







写在前面:此文只记录了下本人感觉需要注意的地方,不全且不一定准确。详细内容可以参考文中帖的链接,比较好!!!
经典的CNN:Inception v1\v2\v3\v4、Resnet、Resnext、DensNet、SeNet…
1、时间轴

2、关于模型改进的一些总结:
1. Inception系列,从网络宽度角度入手。v1提出了1种Inception结构;v2提出BN;v3提出使用 3x3 卷积核代替 5x5 和 7x7、分解卷积核 nxn->1xn,nx1;v4提出3种Inception结构。
2. Resnet,从网络深度角度入手,提出参差结构
3. Resnext,从宽度和深度两方面入手,提出cardinality【组卷积】
4. Densenet,将每层都与输入层和loss层相连
5. Senet,attention应用在feature map的channel上
文章目录
1. AlexNet
- Alexnet的特点
- 更深的网络结构
- 使用层叠的卷积层,即卷积层+卷积层+池化层来提取图像的特征
- 使用Dropout抑制过拟合
- 使用数据增强Data Augmentation抑制过拟合
- 使用Relu替换之前的sigmoid的作为激活函数
- 多GPU训练
2. VGG16
参考:深入理解VGG16模型
- VGG16特点:
- 通过增加深度(3x3卷积代替)和宽度(高维通道数)能有效地提升性能;
- 最佳模型:VGG16,从头到尾只有3x3卷积与2x2池化,简洁优美;
- 提出"块"设计,深层且窄的卷积(即3 × 3)⽐较浅层且宽的卷积(即5x5)更有效
3. NiN
参考:NiN网络详解
- NiN模块,由⼀个卷积层和多个1 × 1卷积层组成
def nin_block(in_channels, out_channels, kernel_size, strides, padding):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU())
- NiN模型 + 全局平均汇聚层,替换全连接层,减少过拟合,同时显著减少模型的参数。
3. Inception v1
- 1x1卷积核作用:
a) 整合多通道信息,而不会改变输入大小(14146->14*14);
b) 升降维,可以任意增减输出的通道数;
c) 减少计算量 - inception block结构作用:用1*1卷积核降低参数量,比常规低了78倍
- 辅助分类器(拿中间的输出去做回归):更有效回传梯度,扮演regularizer角色(训练初期无明显作用,训练结束时开始有用)
- 使用average pooling代替全连接层,减少参数


Inception v1参考
2. Inception v2
- 相比于Inception v1,加入了BN层减少Internal Covariate Shift问题。
(Internal Covariate Shift:在训练过程中,随着各层参数的不断变化,各层的输出会向某一个趋势不断变化,即隐层的输入分布也会向某一个趋势在不断变化,会越来越接近激活函数的两端值,导致产生梯度消失,模型收敛速度变慢,难以训练,这个就叫Internal Covariate Shift。)
3. Inception v3
- 卷积核分解:
a) 用两个 3 ∗ 3 3*3 3∗3卷积核代替 5 ∗ 5 5*5 5∗5,减少了28%的计算量
b) 用 1 ∗ 3 1*3 1∗3 和 3 ∗ 1 3*1 3∗1代替一个 3 ∗ 3 3*3 3∗3,节省33%(12-20层加较好) - 减小feature map的size,增加channel保持信息无损
Inception v3参考
4. Inception v4
- 提出了3种Inception module,三种模块间有Reduction模块起pool作用;
- 同时借鉴了Resnet的参差结构,在Inception v3/v4加入了参差结构
Inception v4参考
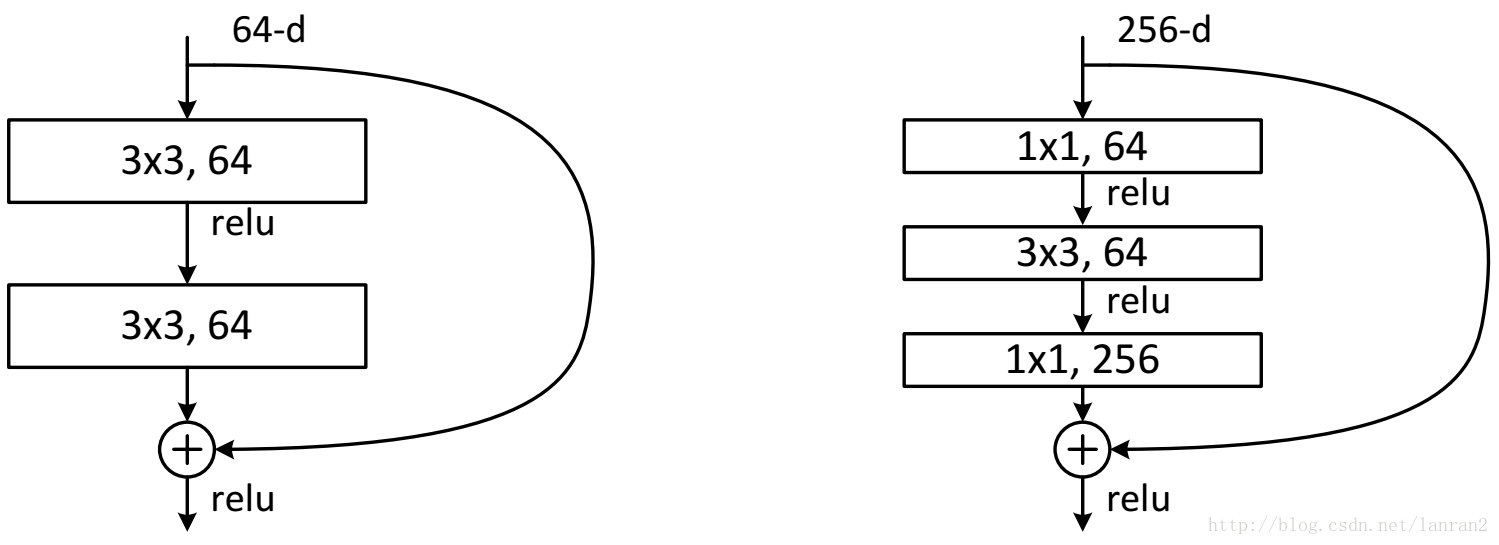
5. ResNet
- 为什么ResNet可以解决“随着网络加深,准确率不下降”的问题:答:理论上,Resnet提供了两种选择方式,也就是identity mapping 和 residual mapping,如果网络已经到达最优,继续加深网络,residual mapping将被push为0,只剩下identity mapping,这样理论上网络一直处于最优状态了,网络的性能也就不会随着深度增加而降低了。
- ResNet的两种设计:
- bottleneck design中
1
∗
1
1*1
1∗1的作用:
a)减少计算与参数量(约17倍)
b)神经网络层数曾多,可以更好的拟合非线性模型
ResNet
6. ResNext

- 在resnet的基础上,借助Inception的splite-transform-merge思想,将参差结构扩展成 cardinality,其中每一个子结构都相同,改善了Inception模型超参数较多,鲁棒性较差,精度方面较Resnet有提高。
Resnext
7. DenseNet
核心:create short paths from early layers to later layers
-
DenseNet 的本质:每一层的输入均来自前面所有层的输出
-
DenseNet-BC网络结构
DenseNet-BC 较 DenseNet 多了 bottleneck layer(B)和 Translation layer(C),接下来详细介绍一下两者的作用:
- bottleneck layer 即 Dense Block中的 1 ∗ 1 1*1 1∗1卷积,可以大大减少计算量。以 DensNet-169 中的 Dense Block(3)为例,第 32 层的输入为前 31 层输出进行concat,如果不做 bottleneck layer ,假设每层输出的channel 为 32(growth rate,文中超参),则第 32 层的输入为32 * 31 + 上一个transition layer的输出channel (合共约1000)。如果做 bottleneck layer , 1 ∗ 1 1*1 1∗1 的channel 为 128(growth rate*4),大大减少了计算量;
- transition layer,也是用来减少计算量的。还拿 DensNet-169 中的 Dense Block(3)为例,第32层的输出为32(growth rate),concate前31层的输出及上个Dense Block的输出为此Dense Block的输出(channel也是1000左右),transition layer有个参数reduction(范围是0到1),表示将这些输出缩小到原来的多少倍,默认是0.5,这样传给下一个Dense Block的时候channel数量就会减少一半,这就是transition layer的作用。文中还用到dropout操作来随机减少分支,避免过拟合。
-
DenseNet的优点:
a. 减轻了梯度消失:DenseNet网络的设计相当于将每一层的input和loss直接相连。
b. 极致利用feature达到更好的效果
c. 一定程度上减少了参数量及防治过拟合(bottleneck layer,Translation layer以及较小的growth rate选择)
DenseNet参考
8. SENet
核心:对特征的通道之间加入类似attention机制考虑
- se block原理图:
a. Squeeze:对channel进行了squeeze,通过ave pooling 将feature map([W, H, C])变为[1,1,C]。【顺着空间维度进行压缩,将每个二维的特征通道[W,H]变成一个实数,该实数某种程度上具有该通道全局的特征】
b. Excitation:对得到的squeeze后的feature map,使用sigmoid函数进行excitation,得到每个通道的权重
c. Reweight:根据b得到的权重与原feature map加权 - se block结构图:
SeNet参考















 471
471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









