







1. HQ-SAM(Segment Anything in High Quality)
1.1 面临问题
应用场景:
特别是对于自动注释和图像/视频编辑任务,其中高度准确的图像掩码至关重要。
SAM模型:
(1)预测不正确,mask破损
(2)粗糙的掩码边界
(3)SA-1B数据集会带来巨大的成本影响,并且无法实现我们工作中所追求的高质量掩码
1.2 应用技术
HQ-SAM直接通过重用SAM的图像编码器和掩码解码器来预测新的高质量掩码,在SAM中引入两个新的关键组件,即High-Quality Output Token和Global-local Feature Fusion,实现了高质量的掩码预测。在训练过程中,当我们对预训练的SAM模型参数进行固定时,在HQ-SAM中只有少数可学习的参数是可训练的。
1.3 模型结构
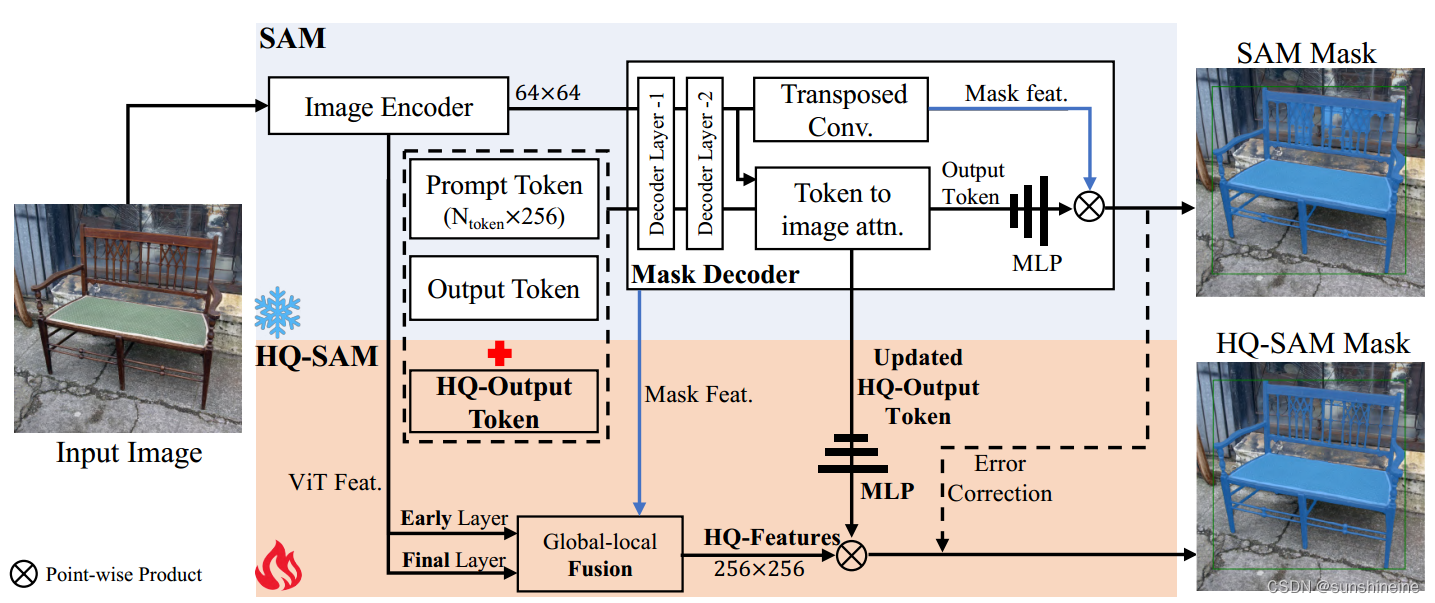
(1) High-Quality Output Token
前言:SAM的原始掩码解码器设计中,采用Output Token(输出令牌)进行掩码预测,预测动态MLP(多层感知机)权重,然后与Mask features(掩码特征)进行逐点积。HQ-Output Token不是只重用SAM的掩码解码器功能,而是在一个精炼的功能集上运行,以实现准确的掩码细节。在训练期间,冻结了整个预训练的SAM参数,同时只更新HQ-Output Token,其相关的三层MLP和一个小的特征融合块。
HQ-SAM整体流程:设计了一个可学习的HQ-Output Token,它与原始的提示Token和输出Token一起输入到SAM的掩码解码器,经过两层解码器,HQ-Output Token使用每个解码器层中其他Token共享的逐点MLP,在每个注意力层中,HQ-Output Token首先与其他Token进行自注意力,然后进行Token到图像和图像到Token的注意力,更新特征形成Updated HQ-Output Token。Updated HQ-Output Token可以访问全局图像上下文、提示Token的关键几何/类型信息以及其他Output Token的隐藏掩码信息。最后,添加了一个新的三层MLP(掩码预测层),从Updated HQ-Output Token生成动态卷积核,然后与融合的HQ-Features进行空间逐点积,以获得高质量的掩码生成。只允许HQ-Output Token及其相关的三层MLP被训练来纠正SAM的Output Token的掩码错误,以预测高质量的分割掩码。
高效token学习的三个主要优点:
1)引入忽略不计的参数,但显著提高了SAM掩码质量,节省HQ-SAM训练时间和数据效率;
2)学习到的token和MLP层不会过度拟合来掩盖特定数据集的标注偏差,从而保持SAM在新图像上强大的zero-shot分割能力,不会发生灾难性的知识遗忘。
3)带有可学习参数的提示符旨在帮助下游任务更好地进行上下文优化,与现有的基于提示或微调的工作不同,更关注SAM对高质量分割的最小适应。
(2)Global-local Feature Fusion
非常精确的分割还要求输入图像特征具有丰富的全局语义上下文和局部边界细节。将SAM的掩码解码器的Mask Features与ViT编码器的早期和后期特征映射融合在一起,首先通过转置卷积将早期层和后期层ViT编码器特征上采样到空间大小256×256。然后,经过简单的卷积处理,以元素的方式总结了这三种类型的特征,同时使用了全局语义上下文和局部细粒度特征,最终得到HQ-Features。这种全局-局部特征融合是简单而有效的,产生了保留细节的分割结果,内存占用和计算负担很小。
2. PA-SAM( Prompt Adapter SAM for High-Quality Image Segmentation)
2.1 面临问题
SAM模型:
(1)SAM在生成精细的掩码边界和细节预测方面存在局限性,例如在处理网球拍、椅子等对象时,SAM生成的掩码边界较为粗糙,对于风筝线和昆虫触角等细节的预测也存在错误。
(2)SAM分割质量很大程度上取决于输入到掩码解码器的提示符是否能携带详细的信息。
2.2 应用技术
(1)在SAM的掩码解码器中提出了一个可训练的提示驱动适配器,它通过自适应细节增强和硬点挖掘来改进网络对不确定区域的学习。该模块的目标是将图像的详细信息集成到网络中,以提高对细节的敏感度和分割质量。
(2)自适应细节增强:捕获高质量的细节信息。
密集提示补偿:设计了一个补偿模块来编码原始图像及其梯度,以解决在图像编码过程中由于下采样导致的细节信息损失问题。
稀疏提示优化:优化稀疏提示特征,使详细信息流入稀疏提示,增强模型对高质量图像分割的引导。
(3)硬点挖掘:该方法使用稀疏提示直接指导细节特征。
硬点挖掘利用、
和
构建采样挑战点的指导。例如,在正点采样中,首先构建初始采样指导,然后在训练阶段使用Gumbel top-k操作来确保采样点的多样性。通过这种方式,可以对PA密集提示进行点采样,得到新的正点。
2.3 模型结构
PA-SAM的总体架构如下图所示,以掩码解码器为中心,分为左输入(原始SAM解码器输入)、解码器内部和输出、右输入(提示适配器PA)三部分讲解,整体流程如下:

(1)左输入
(1)输入图像进入图像编码器(Image Encoder),生成图像嵌入。
(2)输入掩码进入掩码编码器(Mask Encoder),编码为密集提示(dense prompts)。
(3)输入点或框进入提示编码器(Prompt Encoder),编码为稀疏提示(sparse prompts)。
(4)Image Position Embedding:图像位置嵌入,为图像中的每个像素分配一个唯一的位置标识,用于表示输入图像中不同位置的特征,有助于模型理解图像中的空间结构。
将上述四种输入到掩码解码器中。
(2)右输入
为了捕获高质量的细节信息,我们的思路是将图像细节转化为多粒度提示特征,以提示驱动的方式对SAM进行微调,提出了一个可训练的提示驱动适配器(Prompt Adapter)。它将图像特征与密集提示(dense prompts)相结合,并将其与稀疏提示(sparse prompts)一起发送给掩码解码器。在掩码解码器中,所提出的提示适配器将图像特征和稀疏提示分别转换为密集和稀疏适配器提示跟随每个块的自关注。随后,以残差方式将输出提示特征重新集成到PA-SAM中,优化掩码解码器的特征表示。在该架构中,模型可同时利用详细和不太详细的信息,从而提高分割的质量。
(3)解码器内部和输出
(1)Decoder Embeddings:这部分是解码器的输入层,负责将编码器和提示适配器(Prompt Adapter)传递过来的信息转换成适合解码器处理的嵌入表示。这些嵌入表示包含了图像的特征和用户提供的提示信息,它们将作为解码器后续处理的基础。
(2)Self Attn.:自注意力机制,允许解码器在生成输出时考虑之前生成的标记。这种机制有助于模型捕捉序列数据中的依赖关系。
(3)Token to Image Attn.:标记到图像注意力,这个组件将解码器中的标记特征与原始图像特征进行关联。通过这种方式,模型能够在生成输出时利用原始图像的详细信息,提高分割掩码的准确性。
(4)MLP:多层感知机,在解码器中用于处理来自图像到标记注意力的输出,进一步提炼和转换特征表示。
(5)Image to Token Attn.:图像到标记注意力,这个组件负责将图像特征转换为标记,并通过注意力机制对这些标记进行加权。这个过程使得模型能够关注输入图像中的重要部分,并为后续的处理步骤提供重点信息。
(6)Last layer:这是解码器的输出层,负责生成最终的分割掩码。再将掩码传送到掩码预测模型(Mask Prediction Module)中,生成最终的损失,计算模型预测掩码与真实掩码之间的差异
3. WSI-SAM(WSI-SAM: Multi-resolution Segment Anything Model (SAM) for histopathology whole-slide images)
3.1 面临问题
(1)现有分割模型通常是为特定的分割任务设计和训练的,这极大地限制了在临床实践中更广泛应用的推广。
(2)现有的医学SAM不适合全载玻片图像(WSIs)的多尺度性质,限制了它们的有效性。
3.2 应用技术
(1)高分辨率和低分辨率令牌:引入了HR和LR令牌沿着一个新的掩码预测层,从而在多个分辨率下实现精细的掩码预测。
(2)双掩码解码器:提出了双掩码解码器,其中包括SAM掩码解码器和轻量级融合模块。融合模块中同时包含高级对象上下文和低级边界/边缘细节。
(3)令牌聚合:这些令牌以不同的分辨率表示同一对象的特征,将空间逐点乘积应用于HR和LR掩码特征以促进掩码生成。
3.3 模型结构
通过结合不同分辨率的信息来提高分割的准确性,同时保持了模型的零样本能力。通过这种方式,WSI-SAM能够有效地处理全切片图像中的多尺度问题。
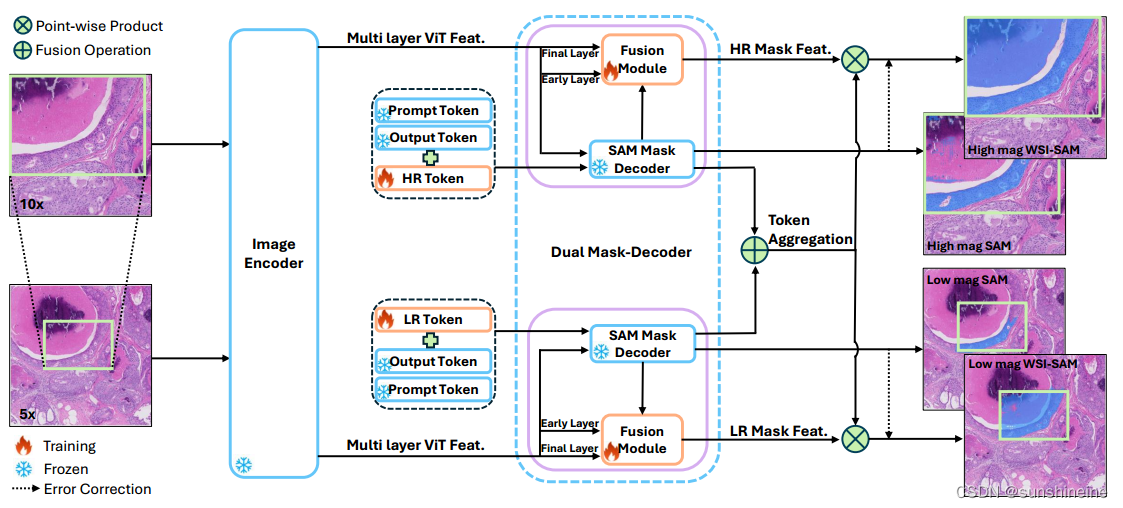
输入图像首先通过图像编码器Image Encoder进行特征提取,并生成图像嵌入。提示编码器Prompt Encoder处理输入的提示信息。然后,HR和LR令牌分别与相应分辨率的图像特征进行交互。这些特征通过Dual Mask Decoder双掩码解码器进行处理,双掩码解码器由原始的SAM掩码解码器和一个轻量级融合模块Fusion Module组成。Fusion Module融合模块结合了来自ViT编码器的早期和晚期特征,以及SAM掩码解码器的特征,通过点乘操作将不同层次的ViT特征与HR和LR的掩码特征结合起来。最后,通过Token Aggregation令牌聚合(平均合并更新后的HR和LR令牌,以捕获多分辨率的上下文信息)和Fusion Operation融合操作(通过点乘(Point-wise Product)将HR和LR掩码特征结合起来)生成最终的掩码预测。
4. Semantic-aware SAM for Point-Prompted Instance Segmentation
4.1 面临问题
SAM模型:
(1)SAM 的一个限制在于其缺乏分类能力,导致类别无关的分割结果,无法根据需要准确分割特定类别——SAM 的输出与类别无关,无法区分不同类别的实例。
(2)SAM 对局部分割具有高度可信度,即使局部区域不属于实例,SAM 也可能会为其分配高分。这会导致生成的掩码建议不完整,甚至包含多个实例。
4.2 应用技术
(1)设计了一个语义感知实例分割网络(SAPNet),该网络集成了具有匹配能力的多实例学习(MIL)和具有点提示的SAM。
(2)SAPNet策略性地选择由SAM生成的最具代表性的掩码建议来监督分割,并特别关注对象类别信息。
(3)引入了点距离引导和框挖掘策略来缓解弱监督分割的固有挑战:群体和局部问题。
4.3 模型结构
SAPNet(Semantic-Aware Instance Segmentation Network)的模型结构是一个端到端的系统,专门为点提示实例分割任务设计,既能够处理从点注释到掩码提议的转换,也能够通过精炼和分割指导来提高分割质量。该模型结构可以分为两个主要部分:一部分用于生成掩码提议(mask proposals),另一部分用于实例分割。SAPNet能够在点提示实例分割任务中实现高性能,同时保持训练和推理的效率。
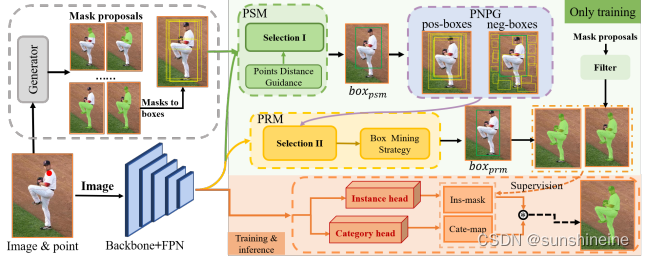
(1)生成初始掩码框
图像和点输入(Image & point input):模型接收输入图像和与之相关的点注释。
Backbone + FPN(特征金字塔网络):使用一个预训练的卷积神经网络作为主干网络(Backbone),例如ResNet,结合特征金字塔网络(FPN)来提取多尺度的特征图,这些特征图将用于后续的提议生成和分割。
Mask proposals:使用SAM生成类别无关的掩码提议。
(2)生成正负样本框
Proposal Selection Module (PSM):该模块使用多实例学习(MIL)和点距离惩罚机制(PDG,为了解决相邻对象的区分问题,通过计算提议区域内标注点之间的欧几里得距离来指导选择过程)从多个提议中选择出最有代表性的掩码,为每个对象生成一个丰富的语义提议。
正负样本生成器 Positive and Negative Proposals Generator (PNPG):该模块基于PSM阶段选择的正样本提议(pos-boxes),生成更多的正样本提议,并通过负样本提议(neg-boxes)来帮助模型训练,解决背景噪声和局部预测问题。
(3)精炼框
提议精炼模块 Proposals Refinement Module (PRM):PRM结合正样本提议和初始集合,形成一个丰富的正样本集合,通过Focal Loss和专门的损失函数来优化负样本,进一步精炼提议。
框挖掘策略 Box Mining Strategy (BMS):BMS通过动态扩展PRM阶段选定的提议框来解决局部问题,确保边界框与对象的真实边界一致。
to
:将精炼后的提议转换为用于实例分割的边界框。
(4)预测掩码
Instance head:使用生成的边界框来指导实例分割,生成每个实例的掩码。
Category head:生成类别映射(Cate-map),有助于确定每个提议的类别。
训练与推理(Training & Inference):在训练阶段,模型使用上述所有组件来优化分割性能。在推理阶段,只保留分割分支,使用高效的Matrix-NMS技术直接生成掩码预测。
5. Open-Vocabulary SAM: Segment and Recognize
Twenty-thousand Classes Interactively
5.1 面临问题
(1)SAM 在其原始设计中缺乏对其所分割对象的识别能力。
(2)CLIP 使用图像级对比损失进行训练,在密集预测任务方面面临挑战。
5.2 应用技术
利用两个独特的知识转移模块SAM2CLIP和CLIP2SAM,同时进行交互式分割和识别。前者通过蒸馏和可学习的变压器适配器将SAM的知识融入到CLIP中,后者将CLIP的知识融入到SAM中,增强了SAM的识别能力。
5.3 模型结构
(1)三种SAM和CLIP结合的对比

Image Cropping Baseline (a):使用 SAM Decoder 生成分割掩码。将原始输入图像根据 SAM Decoder 的输出进行裁剪。裁剪后的图像作为 CLIP Visual Encoder 的输入。CLIP Text Encoder 和裁剪后的图像特征一起用于文本嵌入和对象识别。
Feature Cropping Baseline (b):类似于 (a),但SAM Decoder 预测的分割掩码不是裁剪原始图像,而是用于裁剪 CLIP 模型提取的特。裁剪后的特征通过一个适配器进行处理,以改善模型在下游任务上的性能。
Our Single Encoder Design (c):这是一个统一的架构设计,将 CLIP Visual Encoder 作为主特征提取器。SAM2CLIP 模块通过蒸馏和适配器将 SAM 的知识转移到 CLIP 模型中。CLIP2SAM 模块将 CLIP 的知识转移到 SAM Decoder,增强其识别能力。该设计避免了使用两个独立的编码器,减少了计算成本,并允许模型在分割和识别任务上进行联合训练。
(2)整体结构
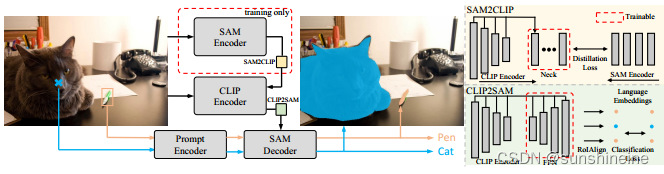
SAM2CLIP:通过知识蒸馏 (Knowledge Distillation)、多尺度特征适配 (Multi-Scale Feature Adaptation)和变换适配器 (Transformer Adapter)将SAM的知识融入到CLIP中。
多尺度特征适配 同时考虑了图像的高分辨率细节和高层次的语义信息,有助于 CLIP 模型更全面地理解和对齐 SAM 模型的特征表示。变换适配器包含一个轻量级的变换适配器,它使用像素级蒸馏损失 (pixel-wise distillation loss) 来对齐 CLIP 特征和 SAM 特征。SAM2CLIP 使用 MSE 损失函数来最小化 SAM 特征和适配器输出特征之间的差异,从而实现特征对齐。
CLIP2SAM:旨在将 CLIP 模型的视觉和语言知识整合到 SAM 解码器中,以提升对图像中对象的识别性能。使用特征金字塔网络 (Feature Pyramid Network, FPN)来提取多尺度的 CLIP 特征,这些特征包含了不同层次的视觉信息,有助于处理不同大小的对象。通过区域感兴趣对齐 (RoIAlign)操作,CLIP2SAM 从多尺度特征中提取与特定区域(如由 SAM Decoder 生成的分割掩码所定义的区域)相对应的特征。
6. SAM-CLIP: Merging Vision Foundation Models towards
Semantic and Spatial Understanding
6.1 面临问题
CLIP模型擅长语义理解,而SAM模型擅长空间理解,特别是在图像分割任务中。
6.2 应用技术
CLIP擅长于语义理解,而SAM擅长于分割的空间理解。我们的方法集成了多任务学习、持续学习和升华技术。此外,与传统的从头开始的多任务训练相比,它所需的计算成本要低得多,并且只需要最初用于训练单个模型的预训练数据集的一小部分。通过将该方法应用于SAM和CLIP,我们得到了SAM-CLIP:一个将SAM和CLIP的功能结合在一起的统一模型。与独立部署SAM和CLIP相比,我们的合并模型SAM-CLIP降低了推理的存储和计算成本,使其非常适合边缘设备应用。
6.3 模型结构
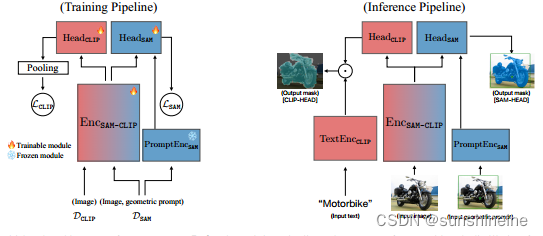
(1)训练通道
EncSAM-CLIP是合并后的图像编码器,用于生成图像特征。PromptEncSAM是提示编码器,处理几何提示(如点、掩码区域或边界框)。HeadCLIP和HeadSAM是两个任务特定的头部,分别从CLIP和SAM模型中继承而来。
(2)推理通道
- 输入图像和文本提示进入文本编码器 (Text Encoder),将文本提示转换为嵌入向量。
- 输入图像进入共享的图像编码器 (Image Encoder),提取图像的视觉特征。
- 输入几何提示(点、边界框或掩码区域)进入提示编码器 (Prompt Encoder),将其编码为可以用于分割任务的格式。
- 分类头部 (Classification Head):
HeadCLIP使用图像编码器的输出来进行分类任务。它将图像特征与文本嵌入进行比较,以执行如零样本分类的任务。 - 分割头部 (Segmentation Head):
HeadSAM则利用图像编码器的输出和提示编码器的信息来生成分割掩码。在实例分割任务中,它使用几何提示来预测对象的分割掩码。 - 内积 (Inner Product):在图像-文本任务中,使用内积(
⊙表示)来计算文本嵌入和图像块嵌入之间的相似度,用于评估图像和文本之间的对齐程度。
7. MATCHER: SEGMENT ANYTHING WITH ONE SHOT USING ALL-PURPOSE FEATURE MATCHING
7.1 面临问题
应用场景:
(1)Matcher框架可以有效地解决语义分割、目标部分分割和视频目标分割等多样化感知任务。
(2)Matcher可以有效地处理各种复杂、真实的环境下的感知任务(在野外图像)表现出强大的泛化能力。
SAM模型:
(1)语义类别的缺失:SAM不能为预测的掩码提供语义类别信息。
(2)多义性掩码输出:SAM倾向于预测多个模糊的掩码输出,这使得为不同任务选择适当的掩码作为最终结果变得困难。
(3)任务特定结构的需求:不同的分割任务涉及复杂多样的感知需求,此外,不同任务的结构差异也需要考虑,包括从个体部分到完整实体以及多个实例的不同语义粒度。简单地组合基础模型可能会导致性能不佳。
7.2 应用技术
提出了一种新的感知范式Matcher,它利用现成的视觉基础模型来解决各种感知任务。Matcher可以在没有训练的情况下使用上下文示例来分割任何东西。此外,我们在Matcher框架内设计了三个有效的组件来与这些基础模型协作,并在不同的感知任务中释放它们的全部潜力。
7.3 模型结构
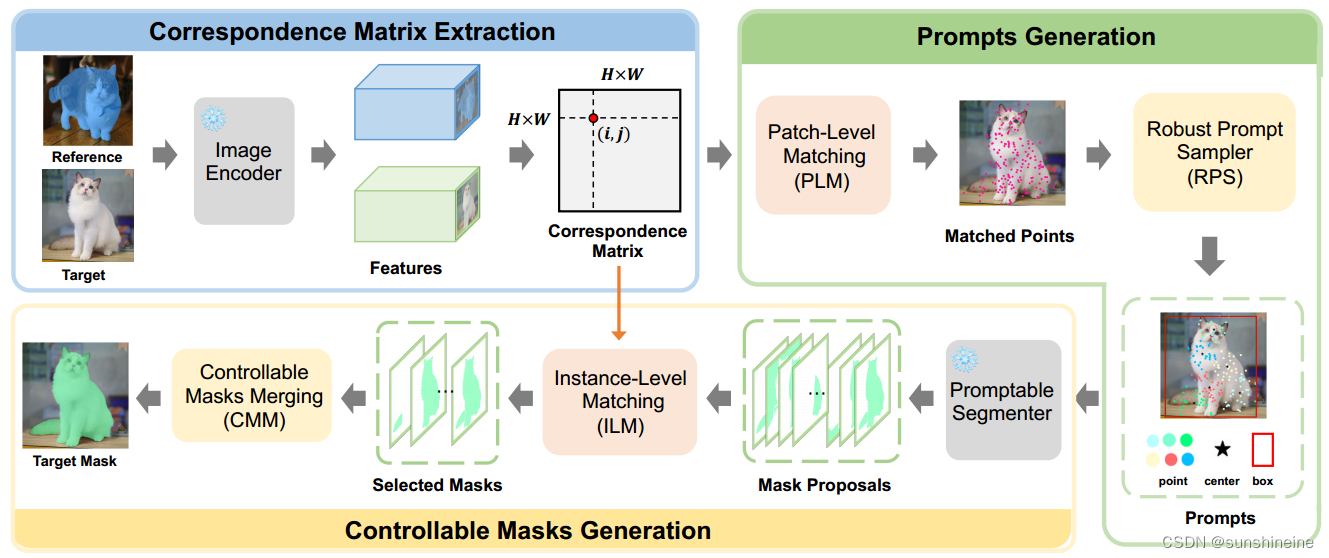
该模型用于处理各种分割任务,如语义分割、对象部分分割和视频对象分割。模型的结构可以分为三个主要的操作部分:Correspondence Matrix Extraction(对应矩阵提取)、Prompts Generation(提示生成)和Controllable Masks Generation(可控掩码生成)。下面是对每个部分的详细解释:
-
Correspondence Matrix Extraction (CME) - 对应矩阵提取:
- 在这个阶段,模型使用图像编码器(Encoder)来提取参考图像(Reference Image)和目标图像(Target Image)的块级(Patch-Level)特征。
- 通过计算两幅图像特征之间的相似度,构建一个对应矩阵(Correspondence Matrix),该矩阵用于发现参考掩码(Mask)在目标图像上的最佳匹配区域。
-
Prompts Generation (PG) - 提示生成:
- 包含两个子步骤:
- Patch-Level Matching (PLM) - 块级匹配:使用对应矩阵来进行块级匹配,找到目标图像中最相似的区域。
- Robust Prompt Sampler (RPS) - 鲁棒提示采样器:在匹配点的基础上,采用鲁棒的采样策略生成多种提示(Prompts),这些提示将作为输入传递给分割模型。
- 包含两个子步骤:
-
Controllable Masks Generation (CMG) - 可控掩码生成:
- 同样包含两个子步骤:
- Instance-Level Matching (ILM) - 实例级匹配:在参考掩码和候选掩码之间执行实例级匹配,使用最优传输(Optimal Transport)问题和地球移动者距离(Earth Mover’s Distance, EMD)来计算掩码之间的结构距离,从而选择高质量的掩码。
- Controllable Masks Merging (CMM) - 可控掩码合并:通过控制合并掩码的数量,生成目标图像中相同语义实例的可控掩码输出。
- 同样包含两个子步骤:
整个流程是一个无需训练的框架,它通过上述三个步骤整合了通用特征提取模型(如DINOv2)和类无关分割模型(如SAM),以实现对给定上下文示例(包括参考图像和掩码)的目标图像进行分割。这个模型在多种分割任务上展示了出色的泛化性能,并且所有的这些操作都是在没有训练的情况下完成的。
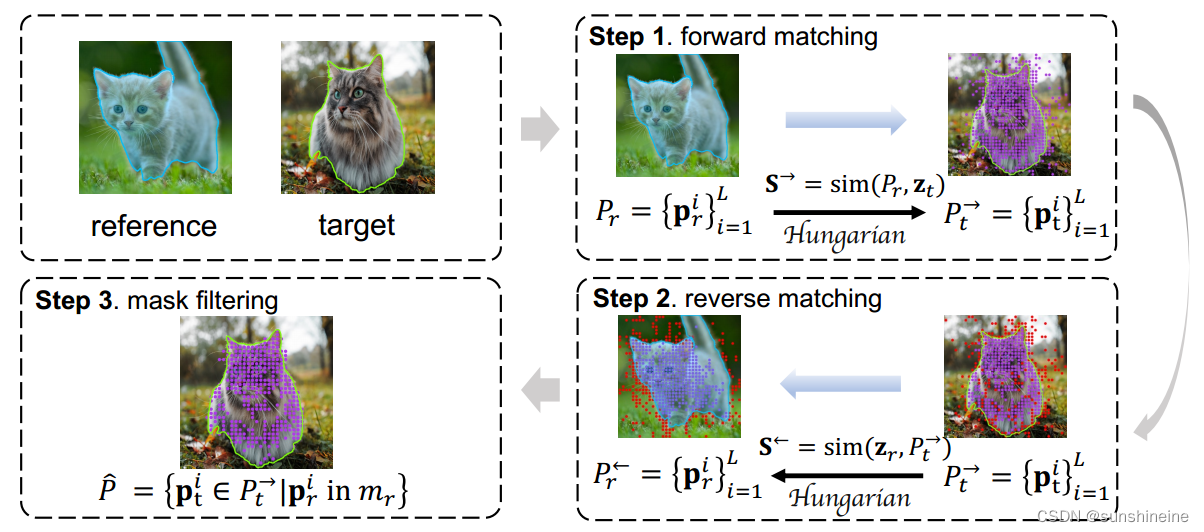 在Matcher模型中,双向匹配(Bidirectional Matching)被用于Patch-Level Matching(块级匹配)的过程中,以提高匹配的准确性并减少异常值(outliers)的影响。双向匹配包括以下三个步骤:
在Matcher模型中,双向匹配(Bidirectional Matching)被用于Patch-Level Matching(块级匹配)的过程中,以提高匹配的准确性并减少异常值(outliers)的影响。双向匹配包括以下三个步骤:
-
前向匹配(Forward Matching):
- 在这个步骤中,模型首先使用前向对应矩阵(S→)在参考掩码(Pr)和目标图像特征(zt)之间执行二分图匹配,找到目标图像中与参考掩码点最匹配的点(P→t)。
-
反向匹配(Reverse Matching):
- 接下来,模型执行一个名为反向匹配的过程,使用反向对应矩阵(S←)在前向匹配得到的点(P→t)和参考图像特征(zr)之间进行匹配,得到反向匹配点(P←r)。
-
掩码过滤(Mask Filtering):
- 最后,模型在前向匹配集中筛选点,如果对应的反向匹配点不在参考掩码(mr)上,则这些点被视为异常值并被过滤掉。最终的匹配点集合为 ˆP = {pi t ∈ P → t |pi r in mr}。
通过这种双向匹配策略,Matcher模型能够更精确地定位目标图像中与参考掩码相对应的区域,从而生成更高质量的分割掩码。这种策略特别有助于处理那些上下文不明确或包含多个实例的困难情况,因为它能够减少错误匹配的点,从而提高最终分割结果的准确性。
8. Semantic-SAM: Segment and Recognize Anything at
Any Granularity
8.1 面临问题
8.2 应用技术
我们的模型提供了两个关键优势:语义感知和粒度丰度。为了实现语义感知,我们跨粒度整合多个数据集,并对解耦的对象和部件分类进行训练。这使得我们的模型能够促进丰富语义信息之间的知识转移。对于多粒度能力,我们提出了一个多选择学习方案,使每个点击点能够在多个级别上生成对应于多个groundtruth掩码的掩码。
8.3 模型结构
9. SAM-based instance segmentation models for the automation of structural damage detection
9.1 面临问题
基于土建结构外观缺陷的自动化视觉检测是至关重要的,因为它目前是劳动密集型和耗时的性质。自动检测的一个重要方面是图像采集,考虑到近年来软件和硬件计算的普遍发展,图像采集具有快速和经济的特点。以前的研究主要集中在混凝土和沥青上,对砌体裂缝的关注有限,而且缺乏公开的数据集。
9.2 应用技术
通过引入“MCrack1300”数据集来解决这些差距,该数据集由1300张带注释的图像(640像素× 640像素)组成,包括砖、碎砖和裂缝,例如分割。我们评估了几种领先的基准测试算法,并提出了两种新颖的、自动执行的方法,基于最新的视觉大规模模型,即基于提示的分段任意模型(SAM)。我们使用低秩自适应(LoRA)对SAM的编码器进行微调。第一种方法包括放弃提示编码器并将SAM的编码器连接到其他解码器,而第二种方法引入了可学习的自生成提示器。我们重新设计了特征提取器,使两种方法与SAM编码器无缝集成
9.3 模型结构
10. Knowledge distillation with Segment Anything (SAM) model for Planetary Geological Mapping
10.1 面临问题
(1)行星地质图像标记和处理成本高昂且十分耗时,手动标记这些图像是一项复杂且具有挑战性的任务,需要大量的领域知识和精力。
(2)SAM 框架分割精度高,但是缺乏特定于问题的偏差,它无法直接应用于特定领域的任务。
10.2 应用技术
(1)知识蒸馏和SAM的方法,以加速行星地质绘图中的特征识别和区域划分。
(2)轻量级的领域特定解码器:研究者训练一个轻量级的领域特定解码器,而不是直接微调(fine-tune)SAM的解码器,原因是SAM 模型是在一般性的世界案例场景下训练的,它可能并不具备特定于行星地质绘图任务的领域偏见。另外 SAM 的解码器可能过于泛化,难以在没有额外信息的情况下精确地适应特定的地质绘图任务。它能够从SAM模型的图像编码器生成的嵌入中学习问题特定的语义。
(3)增量训练样本:不需要大量的标注数据,通过使用少量标注图像训练领域解码器,使图像标注效率得到提升。
(4)选择适当的提示模式:研究者评估了SAM模型在三种不同的提示设置下的表现:自动提示模式、点提示模式和框提示模式。自动提示模式会生成单点输入提示,并使用非极大值抑制选择高质量遮罩。点提示模式使用感兴趣区域的中心作为提示。框提示模式则计算了围绕真实遮罩的边界框。
10.3 模型结构
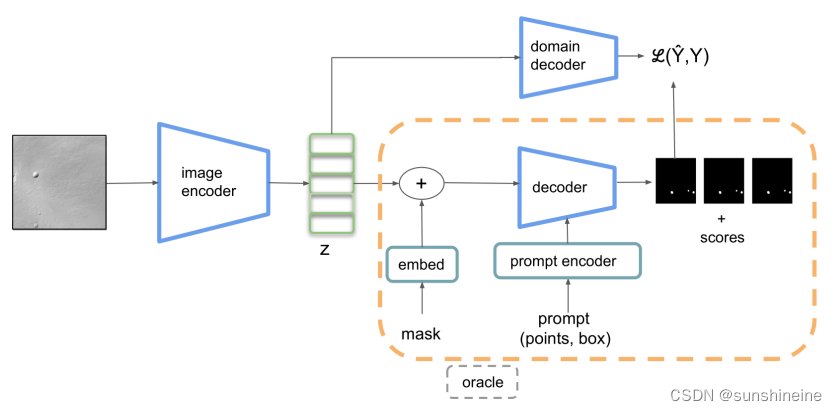
(1)知识蒸馏
首先,使用SAM的图像编码器(教师模型)处理输入图像,得到瓶颈特征。这些特征是高维的,并且捕获了图像中的视觉信息,但尚未直接对应于分割掩码。瓶颈特征随后被送入领域特定解码器(学生模型),从教师模型提取的特征中学习到特定于火星表面地貌(如坑洞和天窗)的分割任务的语义信息。
(2)领域特定解码器
这个解码器由几个上采样层组成,这些层通常使用反卷积(deconvolution)或转置卷积(transposed convolution)操作,将SAM编码器的瓶颈特征映射回原始图像的空间分辨率。用于将SAM编码器的输出(瓶颈特征)映射回图像空间,生成精确的分割掩码。在训练领域解码器的过程中,SAM的图像编码器的权重被冻结,即不更新其权重,保持图像编码器的稳定性,同时让领域解码器学习到特定任务的语义信息。领域解码器的最后通常使用sigmoid激活函数,将输出的logits映射到[0, 1]的范围内,这代表了分割掩码的概率分布,其中1表示像素属于前景,0表示像素属于背景。
(3)增量训练样本
图中橙色框内表示的 SAM 提示编码器和掩码解码器仅用于增量注释的训练样本。它从少量的标注样本开始训练,并逐步增加训练样本的数量,为了模拟标注资源有限的实际应用场景。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









