






`nn.Embedding` 和 `nn.Linear` 都是 PyTorch 中的神经网络模块,用于实现不同的功能。我们将首先介绍它们之间的区别,然后展示代码实例和输出结果,以及如何通过转换它们以达到相同的输出结果。
1. nn.Embedding:
`nn.Embedding` 用于实现词嵌入。是一个2维权重的矩阵(vocab_size, embedding_size),在创建完成后,我们只需要输入对应的词id,就会从该矩阵中索引出对应的词向量。
它将整数索引(通常表示单词或其他离散特征)映射到固定大小的向量。词嵌入可以捕捉单词之间的语义关系,它们通常作为自然语言处理任务的输入。
import torch
import torch.nn as nn
vocab_size = 10 # 词汇表大小
embedding_dim = 4 # 嵌入向量维度
embedding = nn.Embedding(vocab_size, embedding_dim)
input_ids = torch.tensor([1, 3, 5], dtype=torch.long) # 示例输入
embeddings = embedding(input_ids)
print(embeddings)输出结果:
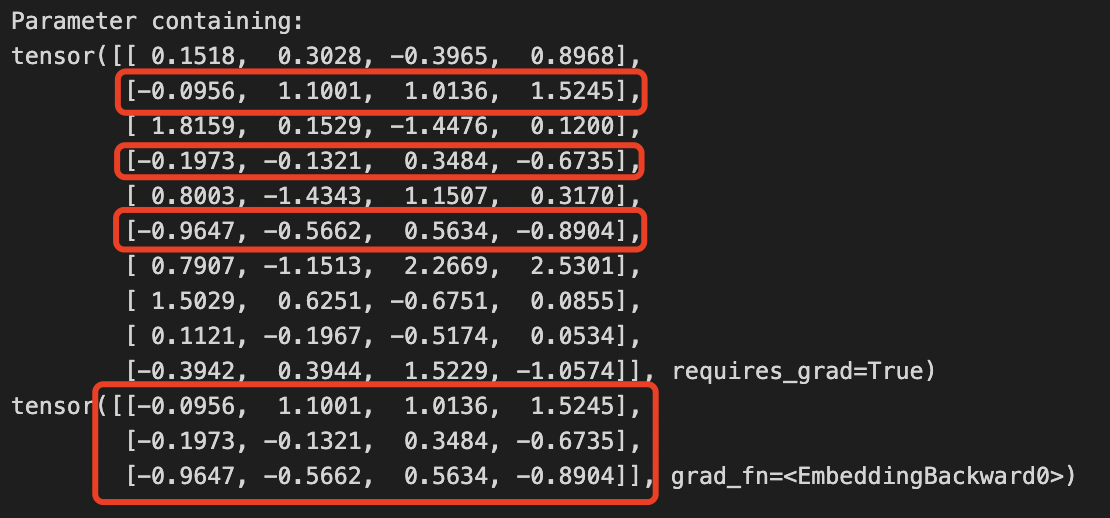
可以看到输出的结果与nn.Embedding权重的第1,3,5行的权重完全相同,
2. nn.Linear:
`nn.Linear` 用于实现全连接线性层。它接受一个输入向量,并通过线性变换(矩阵乘法和偏置相加)将其映射到另一个向量空间。全连接层通常用于实现神经网络的隐藏层或输出层。
input_dim = 4 # 输入向量维度
output_dim = 5 # 输出向量维度
linear = nn.Linear(input_dim, output_dim)
input_vec = torch.tensor([[1.0, 2.0, 3.0, 4.0]]) # 示例输入
output_vec = linear(input_vec)
print(output_vec)输出结果:

3. 使用nn.Linear模拟nn.Embedding
要使用 `nn.Linear` 模拟 `nn.Embedding` 的行为,我们可以执行以下操作:
import torch
import torch.nn as nn
vocab_size = 10
embedding_dim = 4
input_ids = torch.tensor([1, 3, 5], dtype=torch.long)
# 使用 nn.Embedding
embedding = nn.Embedding(vocab_size, embedding_dim)
embeddings = embedding(input_ids)
print("nn.Embedding 输出:")
print(embeddings)
# 使用 nn.Linear
linear = nn.Linear(vocab_size, embedding_dim, bias=False) # 禁用偏置项
input_one_hot = torch.zeros(len(input_ids), vocab_size).scatter_(1, input_ids.unsqueeze(1), 1) # 将输入转换为 one-hot 向量
linear_output = linear(input_one_hot)
print("nn.Linear 输出:")
print(linear_output)
# 将 nn.Embedding 的权重赋值给 nn.Linear 的权重
linear.weight.data = embedding.weight.data.t()
linear_output_updated = linear(input_one_hot)
print("更新权重后的 nn.Linear 输出:")
print(linear_output_updated)输出结果:
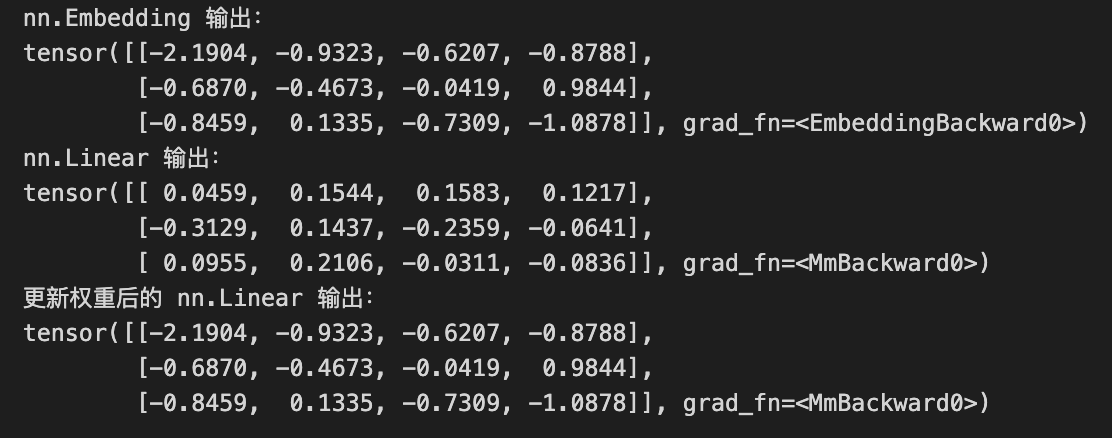
从输出结果中,我们可以看到,通过禁用偏置项并将输入转换为 one-hot 向量,我们可以使用 `nn.Linear` 模拟 `nn.Embedding` 的行为。同时,我们需要将 `nn.Embedding` 的权重赋值给 `nn.Linear` 的权重,这样它们才能产生相同的输出。














 1070
1070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









