







背景
当下 Doris 正处于快速迭代的阶段,稳定性不如 HDFS 等框架,直接应用在线上环境可能会有风险。而通过备份恢复的方案,整个恢复流程可能需要数小时,如果是对外的实时业务,这样的隐患对企业来说是比较大的。于是我们开始寻求一种比较稳妥的方案,一种显而易见的方式是双集群做高可用。
难点
目前常用的数据库普遍采用日志(比如 MySQL、HBase)、CCR 技术(比如 ES)实现主从集群的数据同步。然而,Doris 中并没有这种日志(2.0 之前),也不支持 CCR 技术。
社区提供的方案是将集群定期备份到远程存储中,出问题的时候再恢复。但这种方案需要的时间比较长,至少需要几个小时,这在我司的场景中是比较难接受的。
还有一个方案是写入的时候同时往两个集群写,但这会增加开发的工作,较难规范,不可控程度较高。
基于以上问题,提出一种 Doris 双集群的解决思路,基本可以实现对开发透明化、无感知。
具体实现
数据写入
目前我们 Doris 的数据写入主要有两种方式:一是通过 Flink Doris Connector 实时写入,二是通过 DataX 离线定期写入或初始化数据。
这两种方式都是通过连接器实现不同组件之间的数据交互,于是可以通过改造连接器实现同时将数据写到两个集群。
表格操作/DDL/DML
前面通过自定义连接器把两个集群的数据写入做到了无感知,这一块最好也能无感知,不然会有体验上的割裂。
由于 Doris 的 FE UI 界面是面向管理的,不适合作为日常的开发环境,最好能够在数据管理平台开发一个 Doris UI 页面,这个页面要有以下功能:
- 执行 DDL
- 判断是否 DDL,如果是,同时在两个集群执行
- 执行 DQL
- 只在主集群执行
- 权限控制
查询
使用负载均衡,平时主要查主集群,主集群挂了自动切换到从集群
Flink Doris Connector 的改造
下面主要说一说 Connector 的改造,个人感觉这是整个方案中比较难的点。
社区的 Connector 用法如下:
create table database.table_name
(
xxx int,
...
)with (
'connector' = 'doris',
'fenodes' = 'xxx:8030',
'table.identifier' = 'database.table',
'username' = 'user',
'password' = 'password'
);
因为我们要写到两个 Doris 集群,要能接收两个 FE 参数,具体思路如下:
create table database.table_name
(
xxx int,
...
)with (
'connector' = 'doris-dual-cluster',
'master.fenodes' = 'xxx:8030',
'slave.fenodes' = 'xxx:8030',
'table.identifier' = 'database.table',
'username' = 'user',
'password' = 'password'
);
如果只写了一个 fenodes,就只写一个集群,两个都指定,就写两个集群,简单明了。
下面是 Flink Connector 的架构,其中DynamicTableSourceFactory 和 DynamicTableSinkFactory 提供连接器特定的逻辑,将 CatalogTable 的元数据转换为 DynamicTableSource 和 DynamicTableSink 的实例。
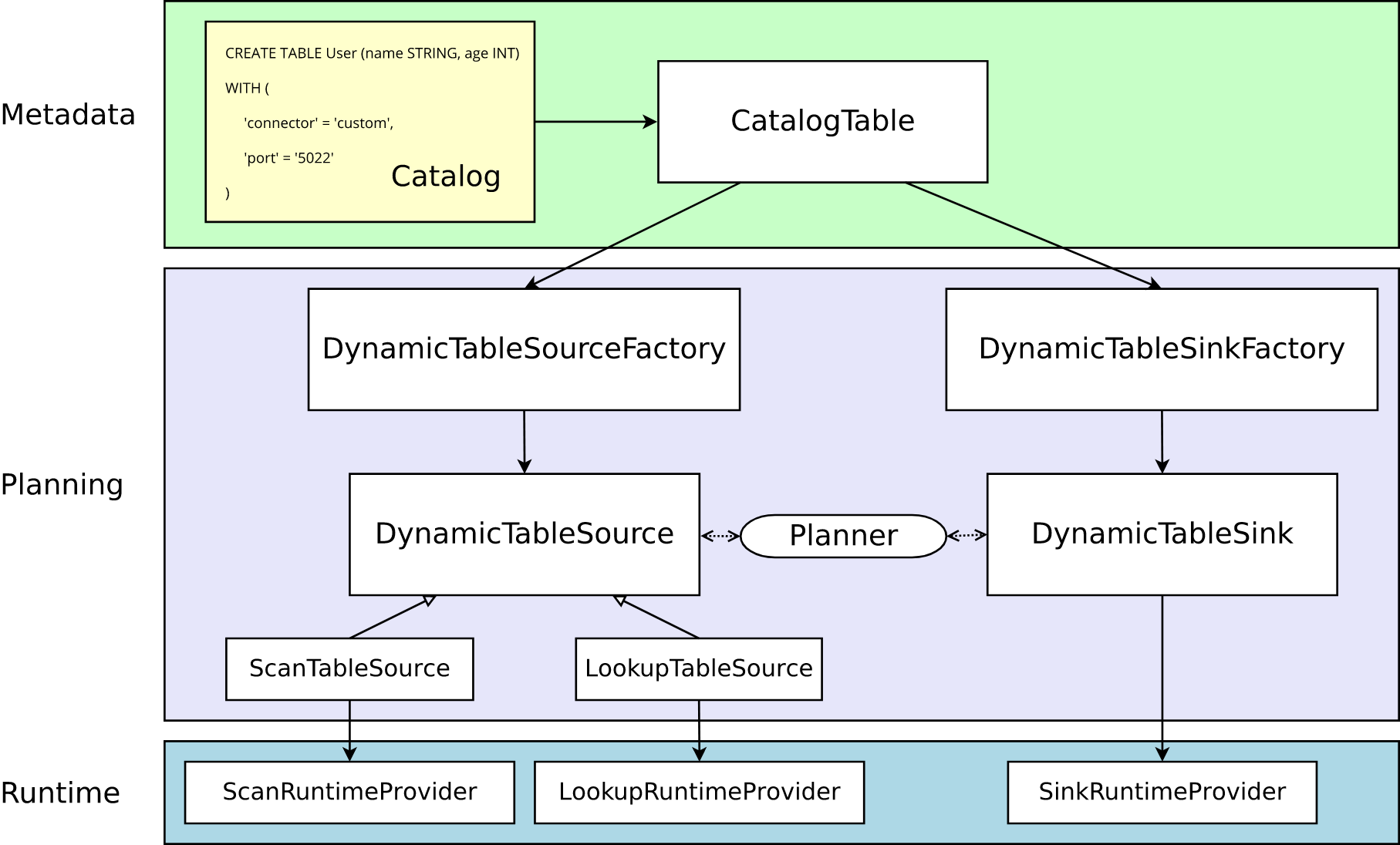
我需要的是写入两个集群,所以重点关注 DynamicTableSink,对应地在 Flink Doris Connector 中,是 DorisDynamicTableSink。它会构建 DorisDynamicOutputFormat 对象,DorisDynamicOutputFormat 中有个 flush 方法,会调用 DorisStreamLoad 类把数据真正写到 Doris 中,我的思路是在 DorisDynamicOutputFormat 中创建两个 DorisStreamLoad,一主一从,在 flush 方法中同时写到两个集群。
flush 的主要代码如下,因为考虑到要失败重试,而可能主集群一次就成功,从集群要重试好几次,所以写得可能有点冗杂:
public synchronized void flush() throws IOException {
......
boolean master = masterDorisStreamLoad == null;
boolean slave = slaveDorisStreamLoad == null;
for (int i = 0; i <= executionOptions.getMaxRetries(); i++) {
if (masterDorisStreamLoad != null && !master) {
try {
masterDorisStreamLoad.load("Master", result);
master = true;
} catch (StreamLoadException e) {
LOG.error("Master cluster sink error, retry times = {}", i, e);
if (i >= executionOptions.getMaxRetries()) {
throw new IOException(e);
}
try {
masterDorisStreamLoad.setHostPort(getBackend("master"));
LOG.warn("Streamload to master cluster error, switch be: {}", masterDorisStreamLoad.getLoadUrlStr(), e);
Thread.sleep(1000 * i);
} catch (InterruptedException ex) {
Thread.currentThread().interrupt();
throw new IOException("unable to flush to master cluster; interrupted while doing another attempt", e);
}
}
}
if (slaveDorisStreamLoad != null && !slave) {
try {
slaveDorisStreamLoad.load("Slave", result);
slave = true;
} catch (StreamLoadException e) {
LOG.error("Slave cluster sink error, retry times = {}", i, e);
if (i >= executionOptions.getMaxRetries()) {
throw new IOException(e);
}
try {
slaveDorisStreamLoad.setHostPort(getBackend("slave"));
LOG.warn("Streamload to slave cluster error, switch be: {}", slaveDorisStreamLoad.getLoadUrlStr(), e);
Thread.sleep(1000 * i);
} catch (InterruptedException ex) {
Thread.currentThread().interrupt();
throw new IOException("unable to flush to slave cluster; interrupted while doing another attempt", e);
}
}
}
if (master && slave) {
batch.clear();
break;
}
}
}
最后整个 Connector 改造完,执行的效果如下,每一次都会把一批数据写到两个集群。
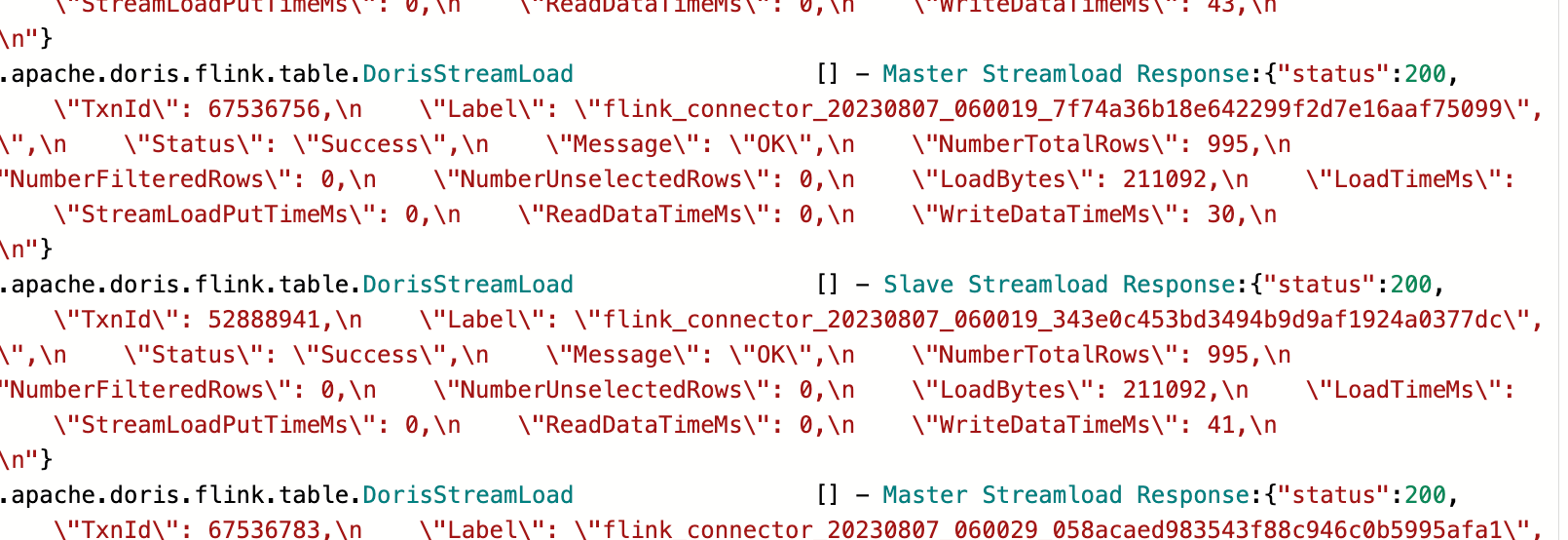
改造完的 Connector 也放在 GitHub 上,有需要的可以自取: https://github.com/LCehoennardo/flink-dual-doris-connector
总结
这样实现的好处是:一、对开发透明;二、简单易实现,从调研到构建整体思路,再到改造完 Flink Doris Connector,我大约花了一周左右的时间;三、即使集群发生长时间故障,实时数据也不会受到太大影响。因为数据是同时写往两个集群的,两者互为主从,是平等的关系。如果其中一个集群宕机,就把数据读写切到另一个集群,这样线上是无感知的,而后等集群恢复了再追数据即可。
如果是一主一从,从集群的数据从主集群获取,那么主集群挂了,从集群也没有数据写入,线上的实时数据就会不准了。
按照上面的方案,我们已经运行了两三个月了,基本没有什么问题,主从数据也能保持一致。
写在最后
因为 Doris 本身可以通过多个 FE 和 BE 实现有高可用,其实一开始对于是否有必要做双集群,我是抱着怀疑态度的,但我们实际使用中确实出现过由于 tablet 不可用带来的整个集群故障,于是也就做了。
最近参加了 Doris 的深圳行活动,会上说 Doris 即将发布 2.0 版本,将带来跨集群数据复制功能(CCR),这说明我们的方向是对的,确实也有不少公司有这种需求,我也是十分地期待。另外,会上我们的同事也有分享这套双集群的解决思路,这篇文章算是一个技术补充。
最后,期待 Doris 2.0 ~
来源:大数据小屋















 1117
1117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









