







转载自音程UP主的博客
原文链接:https://blog.csdn.net/qq_43391414/article/details/120783887
1.概述
torch.nn.Embedding是用来将一个数字变成一个指定维度的向量的,比如数字1变成一个128维的向量,数字2变成另外一个128维的向量。不过,这128维的向量并不是永恒不变的,这些128维的向量是模型真正的输入(也就是模型的第1层)(数字1和2并不是,可以算作模型第0层),然后这128维的向量会参与模型训练并且得到更新,从而数字1会有一个更好的128维向量的表示。
显然,这非常像全连接层,所以很多人说,Embedding层是全连接层的特例。
2.Embedding
import numpy as np
import torch.nn as nn
import torch比如我们有2个字,
vocab={"我":0,"你":1}我们要把这两个字变成向量,有两种做法:
2.1 nn.Linear
vocab={"我":0,"你":1}
vocab_vec=torch.eye(2)#构造one-hot向量,所以需要用两个2维的向量表示这两个字。
print(vocab_vec)tensor(
[[1., 0.],
[0., 1.]])但是众所周知one-hot向量没有任何的语义信息,而且在这个one-hot中,空间庞大。我们需要一个低维稠密的向量来代替one-hot向量。很简单,一个线性层即可。
fc=nn.Linear(2,2)#表示一个字原来向量维度是2,现在还是线性变换成2.
fc(vocab_vec)
上面才是我们想要的这两个字的表示,然后将上述输入到模型的后续层中,进行训练,这样,由于线性层fc的参数会不断变化,所以上面这个数值fc(vocab_vec)当然也会随之而变化喽。
2.2 nn.Embedding
使用这个会更简单,更方便一些。我们不需要构造one-hot向量,我们开头说过了,Embedding层将一个数字直接转化为你想要的维度的向量,这是好事!比如你内存不够的时候,就不用像上面这种做法那样需要多存储一个one-hot的矩阵。
vocab={"我":0,"你":1}
embedding=torch.nn.Embedding(vocab_size=2,emb_size=2)
#vocab_size:表示一共有多少个字需要embedding,
#emb_size:表示我们希望一个字向量的维度是多少。然后,我们想要得到我们那两个字(“我”,“你”)的向量,只需要将"我"和"你"的编号输入即可,而不需要那个one-hot向量,比如"我"的编号是0,"你"的编号是1:
me=torch.tensor([0],dtype=torch.int64)
you=torch.tensor([1],dtype=torch.int64)然后将上述作为参数,传入embedding层。
print(embedding(me))
print(embedding(you))tensor([[0.6188, 1.5322]], grad_fn=<EmbeddingBackward>)
tensor([[-0.8198, -0.9139]], grad_fn=<EmbeddingBackward>)就得到了上述两个字的向量。当然了,我们也可以合并起来得到:
meyou=torch.tensor([0,1],dtype=torch.int64)
print(embedding(meyou))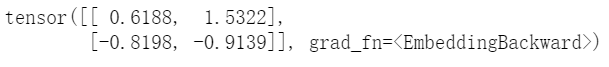
同样,上述得到的向量输入到模型的后续中,训练后,Embedding层的参数会随之改变,从而我们得到了更好的字向量。
对比
可以看到,Embedding和Linear几乎是一样的,区别就在于:输入不同,一个是输入数字,后者是输入one-hot向量。习惯上,我们在模型的第一层使用的是Embedding,而不是Linear。模型的后续不会再使用Embedding,而是使用Linear。
初始化第一层
补充:上述我们在做定义的时候,里面的参数是初始化的。
fc=nn.Linear(2,2)
embedding=torch.nn.Embedding(vocab_size,emb_size)有的时候,我们可能觉得其初始化得不好,想要按照我们的来指定,怎么办?
1.使用nn.Parameter直接进行赋值。
myemb=nn.Parameter(torch.rand(2,2))#(0,1)均匀分布的参数
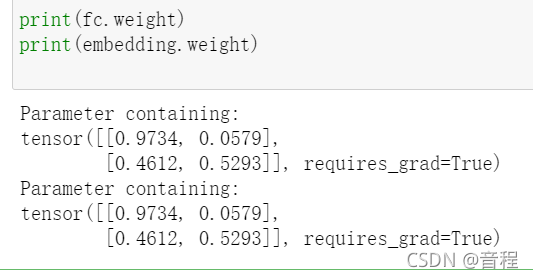
print(fc.weight)#原来的
fc.weight=myemb#修改
print(embedding.weight)#原来的
embedding.weight=myemb#修改
我们再查看修改后的:
2.使用.data
embedding.weight.data.uniform_(-1,1)#又改成(-1,1)的均匀分布。
embedding.weight#查看一下
3.nn.Embedding.from_pretrained
以上两种方法对于Embedding和Linear都适用。接下来的一个方法只适用于Embedding。
a=torch.tensor([[1,2],[2,2]],dtype=torch.float32)
embedding=nn.Embedding.from_pretrained(a)
embedding.weight















 309
309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









