







 本文探讨了预训练模型的掩码策略,从BERT的mask token到ERNIE的mask entity和n-gram。重点介绍了ERNIE-gram,它是一种显式的n-gram掩码方法,旨在增强粗粒度信息集成。通过结合细粒度和单标识的预测方式,ERNIE-gram能更好地建模n-gram间的依赖关系。此外,动态掩码策略增加了模型的泛化能力。实验结果显示,这些创新策略提升了模型的表现。
本文探讨了预训练模型的掩码策略,从BERT的mask token到ERNIE的mask entity和n-gram。重点介绍了ERNIE-gram,它是一种显式的n-gram掩码方法,旨在增强粗粒度信息集成。通过结合细粒度和单标识的预测方式,ERNIE-gram能更好地建模n-gram间的依赖关系。此外,动态掩码策略增加了模型的泛化能力。实验结果显示,这些创新策略提升了模型的表现。
前言
预训练模型的trick可谓是百花争艳,有从模型入手的,有从数据入手的,今天来说说mask派系,从bert最开始的mask token 到后面ernie的 mask entity以及还有mask n-gram,动态mask等等,都提出很多有意思的idea。
接着百度ernie最新【2021.5.20】放出的ernie-gram,里面也详细的讨论归纳了一些mask策略,一起看一下
需要八卦一下的是:很多ernie的研究【ernie-doc,ernie-gram等等】并没有给出预训练实现代码,只给出训练好的模型和一堆fintune代码,对应用工程来说足够了,但是对应开发者想实现说实话还是不透明,哈哈哈,这毕竟也是人家的技术壁垒,不开源,哈哈哈。
总的来说就是:
bert是开山之作,其最最精华和有看点的就是其MLM的设计,其是一种细粒度的掩码,为了助于在预训练时进行充分的表征学习,后续很多改进工作都是从粗粒度角度进行探究,如实体,n-gram等等,说的更直白点就是从屏蔽单个标记到n个连续序列的标记。这在一定程度上增加模型的学习难度,学出来的模型也更具有泛化性。
但是以往的学习都是整体学习这一连续屏蔽的序列,而忽略了粗粒度语言信息的内在依赖和相互关系的建模,基于此百度提出了ERNIE-gram,一种显式的n-gram掩蔽方法,以增强粗粒度信息集成到预训练
ernie-gram
论文:https://arxiv.org/pdf/2010.12148.pdf
关于解读,已经有很多了,可以看:
这里简单罗列一些比较重要的点
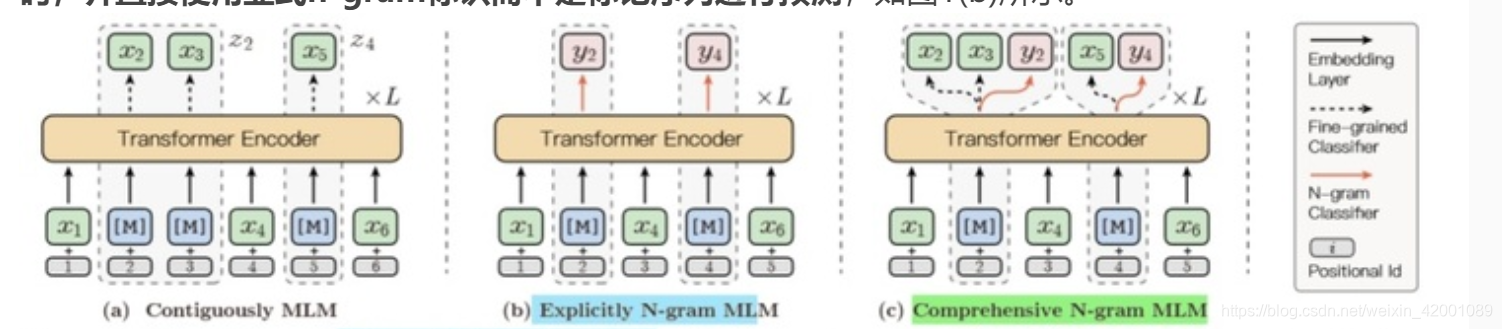
(a)图就是粗粒度,(b)主要就是解决n-gram预测空间,但是其终究还行忽略了一个n-gram内部完整tokens的预测,(c)就是本paper的创新点,综合了前两种,同时以细粒度和单标识[M]粗粒度的方式预测n-grams
主要创新点就是:
(1)提出显示的n-gram掩码即图(c)
那怎么通过一个掩码【M】 恢复n-grams中所有token的表示呢,秘密就在于:
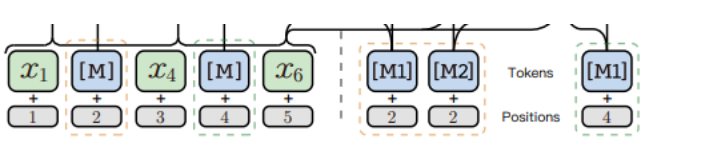
同时认为n-gram的长度信息对表征学习是有害的,因为它会在预测过程中任意删除一些语义相关的不同长度的n-gram,所以一个n-grams只知道整个句子的上下文,每一个token只知道整个句子的上下文+本身,n-grams的长度信息被隐藏了,总的来说如下:
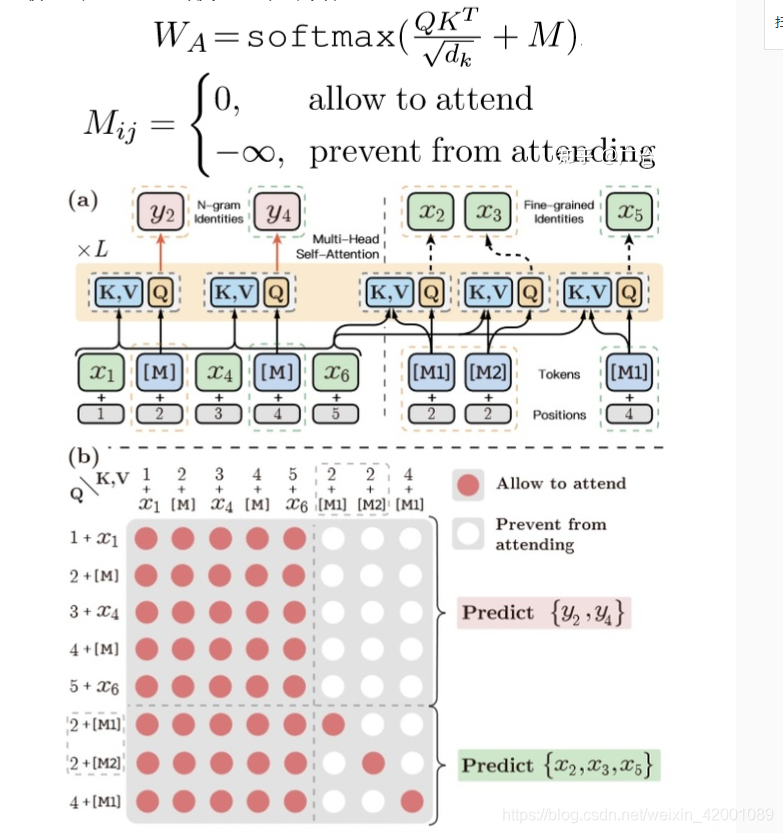
(2)增强的N-gram关系建模
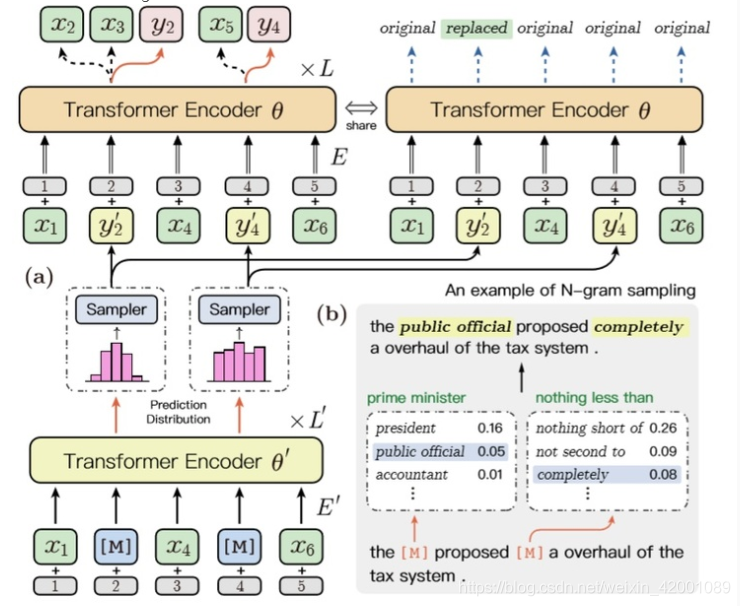
为了明确地学习n-gram之间的语义关系,我们联合训练了一个小的生成器模型θ’与显式n-gram MLM目标函数,以采样n-gram标识。然后利用生成的标识进行掩码,训练标准模型θ以粗粒度和细粒度的方式预测原始的n-gram,如图3(a)所示,该模型可以有效地建模相似的n-gram之间的成对关系。微调时不使用生成器模型。
总的模型就是:
(3)实验结果
肯定是好的啦,具体看论文吧
动态掩码策略
就是每次(epoch)都是随机选择需要掩码序列,不固定,其实就是进一步加大随机性,给模型加大学习难度,增加其泛化性。
总结
掩码策略是魔改预训练模型的一个重要创新方向,可以不断的通过融入新知识使得模型具有泛化性,发挥大家的聪明才智吧
欢迎关注笔者微信公众号,会有更多好文章:


















 9154
9154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









