







写在前面,本文只记录了个人认为的关键点,仅供参考。更多细节请参考链接中文章
参考1:机器学习之常用优化方法
参考2:拉格朗日乘数法
梯度下降法
梯度下降法是最早最简单,也是最为常用的最优化方法。梯度下降法实现简单,当目标函数是凸函数时,梯度下降法的解是全局解。一般情况下,其解不保证是全局最优解,梯度下降法的速度也未必是最快的。梯度下降法的优化思想是用当前位置负梯度方向作为搜索方向,因为该方向为当前位置的最快下降方向,所以也被称为是”最速下降法“。最速下降法越接近目标值,步长越小,前进越慢。
- 梯度下降法的搜索迭代示意图如下图所示:

- 公式为目标函数的一阶泰勒函数展开:

- 梯度下降法的缺点:
1.靠近极小值时收敛速度减慢
2.可能会“之字形”地下降
3.直线搜索时可能会产生一些问题;
- 随机梯度下降和批量梯度下降
批量梯度下降:最小化所有训练样本的损失函数,使得最终求解的是全局的最优解,即求解的参数是使得风险函数最小,但是对于大规模样本问题效率低下。
随机梯度下降:最小化每条样本的损失函数,虽然不是每次迭代得到的损失函数都向着全局最优方向, 但是大的整体的方向是向全局最优解的,最终的结果往往是在全局最优解附近,适用于大规模训练样本情况。
牛顿法
牛顿法使用函数f (x)的泰勒级数的前面2项来寻找方程f (x) = 0的根。牛顿法最大的特点就在于它的收敛速度很快。
- 牛顿法的搜索迭代示意图如下图所示:
- 公式为目标函数的二阶泰勒函数展开:
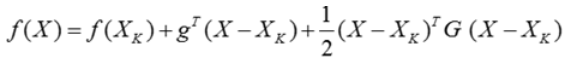
- 牛顿法和梯度下降法的效率对比:
从本质上去看,牛顿法是二阶收敛,梯度下降是一阶收敛,所以牛顿法就更快。如果更通俗地说的话,比如你想找一条最短的路径走到一个盆地的最底部,梯度下降法每次只从你当前所处位置选一个坡度最大的方向走一步,牛顿法在选择方向时,不仅会考虑坡度是否够大,还会考虑你走了一步之后,坡度是否会变得更大。所以,可以说牛顿法比梯度下降法看得更远一点,能更快地走到最底部。(牛顿法目光更加长远,所以少走弯路;相对而言,梯度下降法只考虑了局部的最优,没有全局思想。)
- 牛顿法的优缺点总结:
优点:二阶泰勒展开,收敛速度更快
缺点:牛顿法是一种迭代算法,每一步都需要求解目标函数的Hessian矩阵的逆矩阵,计算比较复杂。
拟牛顿法
拟牛顿法的本质思想是改善牛顿法每次需要求解复杂的Hessian矩阵的逆矩阵的缺陷,它使用正定矩阵来近似Hessian矩阵的逆,从而简化了运算的复杂度(即使用正定矩阵去逼近难求的Hessian矩阵)。拟牛顿法和最速下降法一样只要求每一步迭代时的目标函数的梯度(即利用一阶就可以去模拟牛顿的二阶)。通过测量梯度的变化,构造一个目标函数的模型使之足以产生超线性收敛性。
-
公式为目标函数的二阶泰勒函数展开:

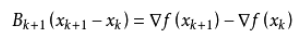
这里的 B k B_k Bk为代替牛顿法中Hessian矩阵的正定矩阵 -
优点
解决了使用一阶的正定矩阵去逼近牛顿法中难求的Hessian逆矩阵,降低了计算量
拉格朗日乘数法
拉格朗日乘子法主要用于解决约束优化问题,它的基本思想就是通过引入拉格朗日乘子来将含有n个变量和k个约束条件的约束优化问题转化为含有(n+k)个变量的无约束优化问题。
一般在机器学习中的损失函数都伴随着约束条件,分为约束条件为等式和不等式。
-
考虑等式和不等式的综合公式为:

-
考虑不等式的公式为:
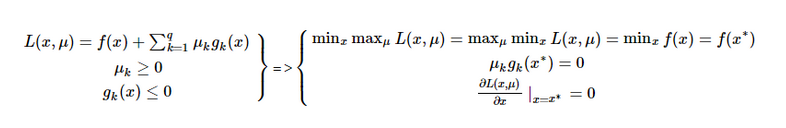















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









