







Extendible Hashing
刚学习完CMU1545的哈希索引,对于课上的例子理解不是很深,特此巩固
文章目录
Extendible Hashing
可扩展哈希是一种动态哈希方法,可以自动的进行增长,结构为桶+目录。主要分类的方式是通过哈希函数处理后的key的高(低)位进行分类,类似于数据结构中的桶排序。
一、名词介绍
含有数据结构:
目录(Dictionary):存储指向桶的指针,大小为2^全局深度。
全局深度(Global Depth):表示目录对桶进行分类的位数,如全局深度=2时,就采用高(低)2位进行分类,即:00,01,10,11。
桶(Buckets):存储值。
局部深度(Local depth):根据全局深度来确定等会扩展的时候的操作。
操作
桶分裂(Bucket Splitting):当桶内元素溢出时,进行分裂动作。
目录扩展(Directory Expansion):当桶元素溢出时,进行目录扩展操作。
二、基本操作
1.操作流程
- 哈希处理:这是一种Hashing Scheme,所以接收的数据为经过哈希函数处理过后的值。这个值我们并不纠结于是什么,但需要转换为二进制格式。
- 查看全局深度。如全局深度为2,则提取输入数据的高(低)2位作为索引。如输入数据为1000101,则我们需要使用高(低)两位10(01)作为索引。(注:为了方便,我们统一使用高位作为例子,低位操作同理即可)。
- 查看目录表,将数据放入10所指向的桶中。
- 如果桶未满,直接放入即可。
- 如果桶满了,需要进行桶分裂和目录扩展的操作。
- 重复以上操作
2.桶满时操作
当桶满了时候,需要进行目录扩展和桶分裂,这也是此方法的精华之处。
- 检查局部深度和全局深度的关系
case 1:
1、如全局深度等于局部深度,则需要进行目录扩展和桶分裂。此时目录的全局深度+1,溢出桶在保留元素后删除。
2、对数据进行重新的散列操作,将原有数据分为两个桶后,依据现有的目录重新插入数据。
eg:原有全局深度为2,桶01此时满员。在桶满了之后则变为3,使用高3位:010和011进行索引。此时溢出的桶被删除,新增两个桶分别由010和011指向,局部深度=全局深度,并对满桶的数据进行散列操作,将数据分散到这两个桶中。
case 2:
1、如全局深度大于局部深度,无需进行目录扩展,因为别的桶已经扩展完了。这点之后的例子会直观的展示。因此只需要进行桶分裂,步骤和case1相同。
3.例子
此例参考CMU15-445 Hash Index与https://www.geeksforgeeks.org/extendible-hashing-dynamic-approach-to-dbms/
我们假设:桶大小为3,hash函数为恒等函数即H = key,插入值为整型数
3.1初始化
将每个整数拆分为二进制数,此时我们使用16、4、6、22、24、10、31、7数进行插入操作。则上述整型数的二进制为:
16- 10000
4- 00100
6- 00110
22- 10110
24- 11000
10- 01010
31- 11111
7- 00111
最初,全局深度=局部深度=1,因为目录中只有0,1两页。如图所示:
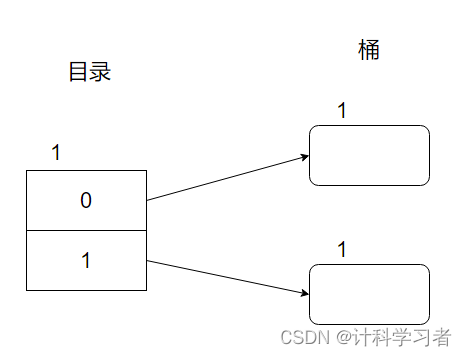
三个1代表了全局和局部深度
3.2 插入
此时插入16,因为二进制为10000,高1位为1,则插入1指向的桶中
此时插入4,因为二进制为00100,高1位为0,则插入0指向的桶中
…………
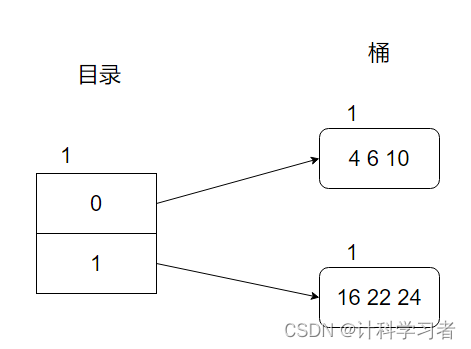
插入到10,此时变成了这样
之后插入31,因为31的二进制为11111,理应放入1所指向的桶中
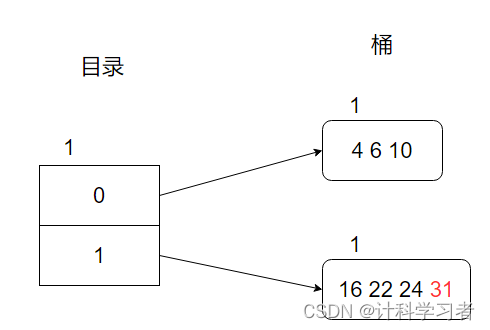
但是因为桶容量为3,出现了桶溢出!
判断:全局深度=目录中1指向的桶的局部深度,因此进行目录扩展和桶分裂
1、目录扩展:全局深度++,此时目录的内容为(暂时不管桶的指向)

2、因为只是1指向的桶发生了分裂,因此0指向的桶不进行桶分裂,将00和01两页一起指向之前0指向的桶,即:
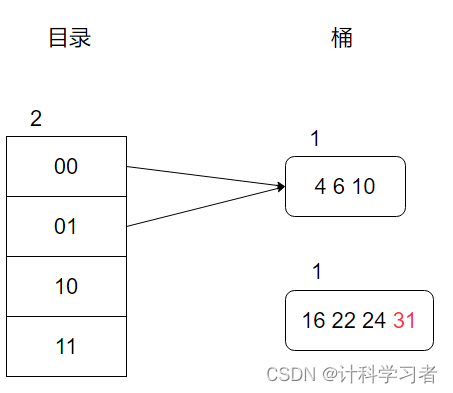
此时该桶的局部深度不变,表示没有发生桶分裂
3、将溢出桶进行桶分裂,即将原有的数据按照现在目录重新计算并放入新桶中,新桶的局部深度=全局深度=2
16的二进制为10000,高2位为10,因此放入10指向的桶中
22的二进制为10110,高2位为10,因此放入10指向的桶中
24的二进制为11100,高2位为11,因此放入11指向的桶中
31的二进制为11111,高2位为11,因此放入11指向的桶中
此时,图变成了这样:
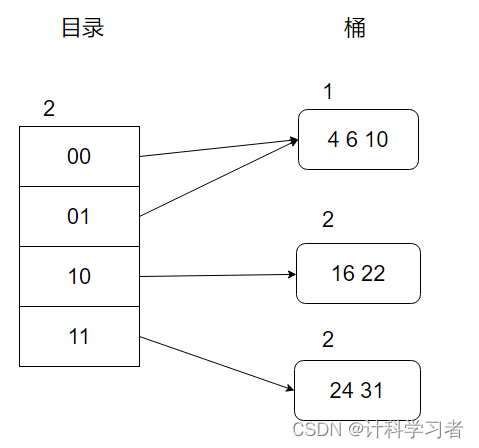
之后继续插入7,二进制为00111,高2位为00,插入00的桶中。但此时00的桶已经满了,因此发生了溢出。
判断:全局深度>局部深度,因此不进行目录扩张,仅仅进行桶分裂

从此,插入步骤结束
2.读取数据和删除数据
读取和删除也是根据哈希值找到对应的桶,对桶内数据进行遍历。
总结
优点:
1、检索块
2、不会发生数据丢失
3、值动态更新
缺点:
1、如果在同一目录上散列多个记录,同时保持记录分布不均匀,则目录大小可能会显着增加。
2、每个桶的大小是固定的。
3、当全局深度和局部深度差异变得很大时,指针会浪费内存。
4、这种方法编码起来很复杂。















 6220
6220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









