











------------------------------------------------------------------------------------------------------------------------------------------------------------------------
前言:
上面是赛题,由于时间有点紧,所以没有做过多的特征处理,仅仅挖掘了一部分特征,其实还有其他大量特征待挖掘,有兴趣的小伙伴可以思考一下,下面仅仅是抛砖引玉
--------------------------------------------------------------------------------------------------------------------------------------------------------------
特征处理:
1)时间转化,将其转化为距离借钱日期的天数,并根据日期划分训练集和测试集

2)划分训练集和测试集

3)获取客户个人属性以及label,对性别进行one-hot编码({'\\N', 'F', 'M'})
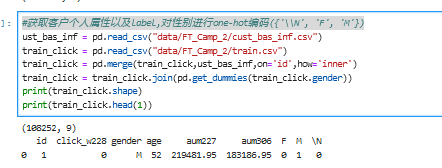
4)将上述信息合并到训练集和测试集

5)提取与收出信息相关的特征
这里包括客户的支出情况,收入情况,总体情况以及最后10天的情况,以下是部分截图

6)制作完整的测试集
由于待测试的部分客户可能没有支出收入,故没有交易记录,所以我们也要考虑到这部分客户

7)去除非法字符串\\N
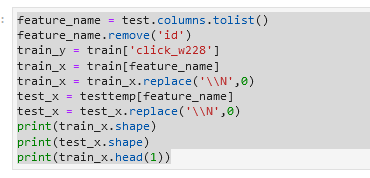
这个应该是年龄下的,这里可是试着将这部分样本剔除
8)提取feature 和label
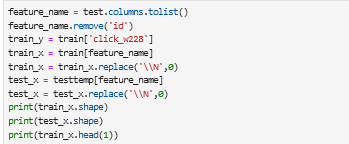
训练模型:
以下是部分截图




提交后结果是0.67,还有很大改进空间
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
思考:
可以看到上面只是一个baseline,分数当然也不是很好,有时间的话可以考虑如下
1)有两个文件的信息还没进行挖掘即g2.csv 和trx_cod.csv
2)以上在计算一个客户的支出消费情况时,是直接统计的,可以考虑每个客户下按天为单位进行统计
3)从上面特征的重要度可以看出关于最后10 天的的相关特征还是很重要的,可以考虑统计最后5天,15天等
4)增加其他统计量
5)其实还可以更无赖,那就是先看看测试集上面客户的id,然后在训练集上面找到对应的人,看看其以前有没有进行借款,如果有那么其很有可能下次还借是吧!
......................................
当然不仅限于以上,所以说:可挖掘的东西还有很多。
补充第一名代码:
import pandas as pd
import numpy as np
import xgboost as xgb
from sklearn.model_selection import StratifiedKFold, KFold
import matplotlib.pyplot as plt
from sklearn import preprocessing
import warnings
warnings.filterwarnings('ignore')
transaction_history = pd.read_csv('data/FT_Camp_2/sz_detail.csv')
sz_id_inf = pd.read_csv('data/FT_Camp_2/trx_cod.csv')
g2_cod_inf = pd.read_csv('data/FT_Camp_2/g2.csv')
cuts_inf = pd.read_csv('data/FT_Camp_2/cust_bas_inf.csv')
## 用户信息, 性别转类别特征,划分年龄区间
cuts_inf['gender'] = cuts_inf['gender'].astype('category').cat.codes
cuts_inf['age'] = cuts_inf.age.apply(lambda x: int(x) if x not in ['3', '\\N'] else np.nan)
cuts_inf['age_range'] = pd.cut(cuts_inf['age'], [0, 19, 29, 39, 49, 59, 100], labels=False).astype('category').cat.codes
cuts_inf['aum227'] = cuts_inf.aum227.apply(lambda x: float(x) if x != '\\N' else np.nan)
cuts_inf['aum306'] = cuts_inf.aum306.apply(lambda x: float(x) if x != '\\N' else np.nan)
## 收支分类 转类别特征
sz_id_inf['cat1'] = sz_id_inf['cat1'].astype('category').cat.codes
## sz_id g2 类别编码 train test 保持一致的编码
transaction_history = transaction_history.sort_values(['id', 'prt_dt']).reset_index(drop=True)
transaction_history['g2_cod'] = transaction_history['g2_cod'].fillna('-1')
sz_le = preprocessing.LabelEncoder()
sz_le.fit(transaction_history.sz_id.values)
g2_le = preprocessing.LabelEncoder()
g2_le.fit(transaction_history.g2_cod.values)
### 特征提取函数
def get_feature(end_time, data_name):
if data_name == 'train':
data = pd.read_csv('data/FT_Camp_2/train.csv')
else:
data = pd.read_csv('data/FT_Camp_2/pred_users.csv')
transaction_history_data = transaction_history[(transaction_history['prt_dt']<=end_time)].reset_index(drop=True)
## 将一些辅助类别信息补充到交易信息表里
transaction_history_data = pd.merge(transaction_history_data, cuts_inf[['id', 'gender', 'age', 'age_range']], on=['id'], how='left')
transaction_history_data = pd.merge(transaction_history_data, sz_id_inf[['sz_id', 'cat1']], on=['sz_id'], how='left')
transaction_history_data['sz_id'] = sz_le.transform(transaction_history_data['sz_id'].values)
transaction_history_data['g2_cod'] = g2_le.transform(transaction_history_data['g2_cod'].values)
transaction_history_data = transaction_history_data[['id', 'sz_id', 'cat1', 'g2_cod', 'gender', 'age', 'age_range', 'rmb_amt','prt_dt']]
## 训练集用户属性 信息
data = pd.merge(data, cuts_inf[['id', 'gender', 'age', 'age_range']], on=['id'], how='left')
## 训练集用户记录里最多的 sz_id g2_cod
temp = transaction_history_data.groupby(['id', 'sz_id'], as_index=False)['prt_dt'].count()\
.sort_values(['id', 'prt_dt'], ascending=[True, False]).groupby('id').apply(lambda x: x['sz_id'].values[0])\
.reset_index().rename(columns={0:'sz_id'})
data = pd.merge(data, temp, on=['id'], how='left')
data['sz_id'] = data['sz_id'].astype('category').cat.codes
temp = transaction_history_data.groupby(['id', 'g2_cod'], as_index=False)['prt_dt'].count()\
.sort_values(['id', 'prt_dt'], ascending=[True, False]).groupby('id').apply(lambda x: x['g2_cod'].values[0])\
.reset_index().rename(columns={0:'g2_cod'})
data = pd.merge(data, temp, on=['id'], how='left')
data['g2_cod'] = data['g2_cod'].astype('category').cat.codes
### 用户交易条目数和交易天数 平均每天交易数
temp = transaction_history_data.groupby('id', as_index=False)['prt_dt'].agg({'user_trans_count':'count'})
data = pd.merge(data, temp, on=['id'], how='left')
temp = transaction_history_data.groupby('id', as_index=False)['prt_dt'].agg({'user_trans_day_count':'nunique'})
data = pd.merge(data, temp, on=['id'], how='left')
data['user_trans_day_mean'] = data['user_trans_count']/data['user_trans_day_count']
## 用户 总交易额 收入 支出 条目、天平均
temp = transaction_history_data[transaction_history_data['rmb_amt']>=0].groupby('id', as_index=False)['rmb_amt'].agg({'user_sr_sum':'sum'})
data = pd.merge(data, temp, on=['id'], how='left')
temp = transaction_history_data[transaction_history_data['rmb_amt']<0].groupby('id', as_index=False)['rmb_amt'].agg({'user_zc_sum':'sum'})
data = pd.merge(data, temp, on=['id'], how='left')
data['user_sr_+_zc'] = data['user_sr_sum'] + data['user_zc_sum']
data['user_sr_-_zc'] = data['user_sr_sum'] - data['user_zc_sum']
for i in ['user_sr_sum', 'user_zc_sum', 'user_sr_+_zc', 'user_sr_-_zc']:
col = i + '/trans'
data[col] = data[i]/data['user_trans_count']
col = i + '/days'
data[col] = data[i]/data['user_trans_day_count']
## 用户 总交易额 收入 支出 均值,方差 统计值
temp = transaction_history_data.groupby('id', as_index=False)['rmb_amt']\
.agg({'user_rmb_mean':'mean', 'user_rmb_std':'std'})
data = pd.merge(data, temp, on=['id'], how='left')
temp = transaction_history_data[transaction_history_data['rmb_amt']>=0].groupby('id', as_index=False)['rmb_amt']\
.agg({'user_sr_mean':'mean', 'user_sr_std':'std'})
data = pd.merge(data, temp, on=['id'], how='left')
temp = transaction_history_data[transaction_history_data['rmb_amt']<0].groupby('id', as_index=False)['rmb_amt']\
.agg({'user_zc_mean':'mean', 'user_zc_std':'std'})
data = pd.merge(data, temp, on=['id'], how='left')
## 用户 sz三种不同类型计数占比
temp = transaction_history_data.groupby(['id', 'cat1'])['prt_dt'].count().unstack().reset_index()\
.rename(columns={0:'user_cat1_0_count', 1:'user_cat1_1_count', 2:'user_cat1_2_count'})
data = pd.merge(data, temp, on=['id'], how='left')
for i in ['user_cat1_0_count', 'user_cat1_1_count', 'user_cat1_2_count']:
col = i.replace('count', 'ratio')
data[col] = data[i]/data['user_trans_count']
## 用户 交易的第一天和最后一天
temp = transaction_history_data.groupby('id', as_index=False)['prt_dt'].agg({'user_first_day':'min', 'user_last_day':'max'})
data = pd.merge(data, temp, on=['id'], how='left')
data['user_first_day'] = data['user_first_day'].astype('category').cat.codes
data['user_last_day'] = data['user_last_day'].astype('category').cat.codes
## 用户 交易记录 sz_id 占比
temp = transaction_history_data.groupby(['id', 'sz_id'], as_index=False)['prt_dt'].count()
temp = pd.merge(temp, transaction_history_data[['id', 'prt_dt']].groupby('id', as_index=False)['prt_dt'].agg({'sz_id_ratio': 'count'}),\
on=['id'], how='left')
temp['sz_id_ratio'] = temp['prt_dt']/temp['sz_id_ratio']
temp = pd.pivot_table(temp[['id', 'sz_id', 'sz_id_ratio']], index=['id', 'sz_id']).unstack().reset_index().fillna(0)
data = pd.merge(data, temp, on=['id'], how='left')
## 用户 交易记录 g2_cod 占比
temp = transaction_history_data.groupby(['id', 'g2_cod'], as_index=False)['prt_dt'].count()
temp = pd.merge(temp, transaction_history_data[['id', 'prt_dt']].groupby('id', as_index=False)['prt_dt'].agg({'g2_cod_ratio': 'count'}),\
on=['id'], how='left')
temp['g2_cod_ratio'] = temp['prt_dt']/temp['g2_cod_ratio']
temp = pd.pivot_table(temp[['id', 'g2_cod', 'g2_cod_ratio']], index=['id', 'g2_cod']).unstack().reset_index().fillna(0)
data = pd.merge(data, temp, on=['id'], how='left')
## 用户余额
if data_name == 'train':
data = pd.merge(data, cuts_inf[['id', 'aum227']], on=['id'], how='left').rename(columns={'aum227':'aum_last'})
else:
data = pd.merge(data, cuts_inf[['id', 'aum306']], on=['id'], how='left').rename(columns={'aum306':'aum_last'})
## 用户 交易记录 sz_id 金额求和
temp = transaction_history_data.groupby(['id', 'sz_id'], as_index=False)['rmb_amt'].agg({'sz_id_amt':'sum'})
temp = pd.pivot_table(temp[['id', 'sz_id', 'sz_id_amt']], index=['id', 'sz_id']).unstack().reset_index().fillna(0)
data = pd.merge(data, temp, on=['id'], how='left')
## 用户 交易记录 g2_cod 金额求和
temp = transaction_history_data.groupby(['id', 'g2_cod'], as_index=False)['rmb_amt'].agg({'g2_cod_amt':'sum'})
temp = pd.pivot_table(temp[['id', 'g2_cod', 'g2_cod_amt']], index=['id', 'g2_cod']).unstack().reset_index().fillna(0)
data = pd.merge(data, temp, on=['id'], how='left')
return data
## 1-1 ~ 2-27 训练集提取特征 1-1 ~ 3-6 测试集提取特征
train = get_feature('2019-02-27', 'train')
test = get_feature('2019-03-06', 'test')
## 处理列名格式
rename_col = []
for i in train.columns:
if isinstance(i, tuple):
rename_col.append(i[0]+'_'+str(i[1]))
else:
rename_col.append(i)
train.columns = rename_col
rename_col = []
for i in test.columns:
if isinstance(i, tuple):
rename_col.append(i[0]+'_'+str(i[1]))
else:
rename_col.append(i)
test.columns = rename_col
y = train['click_w228'].values
## 模型用到的210个特征
## 具体筛选方式是先跑一折xgb模型,保留特征重要度大于10的210个特征,后期固定下来所以略去具体的训练步骤
col_lst = [ i for i in train.columns if i in [
'aum_last', 'age', 'user_cat1_1_ratio', 'user_trans_day_mean','sz_id_ratio_28', 'sz_id_amt_31', 'user_cat1_0_ratio',
'user_sr_std', 'user_cat1_2_ratio', 'user_zc_std', 'sz_id_amt_53','user_sr_+_zc', 'user_cat1_2_count', 'user_sr_+_zc/trans',
'user_first_day', 'g2_cod_amt_221', 'user_cat1_1_count', 'sz_id_ratio_31', 'sz_id_ratio_53', 'user_sr_+_zc/days',
'sz_id_ratio_15', 'user_sr_mean', 'user_cat1_0_count','g2_cod_ratio_239', 'user_last_day', 'sz_id_amt_28',
'g2_cod_ratio_221', 'sz_id_ratio_32', 'g2_cod_ratio_223','g2_cod_ratio_203', 'sz_id_ratio_39', 'sz_id_amt_15',
'sz_id_ratio_42', 'sz_id_ratio_52', 'g2_cod_amt_265','user_zc_sum', 'user_rmb_mean', 'sz_id_amt_52', 'sz_id_amt_54',
'sz_id_ratio_40', 'g2_cod_amt_223', 'g2_cod_ratio_201','user_sr_sum', 'user_rmb_std', 'sz_id_ratio_54', 'g2_cod_amt_201',
'g2_cod_amt_243', 'g2_cod_ratio_243', 'sz_id_amt_32','g2_cod_amt_203', 'sz_id_ratio_45', 'sz_id_ratio_1',
'user_trans_count', 'sz_id_amt_10', 'g2_cod_ratio_158','user_trans_day_count', 'sz_id_amt_42', 'sz_id_ratio_30',
'g2_cod_ratio_117', 'sz_id_ratio_27', 'g2_cod_amt_306','g2_cod_ratio_265', 'user_sr_sum/days', 'sz_id_amt_45',
'user_zc_sum/days', 'user_sr_-_zc/days', 'user_sr_sum/trans','sz_id_amt_40', 'user_zc_mean', 'sz_id_amt_33', 'sz_id_ratio_7',
'sz_id_ratio_33', 'sz_id_amt_39', 'sz_id_ratio_16', 'g2_cod_ratio_304', 'sz_id_ratio_2', 'g2_cod_ratio_306',
'g2_cod_ratio_266', 'user_sr_-_zc', 'g2_cod_ratio_300','g2_cod_ratio_303', 'sz_id_ratio_3', 'user_zc_sum/trans',
'sz_id_amt_27', 'g2_cod_amt_253', 'g2_cod_amt_304','g2_cod_amt_117', 'sz_id_ratio_10', 'g2_cod_amt_300', 'gender',
'g2_cod_ratio_119', 'g2_cod_amt_303', 'g2_cod_amt_112','sz_id_ratio_19', 'g2_cod_ratio_278', 'g2_cod_ratio_253',
'user_sr_-_zc/trans', 'sz_id', 'g2_cod_ratio_345', 'g2_cod','g2_cod_ratio_129', 'sz_id_amt_7', 'sz_id_amt_24', 'sz_id_amt_30',
'g2_cod_ratio_222', 'sz_id_amt_1', 'g2_cod_amt_340','g2_cod_ratio_31', 'sz_id_amt_19', 'sz_id_amt_3', 'sz_id_amt_41',
'sz_id_amt_16', 'g2_cod_ratio_340', 'sz_id_ratio_29','g2_cod_ratio_185', 'sz_id_amt_46', 'g2_cod_amt_31',
'g2_cod_amt_158', 'sz_id_amt_11', 'g2_cod_ratio_112','g2_cod_ratio_121', 'sz_id_amt_2', 'sz_id_ratio_41',
'sz_id_ratio_24', 'sz_id_ratio_11', 'g2_cod_amt_346','sz_id_ratio_6', 'sz_id_ratio_46', 'g2_cod_amt_278',
'g2_cod_amt_119', 'g2_cod_amt_345', 'g2_cod_amt_239','sz_id_amt_29', 'g2_cod_ratio_346', 'g2_cod_amt_121',
'g2_cod_amt_157', 'sz_id_amt_37', 'sz_id_ratio_34','g2_cod_ratio_34', 'sz_id_amt_0', 'sz_id_ratio_26',
'g2_cod_amt_222', 'g2_cod_amt_185', 'sz_id_ratio_17','g2_cod_amt_34', 'g2_cod_ratio_314', 'sz_id_amt_6',
'g2_cod_ratio_187', 'sz_id_amt_12', 'sz_id_ratio_12','g2_cod_amt_268', 'g2_cod_amt_129', 'sz_id_ratio_36',
'sz_id_amt_17', 'sz_id_ratio_37', 'g2_cod_ratio_268', 'age_range','g2_cod_ratio_283', 'g2_cod_amt_41', 'g2_cod_amt_269',
'sz_id_ratio_23', 'sz_id_ratio_4', 'g2_cod_amt_187','g2_cod_ratio_262', 'g2_cod_ratio_293', 'g2_cod_ratio_128',
'sz_id_ratio_0', 'g2_cod_ratio_148', 'g2_cod_amt_283','sz_id_amt_55', 'g2_cod_ratio_130', 'sz_id_amt_49',
'g2_cod_amt_120', 'g2_cod_amt_293', 'g2_cod_amt_266', 'g2_cod_ratio_120', 'g2_cod_ratio_267', 'g2_cod_ratio_172',
'g2_cod_amt_314', 'g2_cod_ratio_263', 'sz_id_amt_34','sz_id_amt_26', 'g2_cod_amt_267', 'g2_cod_ratio_174',
'g2_cod_ratio_269', 'g2_cod_amt_134', 'sz_id_amt_4','sz_id_amt_36', 'sz_id_ratio_44', 'g2_cod_ratio_157',
'g2_cod_amt_174', 'sz_id_ratio_25', 'sz_id_amt_25', 'sz_id_amt_8','sz_id_amt_9', 'g2_cod_ratio_292', 'g2_cod_ratio_349',
'g2_cod_amt_263', 'g2_cod_amt_130', 'sz_id_amt_22','sz_id_ratio_9', 'g2_cod_amt_206', 'sz_id_ratio_22',
'g2_cod_ratio_350', 'sz_id_ratio_51', 'sz_id_amt_51','g2_cod_ratio_41', 'sz_id_ratio_47', 'sz_id_ratio_5',
'g2_cod_amt_172']]
## 模型训练部分,分层抽样,10折cv只跑一折即可
skf = StratifiedKFold(n_splits=10, random_state=42, shuffle=True)
auc_list = []
sub_list = []
for k, (train_idx, test_idx) in enumerate(skf.split(y, y)):
if k in [9]:
print(k+1)
X_train, X_test, y_train, y_test = \
train[col_lst].iloc[train_idx], train[col_lst].iloc[test_idx], y[train_idx], y[test_idx]
xgb_train = xgb.DMatrix(X_train, label=y_train)
xgb_val = xgb.DMatrix(X_test, label=y_test)
params = {
'booster': 'gbtree',
'objective': 'binary:logistic',
'eval_metric': 'auc',
'gamma': 0.1,
'min_child_weight': 1.1,
'learning_rate' : 0.01,
'max_depth': 5,
'subsample': 0.8,
'colsample_bytree': 0.8,
'colsample_bylevel': 0.8,
'lambda': 10,
'verbose_eval': 1,
'nthread': 6,
'silent': 1,
}
evallist = [(xgb_train, 'train'), (xgb_val, 'eval')]
gbm = xgb.train(params, xgb_train, 3000, evallist, early_stopping_rounds=60, verbose_eval=50)
auc_list.append(gbm.best_score)
sub_list.append(gbm.predict(xgb.DMatrix(test[col_lst]), ntree_limit=gbm.best_ntree_limit))
test['score'] = sub_list[0]
test[['id', 'score']].to_csv('ques2_210fea_cv1.csv', index=None)















 301
301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









