







1.获取输出目标数据的describe()。这包括数据的count,mean,std,min,median。然后获取输出数据的skew,kurt
2.绘制主要影响因素的图像,例如房子价格的主要影响因素是面积,即绘制面积与价格的图像。通过观察图像,查看异常值,并对异常值进行处理。一般异常值即为离群点数据

3.将训练集数据与测试集数据进行联合起来进行特征处理。
4.绘相关系数矩阵热图,分析各个特征的相关性,并对一下关联度比较高的数据进行选择性删除其中部分,只保留其中一份。关联程度比较高,说明这些数据之间存在较大的关联性,通过其中一个数据就可以表现着全部数据的特征。

5.查看缺失值,并对缺失数据进行排序。 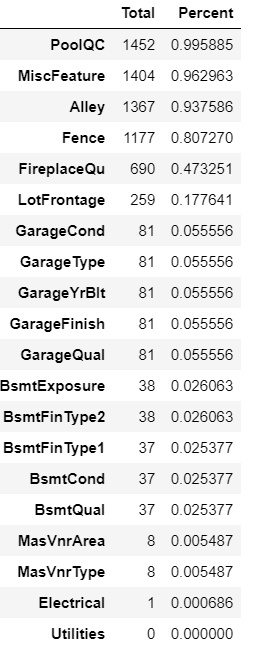
6.考虑缺失数据对总数据的影响,如缺失数据对总体数据来说是无关数据,则可以之间删除,如果是相关选项,则对相关数据进行填补。对数据值形数据来说,一般填补中位数,对类别形数据来说,一般填补众数。对缺失数据是否进行删除,根据具体情况而定,如果缺失数据只是少部分,可以考虑直接删除这部分数据。
7.转换一些具有明确特征的数值变量,并增加一些组合特征,通过原来的特征进行组合,构建和目标关系更大的特征。
8.LabeEncoder一些一些类型特征。from skearn.propocessing import LanbelEncoder。(第七和第八的有效组合可以使数据模型更加的健壮。)
9.对(偏度)倾斜特征,数据值型特征机械能Box-Cox变换,使数据型数据更趋向正态分布。数值特征计算偏度后,不符合正态分布的数据采用box-cox变换。对类别变量(虚拟分类)进行one-hot转换,pd.get_dummies()
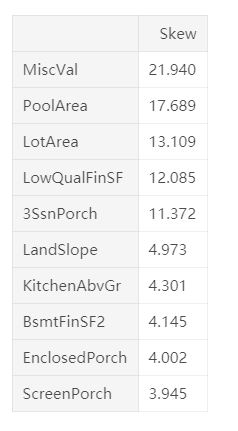
10.最后,计算训练集长度,对进行完特征工程之后的数据进行划分,train,text。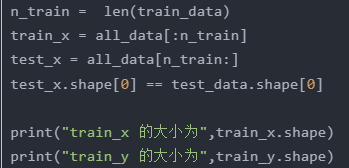















 9455
9455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









