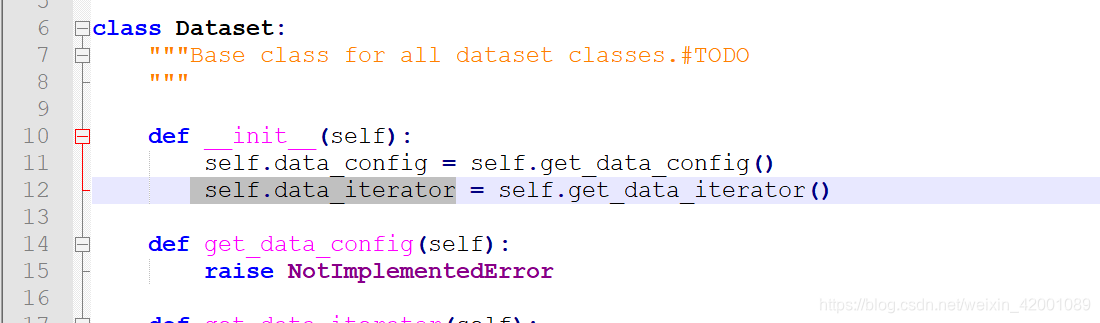
关于DailyDialogPlusPlusMLR的get_data_config,其实是调用了DailyDialogPlusPlusMLRLossConfig类即
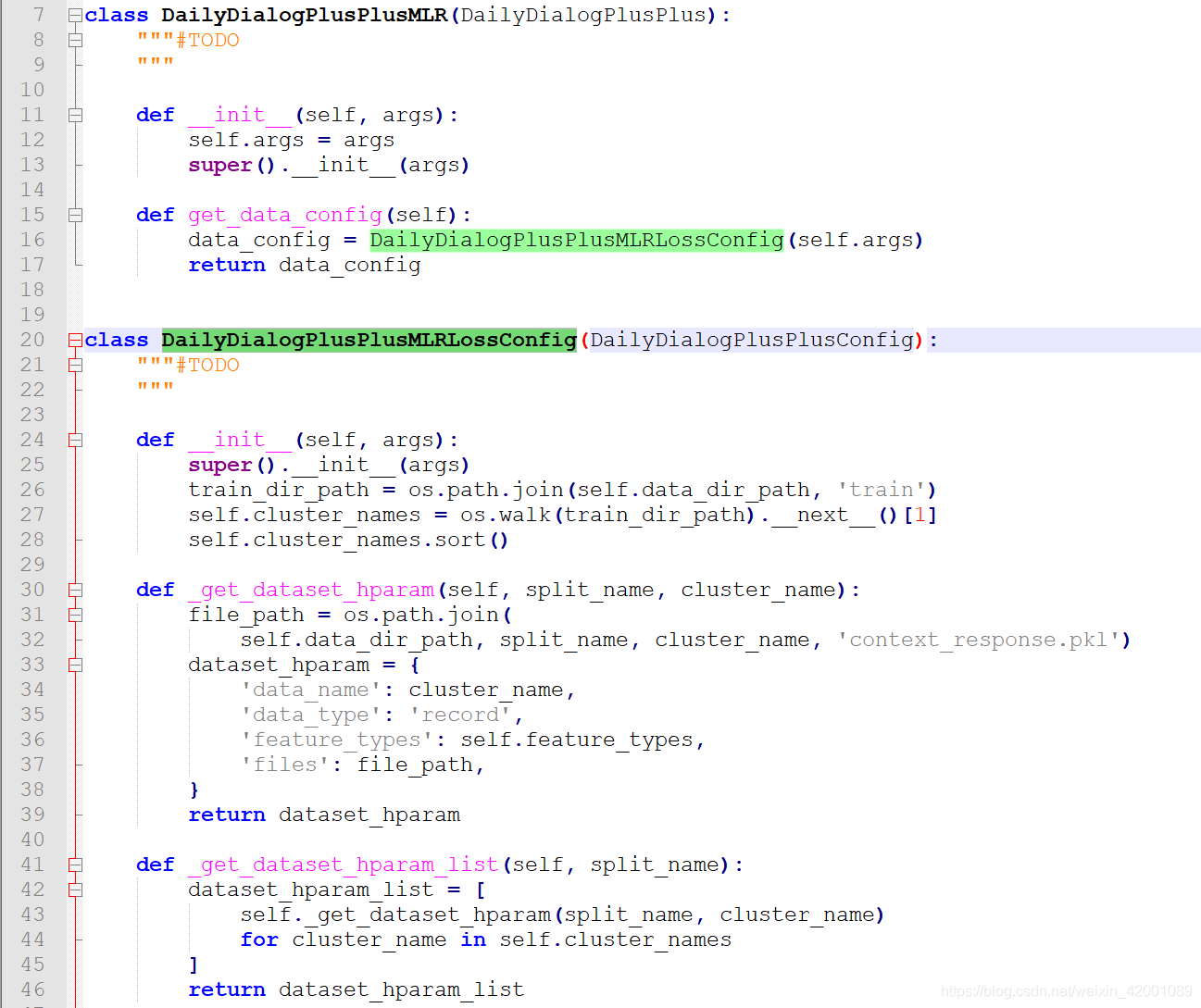
关于get_data_iterator类函数,DailyDialogPlusPlus类重写了,所以直接看该类的该函数即可

可以看到主要是使用了texar.torch的data.MultiAlignedData,这texar是一个库,可以学习一下,关于其的MultiAlignedData的API可以看这里
可以看到,这里主要是通过data.MultiAlignedData使用对应的train_hparams、valid_hparams、test_hparams来加载train/valid/test,其实加载的就是数据预处理部分的context_response.pkl
(2)model
其实就是./model/bert_metric.py中的BERTMetric类,这里没什么看的主要就是模型的返回
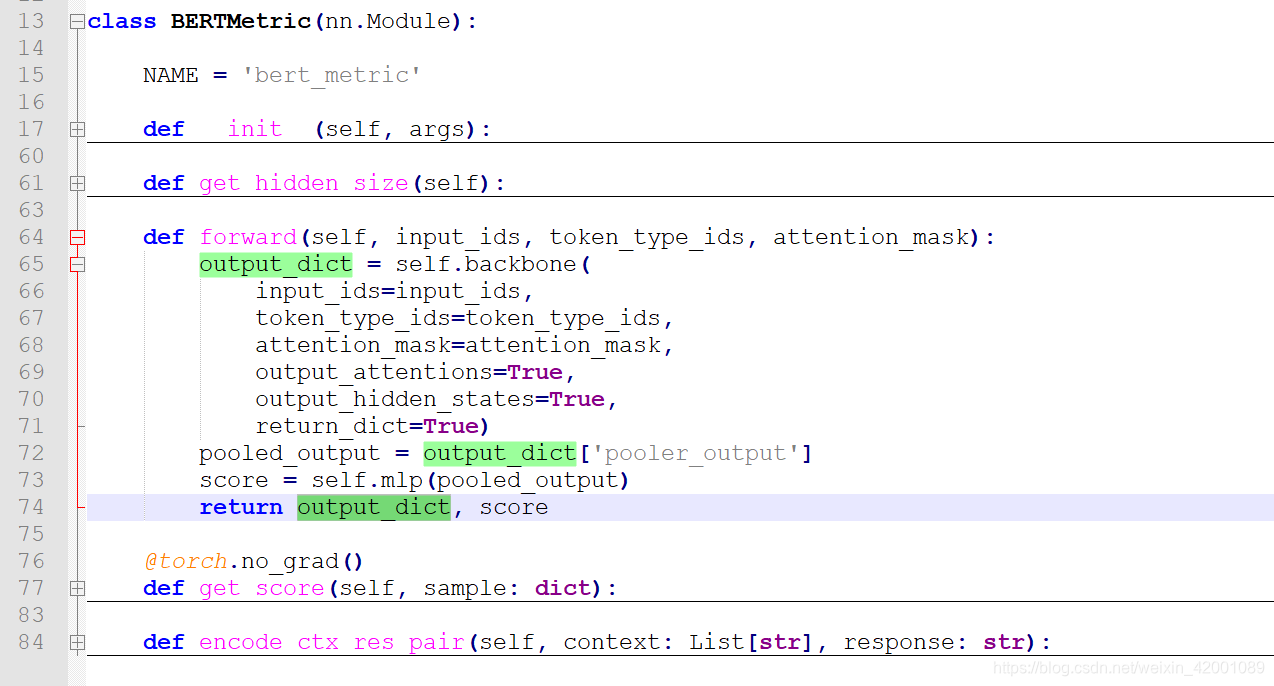
主要就是74行的返回,可以看到,output_dict就是bert的普通返回,score是使用pooler_output过了三层MLP得到的一个分数,关于mlp:

看到这里,并没有看到我们最想看到的东西,即paper提到的三个loss怎么计算,一般loss的计算逻辑都是在模型部分写好的,这里有点奇怪,其实loss的逻辑,他写在了下一小节的trainer中了,我们一起来看一下
(3)trainer
主要就是./trainer/trainer_mlr_pretrain.py下的MultiLevelRankingLossTrainer类,其继承了./trainer/trainer_base.py下的Trainer类。
主入口如下即run,可以看到其实主逻辑在_train下的self._train_epoch
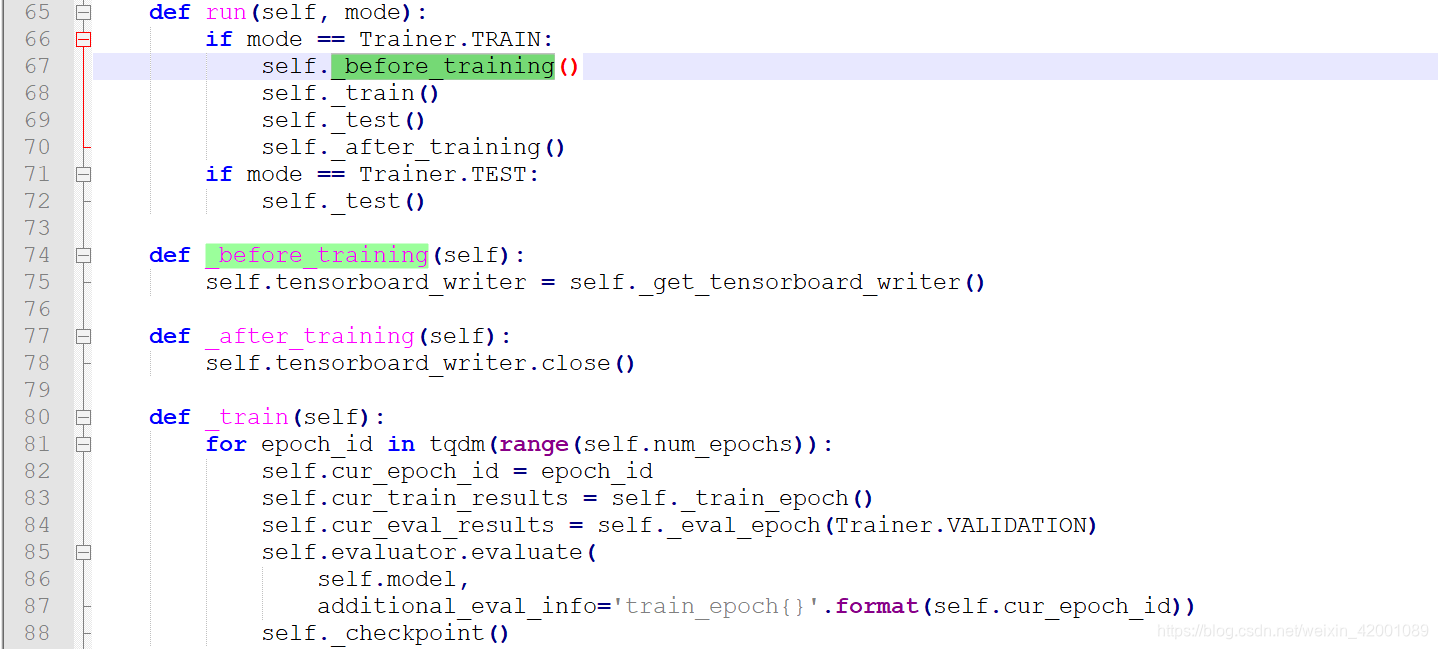
关于_train_epoch这个类函数在MultiLevelRankingLossTrainer中重写了,我们重点看这个,
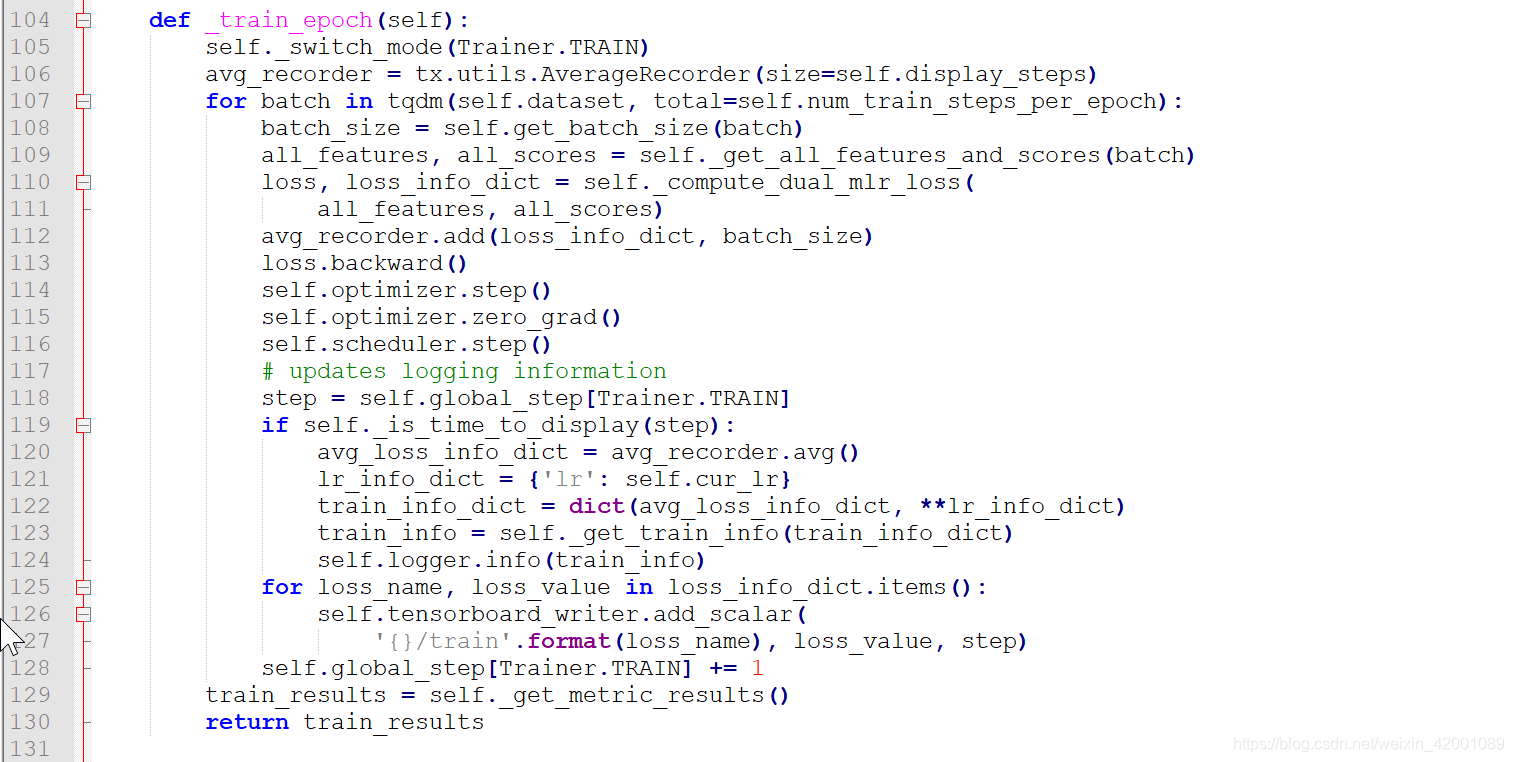
可以看到,最重要的就是109行的_get_all_features_and_scores函数和110行的_compute_dual_mlr_loss函数。
先来看_get_all_features_and_scores
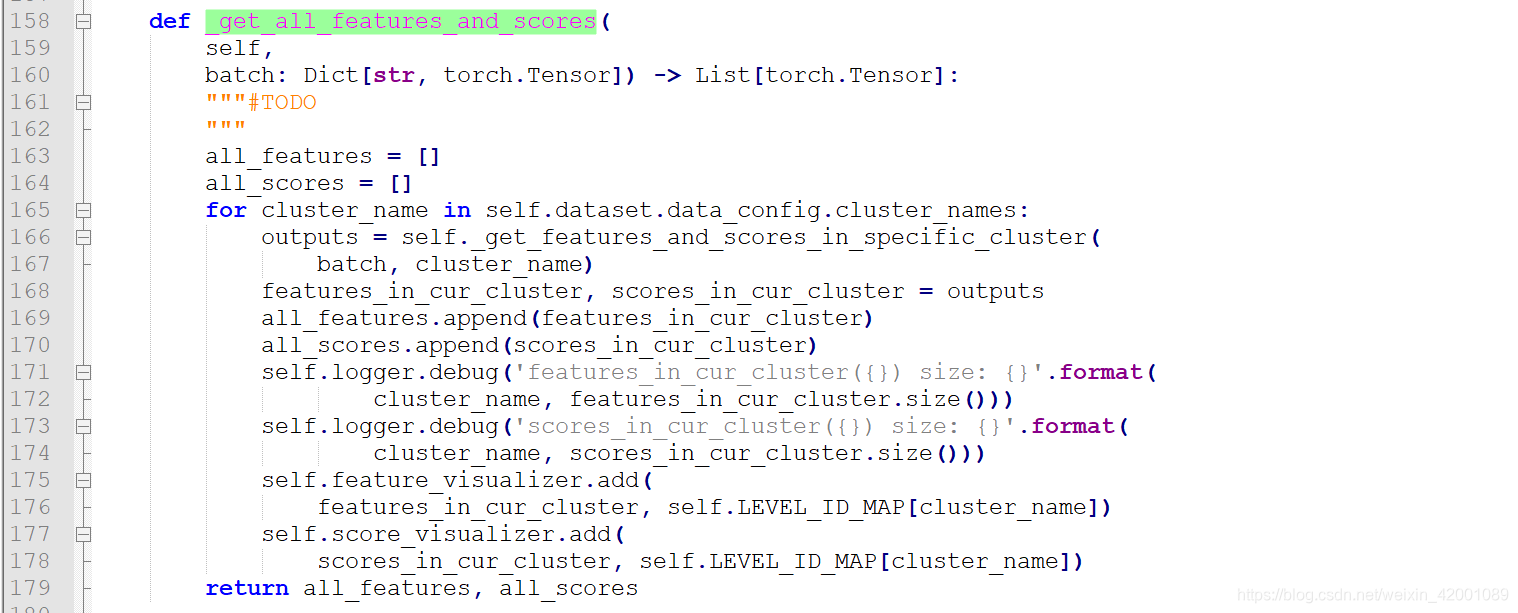
注意看165行的逻辑,这里的self.dataset.data_config.cluster_names其实就是下面三种
response_types = [
'positive_responses',
'adversarial_negative_responses',
'random_negative_responses',
]
每一种通过函数self._get_features_and_scores_in_specific_cluster得到对应的bert的输出,可以看到最后得到的是两个列表即 all_features 和all_scores。
列表元素就是三种方式的模型输出,举例来说就是,如all_features 大概就是:
[positive_responses_features, adversarial_negative_responses_features, random_negative_responses_features]
-----------------------------------------------最关键的部分开始---------------------------------------------------------
接着来看_compute_dual_mlr_loss函数,这里就是我们最想看到的计算Loss的部分
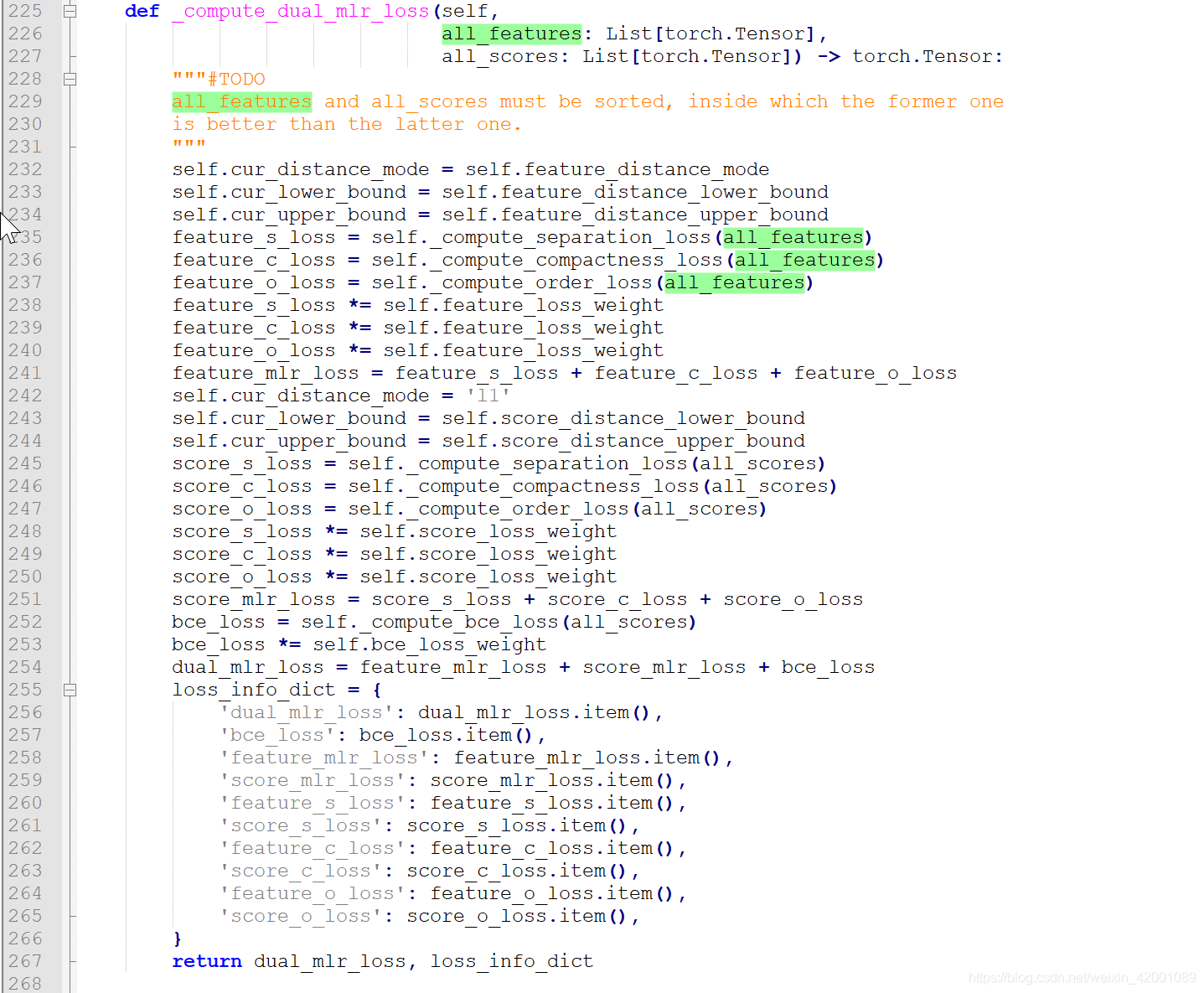
可以看到大概就是feature_mlr_loss、score_mlr_loss、bce_loss。其中前两种,计算的逻辑一模一样,只是输入不一样即一个是features一个是score,我们看一个即可,就看feature_mlr_loss吧,其实可以清楚的看到主要是通过三个函数计算得到的即_compute_separation_loss、_compute_compactness_loss、_compute_order_loss,这里就是对应的paper中的pretrain三种loss的计算即
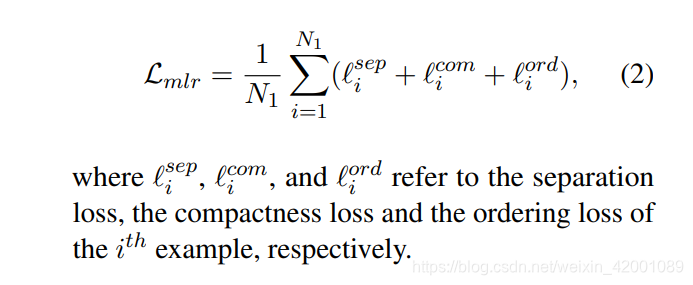
下面一个一个来看
【_compute_separation_loss】

对应到论文的公式如下:旨在让具有不同连贯性程度的context-response pairs彼此远离,对应到上述代码的部分就是287行

其中红框的部分对应的代码是由_compute_inter_cluster_distances函数得到的如下:
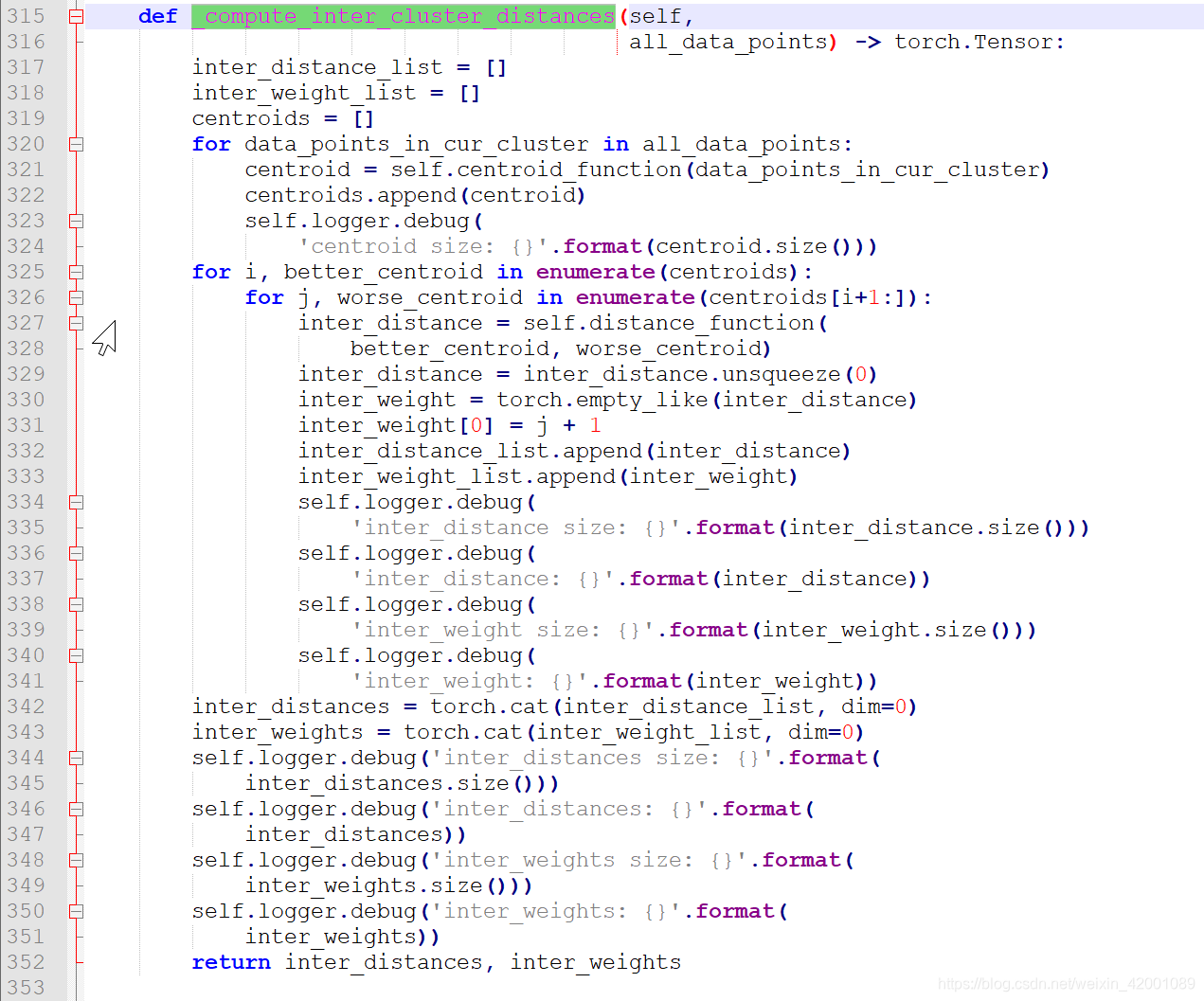
其中321行的centroid就是paper的e,data_points_in_cur_cluster就是paper的s,self.centroid_function就是paper中所说的:

具体看self.centroid_function其实就是个mean,通过这里我们可以清楚看到paper中的公式具有是怎么计算的。

【_compute_compactness_loss】

对应到论文的公式如下:旨在让连贯性程度相同的pairs相互靠近,对应到上述代码的部分就是293行

其中红框的部分对应的代码是由_compute_intra_cluster_distances函数得到的如下:
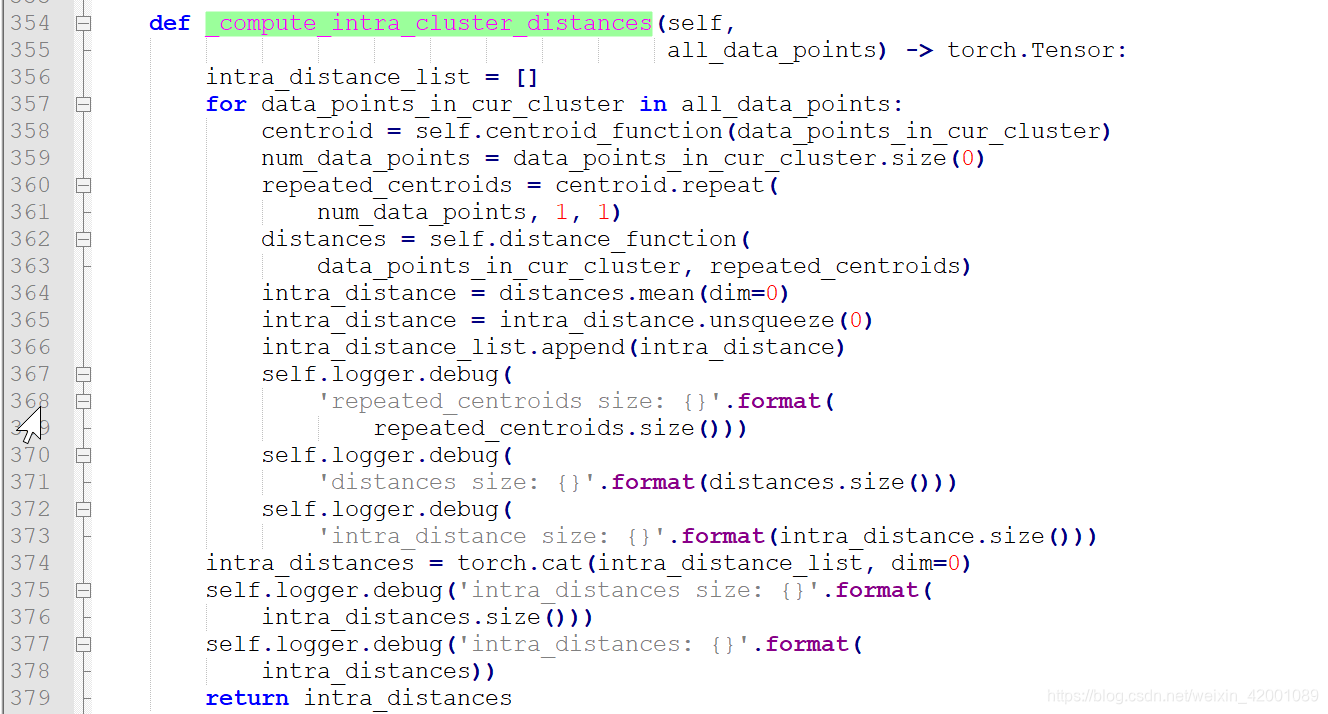
尤其看360行的repeated_centroids是重复了num_data_points次,即公式中的
【_compute_order_loss】

对应到论文的公式如下:旨在为了约束不同连贯性程度的pairs之前满足一个从小到大的排序关系,例如最不连贯的pair对应的分数要小于中等连贯的,中等连贯的又要小于最连贯的,对应到上述代码的部分就是307行
-----------------------------------------------最关键的部分结束---------------------------------------------------------
最后还有一个是_compute_bce_loss,这个就是传统的正负样本,即是不是当前context的reponse,还记得上述说的
[positive_responses_features, adversarial_negative_responses_features, random_negative_responses_features]吗
只不过这里用的score,即
[positive_responses_score, adversarial_negative_responses_score, random_negative_responses_score]

可以看到,270行取第一个即positive_responses_score作为正样本,后面的都是负样本。
小结
通过以上的代码分析,我们再来深入理解一下,这里的预训练思想,首先设置了三个连贯性程度,哪三个连贯性程度呢?那就是:
response_types = [
'positive_responses',
'adversarial_negative_responses',
'random_negative_responses',
]
可以看到positive_responses的连贯性程度应该是最好的,adversarial_negative_responses其次,random_negative_responses最不好。
这三种连贯性对应的样本制作也非常容易,如positive_responses就是真真的上下文对话,random_negative_responses的response就是随机抽样得到的。
进而利用这三个连贯性程度计算三种loss。
每一种连贯性程度下可能有多个样本(即代码中的data_points_in_cur_cluster,paper中的s),那么通过取该连贯性程度下的所有样本平均来求得该程度的一个表征(即代码中的centroid,paper中的e),所以具体来说,代码中在计算paper说的三种loss的时候,基本都有一个centroids列表,那里面可以简单看成就是一个有三元素的列表,分别代表三种连贯性程度的表征(即paper中的e)
第一种loss即compute_separation_loss就是区分三个连贯性程度,尽可能让三种不同的连贯性原理
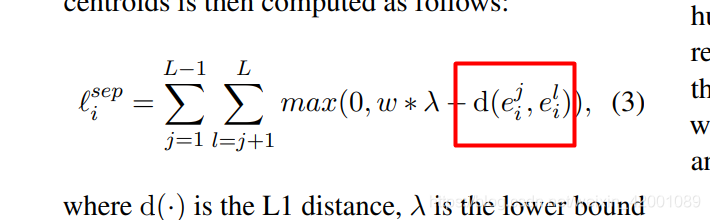
L可以简单理解为上述三种不同的连贯性程度,可以看到当任意两种不同的连贯性的距离程度越大时【红框公式即d】,那么-d就越小,loss就越小,所以优化目标就是不断拉大任意两种不同的连贯性程度。
第二种loss即_compute_compactness_loss,是在各个连贯性程度内部计算的,不涉及到不同性连贯性程度之间的交互,这里的K就可以简单看成每一种连贯性程度下可能有多个样本【也就是多论对话】
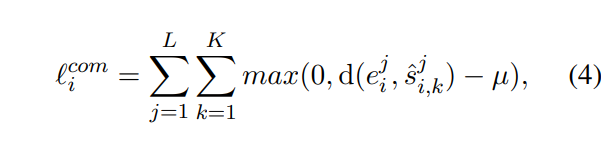
可以看到,e是所有s【当前连贯性程度下】的平均,在同一个连贯性程度下【不论是positive_responses还是adversarial_negative_responses还是random_negative_responses】,所有样本的连贯性程度应该都是一样的,即d越小,loss越小
第三种loss即_compute_order_loss,是加了一个排序过程:
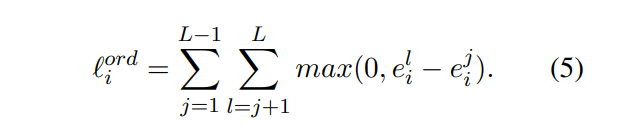
就连贯性程度分数来说:
positive_responses > adversarial_negative_responses > random_negative_responses
对应的编号应该是[2,1,0]
当j=0,l=1,2即j=random_negative_responses,l=adversarial_negative_responses和positive_responses
所以l-j越小越好,因为前者相关性分数应该小于后面,所以loss越小越好,这里面无疑加上了排序。
一开始看论文,笔者也有很大疑惑,不太理解,究其原因主要是不了解公式中的L和K是什么含义,即
L:三种不同的连贯性程度
K:每一种连贯性程度下的样本个数【多轮对话】
最后还有一个_compute_bce_loss,这个很常规啦,没什么说的
fintune
fintune阶段主要就是利用了人工打标的少量样本来让模型学到人类打分的真实标准,这里本来没有什么特别要学的,就是一个监督学习,但是paper中为了不让之前在预训练阶段学习到的量化知识被遗忘掉,引入了一个知识蒸馏正则项,即将预训练后的指标模型(参数冻结,不参与训练)作为teacher,待微调的指标模型作为student,并借鉴TinyBERT的蒸馏目标,约束student的各层输出以及中间层注意力矩阵与teacher的保持一致,所以我们可以借此学习一下蒸馏代码的实现。
主逻辑代码入口是finetune.py,同pretrain阶段一样其实主要是使用了./util/main_utils.py来声明相应的dataset,model,trainer
(1) dataset没啥说的,主入口在dataset/human_judgement_for_fine_tuning.py
和pretrain阶段的基本一样,只不过用的原始数据集是在./data/human_judgement_for_fine_tuning/dailydialog_EVAL下
(2)model也没啥说的,主入口还是model/bert_metric.py
就是用的pretrain阶段训练完的模型来热启的。
(3) trainer,主入口在trainer/trainer_kd_finetune.py,这里比较重要,蒸馏代码就在这里,一起来看一下
主要就是trainer_kd_finetune.py下的KnowledgeDistillationFineTuningTrainer类,首先看一下其初始化:
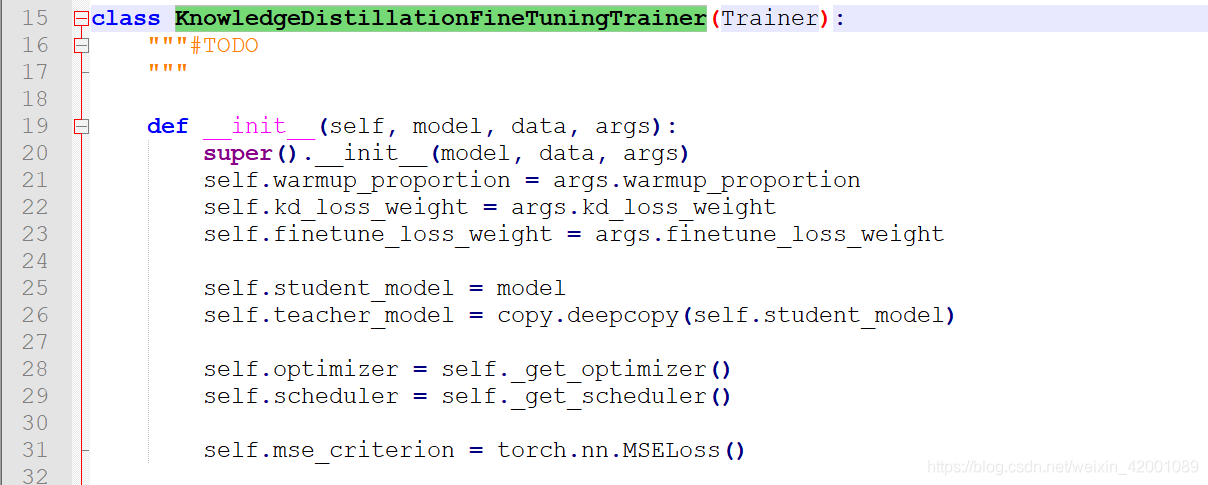
可以看到25-26行,teacher和student的模型结果是一模一样的,通过深copy得到的。
有了teacher和student模型,我们就可以开始蒸馏训练了,类似pretrain的代码主逻辑是在_train_epoch这个类函数上:
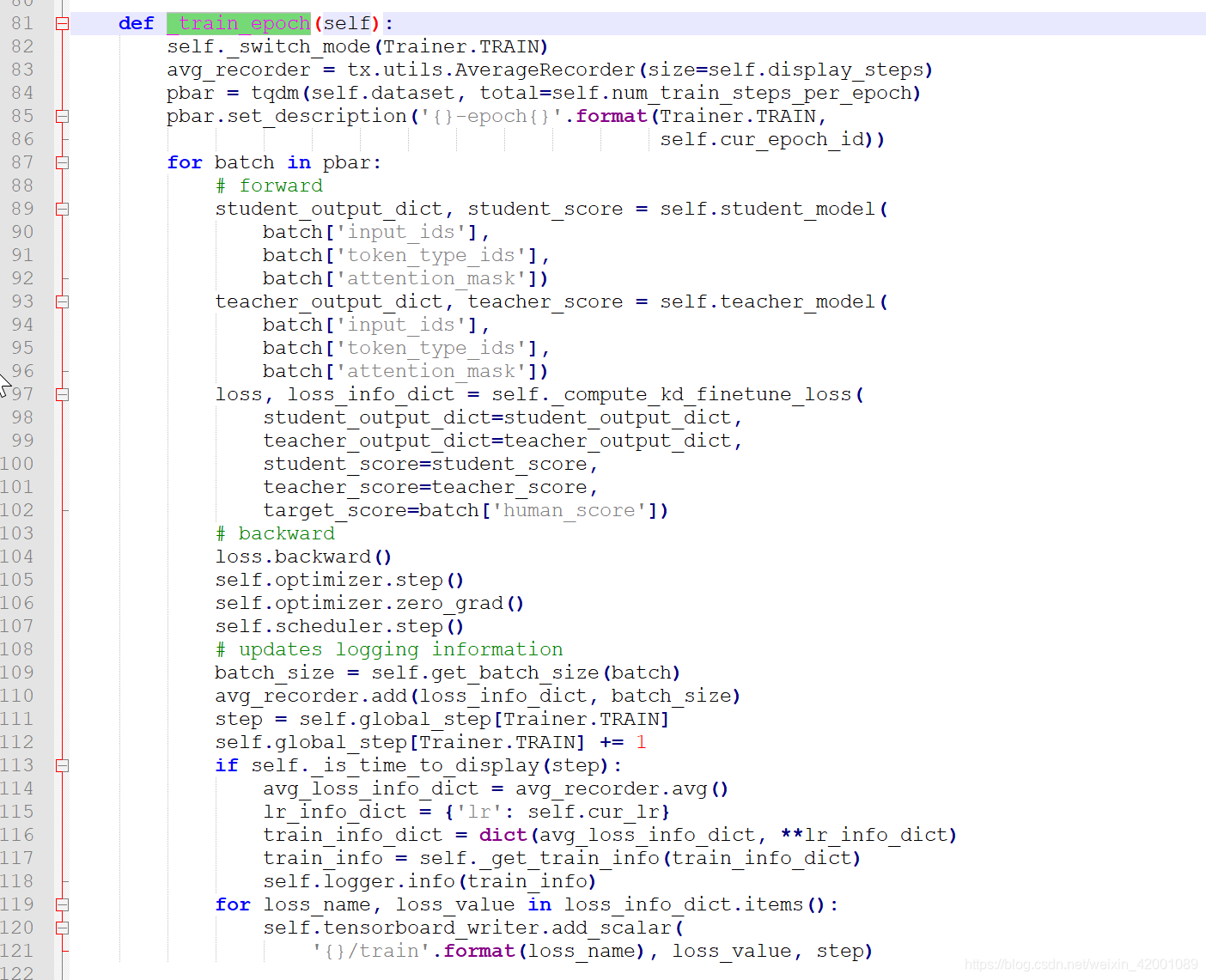
可以清晰的看到首先是89和93行得到teacher和student各自的模型的输出,然后通过97行的_compute_kd_finetune_loss计算得到loss进而网络更新,所以重点看_compute_kd_finetune_loss即可

从这里可以看到其实是两部分loss即
_compute_kd_loss:蒸馏Loss
_compute_finetune_loss:和人工打标的少量监督数据进行有监督学习
【_compute_kd_loss】

从这里的198和206行可以看到,是分别计算了student和teacher各层输出以及中间层注意力矩阵的mse loss,目的就是约束student的各层输出以及中间层注意力矩阵与teacher的保持一致,这其实就是借鉴TinyBERT的蒸馏目标,其次还可以看到200和213行的detach(),其实就是冻结了teacher这些层的更新,只更新student的相应参数。
从这里我们同时学到了一个代码实现的技巧,那就是huggingface的transformers框架,其实是能够直接返回各个中间层的输出以及attentions的输出的
只要在调用API时将output_hidden_states和output_attentions设置为True如下:

随便为了方便取得对应结果,可以将71行的retuen_dict也设置为True,这样在取结果时就很方便,如
取pooler_output:output_dict['pooler_output']
取hidden_states:output_dict['hidden_states']
取attentions:output_dict['attentions']
【_compute_finetune_loss】
这个就是和人工打标的样本进行一个有监督的学习,没什么好说的了,很简单

注意226行有一个predicted_score * 4,之所以乘4是因为,我们模型的预测score是一个sigmod即[0,1],打标的数据是[0,4]的一个连贯性程度,所以乘4正好匹配上。
Evaluation
这里就是评价模型的一些代码,没啥好说的,感兴趣的可以看看,主入口就是/script/eval.sh这里不再累述。
总结
(1) 预训练无监督的构建任务:作者使用了人为定义的三种连贯性程度,且这个定义有一个好处就是可以快速得到相应的标签数据,这个有标签数据无需人工打标。
(2) 使用上述三种连贯性程度的数据,定义了三种Loss来pretrain,其中的_compute_separation_loss和_compute_order_loss涉及到了不同三种连贯性程度的交互,_compute_compactness_loss是同一个连贯性程度自己内部的计算。
(3) 上述(1)的这种无监督构建,非常值得学习借鉴,这无形之中巧妙为后续转化为有监督提供了大前提,(2)这种无监督构建Loss的思路也值得学习。
(4) 蒸馏代码的学习即loss的设计以及teacher网络的detach()
(5) Huggingface的transformer的API学习,即可以返回很多如将output_hidden_states和output_attentions设置为True等等【看fintune一节中的红字】
(6) importlib.import_module这一动态导入包的学习


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









