








梯度消失直觉

当求
J
(
4
)
(
θ
)
J^{(4)}(\theta)
J(4)(θ)关于
h
(
1
)
h^{(1)}
h(1)的梯度时,使用链导法则,可得到图中的式子,若每一个乘数都很小,最终求得的梯度将会随着反向传播越远而变得越小。
具体的推导
首先
h
(
t
)
h^{(t)}
h(t)的计算公式如下
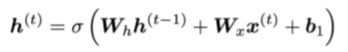
所以使用链式法则可以得到
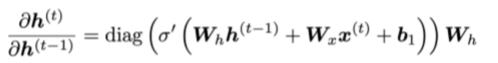
考虑时间步 t的loss
J
(
i
)
(
θ
)
J^{(i)}(\theta)
J(i)(θ)关于隐藏层输出
h
(
j
)
h^{(j)}
h(j)的梯度,j是i之前的某一时间步
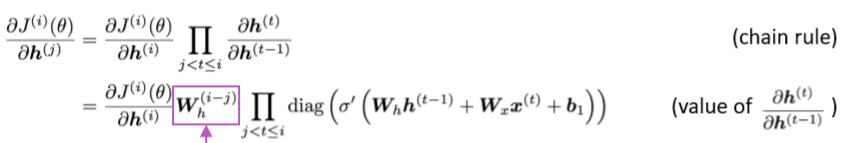
如果式中的
W
h
W_h
Wh很小,那么当i和j离得更远时,
W
h
(
i
−
j
)
W^{(i-j)}_h
Wh(i−j)就变小了
考虑矩阵L2范数
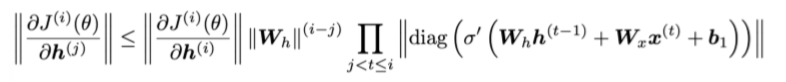
Pascanu等人指出,如果
W
h
W_h
Wh的最大特征值(largest eigenvalue)小于1,那么梯度
∣
∣
∂
J
(
i
)
(
]
t
h
e
t
a
)
∂
h
(
j
)
∣
∣
||\frac{\partial J^{(i)}(]theta)}{\partial h^{(j)}}||
∣∣∂h(j)∂J(i)(]theta)∣∣ 将指数收缩。
- 这里的界限是1,因为我们使用了sigmoid函数
当最大特征值大于1时,会导致梯度爆炸
Why is vanishing gradient a problem?

因为远处的梯度信号比近处的梯度信号小得多,所以将会丢失
因此,模型权重仅针对近期效应而非长期效进行更新。
另一个解释是:梯度可以看作是过去对未来影响的一种衡量
如果在更长的距离内(步骤t到步骤t+n),梯度变小,那么我们无法判断:
- 数据中的步骤t和t+n之间没有依赖关系
- 我们使用了错误的参数来捕获t和t+n之间的真正依赖关系
Effect of vanishing gradient on RNN-LM

为了学习这个例子,RNN-LM需要对第7时间步的"between"和最后的目标单词"ticket"之间的依赖关系进行建模
但如果梯度很小,模型就无法学习到这样的依赖关系,因此,在测试时,这个模型也就无法预测相似长距离的依赖。

Correct answer: The writer of the books is planning a sequel

由于梯度消失,RNN-LMs比句法近因更善于从顺序近因中学习,因此他们比我们认为的更经常地犯这种错误[Linzen et al 2016]
Why is exploding gradient a problem?
如果梯度太大,那么SGD每次更新都会太大
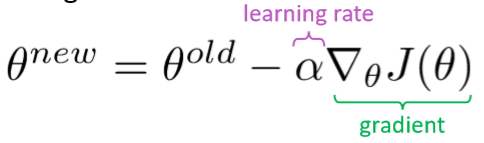
- 这可能会导致不好的结果:如果一步跨的太大,有可能会得到效果更差的参数,甚至最坏的情况下,有可能在网络中导致Inf或Nan(然后就必须从一个较早的checkpoint重启训练)
Gradient clipping: solution for exploding gradient
Gradient clipping:如果梯度的范数大于某个阈值,则在应用SGD更新之前将其缩小

作用可视化后如下图所示

- 这显示了一个简单RNN的损耗面(隐藏状态是标量而不是矢量)
- “悬崖”很危险,因为它有陡峭的梯度
- 在左边,由于梯度太大,梯度下降需要两个非常大的步,导致爬上悬崖然后向目标靠近(两个更新都不好)
- 在右边,渐变剪辑减少了这些步骤的大小,因此效果不太明显
How to fix vanishing gradient problem?
主要问题是RNN很难学会在多个时间段内保存信息。
在普通RNN中,隐藏层不断被重写
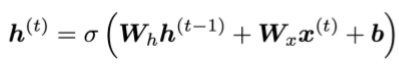
如果将记忆信息单独分出来会如何?
Long Short-Term Memory (LSTM)
- Hochreiter和Schmidhuber在1997年提出的一种RNN,用于解决消失梯度问题。
- 在时间步 t,有一个隐藏层状态
h
(
t
)
h^{(t)}
h(t)和一个记忆单元
c
(
t
)
c^{(t)}
c(t)
- 两者都是向量长度n
- 记忆单元存储了长期信息
- LSTM可以擦除、写入和读取记忆单元中的信息
- 记忆单元被擦除/写入/读取的选择由三个相应的门控制
- 门也是长度为n的向量
- 在每个时间步上,门的每个元素可以是打开(1)、关闭(0)或介于两者之间的某个位置。
- 门是动态的:它们的值是根据当前上下文计算的

可以将LSTM可视化成下图


How does LSTM solve vanishing gradients?
- LSTM体系结构使RNN更容易在多个时间步上保存信息
- e.g. 如果遗忘门设置为记住每个时间步上的所有内容,则单元格中的信息将无限期保留
- 相比之下,vanilla RNN很难学习在隐藏状态下保存信息的循环权重矩阵Wh
- LSTM不保证一定不会发生梯度消失/梯度爆炸,但确实为模型提供了一种学习长距离依赖的简单方法
LSTMs: real-world success
- 2013-2015年,LSTM开始取得最优成果
- 成功的任务包括:手写识别、语音识别、机器翻译、解析、图像字幕
- LSTM成为主导方法
- 现在(2019年),其他方法(如Transformers)在某些任务中变得更为主导。
- 例如在WMT(一个MT会议+竞争)
- 在WMT 2016中,总结报告包含44次“RNN”
- 在WMT 2018中,报告包含9次“RNN”和63次“Transformer”
GRU

一个LSTM的简化版:去掉了显式的记忆单元
LSTM vs GRU
- 研究人员提出了很多RNN的变体,但LSTM和GRU最常用
- 两者最大的区别是GRU计算更快,参数少
- 没有确凿的证据表明一方的表现总是比另一方好
- LSTM是一个很好的默认选择,尤其数据具有长期依赖或训练集很大时
- 经验法则:从LSTM开始,但是如果你想要更有效的方法,可以切换到GRU
Is vanishing/exploding gradient just a RNN problem?
-
不!这对所有的神经结构(包括前馈feed-forward和卷积结构convolutional)都是一个问题,特别是对深层结构。
- 由于链式法则/非线性函数的选择,梯度在反向传播时会变得非常小
- 因此较低层的学习非常缓慢(很难训练)
- 解决方案:许多新的深层前向/卷积架构增加了更多的直接连接(从而允许梯度流动)
例如:
- Residual connections aka “ResNet”
也被称为skip-connections
“Deep Residual Learning for Image Recognition”, He et al, 2015. https://arxiv.org/pdf/1512.03385.pdf
如图所示,有两条路径到达最后一个relu函数,将x与x经过两层变换之后的值相加。这使得深度神经网络更容易训练 - Dense connections aka “DenseNet”
”Densely Connected Convolutional Networks", Huang et al, 2017. https://arxiv.org/pdf/1608.06993.pdf
如图所示,将几层之间全部建立直接联结,形成dense connection。 - Highway connections aka “HighwayNet”
”Highway Networks", Srivastava et al, 2015. https://arxiv.org/pdf/1505.00387.pdf
参考博客介绍:https://blog.csdn.net/l494926429/article/details/51737883
与residual connections类似,但在HighwayNet中,数据是否经过变换传到下层由一个动态的门控制
由LSTM启发,同时也可应用到前馈/卷积网络中
-
结论:虽然消失/爆炸梯度是一个普遍的问题,但由于同一权重矩阵的重复乘法,rnn特别不稳定[Bengio et al, 1994]
Bidirectional RNNs

motivation:在单向的RNN中,每一个时间步只包含左边的信息,而对右边的信息一无所知,而在某些任务中,这直接会影响正确性。比如在上图的情感分类任务中,获得"terribly"的隐藏层表示时,只有左边的信息,其本身带有消极的意思,那么获得的隐藏层表示可能为最终结果贡献了消极的意思。但根据整个句子来看,明显此处是积极的含义。这就说明,获得一个词的表示时,右边的上下文信息也很重要。由此引出了双向RNN

双向RNN包括正向和反向,在时间步t的隐藏层状态将正向和反向获得的隐藏层状态拼接起来即可。此外,正向和反向的权重矩阵不同。

简化图示如下

注:
- 双向RNN只能在整个序列已知的情况下使用
- 比如语言建模就不能使用,因为在语言建模时,只有左边的上下文可以使用。
- 如果有完整的输入序列(例如,任何类型的编码),双向性是强大的(应该默认使用它)。
- 例如,BERT(来自Transformers的双向编码器表示)是一个强大的基于双向性的预训练上下文表示系统。
Multi-layer RNNs
- RNN已经在一维上“很深”(它们在许多时间步上展开)
- 我们还可以通过应用多个RNN使它们在另一个维度上“深入”——这是一个多层RNN。
- 这允许网络计算更复杂的表示
- 较低的rnn应该计算较低级别的特征,较高的rnn应该计算较高级别的特征。
- 多层RNN也称为堆叠RNN(stacked RNNs)

- 高性能RNN通常是多层的(但没有卷积或前馈网络那么深)
- 例如:在一篇2017年论文中,Brutz等人发现,对于神经机器翻译,2到4层对于编码器RNN是最好的,而4层对于解码器RNN来说是最好的。
- 但是,需要skip-connections/dense-connections来训练更深的RNN(例如8层)
- 基于Transformer的网络(如BERT)可多达24层
- Transformer中含有很多类似skipping的连接
总结

- 梯度消失/梯度爆炸会带来什么影响
- 梯度消失/梯度爆炸为什么会出现,存在于哪些网络结构中?
- 梯度消失/梯度爆炸如何解决
- LSTM和GRU对比
- 双向RNN和多层RNN















 459
459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









