







 本文介绍了SPSS Modeler在数据挖掘中的应用,包括业务理解、数据准备、模型建立等步骤。讨论了数据挖掘任务如分类、回归、聚类和关联分析,以及变量类型在数据集成中的角色。重点讲述了数据清洗过程,如离群点和极端值的调整方法,并提供了使用Modeler进行数据清洗和模型构建的操作流程。
本文介绍了SPSS Modeler在数据挖掘中的应用,包括业务理解、数据准备、模型建立等步骤。讨论了数据挖掘任务如分类、回归、聚类和关联分析,以及变量类型在数据集成中的角色。重点讲述了数据清洗过程,如离群点和极端值的调整方法,并提供了使用Modeler进行数据清洗和模型构建的操作流程。
数据挖掘是一个过程,是一个以数据为中心的循序渐进的螺旋式数据探索过程。
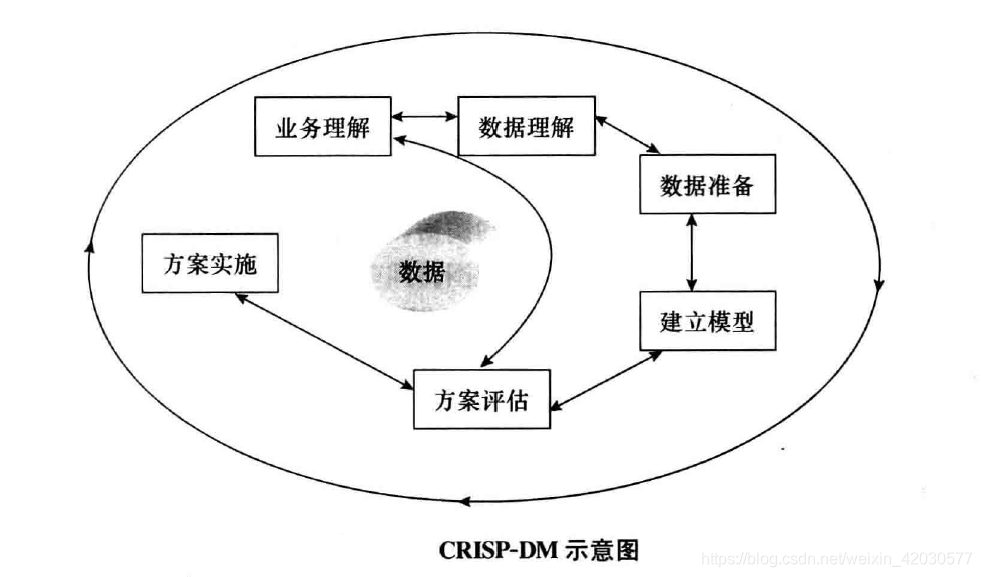
一、数据挖掘方法论的各环节:
1.业务理解
2.数据理解

3.数据准备
4.建立模型
5.方案评估
6.方案实施
二、数据挖掘的任务和应用:
1.数据总结
2.分类和回归
3.聚类分析
4.关联分析
三、数据挖掘得到的只是形式:
1.浓缩数据
2.树形图
3.规则
4.数学模型
四、数据挖掘算法的分类:
1.根据算法分析数据的方式划分
2.根据算法来自的学科划分
3.根据算法所得结果的类型划分
4.根据学习过程的类型划分
首先来了解一下Modeler的数据集成:
一、从数据挖掘角度看变量类型:
连续数值型:表示年龄、家庭人口数等。
二分类型,简称分类型:表示性别等。
多分类型,也称名义型:表示职业、籍
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









