







1.为什么使用索引?
2为什么使用B+树?
3B+树的特点
目录
对于刚接触索引的人来说,可以知道的只有,加索引,查询就会变快。可是为什么呢?
我们来看这样一个例子。
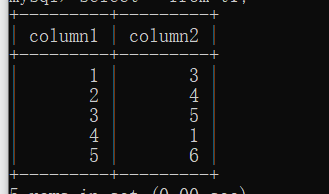
对于column2列。如果我们要找到数据为6,如果没有任何的索引,我们需要查找几次呢?
答案是六次,一次顺序查找,从首项3开始到末项。我们找一个值,如果没有加索引,在最差的情况下(查找的数在末项),需要六次,这只是数据量为6条的情况下,那么如果这个表有几百万条数据,而需要被查找的数据又刚好在末尾,那么我们岂不是要查找几百万次才能找到这个数,显然,这个效率我们是无法接受的。
而我们就需要新的解决方案来应对这样的问题。
所以我们引入索引这个概念。
什么是索引?
索引是存储引擎用于快速找到记录的一种数据结构——《高性能MySQL》
我的理解就是排好序的数据结构。
如果我们刚才的数据是排好序的数据结构,比如下面这个,那么我们需要几次查找呢?假设一次磁盘I/O可以吧一个结点调入内存,并在内存中比较。(在内存中速度非常快,我们忽略不计。)

那么我们只需要 3次查找,如果我们的数据又几百万条,那么效率就大大提高了。
了解了前面的铺垫,那么我们想提高效率,就需要选择正确的数据结构,使得这个排好序的数据结构,查找效率高。
那么为什么不是二叉树?不是红黑树?而是你B+树呢?
当使用二叉查找树作为这种数据结构时,当数据是从1,2,3,4,5,6这种数据插入到数据表里面,会怎么样?

那么在最差的情况下,我们查找数6,居然需要6次查找,这是无法接受的,相当于遍历这个表。
出现这样的原因是,二叉查找树不是一颗平衡树,不会平衡。那么我们使用红黑树好了,它会平衡,不会出现这样的问题。
效果如图:(当数据是从1到10顺序插入)

效率是提高了,但是当数据量提高到几百万行的时候,红黑树的高度还是太高了。我们想要减少它的高度,
那么这个数据结构的解决方案就是使用B+树。
什么是B+树,我的理解是就是多叉平衡树。
原本红黑树的每个节点,只有一个索引,而B+树就是多个,这样说难以理解,看图7和9为同一个结点,10和11 为同一个结点,还可以存储更多的索引。

这样它的高度就会降低超级多,通常B+树的高度低于5,所以我们查找一个数最多只需要五次磁盘I/O。
B+树的特点:
1非叶子结点不存储数据,那么它就可以存储更多的索引。
2叶子结点区间之间有访问指针,提高区间的访问性能。
至于B+树是如何实现的,有点复杂,有兴趣的可以自己查资料。
4聚集索引和非聚集索引
在b+树的数据结构作为索引时,会分为聚集索引和非聚集索引。
使用InoDB作为存储引擎的时候,就是聚集索引,使用MYSAM作为存储引擎的时候,就是非聚集索引。
聚集索引就是数据和表放在一次(聚集)在叶子结点存放的是数据(完整的行记录),非聚集索引就是数据和表文件分开(非聚集)在叶子结点存放的是索引,需要在查找一次才能找到数据。















 380
380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









