






1.1 环境准备
1.系统环境为Windows10。
2.需提前安装Java 8和Scala2.12。
3.集成开发环境(IDE)使用IntelliJ IDEA,具体的安装流程参见IntelliJ官网。
4.安装IntelliJIDEA之后,还需要安装一些插件—Maven、Scala。Maven用来管理项目依赖;
1.2 创建项目
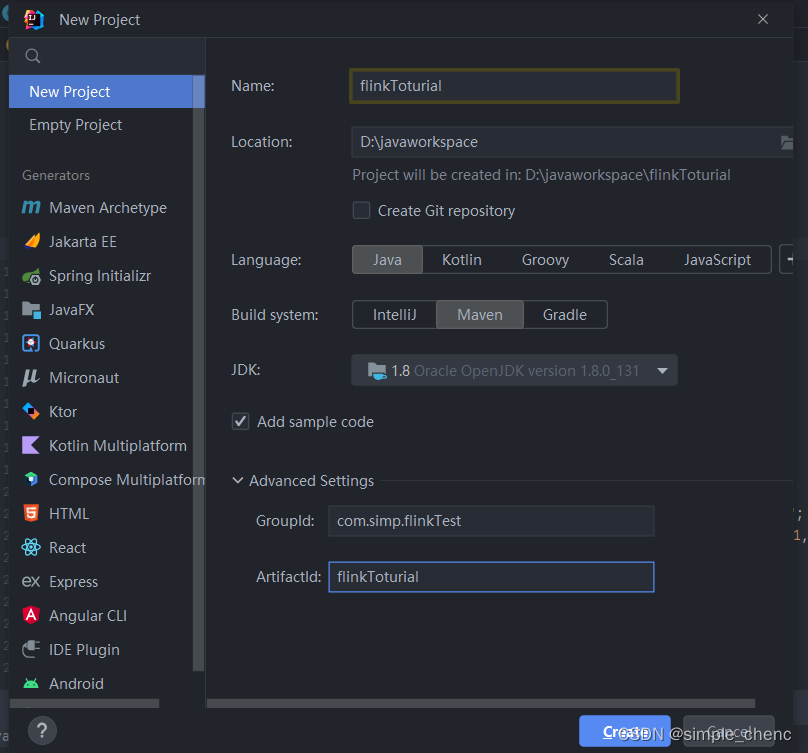
1. 创建工程(1)打开IntelliJIDEA,file->New->Project 创建一个Maven工程,如图2-1所示。
idea版本不同界面会有些许差异
2. 添加项目依赖在项目的pom文件中,增加<properties>标签设置属性,然后增加<denpendencies>标签引入需要的依赖。我们需要添加的依赖最重要的就是Flink的相关组件,包括flink-scala、flink-streaming-scala,以及flink-clients。
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.13.0</flink.version>
<target.java.version>1.8</target.java.version>
<scala.binary.version>2.12</scala.binary.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
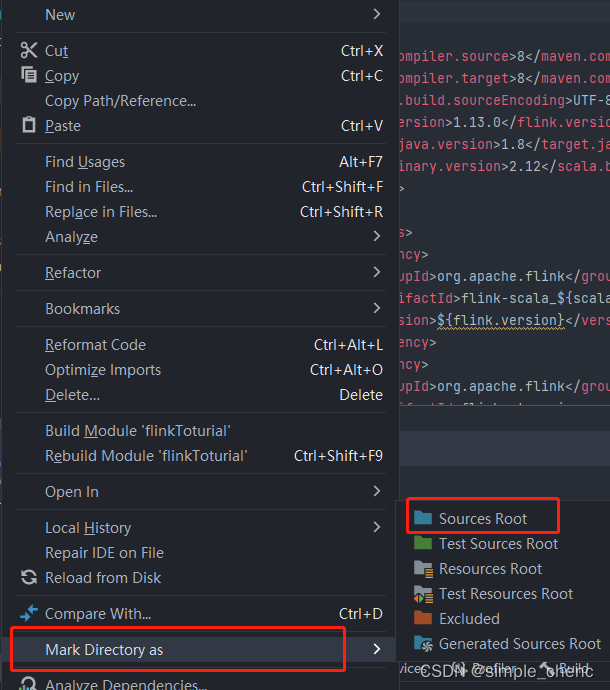
</dependencies>3 编写代码搭好项目框架,接下来就是我们的核心工作——往里面填充代码。我们会用一个最简单的示例来说明Flink代码怎样编写:统计一段文字中,每个单词出现的频次。我们首先在src/main路径下新建一个源码目录scala,本书源码将位于src/main/scala目录下。在这个目录下新建一个包,命名为com.atguigu.chapter02,在这个包下我们将编写Flink入门的WordCount程序。
这里要将scala目录设置为根目录
3.1 批处理
对于批处理而言,输入的应该是收集好的数据集。这里我们可以将要统计的文字,写入一个文本文档,然后读取这个文件处理数据就可以了。
(1)在工程根目录下新建一个input文件夹,并在下面创建文本文件words.txt
(2)在words.txt中输入一些文字,
例如:
hello world
hello flink
hello java
hello scala(3)在com.atguigu.chapter02包下新建Scala的单例对象(object)BatchWordCount,在静态main方法中编写测试代码。我们进行单词频次统计的基本思路是:先逐行读入文件数据,然后将每一行文字拆分成单词;接着按照单词分组,统计每组数据的个数,就是对应单词的频次。具体
代码实现如下:
import org.apache.flink.api.scala._
object Test01 {
def main(args: Array[String]): Unit = {
// 创建执行环境配置并行度
val environment: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
// 读取文本文件
val words: DataSet[String] = environment.readTextFile("input/word.txt")
// 对数据进行格式转换
val wordTuple: DataSet[(String, Int)] = words.flatMap(_.split(" ")).map(word => (word, 1))
// 对数据进行分组聚合
val value: AggregateDataSet[(String, Int)] = wordTuple.groupBy(0).sum(1)
value.print()
}
}输出结果:
(java,1)
(flink,1)
(world,1)
(scala,1)
(hello,4)
可以看到,我们将文档中的所有单词的频次,全部统计出来,以二元组的形式在控制台打印输出了。
需要注意的是,这种代码的实现方式,是基于DataSet API的,也就是我们对数据的处理转换,是看作数据集来进行操作的。事实上Flink本身是流批统一的处理架构,批量的数据集本质上也是流,没有必要用两套不同的API来实现。所以从Flink 1.12开始,官方推荐的做法是直接使用DataStream API,在提交任务时通过将执行模式设为BATCH来进行批处理:
$ bin/flink run -Dexecution.runtime-mode=BATCH BatchWordCount.jar
这样,DataSet API就已经处于“软弃用”(soft deprecated)的状态,在实际应用中我们只要维护一套DataStream API就可以了。这里只是为了方便大家理解,我们依然用DataSet API做了批处理的实现。
3.2 流处理
对于Flink而言,流才是整个处理逻辑的底层核心,所以流批统一之后的DataStream API更加强大,可以直接处理批处理和流处理的所有场景。
1. 读取文件
具体实现代码如下:
import org.apache.flink.streaming.api.scala._
object StreamWordCount {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val lineData: DataStream[String] = env.readTextFile("input/word.txt")
//val lineData: DataStream[String] = env.socketTextStream("localhost", 9999)
val oneWord: DataStream[(String, Int)] = lineData.flatMap(_.split(" ")).map(word => (word, 1))
val data: DataStream[(String, Int)] = oneWord.keyBy(_._1).sum(1)
data.print()
env.execute()
}
}输出结果如下:
1> (scala,1)
10> (flink,1)
4> (hello,1)
2> (java,1)
7> (world,1)
4> (hello,2)
4> (hello,3)
4> (hello,4)这与批处理的结果是完全不同的。批处理针对每个单词,只会输出一个最终的统计个数;而在流处理的打印结果中,“hello”这个单词每出现一次,都会有一个频次统计数据输出。这就是流处理的特点,数据逐个处理,每来一条数据就会处理输出一次。我们通过打印结果,可以清晰地看到单词“hello”数量增长的过程。
以上就是flink的快速上手案例,分别介绍了批处理过程和流处理过程,欢迎留言讨论
走过路过,点个赞。。。















 613
613











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









