







第一次参加,还在更大佬们学习,写点笔记自己看。(排名182,0.11341)
开始把。。。。
#i导入需要用的库
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from scipy.stats import norm,skew
from sklearn.preprocessing import StandardScaler
from scipy import stats
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline#d导入训练和测试集数据
train_data = pd.read_csv("./data/train.csv")
test_data = pd.read_csv("./data/test.csv")#观察热力矩阵数据要用到的保存值
train_data_colimns = train_data
test_data_colimns = test_data
train_data.head(5)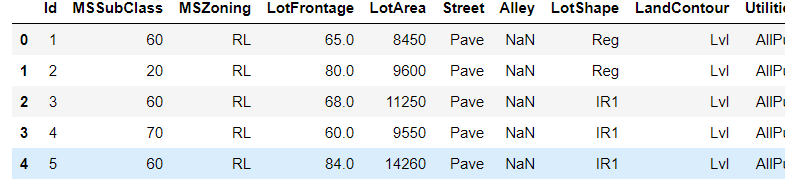
查看数据的维度信息
train_data.shape
![]()
#获取目标数据的decribe
train_data['SalePrice'].describe()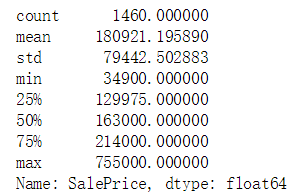
#绘制价格的分布图像
sns.distplot(train_data['SalePrice'])
#根据上图,可以得出住房价格主要集中在(10万,30)万间,这部分比例最大
#输出价格的偏态和峰态
print("Skewness: %f" % train_data['SalePrice'].skew())
print("Kurtosis: %f" % train_data['SalePrice'].kurt())偏态:,不为0,说明该分布不是对称分布的。且大于1,偏态数值为1.883,属于高度偏态分布
峰态,峰态数数值为6.536,大于3,属于尖峰分布,说明数据很集中
绘制住房价格主要影响因素的散点图。这么房子最主要的影响因素是住房的面积,
所以,我们来输出显示一下价格在面积影响下的散点分布图像
var = "GrLivArea"#住房的面积
data = pd.concat([train_data['SalePrice'],train_data[var]],axis = 1)#对价格和面积两列进行合并,按列
data.plot.scatter(x = var,y = 'SalePrice',ylim=(0,900000))#对数值进行绘制,y的范围在0到90000

#观察图像,发现两个离群点,即异常值,面积非常大,但价格非常低。
#有可能是农业用地,但这对我们主要考虑的是住房额价格。需要排除这两个有很大影响的要素
#删除
train_data = train_data.drop(train_data[(train_data['GrLivArea']>4000) & (train_data['SalePrice']<300000)].index)
#显示查看
var = "GrLivArea"
data = pd.concat([train_data['SalePrice'],train_data[var]],axis = 1)
data.plot.scatter(x = var,y = 'SalePrice',ylim=(0,900000))

#判断是不是,一个ID对应一个值
print(len(np.unique(train_data['Id'])) == len(train_data))
len(np.unique(test_data['Id'])) == len(test_data)
#这里训练集数据比测试集数据少一行销售价格。这是我们在结果上需要我们去预测的
print(len(train_data))
print(len(test_data))
print("Train set size:", train_data.shape)
print("Test set size:", test_data.shape)#删除他们的ID标签,我们后面再给他们补上。我们在删除时只对列进行操作,保证了数据行ID行数据不会被我们误删除
sava_test_ID = test_data["Id"]
train_data = train_data.drop(['Id'], axis=1)
test_data = test_data.drop(['Id'], axis=1)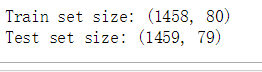
#观察价格数据的形状,层现左偏,所以需要对数据进行对数的转换,使数据更具趋向正态分布
#绘制转换后的直方图和正太概率图
sns.distplot(train_data['SalePrice'] , fit=norm);
fig = plt.figure()
res = stats.probplot(train_data['SalePrice'], plot=plt)
#绘制经过log转换后的直方图和正太概率图,
sns.distplot(np.log(train_data['SalePrice'] +1), fit=norm);
fig = plt.figure()
res = stats.probplot(np.log(train_data['SalePrice'] +1), plot=plt)
#.reset_index 重新设置所有,给就序列SaLePrice添加索引
y = train_data.SalePrice.reset_index(drop=True)
#我们先吧销售价格删除,使得测试和训练数据保持一致。删除前的数据以及保存在y里面
train_features = train_data.drop(['SalePrice'], axis=1)
test_features = test_data#查看数据维度是否正确
print(train_features.shape)
print(test_features.shape)
#这里我们把测试集数据和训练集数据组合保存为数据的特征。
#因为列数据相同,这里数据会吧测试数据接到训练数据的下面
#同时,为新序列重新设置索引
features = pd.concat([train_features, test_features]).reset_index(drop=True)
features.shape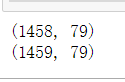
![]()
#处理缺失值数据,对数据进行分析,对相关数据进行比较。
#考虑缺失数据是删除还是填充其他值,一般情况下,数值型数据一般填补中位数,类别型数据填补众数
#将训练集和测试集联合,机械能特征处理
#我们来查看一下数据的的缺失值,和数据的类型
#对每一列的缺失值进行计数,features其实是所有行,里面有个循环选取的过程。
#返回的nulls类型是一个列表,里面记录数据列缺失值的信息
nulls = np.sum(features.isnull())
nullcols = nulls.loc[(nulls != 0)]
dtypes = features.dtypes#记录每一列数据的数据类型
dtypes2 = dtypes.loc[(nulls != 0)]#数据列中存在缺失值的数据
info = pd.concat([nullcols, dtypes2], axis=1).sort_values(by=0,ascending=False)
print(info)
print("There are", len(nullcols), "columns with missing values")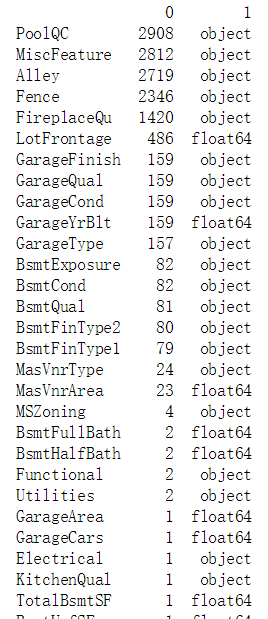
#我们吧房子里面相关类型的数据进行缺失值的填充。
#我们先来看一下相关房子描述的列数:Functional,Electrical,KitchenQual,Exterior1st,Exterior2nd,SaleType
#由于是类别型数据,这里我们填补众数
features['Functional'] = features['Functional'].fillna(features['Functional'].mode()[0])
features['Electrical'] = features['Electrical'].fillna(features['Electrical'].mode()[0])
features['KitchenQual'] = features['KitchenQual'].fillna(features['KitchenQual'].mode()[0])
features['Exterior1st'] = features['Exterior1st'].fillna(features['Exterior1st'].mode()[0])
features['Exterior2nd'] = features['Exterior2nd'].fillna(features['Exterior2nd'].mode()[0])
features['SaleType'] = features['SaleType'].fillna(features['SaleType'].mode()[0])
features['MiscFeature'] = features['MiscFeature'].fillna("None")
features['Alley'] = features['Alley'].fillna("None")
features['Fence'] = features['Fence'].fillna("None")
features['FireplaceQu'] = features['FireplaceQu'].fillna("None")
features['MasVnrType'] = features['MasVnrType'].fillna("None")
features['GarageQual'] = features['GarageQual'].fillna(features['GarageQual'].mode()[0])
features['GarageCond'] = features['GarageCond'].fillna(features['GarageCond'].mode()[0])
features['GarageFinish'] = features['GarageFinish'].fillna(features['GarageFinish'].mode()[0])
features['GarageType'] = features['GarageType'].fillna(features['GarageType'].mode()[0])
features['BsmtCond'] = features['BsmtCond'].fillna(features['BsmtCond'].mode()[0])
features['BsmtExposure'] = features['BsmtExposure'].fillna(features['BsmtExposure'].mode()[0])
features['BsmtQual'] = features['BsmtQual'].fillna(features['BsmtQual'].mode()[0])
features['BsmtFinType2'] = features['BsmtFinType2'].fillna(features['BsmtFinType2'].mode()[0])
features['BsmtFinType1'] = features['BsmtFinType1'].fillna(features['BsmtFinType1'].mode()[0])
features['PoolQC'] = features['PoolQC'].fillna(features['PoolQC'].mode()[0])
features['MSZoning'] = features['MSZoning'].fillna(features['MSZoning'].mode()[0])
features['Electrical'] = features['Electrical'].fillna(features['Electrical'].mode()[0])
features['Utilities'] = features['Utilities'].fillna(features['Utilities'].mode()[0])
features['BsmtFinSF2'] = features['BsmtFinSF2'].fillna(features['BsmtFinSF2'].median())
features['BsmtUnfSF'] = features['BsmtUnfSF'].fillna(features['BsmtUnfSF'].median())
features['BsmtFinSF1'] = features['BsmtFinSF1'].fillna(features['BsmtFinSF1'].median())
features['LotFrontage'] = features['LotFrontage'].fillna(features['LotFrontage'].median())
features['BsmtFullBath'] = features['BsmtFullBath'].fillna(features['BsmtFullBath'].median())
features['GarageYrBlt'] = features['GarageYrBlt'].fillna(features['GarageYrBlt'].median())
features['TotalBsmtSF'] = features['TotalBsmtSF'].fillna(features['TotalBsmtSF'].median())
features['GarageCars'] = features['GarageCars'].fillna(features['GarageCars'].median())
features[ 'GarageYrBlt'] = features['GarageYrBlt'].fillna(features['GarageYrBlt'].median())
features['BsmtHalfBath'] = features['BsmtHalfBath'].fillna(features['BsmtHalfBath'].median())
features['MasVnrArea'] = features['MasVnrArea'].fillna(features['MasVnrArea'].median())
features['GarageArea'] = features['GarageArea'].fillna(features['GarageArea'].median())
# 我们来看一下数据集的热力矩阵
corrmat = train_data_colimns.corr()
f, ax = plt.subplots(figsize=(12, 9))
sns.heatmap(corrmat, vmax=.7, square=True);
#该数据集收集年份在2010年之前,先来判断一下一些年份数据超过这个年份的行数据
def out_time_data(train):
list_data = ['YearBuilt','YearRemodAdd','GarageYrBlt']
for col in list_data:
print(col)
num = 0
for i in train[col]:
if i>2010:
print("列{}中出现错误,错误值为{}".format(col,i))
out_time_data(features)
features[features['GarageYrBlt'] == 2207]

#该数据收集时间为止时间为2010年,所以这部分数据有误,应为输入人员输出错误,理论值为2007
features.loc[2590, 'GarageYrBlt'] = 2007#查看当前数据的缺失值。查看缺失数据数据是否已经填补完成
total = features.isnull().sum().sort_values(ascending = False)
percent = (features.isnull().sum()/features.isnull().count()).sort_values(ascending = False)
missing_data = pd.concat([total,percent],axis = 1,keys = ['Total','Percent'])
missing_data.head(30)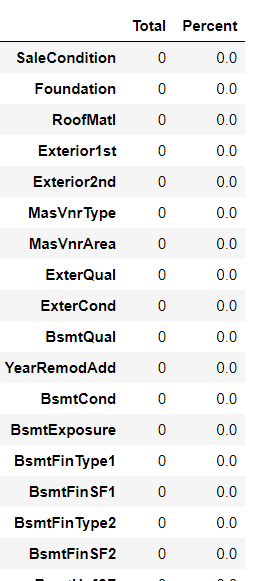
factors = ['MSSubClass']
#该列数据里面类型不一致,改变他
for i in factors:
features.update(features[i].astype('str'))
#定义一个函数,对数据的列进行测试,吧列数据中一些占比出现异常的选项
def count_data(train):
list_1=[]
list_2=[]
list_3=[]
dir = {}
for col in train.columns:#对每一列数据进行循环
# print(col)
dir = train[col].drop_duplicates()#单独列数据进行去重,大于10个的直接跳过
if dir.size>10:
pass
else:#对去重后数据进行保存,储存则数据在整一列数据中对数据进行匹配
# print(dir)
for i in dir:
# print(i)
num = 0
for j in train[col]:
if j == i:
num+=1
rate = num/len(train[col])#计算出现次数在总数中的占比
if(rate>0.97):#小于0.9则数据对整体数据有影响,大于0.9则数据有可能为无关数据
print("列{}的数据占比有异常,超过百分之97数据为重复,重复率为{}".format(col,rate))
print("列{},{} 出现的次数为{}".format(col,i,num))
list_1.append(col)
list_2.append(num)
list_3.append(rate)
# dir[col] = [num,rate]
dir = pd.DataFrame([list_1,list_2,list_3],index = ["列名","出现次数","比例"])
return dir.T
count_data(features)#最几列所占比数据太大,我们删除他们,减低数据维度
features = features.drop(['Utilities', 'Street'], axis=1)
#我们通过一些组合特征,来增加数据的显著性
features['Total_sqr_footage'] = (features['BsmtFinSF1'] + features['BsmtFinSF2'] +
features['1stFlrSF'] + features['2ndFlrSF'])
features['Total_Bathrooms'] = (features['FullBath'] + (0.5*features['HalfBath']) +
features['BsmtFullBath'] + (0.5*features['BsmtHalfBath']))
features['Total_porch_sf'] = (features['OpenPorchSF'] + features['3SsnPorch'] +
features['EnclosedPorch'] + features['ScreenPorch'] +
features['WoodDeckSF'])
#simplified features
features['haspool'] = features['PoolArea'].apply(lambda x: 1 if x > 0 else 0)
features['has2ndfloor'] = features['2ndFlrSF'].apply(lambda x: 1 if x > 0 else 0)
features['hasgarage'] = features['GarageArea'].apply(lambda x: 1 if x > 0 else 0)
features['hasbsmt'] = features['TotalBsmtSF'].apply(lambda x: 1 if x > 0 else 0)
features['hasfireplace'] = features['Fireplaces'].apply(lambda x: 1 if x > 0 else 0)# 对OverallCond做变换
features['OverallCond'] = features['OverallCond'].astype(str)
# 年与月份
features['YrSold'] = features['YrSold'].astype(str)
features['MoSold'] = features['MoSold'].astype(str)
from sklearn.preprocessing import LabelEncoder
cols = ( 'BsmtQual', 'BsmtCond', 'GarageQual', 'GarageCond',
'ExterQual', 'ExterCond','HeatingQC', 'KitchenQual', 'BsmtFinType1',
'BsmtFinType2', 'Functional', 'Fence', 'BsmtExposure', 'GarageFinish', 'LandSlope',
'LotShape', 'PavedDrive', 'CentralAir', 'MSSubClass', 'OverallCond',
'YrSold', 'MoSold')
# 使用LabelEncoder做变换
for c in cols:
lbl = LabelEncoder()
lbl.fit(list(features[c].values))
features[c] = lbl.transform(list(features[c].values))
print('features的数据维度: {}'.format(features.shape))
numeric_feats = features.dtypes[features.dtypes != "object"].index![]()
# 对所有数值型的特征都计算skew,计算一下偏度
from scipy.stats import boxcox_normmax
skewed_feats = features[numeric_feats].apply(lambda x: skew(x.dropna())).sort_values(ascending=False)
skewness = pd.DataFrame({'Skew' :skewed_feats})
skewness.head(10)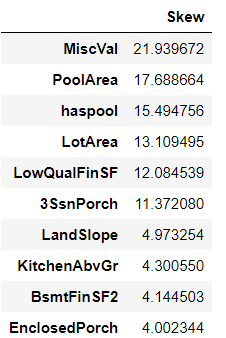
#计算偏度后,不符合正态分布的数据采用box-cox变换
from scipy.special import boxcox1p
skewed_features = skewness.index
lam = 0.2
for feat in skewed_features:
features[feat] = boxcox1p(features[feat], lam)#使类别数据向量化,并输出最后的维度
features = pd.get_dummies(features).reset_index(drop=True)
features.shape![]()
# 使用log1p函数完成log(1+x)变换
train_y = np.log1p(train_data["SalePrice"])
n_train = len(train_data)
train_x = features[:n_train]
test_x = features[n_train:]
test_x.shape[0] == test_data.shape[0]
print("train_x 的大小为",train_x.shape)
print("train_y 的大小为",train_y.shape)
from sklearn.preprocessing import RobustScaler,StandardScaler
from sklearn.linear_model import ElasticNet, Lasso, BayesianRidge, LassoLarsIC
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.kernel_ridge import KernelRidge
from sklearn.pipeline import make_pipeline
from sklearn.base import BaseEstimator, TransformerMixin, RegressorMixin, clone
from sklearn.model_selection import KFold, cross_val_score, train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.feature_selection import SelectFromModel,SelectKBest
import xgboost as xgb
import lightgbm as lgb
# 交叉验证函数
#Validation function
# 交叉验证函数
n_folds = 8
def rmsle_cv(model):
kf = KFold(n_folds, shuffle=True, random_state=42)#为了shuffle数据
rmse= np.sqrt(-cross_val_score(model, train_x_new,train_y.values, scoring="neg_mean_squared_error", cv = kf))
return(rmse)
#对数值型特征进行robust_scale
rb_scaler = RobustScaler()
train_x_rob= rb_scaler.fit_transform(train_x)
lasso = Lasso(alpha =0.0005, random_state=1)# 可在此步对模型进行参数设置,这里用默认值。
lasso.fit(train_x_rob, train_y) # 训练模型,传入X、y, 数据中不能包含miss_value
model = SelectFromModel(lasso,prefit=True)
train_x_new = model.transform(train_x)
test_x_new = model.transform(test_x)lasso = make_pipeline(RobustScaler(), Lasso(alpha =0.0005, random_state=1))
ENet = make_pipeline(RobustScaler(), ElasticNet(alpha=0.0005, l1_ratio=.9, random_state=3))
KRR = KernelRidge(alpha=0.6, kernel='polynomial', degree=2, coef0=2.5)
GBoost = GradientBoostingRegressor(n_estimators=3000, learning_rate=0.05,
max_depth=4, max_features='sqrt',
min_samples_leaf=15, min_samples_split=10,
loss='huber', random_state =5)
model_xgb = xgb.XGBRegressor(colsample_bytree=0.4603, gamma=0.0468,
learning_rate=0.05, max_depth=3,
min_child_weight=1.7817, n_estimators=2200,
reg_alpha=0.4640, reg_lambda=0.8571,
subsample=0.5213, silent=1,
random_state =7, nthread = -1)
model_lgb = lgb.LGBMRegressor(objective='regression',num_leaves=5,
learning_rate=0.05, n_estimators=720,
max_bin = 55, bagging_fraction = 0.8,
bagging_freq = 5, feature_fraction = 0.2319,
feature_fraction_seed=9, bagging_seed=9,
min_data_in_leaf =6, min_sum_hessian_in_leaf = 11)
score = rmsle_cv(lasso)
print("\nLasso 得分: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
score = rmsle_cv(ENet)
print("ElasticNet 得分: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
score = rmsle_cv(KRR)
print("Kernel Ridge 得分: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
score = rmsle_cv(GBoost)
print("Gradient Boosting 得分: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
score = rmsle_cv(model_xgb)
print("Xgboost 得分: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
score = rmsle_cv(model_lgb)
print("LGBM 得分: {:.4f} ({:.4f})\n" .format(score.mean(), score.std()))
#lasso,ENet,KRR,GBoost,model_xgb,model_lgb
class AveragingModels(BaseEstimator, RegressorMixin, TransformerMixin):
def __init__(self, models):
self.models = models
# 遍历所有模型,你和数据
def fit(self, X, y):
self.models_ = [clone(x) for x in self.models]
for model in self.models_:
model.fit(X, y)
return self
# 预估,并对预估结果值做average
def predict(self, X):
predictions = np.column_stack([
model.predict(X) for model in self.models_
])
return np.mean(predictions, axis=1)
averaged_models = AveragingModels(models = (ENet, GBoost, KRR, lasso))
#lasso,ENet,KRR,GBoost,model_xgb,model_lgb
score = rmsle_cv(averaged_models)
print(" 对基模型集成后的得分: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))![]()
class StackingAveragedModels(BaseEstimator, RegressorMixin, TransformerMixin):
def __init__(self, base_models, meta_model, n_folds=5):
self.base_models = base_models
self.meta_model = meta_model
self.n_folds = n_folds
# 遍历拟合原始模型
def fit(self, X, y):
self.base_models_ = [list() for x in self.base_models]
self.meta_model_ = clone(self.meta_model)
kfold = KFold(n_splits=self.n_folds, shuffle=True, random_state=156)
# 得到基模型,并用基模型对out_of_fold做预估,为学习stacking的第2层做数据准备
out_of_fold_predictions = np.zeros((X.shape[0], len(self.base_models)))
for i, model in enumerate(self.base_models):
for train_index, holdout_index in kfold.split(X, y):
instance = clone(model)
self.base_models_[i].append(instance)
instance.fit(X[train_index], y[train_index])
y_pred = instance.predict(X[holdout_index])
out_of_fold_predictions[holdout_index, i] = y_pred
# 学习stacking模型
self.meta_model_.fit(out_of_fold_predictions, y)
return self
# 做stacking预估
def predict(self, X):
meta_features = np.column_stack([
np.column_stack([model.predict(X) for model in base_models]).mean(axis=1)
for base_models in self.base_models_ ])
return self.meta_model_.predict(meta_features)stacked_averaged_models = StackingAveragedModels(base_models = (ENet,GBoost,KRR),meta_model = lasso)
score = rmsle_cv(stacked_averaged_models)
print("Stacking Averaged models score: {:.4f} ({:.4f})".format(score.mean(), score.std()))![]()
#定义评价函数
def rmsle(y, y_pred):
return np.sqrt(mean_squared_error(y, y_pred))
#下面模型融合中选择的模型和我的实验结果不符合
test_x = pd.DataFrame(test_x_new)
train_x = pd.DataFrame(train_x_new)#StackedRegressor:
stacked_averaged_models.fit(train_x.values, train_y.values)
stacked_train_pred = stacked_averaged_models.predict(train_x.values)
stacked_pred = np.expm1(stacked_averaged_models.predict(test_x.values))
print(rmsle(train_y.values, stacked_train_pred))
#XGBoost:
model_xgb.fit(train_x.values, train_y.values)
xgb_train_pred = model_xgb.predict(train_x.values)
xgb_pred = np.expm1(model_xgb.predict(test_x.values))
print(rmsle(train_y.values, xgb_train_pred))
#LightGBM:
model_lgb.fit(train_x.values, train_y.values)
lgb_train_pred = model_lgb.predict(train_x.values)
lgb_pred = np.expm1(model_lgb.predict(test_x.values))
print(rmsle(train_y.values, lgb_train_pred))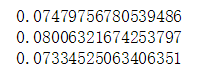
ensemble = stacked_pred*0.8 + xgb_pred*0.1 + lgb_pred*0.1sub = pd.DataFrame()
sub['Id'] = sava_test_ID
sub['SalePrice'] = ensemble
sub.to_csv('submissions_newes.csv',index=False)
















 913
913











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









